Handwritten Text Recognition (HTR) involves automatically transforming a source’s handwritten text within a digital image into its machine text representation.
- handwritten text recognition (HTR)
- machine learning
- Belfort civil registers of birthsBelfort civil registers of births
1. Introduction
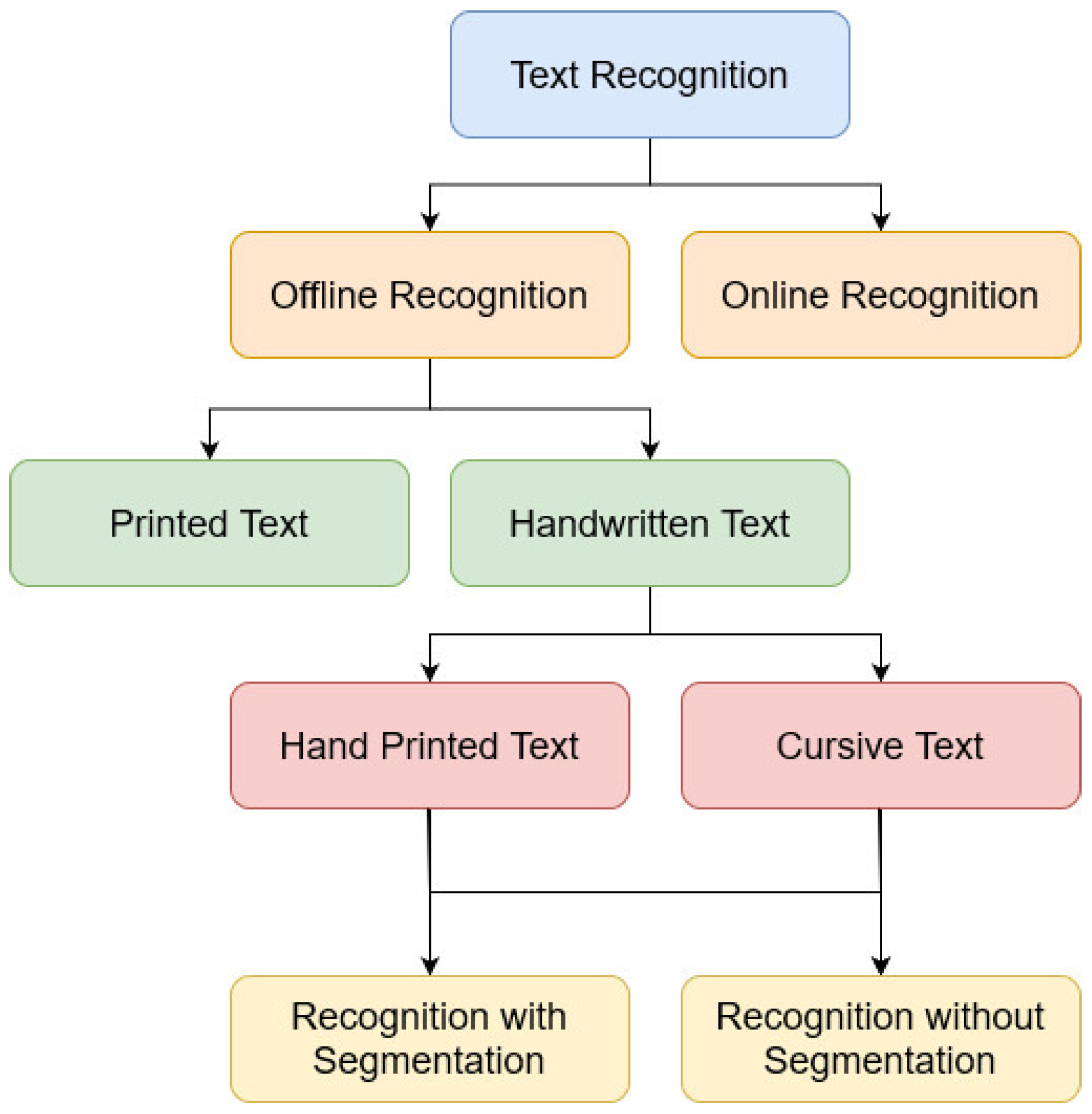
2. State-of-the-Art Recent Surveys
3. Handwritten Text Recognition Workflow
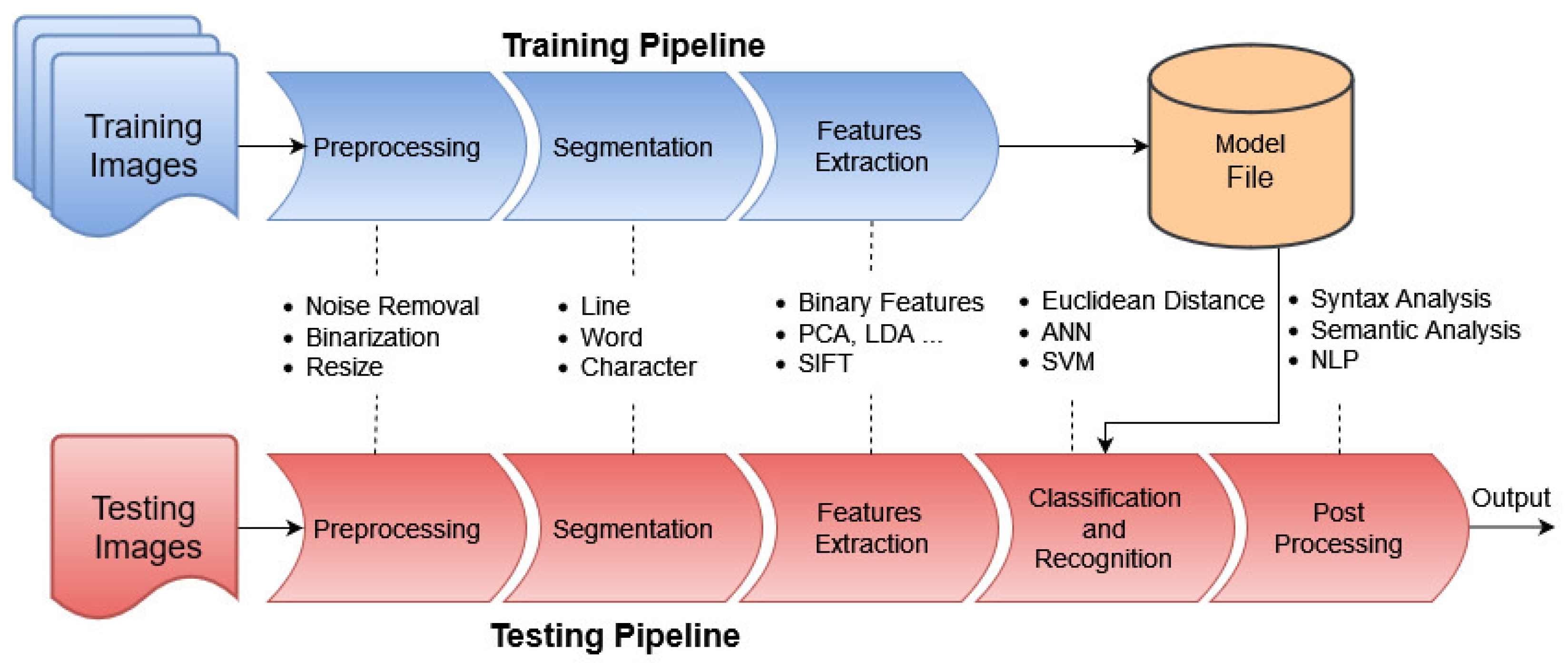
3.1. Image Digitization
3.2. Pre-Processing
-
Binarization: This process involves converting digital images into binary images consisting of dual collections of pixels in black and white (0 and 1). Binarization is valuable for segmenting the image into foreground text and background.
