Your browser does not fully support modern features. Please upgrade for a smoother experience.
Please note this is an old version of this entry, which may differ significantly from the current revision.
Recognition of hand motion capture is an interesting topic. Hand motion can represent many gestures. In particular, sign language plays an important role in the daily lives of hearing-impaired people. Sign language recognition is essential in hearing-impaired people’s communication. Wearable data gloves and computer vision are partially complementary solutions. However, sign language recognition using a general monocular camera suffers from occlusion and recognition accuracy issues.
- sign language recognition
- deep learning
- data gloves
- vision-based
1. Introduction
Recognition of hand motion capture is an interesting topic. Hand motion can represent many gestures. In particular, sign language plays an important role in the daily lives of hearing-impaired people. About 2.5 billion people are expected to have some degree of hearing loss by 2050, according to the WHO. Additionally, more than 1 billion young people are at risk of permanent hearing loss [1]. Moreover, due to the impact of infectious diseases in recent years, online communication has become important. Sign and language recognition can assist individuals with speech or hearing impairments by translating their sign language into text or speech, making communication with others more accessible [2]. In Human–Computer Interaction (HCI), sign recognition can be used for gesture-based control of computers, smartphones, or other devices, allowing users to interact with technology more naturally [3]. Facilitating communication between sign language users and non-users via video calls remains a pertinent research focus. However, the intricate nature of sign language gestures presents challenges to achieving optimal recognition solely through wearable data gloves or camera-based systems.
Both wearable data gloves and camera-based systems have been extensively explored for sign language recognition. Bending sensor gloves only focus on the degree of finger bending. Consequently, several sign language words exhibiting similar curvature patterns become indistinguishable. This limitation curtails the utility of such devices. Given the significance of hand and arm gestures in sign language, it is imperative for vision-based approaches to prioritize the extraction of keypoints data from the hands, thereby reducing interference from extraneous background elements. Occlusion presents a significant challenge to vision-based methodologies. During the acquisition of hand keypoints, monocular cameras may fail to capture certain spatial information due to inter-finger occlusions. Such occlusions often act as impediments, constraining the potential for enhancement in recognition accuracy. In gesture recognition, fingers can easily block each other, objects can block hands, or parts can become nearly unrecognizable due to being overexposed or too dark. As shown in Figure 1, occlusion problems significantly hinder the effective acquisition of keypoints. Integration with bending sensors offers a solution, enabling precise measurement of finger angles, even in regions overlapped by external entities.
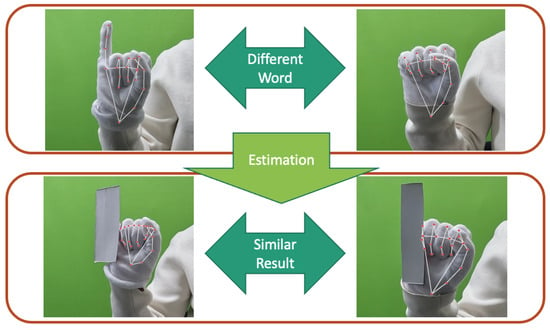
Figure 1. Occlusion problem in hand sign language.
2. Data Gloves System
The main research directions in sign language recognition include computer vision systems and systems based on data gloves. In recent years, the evolution of wearable hand measurement devices has been evident, predominantly driven by miniaturization processes and advancements in algorithms. Notably, data gloves [4,5], including IMU [6] and bending sensors [7,8], have demonstrated significant advancements in wearability, accuracy, and stability metrics. Such advancements have consequently led to marked enhancements in the results of sign language recognition leveraging these measurement apparatus. The application model for sign language recognition based on data gloves is shown in Figure 2.
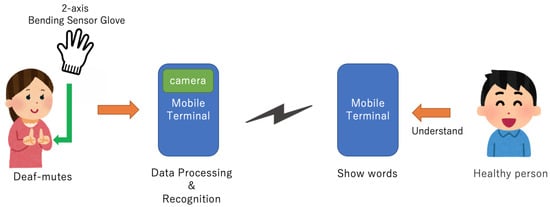
Figure 2. Application model.
