OpenStreetMap (OSM) is a potential source of geospatial open data for monitoring sustainable development goals (SDG) indicators. Improving the quality of these crowdsourcing data has significant implications for monitoring and achieving SDGs, such as zero hunger, sustainable cities, ensuring tenure security, and preserving biodiversity. The quality of OpenStreetMap (OSM) has been widely concerned as a valuable source for monitoring some sustainable development goals (SDG) indicators. Improving its semantic quality is still challenging. As a kind of solution, road type prediction plays an important role. However, most existing algorithms show low accuracy, owing to data sparseness and inaccurate description.
1. Introduction
Volunteered Geographic Information (VGI) has been widely concerned by academia and industry since it was coined by Goodchild in 2007 [
1]. OpenStreetMap (OSM) is one of the most successful VGI projects. According to OSM official statistics, it has more than 9 million registered users so far. Benefiting from numerous volunteers and their familiarity with surrounding features, geospatial data are updated on the OSM platform frequently and quickly. Now various applications are derived and expanded on OSM spatial data because the data is free for all uses [
2]. And OSM is a potential source of geospatial open data for monitoring sustainable development goals (SDG) indicators [
3]. Improving the quality of these crowdsourcing data has significant implications for monitoring and achieving SDGs, such as zero hunger, sustainable cities, ensuring tenure security, and preserving biodiversity [
4].
Nevertheless, there are some issues with spatial data quality because the OSM platform does not have a rigorous error detection and notification mechanism during the contributors’ submission process and many contributors lack knowledge related to geography and geographic mapping, such as inaccuracy and incompleteness, and data quality vary with different countries and regions [
5]. And the contributing experience and skill of contributors also vary greatly. Therefore, it is very difficult for most of them to describe OSM geographic elements with accurate semantic attributes (tags in OSM), which leads to certain semantic quality problems in the OSM dataset, especially for some geographic objects with similar types [
6]. To some extent, these issues have hindered the development of the OSM and reduced its role as a valuable source for monitoring some SDG indicators. Therefore, the research on how to improve the quality of OSM data [
7,
8,
9] has been a popular topic in the academic community in recent years.
Spatial data mainly contain three basic features: spatial, thematic, and temporal features. The thematic features of geographic elements in OSM are mainly described by tags. It can be divided into element class tags and other attribute tags [
6]. Element class tags are applied to differentiate from other types of geographical elements, such as highways, major roads, or residential roads. These tags are very important attributes that connect OSM elements and map layers [
6]. Other attribute tags describe other characteristics of the OSM elements, such as road name, width, and speed limit.
The geographical information quality of OSM has been extensively studied recently. Most of them have focused on two aspects: quality evaluation [
10,
11,
12] and quality improvement [
7,
13]. In terms of quality improvement, many scholars pay more attention to tag recommendations of OSM geographic objects [
9,
14,
15,
16,
17,
18,
19,
20,
21,
22]. Existing tag recommendation methods are mostly based on the characteristics of OSM elements themselves [
14,
15,
16,
17,
18,
19]. For example, Storandt et al. proposed a system to recommend suitable road labels only according to the name of points of interest (POIs) [
15].
The road is one of the most important elements in OSM, and it is the basis of numerous applications such as navigation and network analysis [
23,
24,
25,
26]. Therefore, the tag recommendation of the OSM road network is of particular importance. At present, most of the research on road tag recommendation considers the object’s characteristics and its restricted characteristics [
18,
19,
20]. In addition, the experimental data for the studies are generally selected from the areas with rich OSM data (such as London, UK), and the OSM data of these places are recognized to be extremely useful [
27]. In other words, these models are generally only effective in handling dense OSM datasets. However, insufficient quality and availability of the OSM data relatively in some economically underdeveloped countries and regions often limit their application. The problems of incomplete geographical objects or inaccurate semantic descriptions of geographical objects exist in various degrees. Thus, it is still challenging to further improve the accuracy of tag recommendation.
According to Tobler’s First Law of Geography [
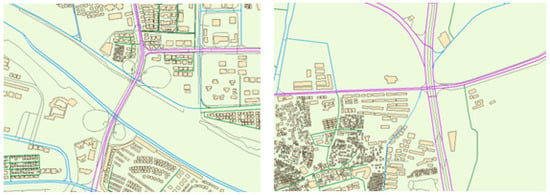
28], the spatial distribution of geographical things or attributes is interrelated with each other, and it appears with clustering, random, and regular characteristics. The relationship can be described by the spatial context. Hence, spatial context extraction from the surrounding environment of geographic objects can enrich their characteristics and is very useful for predicting their types. As shown in
Figure 1, it is easy to find out the difference among the three road types in the OSM platform: secondary, tertiary, and residential roads. The tertiary and residential roads offer more opportunities to be close to residential buildings (regularly arranged buildings in the figure), while secondary roads have only a small part adjacent to residential houses. Its main function is to connect specific administrative centers, traffic hubs, commercial zones, etc., of which characteristics are straight and spacious.
Figure 1. An example of different road types in OSM, where secondary, tertiary, and residential roads are purple, blue, and green, respectively, other types of roads are black, and buildings are yellow rectangles.