-
Noise removal: This process involves eliminating unwanted pixels from the digitized image that can affect the original information. This noise may originate from the image sensor and electronic components of a scanner or digital camera. Various methods have been proposed for noise removal or reduction, such as Non-local means [32] and Anisotropic diffusion [33], as well as filters like Gaussian, Mean, and Median filters.
-
Edges detection: This process involves identifying the edges of the text within the digitized image using various methods such as Sobel, Laplacian, Canny, and Prewitt edge detection.
-
Skew detection and correction: Skew refers to the misalignment of text within a digital image. In other words, it indicates the amount of rotation needed to align the text horizontally or vertically. Various methods for skew detection and correction have been proposed to address this objective, such as Hough transforms and clustering.
-
Normalization: This process involves reducing the shape and size variation of digital images. Additionally, it scales the input image features to a fixed range (e.g., between 0 and 1), while maintaining the relationship between these features. This process plays a valuable role in the training stage of deep learning models.
3.3. Segmentation
3.4. Feature Extraction
3.5. Classification
3.6. Post-Processing
4. Advancements in Handwritten Text Recognition: A State-of-the-Art Overview
|
Reference |
Architecture |
Dataset |
HTR Level |
|---|---|---|---|
|
[38] |
AHCR-DLS (2-CNN) |
HMBD, CMATER and AIA9k |
Character level |
|
[42] |
Transformer-T and Transformer with Cross-Attention |
KHATT |
Character (Subword) level |
|
[46] |
Light Transformer |
IAM |
Character level |
|
[53] |
Attention-Gated-CNN-BGRU |
Kazakh |
Character level |
|
[59] |
CRNN-MDLSTM |
IAM and George Washington |
Line level |
|
[60] |
OctCNN-BGRU |
EPARCHOS, IAM and RIMES |
Line level |
|
[15] |
CRNN-FCNN |
EPARCHOS, IAM and RIMES |
Line level |
|
[62] |
OrigamiNet |
IAM ICDAR 2017 |
Page level |
|
Reference |
Architecture |
Dataset |
HTR Level |
|---|---|---|---|
|
[64] |
Grapheme-based MLP-HMM + Gaussian Mixture HMM + MDLSTM-RNN |
RIMES |
Word and multi-word level |
|
[68] |
Decoupled Attention Network (DAN) |
IAM and RIMES |
Word level |
|
[72] |
Deep Convolutional Network + Recurrent Encoder-Decoder Network |
IAM and RIMES |
Word level |
|
[65] |
MDLSTM + RNN + CTC |
IAM and RIMES |
Line level |
|
[74] |
CNN + 1D-LSTM + CTC |
IAM and RIMES |
Line level |
|
[66] |
MDLSTM + Covolution Layers + FCN + CTC |
IAM, RIMES 2011 and OpenHaRT |
Line level |
|
[91] |
MDLSTM + CTC |
IAM, RIMES and OpenHaRT |
Line level |
|
[67] |
Attention-based RNN + LSTM |
RIMES |
Line level |
|
[73] |
CNN + BLSTM + S2S + CTC |
IAM, RIMES and StAZH |
Line level |
|
[75] |
Gated-CRNN |
IAM and RIMES |
Paragraph level |
|
[80] |
Transformer joint |
ICDAR 2017 Esposalles and FHMR |
Paragraph level |
|
[78] |
Simple Predict & Align Network (SPAN) |
RIMES, IAM and READ 2016 |
Paragraph level |
|
[79] |
Vertical Attention Network (VAN) |
RIMES, IAM and READ 2016 |
Paragraph level |
|
Document Attention Network (DAN) |
RIMES 2009 and READ 2016 |
Page level |
5. Commercial Systems in Handwritten Text Recognition
|
Name |
Link |
|---|---|
|
Transkribus |
https://readcoop.eu/transkribus/ (accessed on 21 November 2023) |
|
Ocelus |
https://ocelus.teklia.com/ (accessed on 21 November 2023) |
|
Konfuzio |
https://konfuzio.com/en/document-ocr/ (accessed on 21 November 2023) |
|
DOCSUMO |
https://www.docsumo.com/free-tools/online-ocr-scanner (accessed on 21 November 2023) |
6. The Belfort Civil Registers of Births
The civil registers of births in the commune of Belfort, spanning from 1807 to 1919, comprises 39,627 birth records at a resolution of 300 dpi. These records were chosen for their homogeneity, as they feature Gregorian dates of birth starting from 1807 and are available until 1919 due to legal reasons.
