Your browser does not fully support modern features. Please upgrade for a smoother experience.
Please note this is an old version of this entry, which may differ significantly from the current revision.
Audio recording in classrooms is a common practice in educational research, with applications ranging from detecting classroom activities to analyzing student behavior.
- neural networks
- noise detection
- noise filtering
1. Introduction
Noise in audio recordings is a persistent problem that can significantly hinder the analysis and interpretation of collected data. This issue is particularly pronounced in noisy environments like classrooms, where a variety of noise sources can interfere with the recording quality [1]. These noises can come from a variety of sources, including background student chatter, classroom ambient noise, and heating and cooling system noise. The unpredictable nature of these noise sources makes their removal from recordings a challenge [2].
To address these challenges, we have implemented the use of a lavalier microphone carried by the teacher, specifically designed to capture the teacher’s speech. This microphone transmits via a UHF signal to a cell phone placed at the back of the classroom. Employing this method ensures the teacher’s talk is predominantly recorded, mitigating privacy concerns as the cell phone mic could inadvertently record both audio and video of students. Furthermore, this setup synchronizes all recordings on a single device. This contrasts with previous studies that recorded video and audio separately and then had to synchronize them, a non-trivial task due to inadvertent interruptions. Researchers use the UHF signal to avoid consuming wifi bandwidth, which is scarce in classrooms. However, the signal can occasionally be interrupted when the teacher moves around the classroom, and it can also occasionally introduce noise. In addition to this, the teacher could carry the necessary equipment in a carry-on bag and could take them to other classrooms and even to other schools. This practical and inexpensive solution was key to achieving the scale of recordings we were able to obtain.
Classrooms are inherently complex and noisy environments due to the nature of the activities carried out in them. Students may be talking amongst themselves, teachers may be giving instructions, and there may be background noise from class materials and other equipment. The presence of multiple speakers and poor acoustics further complicates the process of noise reduction and speaker identification [1].
Collaborative learning environments can be particularly challenging when it comes to speaker identification in noisy audio recordings [2]. In these contexts, the task of identifying individual students speaking in small clusters amidst other simultaneous conversations becomes exceptionally complex. This difficulty underscores the demand for efficient strategies in detecting and filtering noise in classroom recordings. Despite these challenges, the development of advanced techniques such as deep learning and neural networks has shown promise in improving noise detection and filtering in classroom recordings [3][4][5].
