Your browser does not fully support modern features. Please upgrade for a smoother experience.
Please note this is an old version of this entry, which may differ significantly from the current revision.
智能问答系统是集自然语言处理、信息检索、语义分析和人工智能于一体的创新型信息服务系统。该系统主要由三个核心部分组成,即问题分析、信息检索和答案提取。通过这三个部分,系统可以为用户提供准确、快速、便捷的应答服务。
- intelligent question-answering system
- information retrieval
1. 引言
智能问答系统是集自然语言处理、信息检索、语义分析和人工智能于一体的创新型信息服务系统。该系统主要由三个核心部分组成,即问题分析、信息检索和答案提取。通过这三个部分,系统可以为用户提供准确、快速、便捷的应答服务。
智能问答系统的代表性系统包括:
(1)基于规则的算法(1960年代-1980年代)。基于这种模式的问答系统主要依靠编写大量的规则和逻辑来实现对话。ELIZA [1] 由 Joseph Weizenbaum 在 1960 年代开发,是第一个旨在模拟心理治疗师和患者之间对话的聊天机器人。PARRY [2] 是 1970 年代开发的一种模拟精神病患者的问答系统。ELIZA和PARRY的出现为后续的智能问答系统提供了多样化的设计思路和应用场景,从而促进了对话系统的多样化和复杂性。然而,该模型的主要问题是缺乏灵活性和可扩展性。它过于依赖人类设定的规则或模板,消耗大量的时间和人力。当问题变得复杂时,很难通过模型设定的简单规则获得满意的答案。
(2)基于统计的算法(1990年代至2000年代)。基于该模型的问答系统采用统计学习的方法,从大量对话数据中学习模式和规则。常见的算法包括向量空间模型[3]和条件随机场[4]。ALICE(Artificial Linguistic Internet Computer Entity)[5]是一个开源的自然语言处理项目。该系统是一个开放领域的问答平台,能够解决跨多个主题和领域的查询。Jabberwacky [6] 是一个早期的智能聊天机器人,它采用机器学习和对话模型来不断增强其响应。这些系统旨在训练可以学习语料库中问题和答案之间关系的模型。因此,这些模型可以进行更自然、更流畅的对话。然而,语境理解能力和泛化能力较弱,难以适应各专业领域的模型共享和迁移学习。此外,考虑到统计模型是在大型语料库上训练的,这种模型在处理特定领域的问题时可能会受到数据偏差的影响,无法提供准确的答案。
(3)基于混合技术的算法(2010年代-2020年代初)。基于此模型的问答系统可以融合各种技术,包括规则、统计和机器学习。它利用多种输入模式(包括语音、图像和文本)进行无缝互操作。总体目标是帮助用户在指定域内完成特定任务或目标,例如预订、旅行、购物或订购食物。这种多种技术和输入模式的协同整合促进了更复杂、更智能的对话系统。基于混合技术模型的典型问答系统包括苹果的Siri [7]、Microsoft的Cortana [8]、亚马逊的Alexa [9]、Facebook的M [10]和谷歌的Google Assistant [11]。这些系统以人工智能和自然语言处理技术为核心,旨在为用户提供个性化和便捷的信息和服务,以满足多样化的需求。
基于这种模式构建的系统具有更强的上下文理解和个性化定制能力,但存在两个缺点:一是这种系统中的对话质量不稳定;其次,模型的泛化能力有限。在专业领域很难实现模型共享、迁移学习和答案生成。该模型的训练需要在计算和数据资源上投入过多,其训练和部署速度较慢。
(4)基于预训练语言的算法(2020年代)。该模型基于预训练语言模型,如BERT [12]、GPT(Generative Pre-trained Transformer)[13]等。这些模型在大规模数据上进行了预训练,它们学习了丰富的语言表示和上下文理解技能,以生成更自然、流畅和准确的响应。此外,通过对特定领域问答数据集的监督训练,问答系统可以回答专业专业领域的问题。文献[14]主要研究了农业问答系统。该系统利用人工智能技术和相关数据集,为农民提供有关天气、市场价格、植物保护和政府计划等主题的信息。文献[15]提出了一种基于BERT的TD-BERT模型。该模型利用BERT强大的语义表示能力,整合目标信息,提高情感分类的准确性。文献[16]提出了一种BERTserini算法,该算法提高了问答系统的精确匹配率。与原始的BERT算法相比,所提方法超越了其处理字节限制,能够为多文档长文本提供准确的答案。
虽然基于BERTserini算法构建的系统在公共数据集上表现良好,但在电力工程等专业领域的应用中存在一些问题。考虑到精确匹配率低、答案质量差,这些模型的工程应用具有挑战性。这些问题主要由以下几个方面引起。
