The interest in recommendation systems (RSs) has dramatically increased, as they have become main components of all online stores. The aims of an RS can be multifaceted, related not only to the increase in sales or the convenience of the customer, but may include the promotion of alternative environmentally friendly products or to strengthen policies and campaigns. In addition to accurate suggestions, important aspects of contemporary RSs are therefore to align with the particular marketing goals of the e-shop and with the stances of the targeted audience, ensuring user acceptance, satisfaction, high impact, and achieving sustained usage by customers.
- recommendation systems
- e-commerce
- sustainable marketing
- retail
- advanced methods for e-shops
1. Introduction
2. Prior Reviews of RS in e-Commerce
2.1. Reviews of Recommendation Applications
2.2. Reviews of Recommendation Technologies
3. Recommendation Types and Methods in e-Retail
3.1. Typical Applications of RS
-
An e-shop recommending products to its visitors. Important characteristics of the problem are: (a) Whether the recommendations are produced before or after a sale or an item selection action by the user. A recommendation that precedes the user’s action is based on the general needs of the users, while the one that follows a user’s selection aims at matching the current user’s action. (b) Whether the recommendations are addressed to known or unknown users. When the user is unknown, recommendations can only be based on general knowledge, such as global popularity of items and associations among items. The first recommendations are predefined, while the next ones can be adjusted to the user’s actions by a session-based recommendation algorithm. (c) The need for the RS to be dynamically adjusted by exploiting interactivity/filtering. The problem in this case is not simply to produce a list of items but involves the ability to react with intelligence to the user’s selections.
-
Personalizing promotional actions. The problem is to match to a particular user any type of action, such as to send info about a product, show an ad, make a special offer/discount, send coupons, etc., on behalf of stores, either online, offline, or both. The RS may be operating in (a) search engines or metasellers (eBay, BestPrice, etc.) or (b) individual stores, where the RS is typically incorporated into their loyalty program and used to send promotional messages, discounts, gifts, etc. A rapidly growing trend is for companies to offer to their customers mobile apps linked to a customer account. Such apps are inherently personalized bidirectional channels and one of the most promising fields for RS.
3.2. Outline of Main Recommendation Approaches Applied in e-Commerce
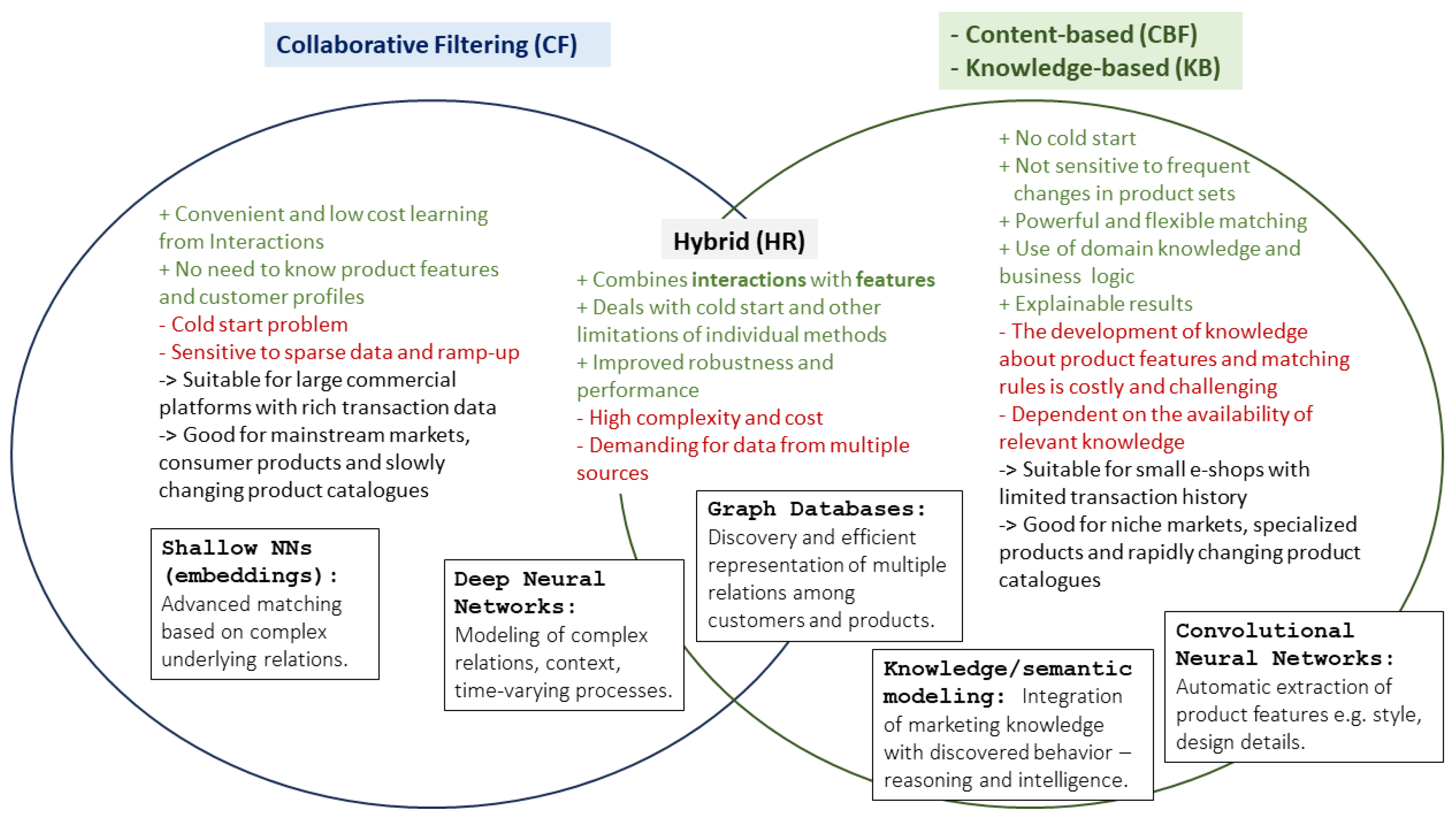