A significant issue in classrooms arises when background noises are too similar to the teacher’s voice, making it challenging for a simple audio enhancement to filter out the noise from the voice. When attempting to use a state-of-the-art automatic transcriber like Whisper [6], researchers encountered not only regular transcription issues but also hallucinations that generated entirely fabricated sentences unrelated to the context of the recording (Figure 1).
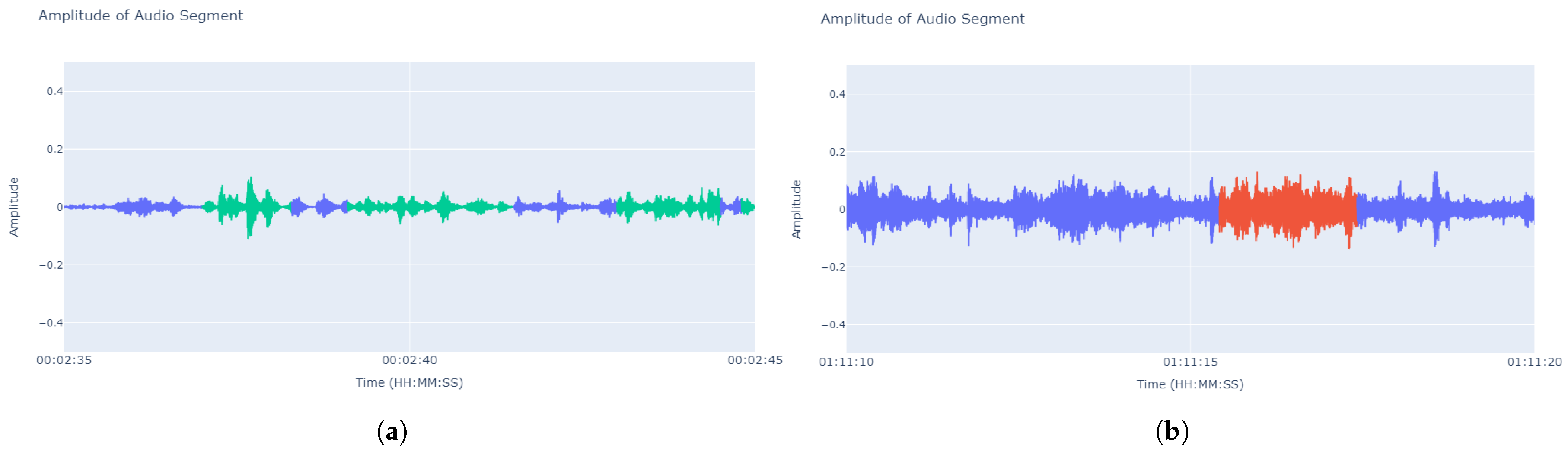
Figure 1. Sound amplitude graph of audio segments belonging to the same lesson both are 10 s long. It can be seen that the noise that produces hallucinations reaches the same volume level as the teacher’s speech level, which makes it difficult to separate it from the teacher’s speech. (a) Audio segment where the transcriber had no problem identifying what the professor said and when he said it (The professor’s speech in green). (b) Segment with significant noise where the teacher barely spoke, almost indistinguishable from the room’s noise. The transcription associated with the timestamp in red in the image is actually a hallucination that said “Ella es trabajecita, díganme cuánto pueden llegar a casa”. (She is a little worker, tell me how much they can get home).
In other instances, phrases like “Voy a estar en la iglesia!” (“I’ll be at the church!”) or “Se pide al del cielo y le ayuda a la luz de la luz”. (“He asks the one from the sky and he helps with the light of the light”.) appeared out of nowhere (in non-talking segments) in a mathematics class, contaminating any analysis of the content of those audio segments.
While some studies have explored multimodal methods for speaker identification using both visual and acoustic features [7], the focus of this research is solely on acoustic features. The goal is to leverage the power of neural networks to detect and filter the best-quality audio segments from classroom recordings, without the need for visual cues or enhancements to the audio during recording.
Moreover, while speech enhancement and inverse filtering methods have shown promise in improving speech intelligibility in noisy and reverberant environments [8], the aim is not to improve the audio during recording. Instead, the focus is on post-recording, using a simple, low-cost recording setup such as a teacher’s mobile phone. The proposed algorithm does not enhance the audio but selects the best-quality audio segments for transcription. This approach not only facilitates the creation of high-quality datasets for speech enhancement models but also improves the transcriptions. By avoiding the transcription of intervals with higher noise levels, it reduces hallucinations and achieves improvements that cannot be obtained by merely adjusting the parameters of transcription tools like Whisper.
2. Audio Segments in Classroom Automatic Transcription
Sound detection, and particularly the identification of noises from various sources, has as many applications as varied as the places where these noises can be found.
Of notable mention is the work by Sabri et al. [9], who in 2003 developed an audio noise detection system using the hidden Markov model (HMM). They aimed to classify aircraft noise with an 83% accuracy, using 15 training signals and 28 testing signals. The system combined linear prediction coefficients with cepstrum coefficients and employed vector quantization based on fuzzy C-mean clustering. This pioneering work, developed before the significant expansion of neural networks in noise detection, has influenced many environments and could even extend to settings such as classrooms.
