Your browser does not fully support modern features. Please upgrade for a smoother experience.
Please note this is an old version of this entry, which may differ significantly from the current revision.
With the rapid development of wireless communication technology, intelligent communication has become one of the mainstream research directions after the fifth generation (5G). In particular, deep learning has emerged as a significant artificial intelligence technology widely applied in the physical layer of wireless communication for achieving intelligent receiving processing. Channel estimation, a crucial component of physical layer communication, is essential for further information recovery.
- channel estimation
- deep learning
- wireless communication
- physical layer
1. Introduction
Deep learning is transforming the paradigms and methods of physical layer communications, with application areas including channel estimation, resource allocation, and signal detection [1][2]. Conventional channel estimation methods work well in systems with a clear and linear representation of the input–output relationship. However, when the wireless environment becomes more complicated, the input–output relationship exhibits nonlinear characteristics, potentially reducing the effectiveness of conventional techniques. Deep learning aims to enable machines to learn to deal with complex and highly nonlinear relationships between input datasets and desired outputs without human intervention [3].
2. Neural Networks
As a branch of artificial intelligence technology, deep learning uses neural networks as models, so it is necessary to briefly introduce neural networks before introducing deep-learning-based channel estimation methods. Neural networks, which mimic the neuronal network of the human brain, consist of input, hidden, and output layers with numerous interconnected neurons through the weights in each layer. By adjusting these weights through learning, neural networks can process input information and produce output. According to the application of deep learning in various fields, the structure of the basic network is different, primarily including the deep neural network (DNN), convolutional neural network (CNN), recurrent neural network (RNN), generative adversarial network (GAN), etc. Most deep learning models can be combined or optimized based on these four networks.
2.1. DNN
A basic structure of DNN is shown in Figure 1, which consists of one input layer, L hidden layers, and one output layer, with several neurons in each layer and full connectivity between layers. A DNN can be considered a neural network that contains numerous hidden layers, and the purpose of adding multiple hidden layers is to enhance the learning and mapping capabilities of the network. Additionally, to introduce the nonlinearity, activation functions like the sigmoid, rectified linear unit (ReLU), or hyperbolic tangent (Tanh) are applied after the outputs of each layer.
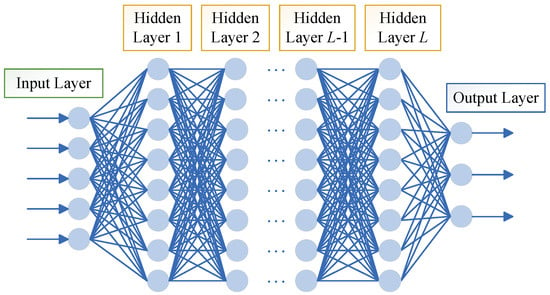
Figure 1. Basic structure of DNN.
2.2. CNN
CNN is among the most representative model structures for deep learning, with the earliest proposition dating back to the publication of the seminal literature [4]. Figure 2 shows a basic CNN structure comprising an input layer, multiple convolutional and pooling layers, a fully connected layer, and an output layer. The input layer’s primary function is to preprocess the data. After this, the convolutional layer extracts features from the processed data, and its output is then mapped nonlinearly via the activation function. Following this, the pooling layer is introduced to decrease computation and prevent overfitting. The convolutional and pooling layers are alternately stacked, and after a series of operations, the output is obtained through the fully connected and output layers. In the convolutional layer, the convolutional kernel is locally connected to its input feature map. For each position in the output feature map, the value is obtained by the weighted sum of the local inputs and connection weights, plus the bias. As this process is equivalent to the convolutional operation, the network is termed a convolutional neural network.
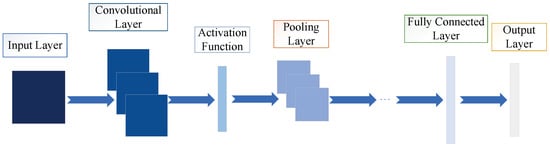
Figure 2. Basic structure of CNN.
2.3. RNN
Figure 3 shows a basic RNN structure. In contrast to the previously discussed DNN and CNN, RNN is uniquely designed to handle sequential data. It can remember information from past moments and utilize it for the current output calculation. In this case, the nodes among the hidden layers are interconnected. Moreover, the hidden layer’s input depends on both the input layer’s value and the hidden layer’s output from the previous moment.
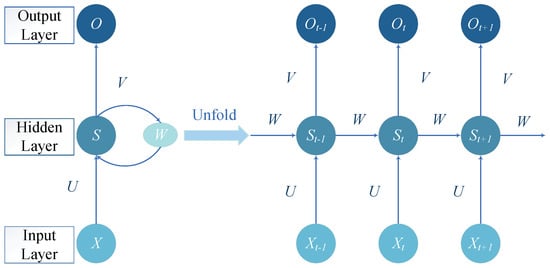
Figure 3. Basic structure of RNN.
During the training process, RNNs may suffer from long-term dependency, leading to gradient vanishing or gradient explosion. Therefore, the literature [5] conducted further research and proposed a special RNN called the long short-term memory (LSTM) network to effectively resolve this issue.
2.4. GAN
Figure 4 represents the general GAN structure, which consists of a generator and a discriminator. The generator receives a latent vector (usually random noise) as input and generates samples analogous to the training data. On the other hand, the discriminator receives samples (which can be real or generated by the generator) as input and predicts their veracity. Notably, the generator and the discriminator train against each other in a competitive and collaborative dynamic. Specifically, the generator’s objective is to trick the discriminator by bringing the generated samples closer and closer to the real samples to the point where they cannot be distinguished accurately. Concurrently, the discriminator is tasked with accurately classifying the samples as possible, thereby heightening the distinction between the real and generated samples. During the iterative adversarial training process, the generator and the discriminator keep adjusting their parameters until they reach an equilibrium point. That is to say, the generator can generate realistic samples, while the discriminator cannot distinguish between real and generated samples.
