Your browser does not fully support modern features. Please upgrade for a smoother experience.
Please note this is an old version of this entry, which may differ significantly from the current revision.
Subjects:
Automation & Control Systems
In modern logistics, the box-in-box insertion task is representative of a wide range of packaging applications, and automating compliant object insertion is difficult due to challenges in modelling the object deformation during insertion. Using Learning from Demonstration (LfD) paradigms, which are frequently used in robotics to facilitate skill transfer from humans to robots, can be one solution for complex tasks that are difficult to mathematically model.
- box-in-box insertion
- compliant insertion
- Learning from Demonstration
1. Introduction
Modern logistics require box-in-box insertion for a broad range of packaging tasks involving compliant, cardboard boxes. Industries such as electronics and cosmetics heavily rely on such box packaging. Typically, smaller boxes containing a product are stacked and placed into larger boxes for transportation. However, these tasks are often carried out manually on the factory floor, leading to drawbacks such as fatigue, limited operational time, and time consumption due to the repetitive and monotonous nature of the work. To overcome these challenges, there is a need for robot automation solutions to perform these tasks. Given that most industrial products are packaged in cuboid-shaped boxes, the problem at hand can be described as ‘developing an autonomous system that can perform compliant box-in-box insertion, wherein a cuboid box made of a flexible material is inserted into another larger box made of a similar deformable material’ (see Figure 1).
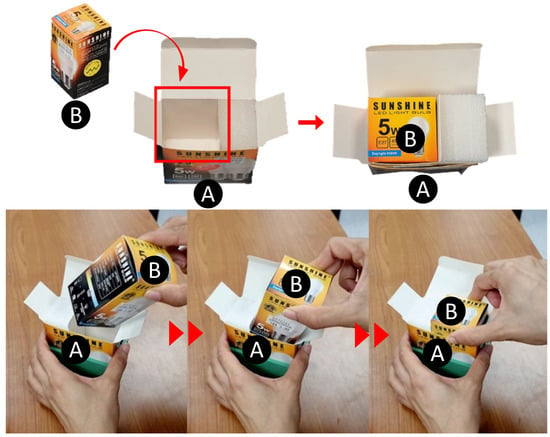
Figure 1. Example of a compliant box-in-box insertion where a folding carton (box B) containing an electric light bulb is to be inserted into a receptacle folding carton (box A). Manual insertion performed by a human (bottom).
Nonetheless, autonomous insertion is a heavily researched field in robotics, especially in the classical peg-in-hole assembly problem [1]. The existing approaches fall into contact model-based and contact model-free approaches [2]. While the former covers techniques based on the contact state modelling between the parts, the latter focuses on learning paradigms such as Learning from Demonstration and Reinforcement Learning. Contact state modelling is known to be sensitive to uncertainties such as the elasticity of the system. A model-free strategy like Learning from Demonstration looks more promising given that the task in question requires compliant objects because humans’ superior sensory systems and decision-making skills enable them to accomplish insertion tasks even under uncertain environments.
While various research has attempted automated assembly in the past, the focus has frequently been on peg-in-hole insertion dealing with rigid objects because it is the basis of many assembly operations. To avoid the damage or wear of such objects, however, some compliance has been introduced through the use of force-guided robotic systems [3] combined with various other techniques, such as the use of machine learning [4] and vision [5], for example. Another simple approach used to safely manipulate objects with ease is to operate the manipulator in velocity control mode [6], which can then be translated to joint torques using the computed torque control method, as performed in [7], to introduce the desired compliance during manipulation. While several works take advantage of active interaction controls such as impedance/admittance control [8], compliance control [9], and hybrid force/position control [10], some other works also focus on utilising grasp planning [11] and soft grippers [12,13] to mimic the compliance of human fingers to reduce the effects of localisation uncertainties [7].
2. Learning from Demonstration and Teleoperation
Learning from Demonstration (LfD) is a policy learning approach that involves a human demonstrator performing/demonstrating a task that is to be imitated by a robot [14]. This technique ends the need for a non-expert robot user to learn how to manually program for a task, as maybe required by other assembly task implementations such as in [15]. Learning from Demonstration can be implemented on robots in several ways, of which the most common ones are kinesthetic teaching [16], teleoperation [17,18], vision-sensing [19,20,21], and the use of wearable sensors.
The datasets gathered from these demonstrations consist of task execution skills acquired from humans. These skills are then extricated (learnt) with the help of different techniques for the task to be performed by the robot [16]. One such commonly used technique is the Hidden Markov Model (HMM) [22,23], which is a robust probabilistic method to encode the spatial and temporal variabilities of human motion across various demonstrations [24] as a sequence of states. These states are defined as separate Gaussian Mixture Models (GMM) to explain the input data [25]. Ref. [23] compared the use of the HMM and Gaussian Mixture Regressions (GMR) approach vs. another, more popular Dynamic Movement Primitive (DMP) technique to allow robots to acquire skills through imitation. DMPs are basically units of action in terms of attractor dynamics of non-linear differential equations that encode a desired movement trajectory [26]. This method allows one to learn a control policy for a task from the demonstrations provided. However, standard DMP learning is prone to existing noise in human demonstrations [27].