The registers initially consist of completely handwritten entries, later transitioning to a partially printed format with spaces left free for the individual information concerning the declaration of the newborn. The transition to this hybrid preprint/manuscript format varied from one commune to another. In Belfort, it occurred in 1885 and concerns $57.5$\% of the 39,627 declarations. The record contain crucial information, including the child's name, parent' names, witnesses, among other relevant data. Figure 3 provides a visual representation of a sample page from the civil registers, while Table 4 outlines the structure and content of an entry within the archive.
The archive is publicly accessible online until the year 1902 via the following link: https://archives.belfort.fr/search/form/e5a0c07e-9607-42b0-9772-f19d7bfa180e (accessed on 12 November 2023). Additionally, the researchers have obtained permission from the municipal archives to access data up to the year 1919.

Figure 3. Sample of Belfort civil registers of births, featuring a hybrid mix of printed and handwritten text, along with marginal annotations.
Table 4. The structure of an entry in the Belfort civil registers of births
| Structure | Content |
| Head margin |
Registration number. First and last name of the person born. |
| Main text |
Time and date of declaration. Surname, first name and position of the official registering. Surname, first name, age, profession and address of declarant. Sex of the newborn. Time and date of birth. First and last name of the father (if different of the declarant). Surname, first name, status (married or other), profession (sometimes) and address (sometimes) of the mother. Surnames of the newborn. surnames, first names, ages, professions and addresses (city) of the 2 witnesses. Mention of absence of signature or illiteracy of the declarant (very rarely). |
| Margins (annotations) |
Mention of official recognition of paternity/maternity (by father or/and mother): surname, name of the declarant, date of recognition (by marriage or declaration). Mention of marriage: date of marriage, wedding location, surname and name of spouse. Mention of divorce: date of divorce, divorce location. Mention of death: date and place of death, date of the declaration of death. |
6.1 Belfort Records Transcription Challenges
- Belfort records pose several challenges that complicate the transcription process of its entries, categorized into seven main areas:
Document layout: The Belfort registers of birth exhibit two document layouts. The first type consists of double pages with only one entire entry on each page, while the second type comprises double pages with two entire entries per page. Each entry within these layouts contains the information outlined in Table 4. However, there are some documents where entries begin on the first page and extend to the second page. - Reading order: It is important to identify the reading order of text regions, including the main text and marginal annotation text within the entry.
- Hybrid format: Some of the registers consists of entries that includes printed and handwritten text, as shown in Figure 3.
- Marginal mentions: These mentions pertain to the individual born but are added after the birth, often in different writing styles and by means of scriptural tools that can be quite distinct. Moreover, they are placed in variable positions compared to the main text of the declaration.
- Text styles: The registers are written in different handwritten styles that consist of angular, spiky letters, varying character sizes, and ornate flourishes, resulting in overlapped word and text lines within the script.
- Skewness: Skewness refers to the misalignment of handwritten text caused by human writing. Many handwritten text lines in the main paragraphs and margins exhibit variations in text skew, including vertical text (90 degrees of rotation). Effective processes are needed to correct the skewness of the images for any degree of rotation.
- Degradation: The images exhibit text degradation caused by fading handwriting and page smudging (ink stains and yellowing of pages).
7. Results
The researchers presents a comparison of state-of-the-art methods based on French RIMES dataset using Character Error Rate (CER) and word Error Rate (WER) metrics as reported in the publications. This dataset has emerged as a benchmark in the field of handwritten text recognition, many models have been evaluated using this dataset, making it a widely accepted and recognized standard for assessing the performance of such systems. Utilizing the RIMES dataset allows for meaningful and relevant comparisons, ensuring that the research facilitates more accurate assessments of systems performance and highlights the best approaches in this field. Figure 4 depicts the CER and WER of state-of-the-art methods at the line and paragraph levels.