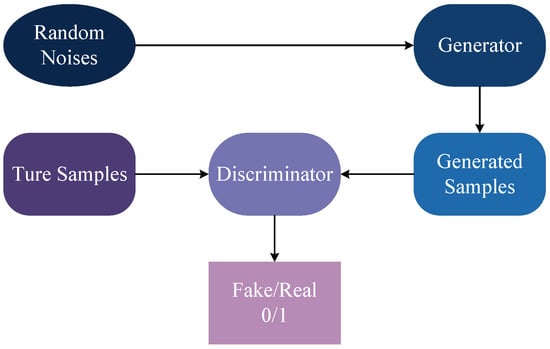
Figure 4. Basic structure of GAN.
3. Toy Example of Deep Learning Application in Channel Estimation
This simulation is set in a vehicular communication scenario within an OFDM system that conforms to the IEEE 802.11p standard. In this environment, the channel exhibits time-varying characteristics, and there is a strong correlation between adjacent OFDM symbols. The classic LS algorithm, performed based on two preambles in an OFDM frame, struggles to track rapid changes in the channel, resulting in poor performance. In contrast, the constructed data pilot (CDP) algorithm constructs virtual pilots from data subcarriers and uses the correlation between adjacent OFDM symbols. It treats the data subcarriers of the previous symbol as a preamble to conduct the current symbol’s channel estimation. This algorithm somewhat improves the channel estimation performance but reduces reliability due to error propagation from one symbol to the next.
Researchers used the VTV Urban Canyon (VTV-UC) channel model with a velocity setting of 48 km/h and a Doppler shift of 500 Hz. To obtain a robust DNN model, researchers trained it at a high SNR of 40 dB. Then, researchers tested it in a SNR range of 0–40 dB and compared its performance with the LS algorithm and the original CDP algorithm. Figure 5a,b display the performance comparison in terms of BER and NMSE, respectively. These results indicate that the DNN-enhanced CDP approach significantly improves the channel estimation accuracy in most scenarios. Even though the performance is not the best in a few low-SNR conditions, it still outperforms the other two traditional algorithms in general, showing the potential of deep learning in channel estimation applications.
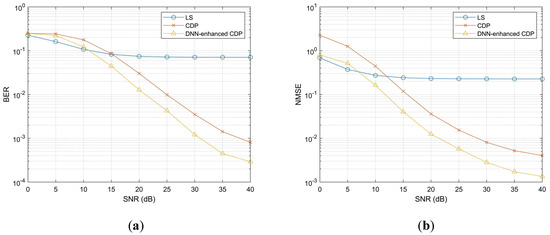
Figure 5. Performance comparison with the LS algorithm and the original CDP algorithm; (a) BER performance comparison; and (b) NMSE performance comparison.
4. Data-Driven Deep-Learning-Based Channel Estimation Methods
Figure 6 illustrates the structure of a simple channel estimator based on data-driven deep learning. The core idea of the data-driven approach is to consider neural networks as “black boxes”, replacing the original traditional communication system structure with them and perpetually updating their parameters through training with massive amounts of data.
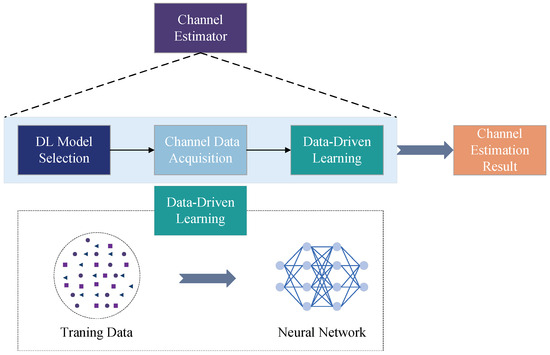
Figure 6. Structure of a data-driven deep-learning-based channel estimator.
4.1. Application of DNN in Data-Driven Channel Estimation
DNN is a fundamental network for deep learning with a simple model, and as such, it was first applied in channel estimation. It allows end-to-end learning, i.e., from the original input to the target output. Figure 7 shows a DNN-based channel estimator proposed in [6], serving as one of the typical examples. In this model, the authors estimated the CSI end-to-end by recovering the transmitted data from the received data, including the pilot and data blocks. Moreover, DNN is highly adaptable and flexible, and its structure and hyperparameters can be modified to accommodate various application scenarios.
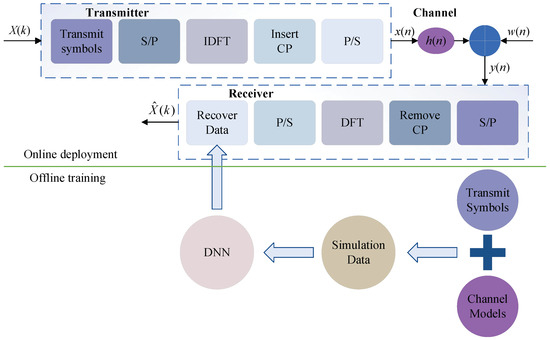
Figure 7. DNN-based end-to-end channel estimator [6].
In 2020, Ma et al. [7] investigated a DNN-based method that combines channel estimation and pilot design. The proposed DNN model is composed of a dimensionality reduction subnetwork and a reconstruction subnetwork. In the first subnetwork, the fully connected layer is designed to compress the high-dimensional channel vector into low-dimensional received measurements, and this compression process treats the weights in the layer as pilot signals. In the second subnetwork, several cascaded convolutional layers and a fully connected layer are designed to recover the high-dimensional channel. Through experimental comparison, this method exhibits a superior NMSE performance to the simultaneous orthogonal matching pursuit (SOMP) algorithm. Furthermore, when the DNN trained with multi-carrier samples is tested on single-carrier samples, and it still performs well, demonstrating its excellent generalization ability.