(1)缺乏模型专业知识:BERT或GPT等语言模型通常是从互联网上收集的大量通用语料库中预先训练的。然而,数字领域提供的与电力工程等行业相关的专业资源有限。因此,该模型在处理专业问题时知识储备不足,影响了答案的质量;(2)文档格式差异:电力工程领域的文档格式与公共数据集的文档格式存在显著差异。电力工程领域的文档通常表现出独特的格式,其特点是有大量的分层标题。容易将标题误解为主要内容,误用作为问题的答案,导致结果不准确;(3)场景需求不同:传统答题系统不需要关注原文中答疑的来源。但是,专为专业用途而设计的系统必须为其答案提供特定的来源信息。如果不提供此类信息,可能会对答复的准确性产生疑问。这进一步降低了应用程序在特定域中的效用。
2. 智能问答系统技术
2.1. 常见问题
常见问题(FAQ)是常见问题和答案的集合,旨在帮助用户快速找到问题的答案[17]。关键是要建立一个丰富而准确的预设问题数据库,该数据库由问题和相应的答案组成。它们是从目标文档中手动整理的。FAQ 通过将用户的问题与最相似的问题进行匹配,提供与用户问题相对应的答案。
2.2. BM25算法
Best Match 25(BM25)算法[18,19]最初由Stephen Robertson及其团队于1994年提出,并应用于信息检索领域。它通常用于计算文档和查询之间的相关性分数。BM25的主要逻辑如下:首先,查询语句涉及分词生成语素;然后,计算每个语素与搜索结果之间的相关性分数。
最后,通过将语素的相关性得分与搜索结果进行加权求和,得到检索查询与搜索结果文档之间的相关性得分。BM25算法的计算公式如下:
在此上下文中,Q 表示查询语句,𝑞我表示从 Q 获得的语素。对于中文来说,通过标记化查询 Q 得到的分割结果可以看作是语素𝑞我.D 表示搜索结果文档。𝑊我表示语素的权重𝑞我和𝑅(𝑞我,D)表示语素之间的相关性分数𝑞我和文件D。重量参数有多种计算方法𝑊我,逆文档频率 (IDF) 是常用的方法之一。IDF 的计算过程如下:
在等式中,N 表示索引中的文档总数,并且𝑛(𝑞我)表示包含以下内容的文档数𝑞我.
最后,BM25算法的相关性评分公式可以总结如下:
哪里𝑘1b为调整因子,𝑓(𝑞我,D)表示语素的频率𝑞我出现在文档 D 中, |D|表示文档 D 的长度,vgdl 表示所有文档的平均长度。
2.3. 安塞里尼
Anserini [20]是一个开源的信息检索工具包,支持各种基于文本的信息检索研究和应用。Anserini 的目标是提供一个易于使用且高性能的工具包,支持对大规模文本数据集进行全文搜索、近似搜索、排名和评估等任务。它支持将文本数据集转换为可搜索的索引文件,以便进行有效的检索和查询。Anserini 结合了多种常用的文本检索算法,包括 BM25 算法。使用 Anserini,可以毫不费力地构建基于 BM25 的文本检索系统,并对大规模文本集合进行有效的搜索和排名。该算法的流程图如图 1 所示。
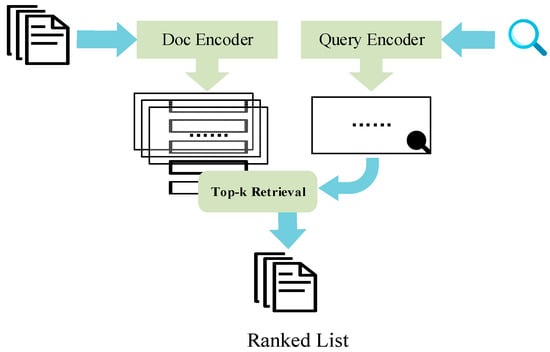
Figure 1. The flowchart of the Anserini algorithm.
2.4. BERT Model
Bidirectional Encoder Representations from Transformers (BERT) [12] is a pre-trained language model proposed by Google in 2018. The model structure is shown in Figure 2. In the model, 𝐸𝑖 represents the encoding of words in the input sentence, which is composed of the sum of three word embedding features. The three word embedding features are Token Embedding, Position Embedding, and Segment Embedding. The integration of these three words embedding features allows the model to have a more comprehensive understanding of the text’s semantics, contextual relationships, and sequence information, thus enhancing the BERT model’s representational power. The transformer structure in the figure is represented as Trm. The 𝑇𝑖 represents the word vector that corresponds to the trained word 𝐸𝑖.