3.3. Modeling Methods Most Commonly Used in Retail
| Methods | Comments | Related Papers |
|---|---|---|
| Rule-based and knowledge-based models |
Methods with long history in RS, suitable for alleviating the cold start, sparse data, and ramp-up problems. Complex models can be used to combine pre-existing domain knowledge with discovered patterns and product features. Recent research utilized semantic web technologies and reasoning engines in order to enhance the intelligence/cognitive abilities. | [22][23][24][25][26][27][28][29][30][31][32][33] |
| Neural networks and deep learning |
The most rapidly developing modeling approaches, appearing in a variety of different forms (e.g., deep networks, recurrent, embedding-based, etc.). Their main strengths are in learning complex relations and in capturing semantic, sequencing, and contextual information. Their limitations are their high demands for training data and computational resources. They are the preferred technologies for modeling multiple-step behavior and for extracting features from unstructured data. | [34][35][36][37][38][39][40][41][42][43][44][45][46][47][48][49][50][51][52][53][54][55][56][57][58][59][60][61][62][63][64][65][66][67][68][69][70] |
| Markovian methods | Less popular methods that aim at capturing the sequences of user actions in click stream data and session-based RS. Recent research work was limited. | [71][72][73][74][75] |
| Graph databases | A relatively new and promising framework, which is efficient in capturing logical relations among users and items. It is suitable for both CF and KB approaches. | [76][77][78] |
| Matrix factorization | The most typical approach for early CF recommenders, which is still valid as a powerful core method for reducing the dimensionality problem. Recent research work in e-commerce RS was limited. | [43][79][80] |
| Natural language processing |
Particularly useful methods for extracting implicit information about users’ stances, regarding both their personality/behavior and their opinion on specific products. Additionally, NLP has been used for extracting item features from their text description. | [81][82][83][84][85][86][87][88] |
3.3.1. Rule-Based and Knowledge-Based Models
3.3.2. Neural Networks and Deep Learning
Shallow Neural Models
Deep Neural Networks
Graph Neural Networks
3.3.3. Markovian Methods
3.3.4. Graph Database Modeling
3.3.5. Matrix Factorization
3.3.6. Natural Language Processing Methods
This entry is adapted from the peer-reviewed paper 10.3390/su152316151
References
- Kennedyd, S.I.; Marjerison, R.K.; Yu, Y.; Zi, Q.; Tang, X.; Yang, Z. E-commerce engagement: A prerequisite for economic sustainability—An empirical examination of influencing factors. Sustainability 2022, 14, 4554.