The interpolation approach is closely connected with the performance of the pilot-based method. In [8], Ge et al. proposed to utilize DNN to replace the interpolation process of the conventional pilot-based method. Firstly, the position index and the channel estimation result of pilot subcarriers are used as training data to train the DNN model. Then, the position index of data subcarriers is used as the input to the DNN, and the channel estimation of data subcarriers is finally obtained. This method does not require prior statistics or matrix inverse operations like the MMSE algorithm and thus has a lower complexity. Moreover, the proposed method exhibited superior estimation accuracy in experiments compared to the LS algorithm, which requires interpolation. Finally, the author tested the model trained with eight multipath paths in conditions with 4, 8, and 12 multipath paths. The BER performance remains almost unchanged, showing the excellent generalization ability of the proposed model.
In 2021, Zheng et al. [9] developed an online DNN-based channel estimation method under limited pilot conditions. This method can dynamically learn and compute in real time, inferring and updating the DNN weights from the pilot symbols received online without knowing the real channel matrix to adapt to the actual communication environment. The proposed DNN-based method exhibits the strongest robustness in experiments. Furthermore, its estimation accuracy approaches the group orthogonal matching pursuit (GOMP) algorithm and the burst LASSO algorithm while surpassing the MMSE algorithm. Significantly, it surpasses all these methods by orders of magnitude in terms of computational speed. Additionally, the proposed DNN model, trained at an SNR of 30 dB, consistently surpasses the MMSE algorithm in terms of NMSE performance when tested at lower SNR levels. Specifically, the experiments conducted on the 3GPP SCM TR 25.996 and the DeepMIMO channel models can both yield this result, demonstrating the model’s strong generalization on lower SNR.
In the realm of ocean exploration, underwater acoustic (UWA) communication is pivotal. In 2022, Zhang et al. [10] investigated a DNN-based scheme for underwater acoustic channel estimation in OFDM systems. The DNN utilizes transmitted pilots and received symbols in this scheme to reconstruct the UWA channel. Encouragingly, the scheme shows outstanding signal detection performance on the estimated channel. Simulation results demonstrate its efficacy, reducing the BER by over 40% in comparison to the LS algorithm. Furthermore, as the pilot number grows, the BER performance approaches that of the MMSE algorithm.
To improve the estimation performance in impulse noise environments, Li et al. [11] developed a method based on the denoising autoencoder-DNN (DAE-DNN). The proposed method consists of three steps: first, utilizing DAE for preprocessing, namely learning the impaired data and restoring clean received signals under conditions where impulse noise is present; second, employing the preprocessed data from DAE to train the DNN offline; and finally, the DNN estimates the CSI online. Experimental results demonstrate that this method has strong robustness under impulse noise conditions, outperforming the MMSE algorithm, the orthogonal matching pursuit (OMP) algorithm, and the LS algorithm in terms of MSE and BER.
4.2. Application of CNN in Data-Driven Channel Estimation
CNN is advantageous for channel estimation since it can reduce the computation of feature parameters and automatically select the appropriate training weights. In addition, CNN’s excellent feature extraction capability contributes to its excellent image processing performance. Hence, the channel estimation problem can be transformed into an image processing problem in the application, enabling it to learn from the training data and obtain accurate CSI. Figure 8 shows examples of transforming the channel time–frequency response into a 2D image under the Vehicular-A (VehA) channel model [12]. Specifically, Figure 8a,b represent the channel time–frequency response images under the perfect channel model without noise and the noisy channel model with an SNR of 22 dB, respectively.
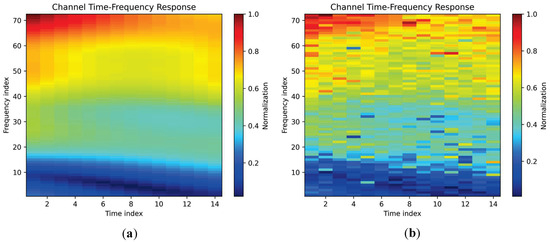
Figure 8. Two-dimensional image examples of the channel time–frequency response: (a) under the VehA perfect channel model (without noise); and (b) under the VehA noisy channel model (SNR = 22 dB).
In 2019, the ChannelNet proposed by Soltani et al. [13] with regard to the channel time–frequency response as a low-resolution 2D image and the values are only known at pilot positions. The ChannelNet consists of a super-resolution CNN (SRCNN) and a denoising CNN (DnCNN), which are cascaded into a two-step channel estimator. In the first step, the low-resolution image is enhanced into a high-resolution image by the SRCNN. In the second step, the DnCNN removes the noise effect to obtain a higher-quality image (i.e., an accurately estimated channel). Through experimental verification, the ChannelNet’s MSE performance is superior to the ALMMSE algorithm (an approximation to linear MMSE) but inferior to the MMSE algorithm in low SNR. However, the performance of ChannelNet trained at the SNR of 22 dB shows a decreasing trend when the SNR exceeds 23 dB, which indicates that its generalization ability on real noise is not good enough. Notably, this literature is a pioneer in using image processing methods for channel estimation, providing a novel idea for many subsequent studies. Inspired by this, Li et al. [14] investigated a deep residual channel estimation network (ReEsNet) based on residual learning, which can work in a wide range of scenarios and significantly reduce the complexity while improving estimation accuracy.