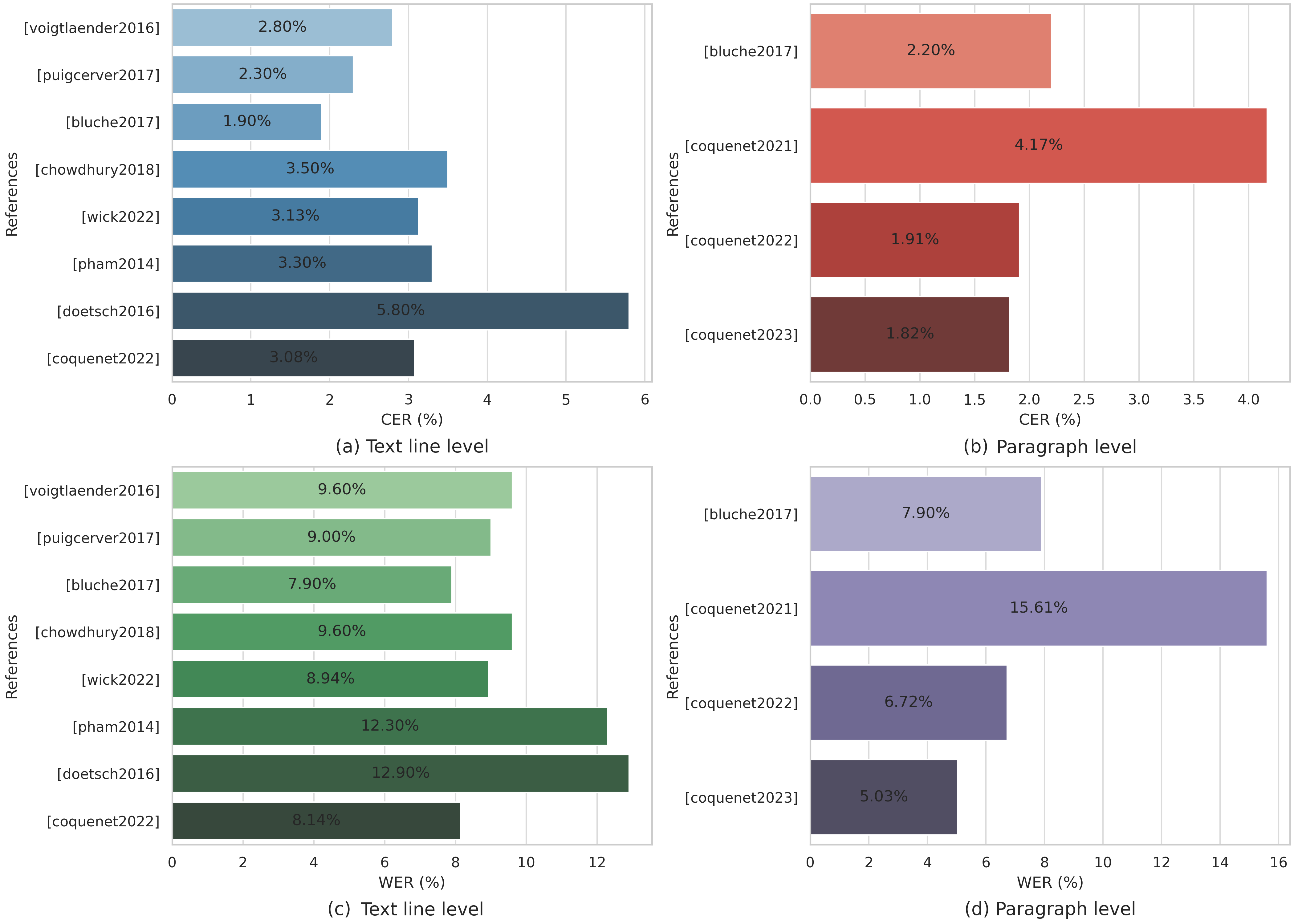 Figure 4. State-of-the-art Character Error Rate (CER) and Word Error Rate (WER) across various studies applied to the French language at two different levels: text line and paragraph. (a) Shows the CER at the text line level, based on studies by Voigtlaender et al. [65], Puigcerver et al. [74], Bluche et al. [75], Chowdhury et al. [72], Wick et al. [73], Pham et al. [91], Doetsch et al. [67], and Coquenet et al. [79]. (b) Depicts the CER at the paragraph level, as reported in studies by Bluche et al. [75], Coquenet et al. [78][79][83]. (c,d) Present the WER at the text line and paragraph levels, respectively, from the same studies.
Figure 4. State-of-the-art Character Error Rate (CER) and Word Error Rate (WER) across various studies applied to the French language at two different levels: text line and paragraph. (a) Shows the CER at the text line level, based on studies by Voigtlaender et al. [65], Puigcerver et al. [74], Bluche et al. [75], Chowdhury et al. [72], Wick et al. [73], Pham et al. [91], Doetsch et al. [67], and Coquenet et al. [79]. (b) Depicts the CER at the paragraph level, as reported in studies by Bluche et al. [75], Coquenet et al. [78][79][83]. (c,d) Present the WER at the text line and paragraph levels, respectively, from the same studies.
Additionally, the researchers evaluated the effectiveness of commercial systems in recognizing handwritten text in both English and French languages, three systems: Ocelus, Transkribus, and DOCSUMO were chosen to conduct this experiment, as they are among the most well-known and offer free trials for text recognition.
A text line image of Washington dataset was utilized for the English language, and a margin segment from the proposed Belfort civil registers of births was used for the French language. These experiments allowed us to compare and demonstrate the performance of these systems on the recognition of different international languages and various handwriting styles. Table 5 provides a detailed comparison of their performance. It is worth mentioning that evaluating such commercial systems at a documents level has resulted in improved accuracy rates due to differences in character and word counts.
Table 5. Accuracy comparison (%) of HTR commercial systems on French- and English-language datasets.
|
System |
RIMES |
Washington |
||
|
CER (%) |
WER (%) |
CER (%) |
WER (%) |
|
|
Ocelus |
15 |
53 |
2 |
14 |
|
Transkribus |
18 |
33 |
4 |
29 |
|
DOCSUMO |
11 |
33 |
2 |
14 |
8. Conclusion
Handwritten text recognition systems have made significant progress in recent years, becoming increasingly accurate and reliable. In this research, the researchers have presented several state-of-the-art models and achievements in offline handwritten text recognition across various international language documents. Additionally, the researchers presented a comprehensive survey of French handwritten text recognition models specifically. The entry were reviewed at four HTR levels: word, text line, paragraph, and page. Furthermore, the researchers provided a summary of available public datasets for both French and other languages.
Despite significant achievements in recognizing modern handwritten text, there is still a need to extend these capabilities to historical text documents. Historical handwritten text recognition poses unique challenges, such as transcription cost, a variety of writing styles, abbreviations, symbols, and reproduction quality of historical documents.
The researchers also observed that some commercial handwritten text recognition systems are performing exceptionally on handwritten text in English. In contrast, they are inaccurate in recognizing the French historical cursive handwritten text. Nevertheless, these systems could be a promise tool that can assist in automatically transcribing large volumes of historical documents with manual corrections. This is attributed to their advantages in automatic segmentation and dictionary support. Hence, decreasing time and cost.
Finally, the researchers facilitate researchers in identifying the appropriate technique or datasets for further research on both modern and historical handwritten text documents. Furthermore, the researchers conclude that there is a compelling need to design a new technique specifically tailored for transcribing the French Belfort civil registers of births.
This entry is adapted from the peer-reviewed paper 10.3390/jimaging10010018
References
- Fontanella, F.; Colace, F.; Molinara, M.; Di Freca, A.S.; Stanco, F. Pattern recognition and artificial intelligence techniques for cultural heritage. Pattern Recognit. Lett. 2020, 138, 23–29.
- Kamalanaban, E.; Gopinath, M.; Premkumar, S. Medicine box: Doctor’s prescription recognition using deep machine learning. Int. J. Eng. Technol. (UAE) 2018, 7, 114–117.
- Bezerra, B.L.D.; Zanchettin, C.; Toselli, A.H.; Pirlo, G. Handwriting: Recognition, Development and Analysis; Nova Science Publishers, Inc.: Hauppauge, NY, USA, 2017.
- Lu, Z.; Schwartz, R.; Natarajan, P.; Bazzi, I.; Makhoul, J. Advances in the bbn byblos ocr system. In Proceedings of the Fifth International Conference on Document Analysis and Recognition. ICDAR’99 (Cat. No. PR00318), Bangalore, India, 22–22 September 1999; IEEE: Piscataway, NJ, USA, 1999; pp. 337–340.