Another significant work around noise detection was developed by Rangachari and Loizou [10], who proposed a noise-estimation algorithm for highly non-stationary environments, such as a classroom or a busy street, where noise characteristics change rapidly. The algorithm updates the noise estimate using a time-frequency dependent smoothing factor, computed based on the speech-presence probability. This method adapts quickly to changes in the noise environment, making it suitable for real-time applications. The algorithm was found to be effective when integrated into speech enhancement, outperforming other noise-estimation algorithms, and has potential applications in improving the quality of speech communication in noisy settings.
In the domain of voice activity detection (VAD), the influential study by Zhang and Wu [4] stands out for its pioneering approach to addressing the challenges of real-world noisy data. Their research introduces a methodology based on denoising deep neural networks (DDNNs) for VAD, capitalizing on the network’s ability to learn robust features amidst noise. Unlike many traditional systems that lean on clean datasets, this method emphasizes unsupervised denoising pre-training, followed by supervised fine-tuning. This design ensures the model adeptly adapts to real-world noisy data. Once the network undergoes pre-training, it is fine-tuned to mimic the characteristics of clean voice signals. The essence of this approach is its adaptability and proficiency in real-world scenarios, showcasing significant enhancement in voice activity detection amidst noise.
In the realm of polyphonic sound event detection, the work by Çakır et al. [11] stands out for its innovative approach using multi-label deep neural networks (DNNs). The study was aimed at detecting multiple sound events simultaneously in various everyday contexts, such as basketball matches and busy streets, where noise characteristics are complex and varied. The proposed system, trained on 103 recordings from 10 different contexts, totaling 1133 min, employed DNNs with 2 hidden layers and log Mel-band energy features. It outperformed the baseline method by a significant margin, offering an average increase in accuracy of 19%. The adaptability and effectiveness of this method in handling polyphonic sound detection make it a valuable contribution to the field of noise detection. It emphasizes the potential of DNNs in accurately identifying noises from various sources and sets a precedent for future research in enhancing real-time audio communication in noisy environments.
The paper by Dinkel et al. [12] proposes a cutting-edge method that overcomes the difficulties of actual noisy data in the rapidly changing environment of Voice Activity Detection (VAD). Their study provides a teacher-student model for VAD that is data-driven and uses vast, unrestricted audio data for training. This approach only requires weak labels, which are a form of supervision where only coarse-grained or ambiguous information about the data are available (e.g., a label for an entire audio clip rather than precise frame-by-frame annotations) during the teacher training phase. In contrast, many conventional systems rely extensively on clean or artificially noised datasets. A student model on an unlabeled target dataset is given frame-level advice by the teacher model after it has been trained on a source dataset. This method’s importance rests in its capacity to extrapolate to real-world situations, showing significant performance increases in both artificially noisy and real-world settings. This study sets a new standard for future studies in this field by highlighting the potential of data-driven techniques in improving VAD systems, particularly in settings with unexpected and diverse noise characteristics.
An interesting approach can be found in the work of Rashmi et al. [13], where the focus is on removing noise from speech signals for Speech-to-Text conversion. Utilizing PRAAT, a phonetic tool, the study introduces a training-based noise-removal technique (TBNRT). The method involves creating a noise class by collecting around 500 different types of environmental noises and manually storing them in a database as a noise tag set. This tag set serves as the training data set, and when input audio is given for denoising, the corresponding type of noise is matched from the tag set and removed from the input data without tampering with the original speech signal. The study emphasizes the challenges of handling hybrid noise and the dependency on the size of the noise class. The proposed TBNRT has been tested with various noise types and has shown promising results in removing noise robustly, although it has limitations in identifying noise containing background music. The approach opens up possibilities for future enhancements, including applications in noise removal stages in End Point Detection of continuous speech signals and the development of speech synthesis with emotion identifiers.