3. Vision-Based Techniques
There are many studies on sign language recognition solutions based on computer vision [9,10]. With the evolution of deep learning algorithms, the extraction and analysis of features from visual data, including bone keypoint prediction [11], have substantially improved. While sign language recognition has experienced significant advancements, occlusions in images remain a notable challenge in computer vision. Himanshu and Sonia’s review discusses the effects of occlusion on the visual system [12]. There are ways to avoid occlusion problems by using a depth camera, multiple cameras, or labeling invisible objects. There are also methods to detect occlusion, such as using shadows of objects and learning information before and after occlusion using time series data. Although motion capture using a special device such as Kinect [13] and Leap Motion Controller (LMC) [14] exist, sign language recognition using a monocular camera is superior in that it can use a common camera.
Many vision-based studies based on deep learning methods have been proposed. Deep Rameshbhai et al. [15] proposed Deepsign to recognize isolated Indian Sign Language in video frames. The method combined LSTM and GRU and achieved approximately 97% accuracy on 11 different signs.
Arun Singh et al. [16] proposed a model based on sign language recognition (SLR) of dynamic signs using Convolutional Neural Network (CNN), achieving a training accuracy of 70%. Avola et al. [17] used the SHREC dataset to perform sign language recognition. SHREC is a dataset that uses a depth camera to acquire gesture skeletons. DLSTM, a deep LSTM, is used for sign language recognition. In their method, SHREC is utilized, wherein the angles formed by the fingers of the human hand, calculated from the predicted skeleton, are used as features. The training using SHREC and DLSTM enables highly accurate sign language recognition.
Existing work in hand pose estimation includes the following. Liuhao Ge et al. [18] proposed Hand PointNet. This method directly processes 3D point cloud data representing the hand’s visible surface for pose regression. It incorporates a fingertip refinement network, surpasses existing CNN-based methods, and achieves superior performance in 3D hand pose estimation. Nicholas Santavas et al. [19] introduced a lightweight Convolutional Neural Network architecture with a Self-Attention module suitable for deployment on embedded systems, offering a non-invasive vision-based human pose estimation technology for various applications in Human-Computer Interaction with minimal specialized equipment requirements. Liuhao Ge et al. [20] explained the prediction of the skeleton of the hand from image recognition. It estimates the complete 3D hand shape and poses from a monocular RGB image.
Multimodal sensor data fusion methods are crucial in systems that combine bending sensors and vision. CNN [21] and BiLSTM [22] methods can obtain information from spatial and time series data, respectively. The fusion of CNN and BiLSTM [23,24] has been used in the field of Natural language processing. Moreover, the skeleton of the hand is extracted from videos using a method called MediaPipe [25]. In addition, by using the sensor, we can expect to measure the angle of the finger more accurately even in the part that overlaps other objects. Therefore, combining sensor data with sign language recognition will make it possible to accurately predict hand movements.
A comparison of related work is shown in Table 1. Sign language recognition mainly includes two types: data-glove-based and camera-based. Systems based on data gloves generally use bending sensors and IMUs to obtain key point information on the hand skeleton, and the amount of information is less than that of camera systems. The camera system’s recognition rate will decrease due to line-of-sight occlusion, darkness, or overexposure. Therefore combining cameras and data gloves is a potential solution.
Table 1. Comparison of related research.
| Researches | Sensor | Input Features | Fusion Algorithm |
Occlusion Data |
|---|---|---|---|---|
| Our | Camera and Bending | Hand Landmarks, Finger Bending |
CNN-BiLSTM | ◯ |
| Chu et al. [26] | Bending sensor | Finger Bending | DTW | Unnecessary |
| Clement et al. [27] | IMU, Bending sensor | Orientation Finger Bending |
HMM | Unnecessary |
| Samaan et al. [11] | Camera | Hand Landmarks | Bi-LSTM | × |
| Rao et al. [28] | Camera | Hand Landmarks Face Landmarks |
LSTM | × |
| Kothadiya et al. [15] | Camera | Images | LSTM and GRU | × |
| Mohammed et al. [9] | Camera | Images | EfficientNetB4 | × |
This entry is adapted from the peer-reviewed paper 10.3390/electronics12234827
This entry is offline, you can click here to edit this entry!