Several studies have shown that it is feasible to extract spatial contexts (SC) and apply them to tag recommendation of spatial objects [
9,
20,
21,
22], which can improve the recommendation accuracy in the case of poor data integrity and low semantic accuracy in OSM regions. Ali et al. analyzed the spatial context of fuzzy grassland classification tag recommendation and counted the relevant regional entities, such as “amenities” and “leisure” and some linear entities in the research regions [
21], in which the effectiveness of spatial context deployment has been verified. However, they did not adequately consider the influence of the surrounding objects, for example, POIs around the park regions. Alghanim et al. added the building context into the feature matrix of road elements, and they used the random forest (RF) algorithm to recommend road tags [
6]. The work achieved good results on their dataset, but they ignored the influence of other spatial contexts, such as connecting road context, Zhao and Tang proposed a system to recommend suitable building labels that introduced external semantic features, including the location features of buildings, spatial co-location patterns of points of interest (POI), nighttime light, and land use information of the buildings [
22].
2. Quality Evaluation of OSM Data
In recent years, the ability of novice contributors to accurately describe spatial geographic data poses many concerns for OSM data quality [
8]. Therefore, many studies have focused on evaluating the accuracy and completeness of OSM data. International Cartographic Association (ICA) [
28] developed seven rules for assessing the quality of spatial geographic data. Based on these seven rules [
29], Barron et al. extended the rules, including the semantic, geometric accuracy, and availability of spatial data. Moreover, since contributors are an important part of map production, data-centric and contributor-centric assessments are often combined [
11,
12,
30,
31,
32,
33]. Overall, the OSM quality assessment can be divided into extrinsic quality measures and intrinsic quality measures.
Extrinsic quality measures: This type of research compares OSM data with authoritative data from other official institutions for external evaluation [
10,
34,
35,
36]. Such methods rely on external data. However, authoritative datasets are more difficult to obtain than public ones, and the update efficiency of their data is sometimes slower than the fast-changing OSM data. All these factors constrain such evaluation methods in applications and expansions.
Intrinsic quality measures: Intrinsic method does not rely on external or authoritative data sources for validation [
37,
38]. The methods can measure the accuracy of OSM data by assessing changes in historical versions of the data, or by associating user reputation. As an example, Fogliaroni et al. calculated the quality score of geographic features by analyzing the geometric, qualitative, and semantic changes in the edited version of history. They used it to approximate the quality score of spatial data at the end [
8]. Zhou and Zhao used spatial similarity and geometrical similarity to calculate the similarities between the versions. The reputation of the contributor was obtained by analyzing the complicit assessments computed by version similarity [
28]. Mullagann et al. analyzed the spatial semantic relations of point features. The spatial semantic interaction was used to measure the semantic similarity of the change history of geographic elements [
33].
3. Quality Improvement of OSM Data
The quality improvement of OSM data has received much attention from many researchers. It can be divided into two aspects: identifying and correcting erroneous data for OSM, and OSM tag recommendation.
Identifying and correcting erroneous data for OSM: The early literature on improving the quality of crowd-sourced geographic data focused on detecting and modifying error elements. For example, Vargas et al. used a Markov random field method to maximize the correlation among annotations of OSM buildings and predicted building probability maps. After removing several redundant geometric annotations through the relationship between building probability maps and thresholds, they used CNN to predict and add new architectural geometric annotations [
7]. Kashian et al. analyzed the “semantics” of the newly contributed data by identifying potential patterns of coexistence between POIs and other geographic features. They calculated the likelihood of a POI being registered at this location to improve the detection and verification system of the OSM platform. The location accuracy of registered POI in OSM can be improved [
13]. These studies have contributed significantly to improving the semantic quality of OSM databases.
OSM tag recommendation: OSM does not have a proper tag verification mechanism, which leads to a problem in that the OSM tags vary greatly with different contributors. A tag recommendation method is a good method for this issue and can significantly improve the quality of OSM data [
8]. There have been many studies on OSM and other open data in recent years. For example, Arnaud et al. established a tag recommendation system named “OSMantic”. By calculating the corresponding semantic similarity score, the system, which gives timely relevant suggestion tags by calculating the corresponding semantic similarity score when users submit commit them. And the system will give some semantic accuracy hints when the score is too low [
14]. Storandt et al. developed a recommendation system that only needs the POI name to recommend appropriate tags [
15]. Jilani et al. constructed the features of road elements, such as degree distribution, intermediary centrality, node number in a bounding box, etc. The model constructs and represents the road and its features by using a graph structure. They used an artificial neural network (ANN) to train the model and recommend tags [
16]. Corcoran et al. focus on geometric features and define a series of geometric features about road elements, such as degree, road curvature, parallelism, etc. Finally, their model reported 68% and 65% weighted accuracy and recall values, respectively [
18]. Hacar used geometric and semantic features to classify and recommend the leisure tags of polygons [
19]. Tag recommendation can motivate contributors to contribute correct tags which are highly effective in improving quality. Therefore, it is currently a widely studied method. However, these studies only consider geometric or other semantic features of the element itself, which mostly depend on the quality of the OSM data, and it often struggles to adapt to semantically incomplete datasets.
For geographical spatial features, each element is related to other similar elements, and only the distance determines the size of the influence [
27]. In the current research, there is a tendency to combine features of geographic elements with the spatial context, and there are many achievements. For example, Zhang et al. used geometric features and restricted features of road elements to detect label tag semantic inconsistency and other problems, while giving intelligent suggestions based on the information available in the spatial context of the problem data [
20]. Alghanim et al. used building context as a feature to analyze road elements and used a 20 M to 200 M linear buffer to count context semantics. They developed classifiers to recommend classification tags for road elements based on this method [
9]. Ali et al. identified and predicted several grassland fuzzy categories based on contextual attributes and topological features by analyzing the case of building elements and road elements versus object elements with three selected topologies. Among them, the connecting road context applies several road element categories related to park grass, including “foot” and “bike” [
21].
This entry is adapted from the peer-reviewed paper 10.3390/su152416671