This entry is adapted from the peer-reviewed paper 10.3390/app14010138
Diabetic Retinopathy (DR) is one of the most common microvascular complications of diabetes. Diabetic Macular Edema (DME) is a concomitant symptom of DR. As the grade of lesion of DR and DME increases, the possibility of blindness can also increase significantly. To take early interventions as soon as possible to reduce the likelihood of blindness, it is necessary to perform both DR and DME grading.
- DR
- DME
- joint grading
- multi-branch network
- multi-task learing
1. Introduction
Diabetes poses a substantial health risk for a significant portion of the global population. At least one-third of people with diabetes have diabetes-related eye disease. The most common cause of blindness in diabetic patients is DR. As the number of diabetics increases globally, DR will likely continue to play a significant role in vision loss and the resulting functional impairment for decades to come. As the level of DR lesion increases, patients will successively develop symptoms such as blurred vision, visual field defects, obscured and distorted vision, and dark shadows until blindness. Therefore, it is important to perform DR grading to take the appropriate therapeutic options, such as photocoagulation, vitrectomy, injecting medicine into the eyes, and so on. The number, size, and kind of lesions visible on the surface of the retinas in fundus pictures can be used to categorize DR grades. Figure 1 shows the possible lesions in the fundus image. The International Clinical Diabetic Retinopathy Severity Scale (ICDRS) is a uniform standard for DR grading, according to which DR can be classified as 0–5, i.e., no lesions, mild lesions, moderate lesions, severe lesions, and proliferative [1,2,3].
Figure 1. Fundus images from the IDRiD dataset with hard exudates, soft exudates, hemorrhage, microaneurysms, and other lesions. The severity of DR is related to microaneurysms, hemorrhage, soft exudates, and hard exudates. The severity of DME is determined by the distance from hard exudates to the macular area.
DME is an accompanying symptom of DR and is the most common cause of visual impairment or loss. It refers to retinal thickening or hard exudative deposits caused by the accumulation of extracellular fluid within the central macular sulcus, which can be classified into 3 levels by the distance of exudate from the macular center [4]: 0 (normal, no obvious hard exudate), 1 (mild, hard exudate outside the circle with a radius of one optic disc diameter from the macular center), and 2 (severe, hard exudate within a circle with a radius of one optic disc diameter from the macular center). DR and DME have a more complex relationship, as shown in Figure 2. As shown in Figure 2a,b, there is a small amount of hard exudate in the macular area of the fundus image, and its DR and DME labels are 2. The DR grade of 2 means that the degree of DR is moderate. The DME grade of 2 means the lesion level of DME is severe, that likely causes the patient to go blind. So, in this circumstance, if only DR grading is done, the extent of the patient’s lesion will be misjudged. As seen in Figure 2c,d, no exudate in the macular area, which has DR and DME grades of 4 and 0. It means normal with a grading label of 0 for DME, but a grading label of 4 for DR means proliferative, which can also lead to vision loss. In such a case, if only DME grading is done, the degree of the patient’s lesion will also be misjudged. Therefore, it is important to automatically grade both DR and DME to assist physicians in taking the appropriate therapeutic options.
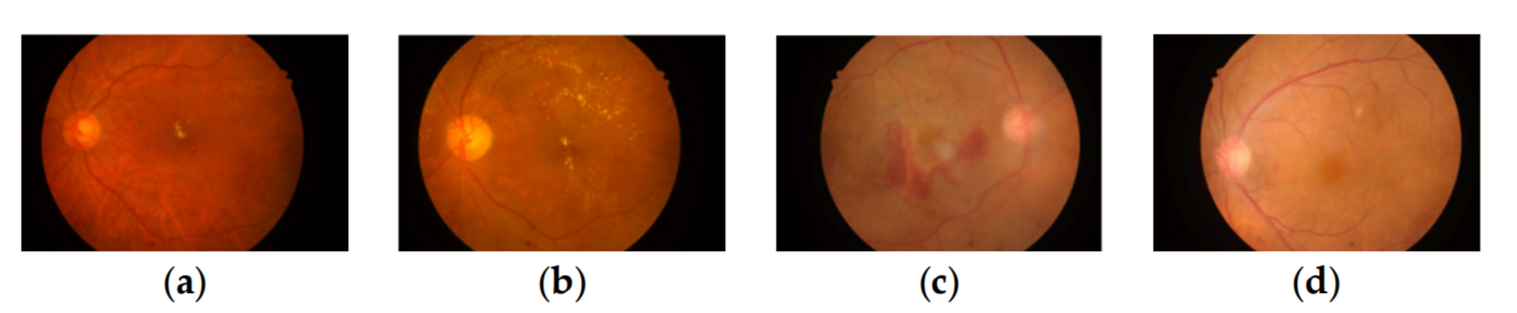
Figure 2. Example images of the degree of DR and DME pathology, (a,b) labeled DR2 DME2, (c,d) labeled DR4 DME0. (a) DR2 DME2; (b) DR2 DME2; (c) DR4 DME0; (d) DR4 DME0.