The numerous convolutional layers in the denoising structure (DnCNN) of ChannelNet [13] lead to a large amount of computation and a long execution time, which greatly consumes memory. For this reason, Pradhan et al. [15] made improvements and proposed the channel estimation network (CENet). Compared with ChannelNet, CENet also uses SRCNN for image resolution enhancement, with the difference that a convolutional blind denoising network (CBDNet) is used as the denoising structure instead of DnCNN. The CBDNet reduces the overall number of convolutional layers, thereby reducing the complexity of the proposed CNN model. Through experimental comparison, the CENet is superior to the ChannelNet but inferior to the ideal MMSE algorithm in terms of MSE. Furthermore, the author tested the CENet trained with 48 pilots under conditions of different numbers of pilots. The results showed that CENet maintains high performance even with fewer pilots, unlike other methods, which exhibited a significant decrease in performance under the same conditions.
Most research utilizing deep learning for channel estimation focuses on constructing complex neural networks, which leads to increased storage and computational requirements. Li et al. [16] addressed this phenomenon by combining the CNN and Transformer and proposing a lightweight channel estimation Transformer (LCET). This scheme treats the channel response matrix as a 2D image, with the channel features extracted using a lightweight feature extraction CNN (LFEC) and then transmitted to a lightweight-adjusted Transformer (LAT) for channel estimation. Through experimental comparison, the estimation accuracy of the LCET surpasses the LS algorithm and some neural networks, closely approximating the performance of LMMSE algorithms in multi-pilot scenarios.
In general, the transceiver of millimeter wave (mmWave) massive MIMO systems employs a hybrid precoding structure, and thus, the acquisition of CSI in the low SNR regime poses difficulties. To overcome this challenge, Zhao et al. [17] proposed ResNet-UNet, a network that combines the residual network (ResNet) and the U-shaped network (U-Net) for channel estimation. In particular, the proposed ResU-net consists of a denoiser and an estimator. Firstly, the received noisy pilot signal is converted into an image and processed by the denoiser. Then, the obtained clean pilot signal image is fed to the estimator to obtain the estimation result. Through experimental verification, the Res-UNet surpasses the conventional algorithms and the deep CNN in estimation accuracy and is robust to noisy environments.
In 2023, Rahman et al. [18] proposed a deep residual convolutional blind denoising network (ResCBDNet) for massive MIMO visible light communication systems to estimate more realistic and accurate CSI. The proposed ResCBDNet comprises two subnetworks: the noise estimation network and the non-blind denoising network, and it transforms the sparse channel matrix into a 2D image. Initially, the scheme employs a noise estimation network to enhance the generalization ability of the true noise. It then interactively reduces the effect of noise in the channel matrix through the adjustment of the noise level mapping. Subsequently, the noiseless estimated channel is recovered using the non-blind denoising network. Experiments demonstrate that the ResCBDnet surpasses some existing deep-learning-based methods in terms of normalized MSE (NMSE) and peak SNR (PSNR). Moreover, with its exceptional noise generalization capability, ResCBDNet demonstrates the superior MSE performance to other methods when SNR = 20 dB.
4.3. Application of RNN in Data-Driven Channel Estimation
RNN is not as widely used as other neural networks in channel estimation. However, some researchers have recently delved into RNN-based methods to improve the channel estimation accuracy. Given the time-dependent properties of RNN, it can be used for time-varying channels to improve time-series information processing. Moreover, it is especially well suited for channel estimation in high-speed mobile settings.
For high-speed mobile environments, channel estimation becomes problematic due to the impact of multipath and Doppler effects, and conventional methods perform poorly due to the limited number of available pilots. Consequently, Gizzini et al. [19] proposed a frame-by-frame (FBF) channel estimation method based on bi-directional RNN (Bi-RNN) for doubly-selective channels. The goal is to perform end-to-end 2D interpolation after estimating the channel of pilot symbols, thereby obtaining the channel estimation of data symbols. Simulation results demonstrate that the proposed Bi-RNN is robust and adaptive, and the estimation accuracy is superior to some existing deep learning schemes. Although the estimation accuracy is marginally lower than the conventional 2D-LMMSE algorithm, the complexity is reduced by nearly 106 times, making it a viable alternative.
In 2021, Essai Ali et al. [20] estimated CSI using a variant of LSTM, namely a bi-directional LSTM (Bi-LSTM) neural network. The proposed network model relies on pilot assistance, does not require prior knowledge of channel statistical information, and employs online training with offline deployment. Under the conditions of limited pilots and uncertain channel prior statistics, this model is robust and has a superior symbol error rate (SER) performance over the LSTM and the conventional algorithms (LS and MMSE). The proposed Bi-LSTM can analyze massive data and establish relationships between features, thus having excellent generalization capabilities and applicability to new datasets.
The gated recurrent unit (GRU) is a lightweight variant with potential developed from LSTM. In 2022, Essai Ali et al. [21] designed an end-to-end channel estimation method based on GRU to recover the transmitted signal from the received signal, thereby estimating the CSI. Through experimental verification, the GRU-based method surpasses the conventional estimation algorithms (LS and MMSE), DNN, and ReEsNet in terms of SER. In 2023, Helmy et al. [22] combined LSTM and GRU to develop an LSTM-GRU estimator, which is designed for channel estimation from the received signal. It consists of three parts: the LSTM, the GRU, and the smoothing module. In this framework, the LSTM serves as a minimum absolute filter that denoises the pre-processed received signals, and the GRU module compensates for the information loss in the LSTM module as a compensator. Finally, the model’s output is smoothed using batch normalization and convolutional layers. Through experimental comparison, the proposed LSTM-GRU estimator has a superior NMSE performance over the CNN and CGAN estimators. Additionally, the LSTM-GRU trained with a pilot length of 8 is tested in scenarios of varying pilot lengths. The estimation performance of this model does not degrade significantly in the short pilot length range, indicating its outstanding generalization ability.
