3. Recommendation Types and Methods in e-Retail
3.1. Typical Applications of RS
The applications addressed in e-retail, as found in the current market landscape, can be categorized as follows:
-
An e-shop recommending products to its visitors. Important characteristics of the problem are: (a) Whether the recommendations are produced before or after a sale or an item selection action by the user. A recommendation that precedes the user’s action is based on the general needs of the users, while the one that follows a user’s selection aims at matching the current user’s action. (b) Whether the recommendations are addressed to known or unknown users. When the user is unknown, recommendations can only be based on general knowledge, such as global popularity of items and associations among items. The first recommendations are predefined, while the next ones can be adjusted to the user’s actions by a session-based recommendation algorithm. (c) The need for the RS to be dynamically adjusted by exploiting interactivity/filtering. The problem in this case is not simply to produce a list of items but involves the ability to react with intelligence to the user’s selections.
-
Personalizing promotional actions. The problem is to match to a particular user any type of action, such as to send info about a product, show an ad, make a special offer/discount, send coupons, etc., on behalf of stores, either online, offline, or both. The RS may be operating in (a) search engines or metasellers (eBay, BestPrice, etc.) or (b) individual stores, where the RS is typically incorporated into their loyalty program and used to send promotional messages, discounts, gifts, etc. A rapidly growing trend is for companies to offer to their customers mobile apps linked to a customer account. Such apps are inherently personalized bidirectional channels and one of the most promising fields for RS.
The focus of research in e-commerce [
9] falls into the broad areas of (1) understanding consumers (collect information and build user profiles), (2) delivering recommendations (match users with items and produce recommendation lists, and (3) recommendation system impacts (maximize business impact, such as user acceptance, satisfaction, and loyalty by considering issues such as timing of delivery, frequency and number of recommendations, provision of justification, and presentation issues).
3.2. Outline of Main Recommendation Approaches Applied in e-Commerce
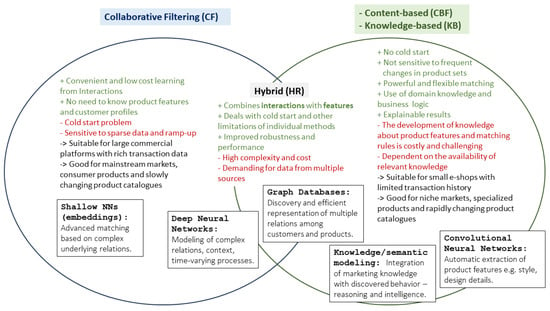
The core of every RS is the algorithm responsible for matching users with items. A variety of recommendation approaches exist, some of which are more simple, while others may combine several technologies in a complex structure. Figure 2 summarizes the main advantages and disadvantages, as well as the most typical technologies applied in each recommendation approach.
Figure 2. Recommendation approaches and state- of-the-art modeling methods.
3.3. Modeling Methods Most Commonly Used in Retail
In this section, the modeling methods most commonly used in electronic and physical retail are reviewed. Short comments for each category and related papers are summarized in Table 1.
Table 1. Modeling methods successfully applied in e-retail.
3.3.1. Rule-Based and Knowledge-Based Models
Rule-based RSs have been applied as a form of CF but also as CBF or a knowledge-based approach. Techniques were often based on adaptations of the association rule mining to the recommendation problem or on its extensions to more advanced versions. Combinations with other methods have also been reported, where the rule component was used to enhance the overall performance. Association rule mining, as proposed by Agrawal et al. [
117], although initially conceived for the market basket problem, has been widely applied to RS for e-shops by reformulating the problem. In its simplest form, instead of focusing on the global user behavior that the discovered rules express, collaborative recommendation was achieved by selecting subsets of association rules for which the antecedent included an item known to be preferred by the target user. The top-k recommendations were then the consequent of the k rules with the highest confidence [
52].