- Schantz, H.F. History of OCR, Optical Character Recognition; Recognition Technologies Users Association: Manchester, VT, USA, 1982.
- Saritha, B.; Hemanth, S. An efficient hidden markov model for offline handwritten numeral recognition. arXiv 2010, arXiv:1001.5334.
- Rodríguez-Serrano, J.A.; Perronnin, F. A model-based sequence similarity with application to handwritten word spotting. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 34, 2108–2120.
- Sánchez, J.A.; Romero, V.; Toselli, A.H.; Villegas, M.; Vidal, E. A set of benchmarks for handwritten text recognition on historical documents. Pattern Recognit. 2019, 94, 122–134.
- Schuster-Böckler, B.; Bateman, A. An introduction to hidden Markov models. Curr. Protoc. Bioinform. 2007, 18, A.3A.1–A.3A.9.
- Toselli, A.H.; Juan, A.; González, J.; Salvador, I.; Vidal, E.; Casacuberta, F.; Keysers, D.; Ney, H. Integrated handwriting recognition and interpretation using finite-state models. Int. J. Pattern Recognit. Artif. Intell. 2004, 18, 519–539.
- Guo, Q.; Wang, F.; Lei, J.; Tu, D.; Li, G. Convolutional feature learning and Hybrid CNN-HMM for scene number recognition. Neurocomputing 2016, 184, 78–90.
- Cheikhrouhou, A.; Kessentini, Y.; Kanoun, S. Hybrid HMM/BLSTM system for multi-script keyword spotting in printed and handwritten documents with identification stage. Neural Comput. Appl. 2020, 32, 9201–9215.
- Wu, J. Introduction to Convolutional Neural Networks; National Key Lab for Novel Software Technology, Nanjing University: Nanjing, China, 2017; Volume 5, p. 495.
- Sherstinsky, A. Fundamentals of recurrent neural network (RNN) and long short-term memory (LSTM) network. Phys. D Nonlinear Phenom. 2020, 404, 132306.
- Markou, K.; Tsochatzidis, L.; Zagoris, K.; Papazoglou, A.; Karagiannis, X.; Symeonidis, S.; Pratikakis, I. A convolutional recurrent neural network for the handwritten text recognition of historical Greek manuscripts. In Proceedings of the Pattern Recognition. ICPR International Workshops and Challenges, Virtual Event, 10–15 January 2021; Proceedings, Part VII. Springer: Berlin, Germany, 2021; pp. 249–262.
- de Sousa Neto, A.F.; Bezerra, B.L.D.; Toselli, A.H.; Lima, E.B. HTR-Flor: A deep learning system for offline handwritten text recognition. In Proceedings of the 2020 33rd SIBGRAPI Conference on Graphics, Patterns and Images (SIBGRAPI), Porto de Galinhas, Brazil, 7–10 November 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 54–61.
- Zayene, O.; Touj, S.M.; Hennebert, J.; Ingold, R.; Ben Amara, N.E. Multi-dimensional long short-term memory networks for artificial Arabic text recognition in news video. IET Comput. Vis. 2018, 12, 710–719.
- Memon, J.; Sami, M.; Khan, R.A.; Uddin, M. Handwritten optical character recognition (OCR): A comprehensive systematic literature review (SLR). IEEE Access 2020, 8, 142642–142668.
- Purohit, A.; Chauhan, S.S. A literature survey on handwritten character recognition. Int. J. Comput. Sci. Inf. Technol. (IJCSIT) 2016, 7, 1–5.
- Singh, L.; Sandhu, J.K.; Sahu, R. A Literature Survey on Handwritten Character Recognition. In Proceedings of the 2023 International Conference on Circuit Power and Computing Technologies (ICCPCT), Kollam, India, 10–11 August 2023; IEEE: Piscataway, NJ, USA, 2023; pp. 1755–1760.
- Narang, S.R.; Jindal, M.K.; Kumar, M. Ancient text recognition: A review. Artif. Intell. Rev. 2020, 53, 5517–5558.
- Dhivya, S.; Devi, U.G. Study on automated approach to recognize characters for handwritten and historical document. ACM Trans. Asian Low Resour. Lang. Inf. Process. 2021, 20.
- Faizullah, S.; Ayub, M.S.; Hussain, S.; Khan, M.A. A Survey of OCR in Arabic Language: Applications, Techniques, and Challenges. Appl. Sci. 2023, 13, 4584.
- Ehrmann, M.; Hamdi, A.; Pontes, E.L.; Romanello, M.; Doucet, A. Named entity recognition and classification in historical documents: A survey. ACM Comput. Surv. 2023, 56, 1–47.
- Maarand, M.; Beyer, Y.; Kåsen, A.; Fosseide, K.T.; Kermorvant, C. A comprehensive comparison of open-source libraries for handwritten text recognition in norwegian. In Proceedings of the International Workshop on Document Analysis Systems, La Rochelle, France, 22–25 May 2022; Springer: Berlin, Germany, 2022; pp. 399–413.
- Nikolaidou, K.; Seuret, M.; Mokayed, H.; Liwicki, M. A survey of historical document image datasets. Int. J. Doc. Anal. Recognit. (IJDAR) 2022, 25, 305–338.
- Hussain, R.; Raza, A.; Siddiqi, I.; Khurshid, K.; Djeddi, C. A comprehensive survey of handwritten document benchmarks: Structure, usage and evaluation. EURASIP J. Image Video Process. 2015, 2015, 1–24.
- Philips, J.; Tabrizi, N. Historical Document Processing: A Survey of Techniques, Tools, and Trends. In Proceedings of the 12th International Joint Conference on Knowledge Discovery, Knowledge Engineering and Knowledge Management (IC3K 2020), Virtual Event, 2–4 November 2020; pp. 341–349.
- El Qacimy, B.; Hammouch, A.; Kerroum, M.A. A review of feature extraction techniques for handwritten Arabic text recognition. In Proceedings of the 2015 International Conference on Electrical and Information Technologies (ICEIT), Marrakech, Morocco, 25–27 March 2015; IEEE: Piscataway, NJ, USA, 2015; pp. 241–245.