It was also concluded by [23] that in the context of separated learning and reproduction, the HMM was more systematic in generalising motion than DMP. It allowed the demonstrator to provide partial demonstrations for a specific segment of the task instead of repeating the whole task again. This is an important feature when the aim is to refine one part of the movement.
Another study by [28], on the robotic assembly of mixed deformable and rigid objects, leveraged the use of haptic feedback with position and velocity controlled robots to make them compliant without explicitly engaging joint torque control. This information was integrated into a reinforcement learning (RL) framework as the insertion hole was smaller than the peg in diameter and was deformable. Thus, the contact mechanics for it were unknown, making it difficult to design a feedback control law. However, the lack of a vision system in their setup caused the insertion to sometimes fail. Another limitation of this method was that it only worked when the peg was relatively close to the hole. Research about automatic control helps with designing adaptive control [29,30] in cases where the peg position is different. Several other works utilising RL to adapt to varying dynamics of the environment during contact-rich robotic manipulation of non-rigid, deformable objects were reviewed by [31].
While the HMM and RL are widely used techniques for encoding task trajectories. RL requires a large dataset of demonstrations for training, which is an issue when there are time constraints, and the HMM method works by interpolating between discrete sets which are unsuitable for the continuous process of encoding tasks [32]. Also, the HMM relies on the proper choice of gains for stability, which requires estimating perturbations and the range of initial positions that the system can handle in advance, which can lead to inaccuracies [23].
The GMM is a probabilistic method that is simple and robust enough for skill learning at the trajectory level. It enables the extraction of all trajectory constraints [16,21]. A combination of the GMM and GMR has been used to encode and generalise trajectories in previous independent works, such as [21,22,33]. The work by [22] presented a Learning by Demonstration framework for extracting different features of various manipulation tasks taught to a humanoid robot via kinesthetic teaching. The collected data were first projected onto a latent space for dimensionality reduction through the Principal Component Analysis (PCA) technique. Then, the signals were temporally aligned using the Dynamic Time Warping (DTW) approach for probabilistic encoding in GMMs. Ref. [21] made use of GMMs to encode upper-body gesture learning through the use of vision sensors and generalised the data through GMR.
While the GMM has been used to encode the training data for box-in-box insertion tasks, the proposed framework introduces a novel generalisation method based on GMR in Barycentric coordinates. Barycentric coordinates are commonly used in computer graphics and computational mechanics to represent a point inside a simplex as an affine combination of all of its vertices. This technique can be generalised to arbitrary polytopes [34] and is implemented in the generalisation approach of the training datasets. GMR is used to learn the robot trajectories that were demonstrated to the robot by the human operator and encoded by Gaussians. Regression makes it possible to retrieve a smooth signal analytically [22].
To perform human demonstrations of contact tasks like box-in-box assembly, it is important to consider how the task forces are being recorded and, more importantly, separated from the human forces acting on the system. Traditional kinesthetic teaching [35], i.e., by a human directly interacting with a robot and physically guiding it through the contact task, would result in the recording of the human forces coupled with the contact task forces. It is difficult to isolate the contact task forces only to perform force control later when generalising. One way to achieve this is to use two robots coupled through teleoperation control [36] so that the human interacts with the master robot and the slave robot deals with the contact task forces. Here, the term ‘Master-Slave’ simply means that the slave robot follows the motion of the master robot in the joint space. That is, to perform a task in a remote fashion, the human operator physically guides the master robot, thereby controlling the action of the slave robot which is in direct interaction with the environment. In fact, one of the first applications of teleoperation control was manipulation, specifically to handle radioactive materials from a safe distance in nuclear research [37].
For contact-rich tasks such as tight tolerance insertion, haptic feedback improves performance in the manipulation of remote objects [38]. Sensing in force-based teleoperation can be implemented through two possibilities: (a) a force/torque sensor attached to the flange of the robot to sense the end-effector forces and (b) a torque sensor built into every manipulator joint itself [39]. The latter approach was preferred due to the expensive nature of standalone six-axis F/T sensors. Instead, the robot construction was performed with strain gauges at every joint of an industrial robot manipulator [40]. Instead of using explicit force-control to track the contact task haptics, the teleoperation’s impedance characteristics are used to capture the forces that the slave should exert on the environment. This is inherent in the master kinematics and is a key aspect of the proposed approach, which allows for an open-loop playback of the assembly demonstrations given the task conditions do not change.
This entry is adapted from the peer-reviewed paper 10.3390/s23218721
This entry is offline, you can click here to edit this entry!