4.4. Application of GAN in Data-Driven Channel Estimation
In channel estimation, GAN has the ability to serve by generating additional data to augment the required training dataset, which is particularly valuable in scenarios without sufficient information about the actual CSI. Moreover, GAN can adaptively improve its performance during training, thereby achieving more accurate estimation results through the adversarial process between the generator and the discriminator.
Motivated by ReEsNet in [14], Zhao et al. [23] developed a super-resolution GAN (SRGAN) for channel estimation in 2021. However, the estimation results of ReEsNet have lost high-frequency details and failed to match the desired fidelity at higher resolutions. In the SRGAN scheme, the channel generated by the generator is closer to the actual channel distribution. Meanwhile, the discriminator recovers more details, significantly enhancing the estimation accuracy. Through experimental comparison, the SRGAN’s MSE performance surpasses both the LS algorithm and the ReEsNet, and it approaches the MMSE algorithm in high SNR.
For massive MIMO systems, Dong et al. [24] investigated a CGAN channel estimator in the same year. The proposed CGAN learns how to map from quantized observations to the actual channel and learns a suitable adaptive loss function for network training, resulting in a highly robust model and a more realistic estimated channel. Even when the model is tested on a different channel (i.e., a millimeter wave channel), its performance remains almost unchanged, demonstrating its exceptional generalization capability. In 2023, Zhang et al. [25] also employed CGAN, but their focus was obtaining accurate CSI for MIMO-OFDM systems in high-speed railway scenarios. Their scheme is executed in two steps and regards the pilot signal as a 2D image. In the denoising step that employs the U-Net framework, the received noisy pilot image is denoised using the Noise2Noise (N2N) algorithm. In the estimation step, the CGAN completes the channel estimation by learning the features of the denoised pilot image. Through experimental verification, the N2N-CGAN has high estimation accuracy in high-speed mobile scenarios, exhibits strong robustness in noisy environments, and has low computational complexity.
In the pilot-based channel estimation scheme, the estimation efficacy highly depends on the pilot insertion pattern. To improve the estimation accuracy while reducing the pilot overhead, Kang et al. [26] proposed a network model called CAGAN as a channel estimation scheme for joint pilot design. The CAGAN comprises a CGAN and a concrete autoencoder (concrete AE). First, the concrete AE is used to search for the most informative location in the time–frequency grid and insert pilots here, thereby optimizing the pilot design. Next, the optimized pilots are fed into the CGAN for channel estimation. Experimental results show that the CGAN can exhibit outstanding estimation performance with a limited number of pilots. In order to verify the generalization ability of noise, the CAGANs trained with an SNR of 15 dB and trained at different SNRs are compared in a 0–30 dB SNR range. The result demonstrates that, when the SNR is above 9 dB, the performance of these two models is comparable.
5. Model-Driven Deep-Learning-Based Channel Estimation Methods
The model-driven approach is built on known mathematical models, and its central idea is to combine deep learning with conventional algorithms to improve or expand existing methods. Moreover, it does not depend on extensive labeled data to select the right standard neural network, thus making deep learning more interpretable and predictable. Figure 9 illustrates the components of the model-driven approach. Currently, most research on model-driven channel estimation primarily unfolds on the basis of the LS algorithm and the algorithms in compressive sensing (CS) that include the OMP algorithm and the approximate message passing (AMP) algorithm.
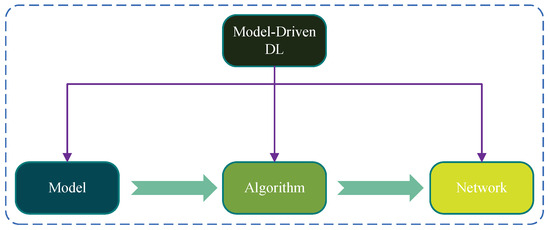
Figure 9. Components of the model-driven approach.
4.1. Model-Driven Channel Estimation Combining LS Algorithm
As previously mentioned, the conventional LS channel estimation algorithm is computationally simple but leads to poor performance since it ignores the impact of noise. The ComNet proposed by Gao et al. [27] solves the problem using deep learning networks, which provides a reference for subsequent research. As shown in Figure 10, the ComNet is constructed by cascading the channel estimation and the signal detection subnets. In the channel estimation subnet part, the authors utilized a DNN to refine the coarse estimation of the traditional LS algorithm. Specifically, the DNN takes the LS coarse estimation as input and learns from the discrepancies between this initial estimation and the actual channel. Then, the DNN adjusts its parameters through training to minimize the prediction error, resulting in a more accurate channel estimation.
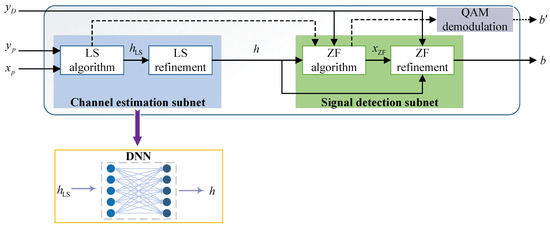
Figure 10. ComNet structure [27].
In 2021, Jiang et al. [28] introduced a dual CNN structure to improve the LS algorithm’s estimation accuracy with lower complexity than the general CNN-based methods. The initial channel estimation obtained by the LS algorithm is used as the input for the dual CNN, which consists of a spatial-frequency CNN (SFCNN) and an angle-delay CNN (ADCNN). In particular, the SFCNN effectively leverages the channel’s sparsity to process white noise, while the ADCNN utilizes the channel correlation to reduce interference. These two CNNs are connected through a discrete Fourier transform (DFT) process. Owing to the dual CNN combining the advantages of SFCNN and ADCNN, it exhibits superior NMSE performance to the single-domain CNN in experiments.