- Binmakhashen, G.M.; Mahmoud, S.A. Document layout analysis: A comprehensive survey. ACM Comput. Surv. (CSUR) 2019, 52, 1–36.
- Srivastva, R.; Raj, A.; Patnaik, T.; Kumar, B. A survey on techniques of separation of machine printed text and handwritten text. Int. J. Eng. Adv. Technol. 2013, 2, 552–555.
- Buades, A.; Coll, B.; Morel, J.M. A non-local algorithm for image denoising. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–25 June 2005; IEEE: Piscataway, NJ, USA, 2005; Volume 2, pp. 60–65.
- Perona, P.; Malik, J. Scale-space and edge detection using anisotropic diffusion. IEEE Trans. Pattern Anal. Mach. Intell. 1990, 12, 629–639.
- Abliz, A.; Simayi, W.; Moydin, K.; Hamdulla, A. A survey on methods for basic unit segmentation in off-line handwritten text recognition. Int. J. Future Gener. Commun. Netw. 2016, 9, 137–152.
- Naik, G.R.; Kumar, D.K. An overview of independent component analysis and its applications. Informatica 2011, 35, 63–81.
- Qu, X.; Swanson, R.; Day, R.; Tsai, J. A guide to template based structure prediction. Curr. Protein Pept. Sci. 2009, 10, 270–285.
- Hazza, A.; Shoaib, M.; Alshebeili, S.A.; Fahad, A. An overview of feature-based methods for digital modulation classification. In Proceedings of the 2013 1st International Conference on Communications, Signal Processing, and Their Applications (ICCSPA), Sharjah, United Arab Emirates, 12–14 February 2013; IEEE: Piscataway, NJ, USA, 2013; pp. 1–6.
- Balaha, H.M.; Ali, H.A.; Saraya, M.; Badawy, M. A new Arabic handwritten character recognition deep learning system (AHCR-DLS). Neural Comput. Appl. 2021, 33, 6325–6367.
- Das, N.; Sarkar, R.; Basu, S.; Kundu, M.; Nasipuri, M.; Basu, D.K. A Genetic Algorithm Based Region Sampling for Selection of Local Features in Handwritten Digit Recognition Application. Appl. Soft Comput. 2012, 12, 1592–1606.
- Das, N.; Reddy, J.M.; Sarkar, R.; Basu, S.; Kundu, M.; Nasipuri, M.; Basu, D.K. A Statistical-topological Feature Combination for Recognition of Handwritten Numerals. Appl. Soft Comput. 2012, 12, 2486–2495.
- Torki, M.; Hussein, M.E.; Elsallamy, A.; Fayyaz, M.; Yaser, S. Window-based descriptors for Arabic handwritten alphabet recognition: A comparative study on a novel dataset. arXiv 2014, arXiv:1411.3519.
- Momeni, S.; Babaali, B. Arabic Offline Handwritten Text Recognition with Transformers. Available online: https://www.researchsquare.com/article/rs-2300065/v1 (accessed on 1 January 2024).
- Mahmoud, S.A.; Ahmad, I.; Alshayeb, M.; Al-Khatib, W.G.; Parvez, M.T.; Fink, G.A.; Märgner, V.; El Abed, H. Khatt: Arabic offline handwritten text database. In Proceedings of the 2012 International Conference on Frontiers in Handwriting Recognition, Bari, Italy, 18–20 September 2012; IEEE: Piscataway, NJ, USA, 2012; pp. 449–454.
- Mahmoud, S.A.; Ahmad, I.; Al-Khatib, W.G.; Alshayeb, M.; Parvez, M.T.; Märgner, V.; Fink, G.A. KHATT: An open Arabic offline handwritten text database. Pattern Recognit. 2014, 47, 1096–1112.
- Ahmad, R.; Naz, S.; Afzal, M.Z.; Rashid, S.F.; Liwicki, M.; Dengel, A. Khatt: A deep learning benchmark on arabic script. In Proceedings of the 2017 14th IAPR International Conference on Document Analysis and Recognition (ICDAR), Kyoto, Japan, 9–15 November 2017; IEEE: Piscataway, NJ, USA, 2017; Volume 7, pp. 10–14.
- Barrere, K.; Soullard, Y.; Lemaitre, A.; Coüasnon, B. A light transformer-based architecture for handwritten text recognition. In Proceedings of the Document Analysis Systems: 15th IAPR International Workshop, DAS 2022, La Rochelle, France, 22–25 May 2022; Springer: Berlin, Germany, 2022; pp. 275–290.
- Li, M.; Lv, T.; Chen, J.; Cui, L.; Lu, Y.; Florencio, D.; Zhang, C.; Li, Z.; Wei, F. Trocr: Transformer-based optical character recognition with pre-trained models. arXiv 2021, arXiv:2109.10282.
- Parvez, M.T.; Mahmoud, S.A. Offline Arabic handwritten text recognition: A survey. ACM Comput. Surv. (CSUR) 2013, 45, 1–35.
- Jannoud, I.A. Automatic Arabic handwritten text recognition system. Am. J. Appl. Sci. 2007, 4, 857–864.
- Alrobah, N.; Albahli, S. Arabic handwritten recognition using deep learning: A Survey. Arab. J. Sci. Eng. 2022, 47, 9943–9963.
- Balaha, H.M.; Ali, H.A.; Youssef, E.K.; Elsayed, A.E.; Samak, R.A.; Abdelhaleem, M.S.; Tolba, M.M.; Shehata, M.R.; Mahmoud, M.R.; Abdelhameed, M.M.; et al. Recognizing arabic handwritten characters using deep learning and genetic algorithms. Multimed. Tools Appl. 2021, 80, 32473–32509.
- Kass, D.; Vats, E. AttentionHTR: Handwritten text recognition based on attention encoder-decoder networks. In Proceedings of the Document Analysis Systems: 15th IAPR International Workshop, DAS 2022, La Rochelle, France, 22–25 May 2022; Springer: Berlin, Germany, 2022; pp. 507–522.
- Abdallah, A.; Hamada, M.; Nurseitov, D. Attention-based fully gated CNN-BGRU for Russian handwritten text. J. Imaging 2020, 6, 141.