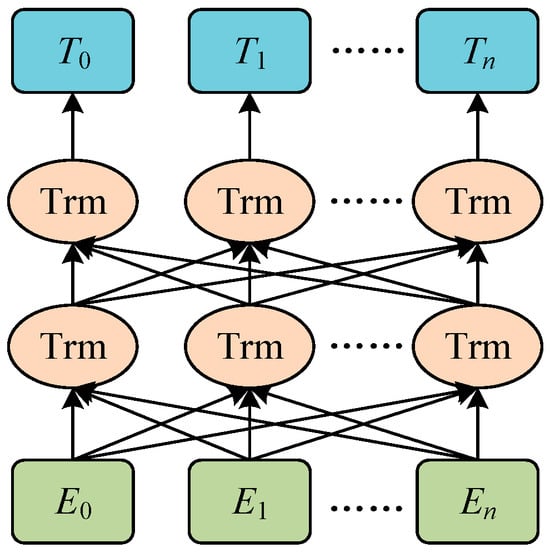
Figure 2. Architecture of BERT.
BERT exclusively employs the encoder component of the Transformer architecture. The encoder is primarily comprised of three key modules: Positional Encoding, Multi-Head Attention, and Feed-Forward Network. Input embeddings are utilized to represent the input data. Addition and normalization operations are denoted by “Add&norm”. The fundamental principle of the encoder is illustrated in Figure 3.
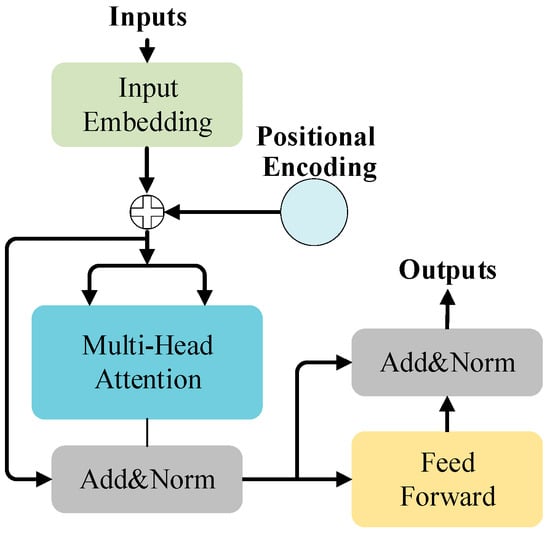
图3.变压器编码器原理。
近年来,在中文领域提出了几种中文BERT模型。其中,哈大讯飞语言认知计算实验室(HFL)发布的中文BERT-wwm-ext模型[21]备受关注,具有代表性。该模型基于原始的Google BERT模型,使用54亿个单词的总词汇进行了进一步的预训练,包括中文百科全书、新闻和问答数据集。该模型采用全词掩码(wwm)策略,这是针对汉语语言特点量身定制的改进。在中文处理中,由于单词是由字符组成的,而一个单词可能由一个或多个字符组成,因此有必要掩盖整个单词而不仅仅是单个字符。wwm 策略旨在更好地理解和捕捉汉语词汇的语义。综上所述,该模型是BERT的改进版中文版,通过全词屏蔽,在中文理解方面表现出更高的性能。
2.5. BERTserini 算法
BERTserini 算法 [16] 的架构如图 4 所示。该算法将 Anserini 信息提取算法与预训练 BERT 模型结合使用。在该算法中,Anserini 检索器负责选择包含答案的文本段落,然后将其传递给 BERT 阅读器以确定答案范围。从图 4 可以看出,BERTserini 是一个智能问答系统,它将 BERT 语言模型与 Anserini 信息检索系统相结合。它协同利用了BERT强大的语言理解能力和Anserini的高效检索功能。与传统算法相比,该算法具有显著优势。它表现出类似于传统算法的快速执行速度,同时还具有端到端匹配的特点,从而获得更精确的答案结果。此外,它还支持从多个文档中提取问题的答案。该算法主要应用于开放域问答任务,其中系统需要从大量非结构化文本中查找问题的答案。
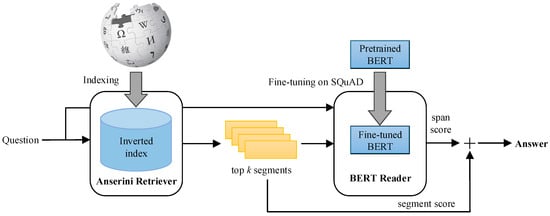
图4.BERTserini 的架构。
This entry is adapted from the peer-reviewed paper 10.3390/pr12010058
This entry is offline, you can click here to edit this entry!