In 2023, Haq et al. [29] innovatively implemented channel estimation on a System on Chip (SoC) based on deep learning. Specifically, the authors proposed a channel estimation method called DNN-augmented LS (LSDNN) for the preamble-based OFDM physical layer. This method employs a fully connected feedforward DNN to process the LS estimation results. Specifically, the DNN uses the initial LS estimation as input, learning from its errors to improve the initial estimation. It does this by minimizing the cost function, thereby refining the LS estimation of the previous preamble. Finally, the proposed LSDNN, the LS algorithm, and the LMMSE algorithm are mapped onto a Zynq multiprocessor SoC (ZMPSoC) platform for extensive experimental comparison. Experimental results verify that the LSDNN has a superior estimation accuracy over the LS and the LMMSE algorithms. However, there is still room for improvement in resource utilization and power consumption.
To overcome the challenge of SNR mismatch in multipath time-varying channels, Li et al. [30] introduced a cascaded network called NDR-Net for channel estimation. The NDR-Net consists of a cascade of a noise level estimation subnet (NLE), a DnCNN, and residual learning, and the channel matrix is regarded as an image in this scheme. Firstly, the LS algorithm estimates the coarse value of the channel matrix, which is then inputted into NLE to obtain the noise level estimation. Subsequently, the estimated noise level and the initial noisy channel matrix image are inputted into DnCNN for noise reduction, resulting in a pure noisy image. Finally, the noiseless channel matrix image is obtained by residual learning. Through experimental comparison, the NDR-Net has better estimation accuracy than conventional methods when the SNR is mismatched. In addition, it applies to different Doppler shifts.
4.2. Model-Driven Channel Estimation Combining OMP Algorithm
As a greedy algorithm, the OMP algorithm offers optimal solutions to sparse recovery problems. Leveraging the sparsity of channels, it facilitates channel estimation with minimized pilot overhead. However, due to the grid mismatch issue, the OMP algorithm may not provide satisfactory estimation results [31]. To achieve better channel estimation performance, combining the OMP algorithm with deep learning is a viable approach.
In 2022, Li et al. [32] designed a model-driven ResNet-based scheme for orthogonal time–frequency space (OTFS) systems. Considering the sparsity of the channel in the delay-Doppler domain, they first employed the OMP algorithm to obtain a coarse estimation. Then, this initial estimation was fed into the proposed ResNet for a more accurate result. During the training process, the ResNet learns from the error between the OMP rough estimation and the actual channel response. Then, this network continuously optimizes the parameters, resulting in a more realistic channel estimation result. Compared to the conventional OMP algorithm, the ResNet-based scheme has a superior NMSE performance. Furthermore, it applies to various scenarios and displays outstanding robustness to Doppler spread.
In [33], Tong et al. introduced a two-step OMP-based channel estimation algorithm. First, a composite convolution kernel function (CKF) is constructed based on the autocorrelation matrix, which then coarsely estimates the angles of arrival/departure (AoAs/AoDs) for multipath channels. Second, a squeeze-and-excitation ResNet (SE-ResNet) utilizing the Noise2Void (N2V) algorithm is proposed to refine the AoAs/AoDs estimation. Then, the channel amplitude is estimated using the LS algorithm. Finally, the channel matrix is accurately recovered based on all the results above. In the experiments, the proposed algorithm exhibits a superior NMSE performance over the simultaneous weighted OMP (SW-OMP) algorithm, the Newtonized OMP (NOMP) algorithm, and the channel estimation neural network (CENN), while having computational complexity.
To enhance the effectiveness of the conventional OMP algorithm in hybrid-field channel estimation, Nayir et al. [34] developed a novel scheme called OMP-CAE by incorporating the convolutional autoencoder (CAE) for massive MIMO channels. In this scheme, the OMP algorithm first provides a rough channel estimation. Since the channel parameters from the OMP rough estimation contain significant errors at low SNR, they are fed into the CAE network. Then, the CAE network uses its strong denoising ability to improve the accuracy of channel estimation. Through experimental verification, the OMP-CAE surpasses the MMSE algorithm and the conventional OMP algorithm in terms of NMSE and applies to different scenarios.
4.3. Model-Driven Channel Estimation Combining AMP Algorithm
The AMP algorithm is a significant iterative algorithm that excels at recovering sparse signals. It can achieve channel estimation in sparse channel environments with low computational complexity [35]. Nevertheless, the AMP algorithm’s performance is highly dependent on certain preset parameters, and it presents a challenge to determine the optimal parameters, leading to its limited estimation performance. Therefore, some researchers have combined the AMP algorithm with deep learning. This approach allows the deep learning network to learn and optimize the iterative steps of the AMP algorithm, forming a novel and effective channel estimation method.
The learned AMP (LAMP) algorithm is a variant of the AMP algorithm that unfolds and maps the AMP algorithm’s iterative steps directly into a DNN, thereby utilizing the DNN’s ability to jointly optimize the coefficients of the linear transformations and the parameters of the nonlinear shrinkage function. However, the existing LAMP networks may not achieve the desired performance in beamspace channel estimation. In light of this, Wei et al. [36] investigated an enhanced scheme based on a prior-assisted Gaussian mixture LAMP (GM-LAMP). Specifically, the authors replaced the soft threshold shrinkage function in the original LAMP network with a Gaussian mixture shrinkage function, which is able to reflect more of the beamspace channel’s prior information. Compared to the OMP, the AMP, and the LAMP algorithms, the GM-LAMP algorithm has a superior NMSE performance with less pilot overhead.