- Marti, U.V.; Bunke, H. A full English sentence database for off-line handwriting recognition. In Proceedings of the Fifth International Conference on Document Analysis and Recognition. ICDAR’99 (Cat. No. PR00318), Bangalore, India, 22 September 1999; IEEE: Piscataway, NJ, USA, 1999; pp. 705–708.
- Fischer, A.; Frinken, V.; Fornés, A.; Bunke, H. Transcription alignment of Latin manuscripts using hidden Markov models. In Proceedings of the 2011 Workshop on Historical Document Imaging and Processing, Beijing, China, 16–17 September 2011; pp. 29–36.
- Causer, T.; Wallace, V. Building a volunteer community: Results and findings from Transcribe Bentham. Digit. Humanit. Q. 2012, 6, 2. Available online: https://www.digitalhumanities.org/dhq/vol/6/2/000125/000125.html (accessed on 1 January 2024).
- Fischer, A.; Keller, A.; Frinken, V.; Bunke, H. Lexicon-free handwritten word spotting using character HMMs. Pattern Recognit. Lett. 2012, 33, 934–942.
- Nurseitov, D.; Bostanbekov, K.; Kurmankhojayev, D.; Alimova, A.; Abdallah, A.; Tolegenov, R. Handwritten Kazakh and Russian (HKR) database for text recognition. Multimed. Tools Appl. 2021, 80, 33075–33097.
- Kumari, L.; Singh, S.; Rathore, V.; Sharma, A. A Lexicon and Depth-Wise Separable Convolution Based Handwritten Text Recognition System. In Proceedings of the Image and Vision Computing: 37th International Conference, IVCNZ 2022, Auckland, New Zealand, 24–25 November 2022; Revised Selected Papers. Springer: Berlin, Germany, 2023; pp. 442–456.
- Tsochatzidis, L.; Symeonidis, S.; Papazoglou, A.; Pratikakis, I. HTR for greek historical handwritten documents. J. Imaging 2021, 7, 260.
- Augustin, E.; Carré, M.; Grosicki, E.; Brodin, J.M.; Geoffrois, E.; Prêteux, F. RIMES evaluation campaign for handwritten mail processing. In Proceedings of the International Workshop on Frontiers in Handwriting Recognition (IWFHR’06), La Baule, France, 23–26 October 2006; pp. 231–235.
- Yousef, M.; Bishop, T.E. OrigamiNet: Weakly-supervised, segmentation-free, one-step, full page text recognition by learning to unfold. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 14710–14719.
- Grosicki, E.; El-Abed, H. Icdar 2011-french handwriting recognition competition. In Proceedings of the 2011 International Conference on Document Analysis and Recognition, Beijing, China, 18–21 September 2011; IEEE: Piscataway, NJ, USA, 2011; pp. 1459–1463.
- Menasri, F.; Louradour, J.; Bianne-Bernard, A.L.; Kermorvant, C. The A2iA French handwriting recognition system at the Rimes-ICDAR2011 competition. In Proceedings of the Document Recognition and Retrieval XIX. SPIE, Burlingame, CA, USA, 25–26 January 2012; Volume 8297, pp. 263–270.
- Voigtlaender, P.; Doetsch, P.; Ney, H. Handwriting recognition with large multidimensional long short-term memory recurrent neural networks. In Proceedings of the 2016 15th International Conference on Frontiers in Handwriting Recognition (ICFHR), Shenzhen, China, 23–26 October 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 228–233.
- Louradour, J.; Kermorvant, C. Curriculum learning for handwritten text line recognition. In Proceedings of the 2014 11th IAPR International Workshop on Document Analysis Systems, Tours, France, 7–10 April 2014; IEEE: Piscataway, NJ, USA, 2014; pp. 56–60.
- Doetsch, P.; Zeyer, A.; Ney, H. Bidirectional decoder networks for attention-based end-to-end offline handwriting recognition. In Proceedings of the 2016 15th International Conference on Frontiers in Handwriting Recognition (ICFHR), Shenzhen, China, 23–26 October 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 361–366.
- Wang, T.; Zhu, Y.; Jin, L.; Luo, C.; Chen, X.; Wu, Y.; Wang, Q.; Cai, M. Decoupled attention network for text recognition. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 12216–12224.
- Moysset, B.; Bluche, T.; Knibbe, M.; Benzeghiba, M.F.; Messina, R.; Louradour, J.; Kermorvant, C. The A2iA multi-lingual text recognition system at the second Maurdor evaluation. In Proceedings of the 2014 14th International Conference on Frontiers in Handwriting Recognition, Hersonissos, Greece, 1–4 September 2014; IEEE: Piscataway, NJ, USA, 2014; pp. 297–302.
- Brunessaux, S.; Giroux, P.; Grilheres, B.; Manta, M.; Bodin, M.; Choukri, K.; Galibert, O.; Kahn, J. The maurdor project: Improving automatic processing of digital documents. In Proceedings of the 2014 11th IAPR International Workshop on Document Analysis Systems, Tours, France, 7–10 April 2014; IEEE: Piscataway, NJ, USA, 2014; pp. 349–354.
- Oprean, C.; Likforman-Sulem, L.; Mokbel, C.; Popescu, A. BLSTM-based handwritten text recognition using Web resources. In Proceedings of the 2015 13th International Conference on Document Analysis and Recognition (ICDAR), Tunis, Tunisia, 23–26 August 2015; IEEE: Piscataway, NJ, USA, 2015; pp. 466–470.
- Chowdhury, A.; Vig, L. An efficient end-to-end neural model for handwritten text recognition. arXiv 2018, arXiv:1807.07965.
- Wick, C.; Zöllner, J.; Grüning, T. Rescoring sequence-to-sequence models for text line recognition with ctc-prefixes. In Proceedings of the Document Analysis Systems: 15th IAPR International Workshop, DAS 2022, La Rochelle, France, 22–25 May 2022; Springer: Berlin, Germany, 2022; pp. 260–274.
- Puigcerver, J. Are multidimensional recurrent layers really necessary for handwritten text recognition? In Proceedings of the 2017 14th IAPR International Conference on Document Analysis and Recognition (ICDAR), Kyoto, Japan, 9–15 November 2017; IEEE: Piscataway, NJ, USA, 2017; Volume 1, pp. 67–72.