- Goldberg, D.; Nichols, D.; Oki, B.M.; Terry, D. Using collaborative filtering to weave an information tapestry. Commun. ACM 1992, 35, 61–70.
- Billsus, D.; Pazzani, M.J. Learning collaborative information filters. In Proceedings of the Fifteenth International Conference on Machine Learning (ICML 1998), Madison, WI, USA, 24–27 July 1998; Volume 98, pp. 46–54.
- Huang, Z.; Chen, H.; Zeng, D. Applying associative retrieval techniques to alleviate the sparsity problem in collaborative filtering. ACM Trans. Inf. Syst. TOIS 2004, 22, 116–142.
- Nilashi, M.; Jannach, D.; bin Ibrahim, O.; Esfahani, M.D.; Ahmadi, H. Recommendation quality, transparency, and website quality for trust-building in recommendation agents. Electron. Commer. Res. Appl. 2016, 19, 70–84.
- Yoon, V.Y.; Hostler, R.E.; Guo, Z.; Guimaraes, T. Assessing the moderating effect of consumer product knowledge and online shopping experience on using recommendation agents for customer loyalty. Decis. Support Syst. 2013, 55, 883–893.
- Linden, G.; Smith, B.; York, J. Amazon.com recommendations: Item-to-item collaborative filtering. IEEE Internet Comput. 2003, 7, 76–78.
- Smith, B.; Linden, G. Two decades of recommender systems at Amazon. com. IEEE Internet Comput. 2017, 21, 12–18.
- Li, S.S.; Karahanna, E. Online Recommendation Systems in a B2C E-Commerce Context: A Review and Future Directions. J. Assoc. Inf. Syst. 2015, 16, 72–107.
- Adomavicius, G.; Tuzhilin, A. Toward the next generation of recommender systems: A survey of the state-of-the-art and possible extensions. IEEE Trans. Knowl. Data Eng. 2005, 17, 734–749.
- Alamdari, P.M.; Navimipour, N.J.; Hosseinzadeh, M.; Safaei, A.A.; Darwesh, A. A systematic study on the recommender systems in the E-commerce. IEEE Access 2020, 8, 115694–115716.
- Fayyaz, Z.; Ebrahimian, M.; Nawara, D.; Ibrahim, A.; Kashef, R. Recommendation Systems: Algorithms, Challenges, Metrics, and Business Opportunities. Appl. Sci. 2020, 10, 7748.
- Karimova, F. A survey of e-commerce recommender systems. Eur. Sci. J. 2016, 12, 75–89.
- Xiao, B.; Benbasat, I. Research on the use, characteristics, and impact of e-commerce product recommendation agents: A review and update for 2007–2012. In Handbook of Strategic e-Business Management; Springer: Berlin/Heidelberg, Germany, 2014; pp. 403–431.
- Singh, P.K.; Pramanik, P.K.D.; Dey, A.K.; Choudhury, P. Recommender systems: An overview, research trends, and future directions. Int. J. Bus. Syst. Res. 2021, 15, 14–52.
- Almahmood, R.J.K.; Tekerek, A. Issues and Solutions in Deep Learning-Enabled Recommendation Systems within the E-Commerce Field. Appl. Sci. 2022, 12, 11256.
- Zhang, Q.; Lu, J.; Jin, Y. Artificial intelligence in recommender systems. Complex Intell. Syst. 2021, 7, 439–457.