The study of DR and DME auto-grading based on deep learning has also evolved with the development of convolutional neural networks(CNN). A CNN-based model was first proposed by Pratt et al. [5] to classify the five-level of DR, where they used a class-weighting strategy to update the parameters of each batch during backpropagation to compensate for the class imbalance in the dataset and reduce overfitting. The model designed by Gargeya and Leng [6] had five residual blocks, which first extracted fundus lesion features and then fed the extracted features into a decision tree for secondary classification with and without lesions. Gulshan et al. [7] used the pre-trained InceptionV3 model on the ImageNet [8] dataset to perform DR classification. Zhang et al. [9] built a high-quality dataset and performed two and four classifications for DR by using an integrated model. Li et al. [10] proposed an integrated algorithm based on multiple improved Inception-v4 for DR lesion detection on retinal fundus images. Wang Z et al. [11] proposed a CNN-based method to simultaneously diagnose DR lesions and highlight suspicious areas. Lin et al. [12] designed an attention fusion-based network with better noise immunity for DR grading, which fused the lesion features by CNN and color fundus images for 5-level DR grading. Zhou Y et al. [13] used a semi-supervised learning method to improve the performance of DR grading and lesion segmentation through collaborative learning.
2. Multi-Task Learning
3. Multi-Branch Network
To extract richer feature information, more and more multi-branching network models have been designed and achieved better results. Hao P et al. [26] proposed a multi-branch fusion network for screening MI in 12 lead electrocardiogram images, and the results showed that the proposed method had a good effect. J Zhuang [27] proposed a network called LadderNet for retinal vessel segmentation, which was based on a multi-branch structure.LadderNet had multiple branches consisting of encoders and decoders. Compared with other advanced methods, its segmentation effect was better than other methods. Yang Z et al. [28] proposed a multi-scale convolutional neural network integration (EMS-Net) to classify breast histopathology microscopy images into four categories. The model first converted each image into multiple scales, and then fine-tuned the pre-trained DenseNet-161, ResNet-152, and ResNet-101 at each scale, respectively, and finally used them to form an integrated model. This algorithm was tested on the BACH Challenge dataset, and achieved accuracy levels of 90.00% and 91.75%, respectively.
4. Attention Mechanism
Bahdanau D et al. [29] first used the attention mechanism (AM) for machine translation, and it is now an important part of most deep-learning network designs. AM is mostly applied in models used for medical image studies to extract useful features and ignore distracting information. Sinha A et al. [30] designed a medical image segmentation model based on self-directed attention. This method could combine local features with respective global relations to highlight interdependent channel maps. The results show that the model effectively improved the accuracy of segmentation. Cai [31] proposed an improved version of Unet based on a multi-scale attention mechanism for medical image segmentation (MA-Unet). MA-Unet used attention gates (AG) to fuse local features with corresponding global relations, which could attenuate the semantic ambiguity caused by skip-join operations. Compared with other advanced segmentation networks, this model had better segmentation performance and less number of parameters. Valanarasu J et al. [32] proposed a gated attention-based model for medical image segmentation. The model extended the existing architecture by introducing additional control mechanisms in the self-attention module. The segmentation performance was tested on three different datasets and the evaluation results prove that the proposed model was superior to other segmentation models.
This entry is adapted from the peer-reviewed paper 10.3390/app14010138