- Bluche, T.; Messina, R. Gated convolutional recurrent neural networks for multilingual handwriting recognition. In Proceedings of the 2017 14th IAPR International Conference on Document Analysis and Recognition (ICDAR), Kyoto, Japan, 9–15 November 2017; IEEE: Piscataway, NJ, USA, 2017; Volume 1, pp. 646–651.
- Torres Aguilar, S.O.; Jolivet, V. Handwritten Text Recognition for Documentary Medieval Manuscripts. J. Data Min. Digit. Humanit. 2023. Available online: https://hal.science/hal-03892163v2 (accessed on 1 January 2024).
- Stutzmann, D.; Moufflet, J.F.; Hamel, S. La recherche en plein texte dans les sources manuscrites médiévales: Enjeux et perspectives du projet HIMANIS pour l’édition électronique. Médiévales 2017, 67–96.
- Coquenet, D.; Chatelain, C.; Paquet, T. SPAN: A simple predict & align network for handwritten paragraph recognition. In Proceedings of the Document Analysis and Recognition–ICDAR 2021: 16th International Conference, Lausanne, Switzerland, 5–10 September 2021; Proceedings, Part III 16. Springer: Berlin, Germany, 2021; pp. 70–84.
- Coquenet, D.; Chatelain, C.; Paquet, T. End-to-end handwritten paragraph text recognition using a vertical attention network. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 45, 508–524.
- Rouhou, A.C.; Dhiaf, M.; Kessentini, Y.; Salem, S.B. Transformer-based approach for joint handwriting and named entity recognition in historical document. Pattern Recognit. Lett. 2022, 155, 128–134.
- Romero, V.; Fornés, A.; Serrano, N.; Sánchez, J.A.; Toselli, A.H.; Frinken, V.; Vidal, E.; Lladós, J. The ESPOSALLES database: An ancient marriage license corpus for off-line handwriting recognition. Pattern Recognit. 2013, 46, 1658–1669.
- Dhiaf, M.; Jemni, S.K.; Kessentini, Y. DocNER: A deep learning system for named entity recognition in handwritten document images. In Proceedings of the Neural Information Processing: 28th International Conference, ICONIP 2021, Sanur, Bali, Indonesia, 8–12 December 2021; Proceedings, Part VI 28. Springer: Berlin, Germany, 2021; pp. 239–246.
- Coquenet, D.; Chatelain, C.; Paquet, T. DAN: A segmentation-free document attention network for handwritten document recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 8227–8243.
- Coquenet, D.; Chatelain, C.; Paquet, T. Faster DAN: Multi-target Queries with Document Positional Encoding for End-to-end Handwritten Document Recognition. arXiv 2023, arXiv:2301.10593.
- Cloppet, F.; Eglin, V.; Helias-Baron, M.; Kieu, C.; Vincent, N.; Stutzmann, D. Icdar2017 competition on the classification of medieval handwritings in latin script. In Proceedings of the 2017 14th IAPR International Conference on Document Analysis and Recognition (ICDAR), Kyoto, Japan, 9–15 November 2017; IEEE: Piscataway, NJ, USA, 2017; Volume 1, pp. 1371–1376.
- Cilia, N.D.; De Stefano, C.; Fontanella, F.; di Freca, A.S. A ranking-based feature selection approach for handwritten character recognition. Pattern Recognit. Lett. 2019, 121, 77–86.
- Clanuwat, T.; Lamb, A.; Kitamoto, A. KuroNet: Pre-modern Japanese Kuzushiji character recognition with deep learning. In Proceedings of the 2019 International Conference on Document Analysis and Recognition (ICDAR), Sydney, NSW, Australia, 20–25 September 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 607–614.
- Shi, B.; Bai, X.; Yao, C. An end-to-end trainable neural network for image-based sequence recognition and its application to scene text recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 2298–2304.
- Swaileh, W.; Lerouge, J.; Paquet, T. A unified French/English syllabic model for handwriting recognition. In Proceedings of the 2016 15th International Conference on Frontiers in Handwriting Recognition (ICFHR), Shenzhen, China, 23–26 October 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 536–541.
- Bhunia, A.K.; Das, A.; Bhunia, A.K.; Kishore, P.S.R.; Roy, P.P. Handwriting recognition in low-resource scripts using adversarial learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 4767–4776.
- Pham, V.; Bluche, T.; Kermorvant, C.; Louradour, J. Dropout improves recurrent neural networks for handwriting recognition. In Proceedings of the 2014 14th International Conference on Frontiers in Handwriting Recognition, Hersonissos, Greece, 1–4 September 2014; pp. 285–290.
- Ingle, R.R.; Fujii, Y.; Deselaers, T.; Baccash, J.; Popat, A.C. A scalable handwritten text recognition system. In Proceedings of the 2019 International Conference on Document Analysis and Recognition (ICDAR), Sydney, NSW, Australia, 20–25 September 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 17–24.
- Bluche, T. Joint line segmentation and transcription for end-to-end handwritten paragraph recognition. Adv. Neural Inf. Process. Syst. 2016, 29.
- Bluche, T.; Louradour, J.; Messina, R. Scan, attend and read: End-to-end handwritten paragraph recognition with mdlstm attention. In Proceedings of the 2017 14th IAPR International Conference on Document Analysis and Recognition (ICDAR), Kyoto, Japan, 9–15 November 2017; IEEE: Piscataway, NJ, USA, 2017; Volume 1, pp. 1050–1055.
- Moysset, B.; Kermorvant, C.; Wolf, C. Full-page text recognition: Learning where to start and when to stop. In Proceedings of the 2017 14th IAPR International Conference on Document Analysis and Recognition (ICDAR), Kyoto, Japan, 9–15 November 2017; IEEE: Piscataway, NJ, USA, 2017; Volume 1, pp. 871–876.
- Wigington, C.; Tensmeyer, C.; Davis, B.; Barrett, W.; Price, B.; Cohen, S. Start, follow, read: End-to-end full-page handwriting recognition. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 367–383.
- Nockels, J.; Gooding, P.; Ames, S.; Terras, M. Understanding the application of handwritten text recognition technology in heritage contexts: A systematic review of Transkribus in published research. Arch. Sci. 2022, 22, 367–392.