- Bouraga, S.; Jureta, I.; Faulkner, S.; Herssens, C. Knowledge-based recommendation systems: A survey. Int. J. Intell. Inf. Technol. IJIIT 2014, 10, 1–19.
- Kim, M.C.; Chen, C. A scientometric review of emerging trends and new developments in recommendation systems. Scientometrics 2015, 104, 239–263.
- Chen, C. CiteSpace II: Detecting and visualizing emerging trends and transient patterns in scientific literature. J. Am. Soc. Inf. Sci. Technol. 2006, 57, 359–377.
- Park, D.H.; Kim, H.K.; Choi, I.Y.; Kim, J.K. A literature review and classification of recommender systems research. Expert Syst. Appl. 2012, 39, 10059–10072.
- Tomkins, S.; Isley, S.; London, B.; Getoor, L. Sustainability at scale: Towards bridging the intention-behavior gap with sustainable recommendations. In Proceedings of the 12th ACM Conference on Recommender Systems, Vancouver, BC, Canada, 2 October 2018; pp. 214–218.
- Sarwar, B.; Karypis, G.; Konstan, J.; Riedl, J. Analysis of recommendation algorithms for e-commerce. In Proceedings of the 2nd ACM Conference on Electronic Commerce, Minneapolis, MN, USA, 17–20 October 2000; pp. 158–167.
- Psaila, G.; Lanzi, P. Hierarchy-based mining of association rules in data warehouses. In Proceedings of the 2000 ACM Symposium on Applied Computing, Como, Italy, 19–21 March 2000; pp. 307–312.
- Lin, W.; Ruiz, C. Efficient adaptive-support association rule mining for recommender systems. Data Min. Knowl. Discov. 2002, 6, 83–105.
- Leung, C.W.k.; Chan, S.C.f.; Chung, F.l. A collaborative filtering framework based on fuzzy association rules and multiple-level similarity. Knowl. Inf. Syst. 2006, 10, 357–381.
- Ghafari, S.; Tjortjis, C. A survey on association rules mining using heuristics. WIREs Data Min. Knowl. Discov. 2019, 9, e1307.
- Najafabadi, M.K.; Mahrin, M.N.; Sarkan, H.M. Improving the accuracy of collaborative filtering recommendations using clustering and association rules mining on implicit data. Comput. Hum. Behav. 2017, 67, 113–128.
- Pariserum Perumal, S.; Ganapathy, S.; Kannan, A. An intelligent fuzzy rule-based e-learning recommendation system for dynamic user interests. J. Supercomput. 2019, 75, 5145–5160.
- Nair, B.; Mohandas, V.; Nayanar, N.; Teja, E.; Vigneshwari, S.; Teja, K. A stock trading recommender system based on temporal association rule mining. SAGE Open 2015, 5, 2158244015579941.
- Liao, S.; Chang, H. A rough set-based association rule approach for a recommendation system for online consumers. Inf. Process. Manag. 2016, 52, 1142–1160.
- Kim, J.; Kang, S.; Kim, H. Recommendation algorithm of the app store by using semantic relations between apps. J. Supercomput. 2011, 65, 16–26.
- Aguilar, J.; Valdiviezo-Diaz, P.; Riofrio, G. A general framework for intelligent recommender systems. Appl. Comput. Inform. 2017, 13, 147–160.
- Stalidis, G.; Siomos, T.; Kaplanoglou, P.I.; Katsalis, A.; Karaveli, I.; Delianidi, M.; Diamantaras, K. Multidimensional Factor and Cluster Analysis Versus Embedding-Based Learning for Personalized Supermarket Offer Recommendations. In Data Analysis and Rationality in a Complex World, Studies in Classification, Data Analysis, and Knowledge Organization; Springer: Berlin/Heidelberg, Germany, 2019; pp. 273–281.
- Mikolov, T.; Yih, W.t.; Zweig, G. Linguistic regularities in continuous space word representations. In Proceedings of the 2013 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Atlanta, GA, USA, 10–12 June 2013; pp. 746–751.