The denoising AMP (DAMP) algorithm is also a variant stemming from the AMP algorithm, replacing the shrinkage function with a denoiser. Pu et al. [37] deeply unfolded the DAMP algorithm by replacing its original denoiser with a DnCNN. They developed the model-driven learned denoising AMP (LDAMP) algorithm for channel estimation with noisy channels in OTFS systems. Then, they predicted the theoretical NMSE performance of the LDAMP algorithm using the state evolution (SE) equation. Owing to the integration of the DAMP algorithm’s superior performance and the nonlinear fitting capability of deep learning, the proposed algorithm exhibits effectiveness and high accuracy.
In 2022, Wang et al. [38] introduced an AMP-based multi-stage scheme with deep learning for quasi-sparse channel environments. This scheme treats the entire system as an end-to-end DNN, and each iterative process of the sensing matrix, noise introduction, and AMP algorithm is regarded as a DNN layer. Firstly, the AMP sensing matrix is trained to adapt to the quasi-sparse channel and learn the optimal sensing matrix. Secondly, the AMP algorithm’s nonlinear shrinkage parameters and linear coefficients are optimized layer-by-layer. Finally, all trainable parameters are jointly optimized, thereby optimizing the entire system. Compared to the AMP, the LAMP, and the LDAMP algorithms, the proposed scheme has a superior NMSE performance while reducing pilot overhead.
Nevertheless, the studies mentioned above are limited to traditional communication scenarios and do not address future communication scenarios. As one of the critical techniques for 6G networks, the research on RIS is in full swing. The introduction of RIS improves the performance of communication systems but also increases their complexity, making conventional techniques, including channel estimation, confront new challenges. With the accelerated advancement in deep learning, numerous researchers have adopted this technique to solve the aforementioned issue. The following section will introduce channel estimation methods based on deep learning for RIS-aided wireless communication systems.
This entry is adapted from the peer-reviewed paper 10.3390/electronics12244965
References
- O’Shea, T.; Hoydis, J. An Introduction to Deep Learning for the Physical Layer. IEEE Trans. Cogn. Commun. Netw. 2017, 3, 563–575.
- Khalid, W.; Yu, H.; Ali, R.; Ullah, R. Advanced physical-layer technologies for beyond 5G wireless communication networks. Sensors 2021, 21, 3197.
- Kim, W.; Ahn, Y.; Kim, J.; Shim, B. Towards deep learning-aided wireless channel estimation and channel state information feedback for 6G. J. Commun. Netw. 2023, 25, 61–75.
- LeCun, Y.; Boser, B.; Denker, J.S.; Henderson, D.; Howard, R.E.; Hubbard, W.; Jackel, L.D. Backpropagation Applied to Handwritten Zip Code Recognition. Neural Comput. 1989, 1, 541–551.
- Sak, H.; Senior, A.; Beaufays, F. Long short-term memory based recurrent neural network architectures for large vocabulary speech recognition. arXiv 2014, arXiv:1402.1128.
- Ye, H.; Li, G.Y.; Juang, B.H. Power of Deep Learning for Channel Estimation and Signal Detection in OFDM Systems. IEEE Wirel. Commun. Lett. 2018, 7, 114–117.
- Ma, X.; Gao, Z. Data-Driven Deep Learning to Design Pilot and Channel Estimator for Massive MIMO. IEEE Trans. Veh. Technol. 2020, 69, 5677–5682.
- Ge, L.; Guo, Y.; Zhang, Y.; Chen, G.; Wang, J.; Dai, B.; Li, M.; Jiang, T. Deep Neural Network Based Channel Estimation for Massive MIMO-OFDM Systems With Imperfect Channel State Information. IEEE Syst. J. 2022, 16, 4675–4685.
- Zheng, X.; Lau, V.K.N. Online Deep Neural Networks for MmWave Massive MIMO Channel Estimation with Arbitrary Array Geometry. IEEE Trans. Signal Process. 2021, 69, 2010–2025.
- Zhang, Y.; Wang, H.; Li, C.; Chen, X.; Meriaudeau, F. On the performance of deep neural network aided channel estimation for underwater acoustic OFDM communications. Ocean Eng. 2022, 259, 111518.
- Li, X.; Han, Z.; Yu, H.; Yan, L.; Han, S. Deep Learning for OFDM Channel Estimation in Impulsive Noise Environments. Wirel. Pers. Commun. 2022, 125, 2947–2964.
- Mehlführer, C.; Colom Ikuno, J.; Šimko, M.; Schwarz, S.; Wrulich, M.; Rupp, M. The Vienna LTE simulators-Enabling reproducibility in wireless communications research. EURASIP J. Adv. Signal Process. 2011, 2011, 29.
- Soltani, M.; Pourahmadi, V.; Mirzaei, A.; Sheikhzadeh, H. Deep Learning-Based Channel Estimation. IEEE Commun. Lett. 2019, 23, 652–655.
- Li, L.; Chen, H.; Chang, H.H.; Liu, L. Deep Residual Learning Meets OFDM Channel Estimation. IEEE Wirel. Commun. Lett. 2020, 9, 615–618.
- Pradhan, A.; Das, S.; Dayalan, D. A Two-Stage CNN Based Channel Estimation for OFDM System. In Proceedings of the 2021 Advanced Communication Technologies and Signal Processing (ACTS), Rourkela, India, 15–17 December 2021; pp. 1–4.
- Li, J.; Peng, Q. Lightweight Channel Estimation Networks for OFDM Systems. IEEE Wirel. Commun. Lett. 2022, 11, 2066–2070.