A significant contribution to this field is the work by Kartik and Jeyakumar [14], who developed a deep learning system to predict noise disturbances within audio files. The system was trained on 1,282,239 training files, and during prediction, it generates a series of 0 s and 1 s in intervals of 10 ms, denoting the ‘Audio’ or ‘Disturbance’ classes (Total of 3 h and 33 min). The model employs dense neural network layers for binary classification and is trained with a batch size of 32. The performance metrics, including training accuracy of 90.50% and validation accuracy of 83.29%, demonstrate its effectiveness. Such a system has substantial implications in preserving confidential audio files and enhancing real-time audio communication by eliminating disturbances.
In the realm of speech enhancement and noise reduction, the work of Yan Zhao et al. [15] in “DNN-Based Enhancement of Noisy and Reverberant Speech” offers a significant contribution. Their study introduces a deep neural network (DNN) approach to enhance speech intelligibility in noisy and reverberant environments, particularly for hearing-impaired listeners. The algorithm focuses on learning spectral mapping to enhance corrupted speech by targeting reverberant speech, rather than anechoic speech. This method showed promising results in improving speech intelligibility under certain conditions, as indicated by preliminary listening tests. The DNN architecture employed in their study includes four hidden layers with 1024 units each, using a rectified linear function (ReLU) for the hidden layers and sigmoidal activation for the output layer. The algorithm was trained using a mean square error loss function and employed adaptive gradient descent for optimization. Objective evaluation of the system using standard metrics like short-time objective intelligibility (STOI) and the perceptual evaluation of speech quality (PESQ) demonstrated significant improvements in speech intelligibility and quality. This research aligns well with the broader objectives of enhancing audio quality in challenging acoustic environments with a specific focus on aiding hearing-impaired listeners.
In a similar vein to the previously discussed works, the study conducted by Ondrej Novotny et al. [16] presents a noteworthy advance in the field of speech processing. This research delves into the application of a deep neural network-based autoencoder for enhancing speech signals, particularly focusing on robust speaker recognition. The study’s key contribution is its approach to using the autoencoder as a preprocessing step in a text-independent speaker verification system. The model is trained to learn a mapping from noisy and reverberated speech to clean speech, using the Fisher English database for training. A significant finding of this study is that the enhanced speech signals can notably improve the performance of both i-vector and x-vector based speaker verification systems. Experimental results show a considerable improvement in speaker verification performance under various conditions, including noisy and reverberated environments. This work underscores the potential of DNN-based signal enhancement in enhancing the accuracy and robustness of speaker verification systems, which complements the objectives of this study that focus on improving classroom audio transcription through neural networks.
In a noteworthy parallel to the realm of audio signal processing for educational purposes, the research conducted by Coro et al. [17] explores the domain of healthcare simulation training. Their innovative approach employs syllabic-scale speech processing and unsupervised machine learning to automatically highlight segments of potentially ineffective communication in neonatal simulation sessions. The study, conducted on audio recordings from 10 simulation sessions under varied noise conditions, achieved a detection accuracy of 64% for ineffective communication. This methodology significantly aids trainers by rapidly pinpointing dialogue segments for analysis, characterized by emotions such as anger, stress, or misunderstanding. The workflow’s ability to process a 10-min recording in approximately 10 s and its resilience to varied noise levels underline its efficiency and robustness. This research complements the broader field of audio analysis in challenging environments by offering an effective model for evaluating human factors in communication, which could be insightful for similar applications in educational settings, paralleling the objectives of enhancing audio transcription accuracy in classroom environments.
This entry is adapted from the peer-reviewed paper 10.3390/app132413243
References
- Li, H.; Wang, Z.; Tang, J.; Ding, W.; Liu, Z. Siamese Neural Networks for Class Activity Detection. In Artificial Intelligence in Education. AIED 2020; Bittencourt, I., Cukurova, M., Muldner, K., Luckin, R., Millán, E., Eds.; Lecture Notes in Computer, Science; Springer: Cham, Switzerland, 2020; Volume 12164.
- Li, H.; Kang, Y.; Ding, W.; Yang, S.; Yang, S.; Huang, G.Y.; Liu, Z. Multimodal Learning for Classroom Activity Detection. In Proceedings of the ICASSP 2020—2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; pp. 9234–9238.