- Barkan, O.; Koenigstein, N. Item2vec: Neural item embedding for collaborative filtering. In Proceedings of the 2016 IEEE 26th International Workshop on Machine Learning for Signal Processing (MLSP), Vietri sul Mare, Italy, 13–16 September 2016; pp. 1–6.
- Barkan, O.; Caciularu, A.; Katz, O.; Koenigstein, N. Attentive item2vec: Neural attentive user representations. In Proceedings of the ICASSP 2020–2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Virtual, 4–8 May 2020; pp. 3377–3381.
- Barkan, O.; Caciularu, A.; Rejwan, I.; Katz, O.; Weill, J.; Malkiel, I.; Koenigstein, N. Cold item recommendations via hierarchical item2vec. In Proceedings of the 2020 IEEE International Conference on Data Mining (ICDM), Sorrento, Italy, 17–20 November 2020; pp. 912–917.
- Hu, L.; Cao, L.; Wang, S.; Xu, G.; Cao, J.; Gu, Z. Diversifying Personalized Recommendation with User-session Context. In Proceedings of the IJCAI, Melbourne, Australia, 19–25 August 2017; pp. 1858–1864.
- Hinton, G.E.; Osindero, S.; Teh, Y.W. A fast learning algorithm for deep belief nets. Neural Comput. 2006, 18, 1527–1554.
- Iandola, F.N.; Han, S.; Moskewicz, M.W.; Ashraf, K.; Dally, W.J.; Keutzer, K. SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and <0.5 MB model size. arXiv 2016, arXiv:1602.07360.
- Shan, Y.; Hoens, T.R.; Jiao, J.; Wang, H.; Yu, D.; Mao, J. Deep crossing: Web-scale modeling without manually crafted combinatorial features. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 255–262.
- He, X.; Liao, L.; Zhang, H.; Nie, L.; Hu, X.; Chua, T.S. Neural collaborative filtering. In Proceedings of the 26th International Conference on World Wide Web, Perth, Australia, 3–7 April 2017; pp. 173–182.
- Huang, P.S.; He, X.; Gao, J.; Deng, L.; Acero, A.; Heck, L. Learning deep structured semantic models for web search using clickthrough data. In Proceedings of the 22nd ACM International Conference on Information & Knowledge Management, San Francisco, CA, USA, 27 October–1 November 2013; pp. 2333–2338.
- Wu, C.Y.; Ahmed, A.; Beutel, A.; Smola, A.J.; Jing, H. Recurrent recommender networks. In Proceedings of the Tenth ACM International Conference on Web Search And Data Mining, Cambridge, UK, 6–10 February 2017; pp. 495–503.
- Lee, H.I.; Choi, I.Y.; Moon, H.S.; Kim, J.K. A multi-period product recommender system in online food market based on recurrent neural networks. Sustainability 2020, 12, 969.
- Salampasis, M.; Siomos, T.; Katsalis, A.; Diamantaras, K.; Christantonis, K.; Delianidi, M.; Karaveli, I. Comparison of RNN and Embeddings Methods for Next-item and Last-basket Session-based Recommendations. In Proceedings of the 2021 13th International Conference on Machine Learning and Computing, Shenzhen, China, 26 February–1 March 2021; pp. 477–484.
- Yuan, F.; Karatzoglou, A.; Arapakis, I.; Jose, J.M.; He, X. A simple convolutional generative network for next item recommendation. In Proceedings of the Twelfth ACM International Conference on Web Search and Data Mining, Melbourne, Australia, 11–15 February 2019; pp. 582–590.
- Addagarla, S.K.; Amalanathan, A. e-SimNet: A visual similar product recommender system for E-commerce. Indones. J. Electr. Eng. Comput. Sci. IJEECS 2021, 22, 563–570.
- Latha, Y.M.; Rao, B.S. Product recommendation using enhanced convolutional neural network for e-commerce platform. Clust. Comput. 2023, 1–15.
- Cong, D.; Zhao, Y.; Qin, B.; Han, Y.; Zhang, M.; Liu, A.; Chen, N. Hierarchical attention based neural network for explainable recommendation. In Proceedings of the 2019 on International Conference on Multimedia Retrieval, Ottawa, ON, Canada, 10–13 June 2019; pp. 373–381.