- Zhao, J.; Wu, Y.; Zhang, Q.; Liao, J. Two-Stage Channel Estimation for mmWave Massive MIMO Systems Based on ResNet-UNet. IEEE Syst. J. 2023, 17, 4291–4300.
- Rahman, M.H.; Chowdhury, M.Z.; Utama, I.B.K.Y.; Jang, Y.M. Channel Estimation for Indoor Massive MIMO Visible Light Communication with Deep Residual Convolutional Blind Denoising Network. IEEE Trans. Cogn. Commun. Netw. 2023, 9, 683–694.
- Gizzini, A.K.; Chafii, M. Deep Learning Based Channel Estimation in High Mobility Communications Using Bi-RNN Networks. arXiv 2023, arXiv:2305.00208.
- Ali, M.H.E.; Taha, I.B. Channel state information estimation for 5G wireless communication systems: Recurrent neural networks approach. PeerJ Comput. Sci. 2021, 7, e682.
- Essai Ali, M.H.; Rabeh, M.L.; Hekal, S.; Abbas, A.N. Deep Learning Gated Recurrent Neural Network-Based Channel State Estimator for OFDM Wireless Communication Systems. IEEE Access 2022, 10, 69312–69322.
- Helmy, I.; Tarafder, P.; Choi, W. LSTM-GRU Model-Based Channel Prediction for One-Bit Massive MIMO System. IEEE Trans. Veh. Technol. 2023, 72, 11053–11057.
- Zhao, S.; Fang, Y.; Qiu, L. Deep Learning-Based channel estimation with SRGAN in OFDM Systems. In Proceedings of the 2021 IEEE Wireless Communications and Networking Conference (WCNC), Nanjing, China, 29 March–1 April 2021; pp. 1–6.
- Dong, Y.; Wang, H.; Yao, Y.D. Channel Estimation for One-Bit Multiuser Massive MIMO Using Conditional GAN. IEEE Commun. Lett. 2021, 25, 854–858.
- Zhang, Q.; Dong, H.; Zhao, J. Channel Estimation for High-Speed Railway Wireless Communications: A Generative Adversarial Network Approach. Electronics 2023, 12, 1752.
- Kang, X.F.; Liu, Z.H.; Yao, M. Deep learning for joint pilot design and channel estimation in MIMO-OFDM systems. Sensors 2022, 22, 4188.
- Gao, X.; Jin, S.; Wen, C.K.; Li, G.Y. ComNet: Combination of Deep Learning and Expert Knowledge in OFDM Receivers. IEEE Commun. Lett. 2018, 22, 2627–2630.
- Jiang, P.; Wen, C.K.; Jin, S.; Li, G.Y. Dual CNN-Based Channel Estimation for MIMO-OFDM Systems. IEEE Trans. Commun. 2021, 69, 5859–5872.
- Haq, S.A.U.; Gizzini, A.K.; Shrey, S.; Darak, S.J.; Saurabh, S.; Chafii, M. Deep Neural Network Augmented Wireless Channel Estimation for Preamble-Based OFDM PHY on Zynq System on Chip. IEEE Trans. Very Large Scale Integr. (VLSI) Syst. 2023, 31, 1026–1038.
- Li, Y.; Bian, X.; Li, M. Denoising Generalization Performance of Channel Estimation in Multipath Time-Varying OFDM Systems. Sensors 2023, 23, 3102.
- Hu, Z.; Chen, Y.; Han, C. PRINCE: A Pruned AMP Integrated Deep CNN Method for Efficient Channel Estimation of Millimeter-wave and Terahertz Ultra-Massive MIMO Systems. IEEE Trans. Wirel. Commun. 2023, 22, 8066–8079.
- Li, Q.; Gong, Y.; Meng, F.; Li, Z.; Miao, L.; Xu, Z. Residual Learning based Channel Estimation for OTFS system. In Proceedings of the 2022 IEEE/CIC International Conference on Communications in China (ICCC Workshops), Foshan, China, 11–13 August 2022; pp. 275–280.
- Tong, W.; Xu, W.; Wang, F.; Shang, J.; Pan, M.; Lin, J. Deep Learning Compressed Sensing-Based Beamspace Channel Estimation in mmWave Massive MIMO Systems. IEEE Wirel. Commun. Lett. 2022, 11, 1935–1939.
- Nayir, H.; Karakoca, E.; Görçin, A.; Qaraqe, K. Hybrid-Field Channel Estimation for Massive MIMO Systems based on OMP Cascaded Convolutional Autoencoder. In Proceedings of the 2022 IEEE 96th Vehicular Technology Conference (VTC2022-Fall), London, UK, 26–29 September 2022; pp. 1–6.
- Donoho, D.L.; Maleki, A.; Montanari, A. Message passing algorithms for compressed sensing: I. motivation and construction. In Proceedings of the 2010 IEEE Information Theory Workshop on Information Theory (ITW 2010, Cairo), Cairo, Egypt, 6–8 January 2010; pp. 1–5.
- Wei, X.; Hu, C.; Dai, L. Deep Learning for Beamspace Channel Estimation in Millimeter-Wave Massive MIMO Systems. IEEE Trans. Commun. 2021, 69, 182–193.
- Pu, X.; Liu, Y.; Song, M.; Chen, Q. Orthogonal Time Frequency Space Channel Estimation Based on Model-driven Deep Learning. J. Electron. Inf. Technol. 2023, 45, 1–8.
- Wang, P.; Li, J.; Liu, X.; Wang, P. Multi-Stage Training Optimization for Pilot Compression and Channel Estimation in Massive MIMO Systems Under Quasi-Sparse Channel Environment. IEEE Commun. Lett. 2022, 26, 3059–3063.
This entry is offline, you can click here to edit this entry!