- Cosbey, R.; Wusterbarth, A.; Hutchinson, B. Deep Learning for Classroom Activity Detection from Audio. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 3727–3731.
- Zhang, X.-L.; Wu, J. Denoising Deep Neural Networks Based Voice Activity Detection. arXiv 2013, arXiv:1303.0663.
- Thomas, S.; Ganapathy, S.; Saon, G.; Soltau, H. Analyzing Convolutional Neural Networks for Speech Activity Detection in Mismatched Acoustic Conditions. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Florence, Italy, 4–9 May 2014; IEEE: Piscataway, NJ, USA, 2014; pp. 2519–2523. Available online: https://api.semanticscholar.org/CorpusID:1646846 (accessed on 24 October 2023).
- Radford, A.; Kim, J.; Xu, T.; Brockman, G.; McLeavey, C.; Sutskever, I. Robust Speech Recognition via Large-Scale Weak Supervision. In Proceedings of the 40th International Conference on Machine Learning, Honolulu, HI, USA, 23–29 July 2023.
- Ma, Y.; Wiggins, J.B.; Celepkolu, M.; Boyer, K.E.; Lynch, C.; Wiebe, E. The Challenge of Noisy Classrooms: Speaker Detection during Elementary Students’ Collaborative Dialogue. Lect. Notes Artif. Intell. 2021, 12748, 268–281.
- Dong, H.-Y. Speech intelligibility improvement in noisy reverberant environments based on speech enhancement and inverse filtering. EURASIP J. Audio Speech Music Process. 2018, 2018, 3.
- Sabri, M.; Alirezaie, J.; Krishnan, S. Audio noise detection using hidden Markov model. In Proceedings of the IEEE Workshop on Statistical Signal Processing, St. Louis, MO, USA, 28 September–1 October 2003; pp. 637–640.
- Rangachari, S.; Loizou, P.C. A noise estimation algorithm with rapid adaptation for highly nonstationary environments. In Speech Communication; Elsevier: Amsterdam, The Netherlands, 2006; pp. 220–231.
- Çakır, E.; Heittola, T.; Huttunen, H.; Virtanen, T. Polyphonic sound event detection using multi label deep neural networks. In Proceedings of the International Joint Conference on Neural Networks (IJCNN), Killarney, Ireland, 12–17 July 2015; pp. 1–7.
- Dinkel, H.; Wang, S.; Xu, X.; Wu, M.; Yu, K. Voice Activity Detection in the Wild: A Data-Driven Approach Using Teacher-Student Training. IEEE/ACM Trans. Audio Speech Lang. Process. 2021, 29, 1542–1555.
- Rashmi, S.; Hanumanthappa, M.; Gopala, B. Training Based Noise Removal Technique for a Speech-to-Text Representation Model. J. Phys. Conf. Ser. 2018, 1142, 012019.
- Kartik, P.; Jeyakumar, G. A Deep Learning Based System to Predict the Noise (Disturbance) in Audio Files. In Advances in Parallel Computing; IOS Press: Amsterdam, The Netherlands, 2020; Volume 37, ISBN 9781643681023.
- Zhao, Y.; Wang, D.; Merks, I.; Zhang, T. DNN-based enhancement of noisy and reverberant speech. In Proceedings of the 2016 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Shanghai, China, 20–25 March 2016; pp. 6525–6529.
- Novotný, O.; Plchot, O.; Glembek, O.; Černocký, J.H.; Burget, L. Analysis of DNN Speech Signal Enhancement for Robust Speaker Recognition. Comput. Speech Lang. 2019, 58, 403–421.
- Coro, G.; Bardelli, S.; Cuttano, A.; Fossati, N. Automatic detection of potentially ineffective verbal communication for training through simulation in neonatology. Educ. Inf. Technol. 2022, 27, 9181–9203.
This entry is offline, you can click here to edit this entry!