- Chen, X.; Xu, H.; Zhang, Y.; Tang, J.; Cao, Y.; Qin, Z.; Zha, H. Sequential recommendation with user memory networks. In Proceedings of the Eleventh ACM International Conference on Web Search and Data Mining, Marina Del Rey, CA, USA, 5–9 February 2018; pp. 108–116.
- Tang, J.; Belletti, F.; Jain, S.; Chen, M.; Beutel, A.; Xu, C.; Chi, E.H. Towards neural mixture recommender for long range dependent user sequences. In Proceedings of the The World Wide Web Conference, San Francisco, CA, USA, 13–17 May 2019; pp. 1782–1793.
- Xue, F.; He, X.; Wang, X.; Xu, J.; Liu, K.; Hong, R. Deep item-based collaborative filtering for top-n recommendation. ACM Trans. Inf. Syst. (TOIS) 2019, 37, 1–25.
- Cheng, H.T.; Koc, L.; Harmsen, J.; Shaked, T.; Chandra, T.; Aradhye, H.; Anderson, G.; Corrado, G.; Chai, W.; Ispir, M.; et al. Wide & deep learning for recommender systems. In Proceedings of the 1st Workshop on Deep Learning for Recommender Systems, Boston, MA, USA, 15 September 2016; pp. 7–10.
- Guo, H.; Tang, R.; Ye, Y.; Li, Z.; He, X. DeepFM: A factorization-machine based neural network for CTR prediction. arXiv 2017, arXiv:1703.04247.
- Chen, Q.; Zhao, H.; Li, W.; Huang, P.; Ou, W. Behavior sequence transformer for e-commerce recommendation in alibaba. In Proceedings of the 1st International Workshop on Deep Learning Practice for High-Dimensional Sparse Data, Anchorage, AK, USA, 5 August 2019; pp. 1–4.
- Khan, Z.; Hussain, M.I.; Iltaf, N.; Kim, J.; Jeon, M. Contextual recommender system for E-commerce applications. Appl. Soft Comput. 2021, 109, 107552.
- McAuley, J.; Targett, C.; Shi, Q.; Van Den Hengel, A. Image-based recommendations on styles and substitutes. In Proceedings of the 38th International ACM SIGIR Conference on Research and Development in Information Retrieval, Santiago, Chile, 9–13 August 2015; pp. 43–52.
- Wu, S.; Tang, Y.; Zhu, Y.; Wang, L.; Xie, X.; Tan, T. Session-based recommendation with graph neural networks. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 346–353.
- Song, W.; Xiao, Z.; Wang, Y.; Charlin, L.; Zhang, M.; Tang, J. Session-based social recommendation via dynamic graph attention networks. In Proceedings of the Twelfth ACM International Conference on Web Search And Data Mining, Melbourne, Australia, 11–15 February 2019; pp. 555–563.
- Fan, W.; Ma, Y.; Li, Q.; He, Y.; Zhao, E.; Tang, J.; Yin, D. Graph neural networks for social recommendation. In Proceedings of the The World Wide Web Conference, San Francisco, CA, USA, 13–17 May 2019; pp. 417–426.
- Liu, P.; Zhang, L.; Gulla, J.A. Real-time social recommendation based on graph embedding and temporal context. Int. J. Hum.-Comput. Stud. 2019, 121, 58–72.
- Wang, D.; Bao, Y.; Yu, G.; Wang, G. Using page classification and association rule mining for personalized recommendation in distance learning. In Proceedings of the International Conference on Web-Based Learning, Hong Kong, China, 17–19 August 2002; Springer: Berlin/Heidelberg, Germany, 2002; pp. 363–374.
- Wang, X.; He, X.; Wang, M.; Feng, F.; Chua, T.S. Neural graph collaborative filtering. In Proceedings of the 42nd International ACM SIGIR Conference on Research and Development in Information Retrieval, Paris, France, 21–25 July 2019; pp. 165–174.
- Berg, R.v.d.; Kipf, T.N.; Welling, M. Graph convolutional matrix completion. arXiv 2017, arXiv:1706.02263.
- Grad-Gyenge, L.; Kiss, A.; Filzmoser, P. Graph embedding based recommendation techniques on the knowledge graph. In Proceedings of the Adjunct Publication of the 25th Conference on User Modeling, Adaptation and Personalization, Bratislava, Slovakia, 9–12 July 2017; pp. 354–359.
- Rakkappan, L.; Rajan, V. Context-aware sequential recommendations withstacked recurrent neural networks. In Proceedings of the The World Wide Web Conference, San Francisco, CA, USA, 13–17 May 2019; pp. 3172–3178.
- Unger, M.; Bar, A.; Shapira, B.; Rokach, L. Towards latent context-aware recommendation systems. Knowl.-Based Syst. 2016, 104, 165–178.
- Liu, Q.; Wu, S.; Wang, D.; Li, Z.; Wang, L. Context-aware sequential recommendation. In Proceedings of the 2016 IEEE 16th International Conference on Data Mining (ICDM), Barcelona, Spain, 12–15 December 2016; pp. 1053–1058.
- Eirinaki, M.; Vazirgiannis, M.; Kapogiannis, D. Web path recommendations based on page ranking and markov models. In Proceedings of the 7th Annual ACM International Workshop on Web Information and Data Management, Bremen, Germany, 5 November 2005; pp. 2–9.
- Shani, G.; Heckerman, D.; Brafman, R.I. An MDP-based recommender system. J. Mach. Learn. Res. 2005, 6, 1265–1295.
- Zhang, Z.; Nasraoui, O. Efficient hybrid Web recommendations based on Markov clickstream models and implicit search. In Proceedings of the IEEE/WIC/ACM International Conference on Web Intelligence (WI’07), Silicon Valley, CA, USA, 2–5 November 2007; pp. 621–627.
- Le, D.T.; Fang, Y.; Lauw, H.W. Modeling sequential preferences with dynamic user and context factors. In Proceedings of the Joint European Conference on Machine Learning and Knowledge Discovery in Databases, Riva del Garda, Italy, 19–23 September 2016; Springer: Berlin/Heidelberg, Germany, 2016; pp. 145–161.
- Rendle, S.; Freudenthaler, C.; Schmidt-Thieme, L. Factorizing personalized markov chains for next-basket recommendation. In Proceedings of the 19th International Conference on World Wide Web, Raleigh, NC, USA, 26–30 April 2010; pp. 811–820.
- Konno, T.; Huang, R.; Ban, T.; Huang, C. Goods recommendation based on retail knowledge in a Neo4j graph database combined with an inference mechanism implemented in jess. In Proceedings of the 2017 IEEE SmartWorld, Ubiquitous Intelligence & Computing, Advanced & Trusted Computed, Scalable Computing & Communications, Cloud & Big Data Computing, Internet of People and Smart City Innovation (SmartWorld/SCALCOM/UIC/ATC/CBDCom/IOP/SCI), San Francisco, CA, USA, 4–8 August 2017; pp. 1–8.
- Sen, S.; Mehta, A.; Ganguli, R.; Sen, S. Recommendation of Influenced Products Using Association Rule Mining: Neo4j as a Case Study. SN Comput. Sci. 2021, 2, 1–17.
- Delianidi, M.; Salampasis, M.; Diamantaras, K.; Siomos, T.; Katsalis, A.; Karaveli, I. A Graph-Based Method for Session-Based Recommendations. In Proceedings of the 24th Pan-Hellenic Conference on Informatics, Athens, Greece, 20–22 November 2020; Association for Computing Machinery: New York, NY, USA, 2020; pp. 264–267.
- Koren, Y.; Bell, R.; Volinsky, C. Matrix factorization techniques for recommender systems. Computer 2009, 42, 30–37.
- Le, D.T.; Lauw, H.W.; Fang, Y. Basket-sensitive personalized item recommendation. In Proceedings of the International Joint Conference on Artificial Intelligence (IJCAI), Melbourne, Australia, 19–25 August 2017.
- Srifi, M.; Oussous, A.; Ait Lahcen, A.; Mouline, S. Recommender systems based on collaborative filtering using review texts—A survey. Information 2020, 11, 317.
- Tarnowska, K.A.; Ras, Z. NLP-based customer loyalty improvement recommender system (CLIRS2). Big Data Cogn. Comput. 2021, 5, 4.
- Sharma, A.K.; Bajpai, B.; Adhvaryu, R.; Pankajkumar, S.D.; Gordhanbhai, P.P.; Kumar, A. An Efficient Approach of Product Recommendation System using NLP Technique. Mater. Today Proc. 2021, 80, 3730–3743.
- Shoja, B.M.; Tabrizi, N. Customer reviews analysis with deep neural networks for e-commerce recommender systems. IEEE Access 2019, 7, 119121–119130.
- Karthik, R.; Ganapathy, S. A fuzzy recommendation system for predicting the customers interests using sentiment analysis and ontology in e-commerce. Appl. Soft Comput. 2021, 108, 107396.
- Karn, A.L.; Karna, R.K.; Kondamudi, B.R.; Bagale, G.; Pustokhin, D.A.; Pustokhina, I.V.; Sengan, S. Customer centric hybrid recommendation system for E-Commerce applications by integrating hybrid sentiment analysis. Electron. Commer. Res. 2023, 23, 279–314.
- Sun, Z.; Han, L.; Huang, W.; Wang, X.; Zeng, X.; Wang, M.; Yan, H. Recommender systems based on social networks. J. Syst. Softw. 2015, 99, 109–119.
- Shambour, Q.; Lu, J. A trust-semantic fusion-based recommendation approach for e-business applications. Decis. Support Syst. 2012, 54, 768–780.
- Agrawal, R.; Imielinski, T.; Arun, S. Mining association rules between sets of items in large databases. ACM Sigmond Rec. 1993, 22, 207–216.
- Aggarwal, C.C. Recommender Systems; Springer: Berlin/Heidelberg, Germany, 2016; Volume 1.
- Gai, P.J.; Klesse, A.K. Making recommendations more effective through framings: Impacts of user-versus item-based framings on recommendation click-throughs. J. Mark. 2019, 83, 61–75.
- Alom, M.Z.; Taha, T.M.; Yakopcic, C.; Westberg, S.; Sidike, P.; Nasrin, M.S.; Van Esesn, B.C.; Awwal, A.A.S.; Asari, V.K. The history began from alexnet: A comprehensive survey on deep learning approaches. arXiv 2018, arXiv:1803.01164.
- Gao, C.; Zheng, Y.; Li, N.; Li, Y.; Qin, Y.; Piao, J.; Quan, Y.; Chang, J.; Jin, D.; He, X.; et al. A survey of graph neural networks for recommender systems: Challenges, methods, and directions. ACM Trans. Recomm. Syst. 2023, 1, 1–51.
- Xu, F.; Lian, J.; Han, Z.; Li, Y.; Xu, Y.; Xie, X. Relation-aware graph convolutional networks for agent-initiated social e-commerce recommendation. In Proceedings of the 28th ACM International Conference on Information and Knowledge Management, Beijing, China, 3–7 November 2019; pp. 529–538.
- Basharin, G.P.; Langville, A.N.; Naumov, V.A. The life and work of AA Markov. Linear Algebra Its Appl. 2004, 386, 3–26.
- Guia, J.; Soares, V.G.; Bernardino, J. Graph Databases: Neo4j Analysis. In Proceedings of the ICEIS, Porto, Portugal, 26–29 April 2017; pp. 351–356.
- Cheng, C.H.; Chen, Y.S. Classifying the segmentation of customer value via RFM model and RS theory. Expert Syst. Appl. 2009, 36, 4176–4184.
- Delianidi, M.; Diamantaras, K.; Tektonidis, D.; Salampasis, M. Session-Based Recommendations for e-Commerce with Graph-Based Data Modeling. Appl. Sci. 2022, 13, 394.