The above natural application of market basket analysis has been extended to consider ratings such as like, neutral, and dislike [
43]. Additionally, association rules can be discovered with the same methods and datasets so that, instead of expressing relations among different items, they express relations among the preferences of different users. In this complementary approach, the preferences of a particular user can be predicted from the preferences of other users. Furthermore, the rules can be generalized so that the antecedents are not restricted to items (or pseudo-items) but can express the presence of any user characteristic. In this way, rules are used to match user profiles with items, thus serving content-based recommendation. The advantages of association rule mining include its efficiency/scalability and the interpretability of the results. The latter can be important in applications such as e-shops, where it has been found that statements such as “you may like this because…” have an impact on the site’s conversion rate [
33]. On the other hand, association rules have limited expressiveness since they can only relate the simultaneous presence of items of the same type. Some of the notable early efforts to improve rule-based RS were to perform multiple-level rule mining [
53] by formulating higher-level rules that generalize lower-level ones (e.g., the rule
𝑏𝑒𝑒𝑟⇒𝑐𝑟𝑖𝑠𝑝𝑠 can be generalized to the rule
𝑑𝑟𝑖𝑛𝑘⇒𝑠𝑛𝑎𝑐𝑘). Lin and Ruiz [
54] developed an algorithm that used multiple support thresholds in order to improve the discoverability of rules for items of a different frequency, while Leung et al. [
55] proposed a CF framework using fuzzy association rules and multilevel similarity.
Ghafari and Tjortjis [
56] presented in their recent review paper considerable work on the enhancement of the association rule mining process using heuristics. Najafabadi et al. [
57] combined association rule mining with clustering to deal with the data sparsity problem and enhance the performance of CF. They considered the number of repurchases of an item as an implicit measure of liking and used it to cluster user preference profiles. Association rules were then mined and applied in the enhanced clustered dataset. In their recent work, Pariserum Perumal et al. [
58] refined the rule component by employing fuzzy logic so that the changes in users’ preferences over time are also considered. They showed success in coping with the dynamic change of users’ interests. Nair et al. [
59] mined temporal association rules by developing a symbolic aggregate approximation method to convert time series to symbols. Liao and Chang [
60] dealt with e-commerce recommendations with possible consumers’ behavioral changes by adapting association rules to the analytic hierarchy process (AHP), proposing rough-set-based rules.
An interesting rule-based approach in sustainable marketing was presented by Tomkins et al. [
24]. The aim was to discover and recommend more choices of sustainable products in market segments where there is a lack of credible information and where alternatives are limited and difficult to find. The authors developed methods to identify sustainability-minded shoppers and then used their purchasing patterns to label the preferred products as sustainable, even if these products were not officially certified. Knowledge from purchasing patterns was then combined with domain knowledge and product metadata, using a probabilistic soft logic rule framework. The method was evaluated on the Amazon platform in food products, outperforming baseline NN-based and SVD-based methods.
A more advanced rule-based approach has been used in KB approaches by employing linked data and ontological rules. In this case, complex relations can be expressed in a problem-specific knowledge domain. An inference engine is then able to apply logic and to produce secondary knowledge in the form of inferred facts [
61,
62]. Kim et al. [
61] presented how the ontology web language (OWL) can be used to formulate semantic rules and recommend apps to mobile users. Their approach was to capture attributes of products, the consumption history of users, and the social relations of users. Recommendation was driven by reasoning, which considered ontology-based semantic relations among apps and also determined the similarity between the target user and his social members. Aguilar et al. [
62] differentiated the intelligent recommendation from knowledge-based approaches as those that, in addition to rules, employ learning, knowledge assertion, and reasoning. They proposed a framework for intelligent recommendation and implemented an RS using fuzzy cognitive maps.
3.3.2. Neural Networks and Deep Learning
Neural networks have attracted researchers due to their great capability in modeling complex relations among items and users, and are nowadays probably the most rapidly developing area. With respect to the number of incorporated layers, neural-network-based models can be divided into shallow and deep networks. Shallow networks include a small number of hidden layers, most often just one. Because of their simple structure, they are suitable for problems with limited complexity, but they train faster and can easily be applied on very large datasets. On the other hand, deep networks incorporate a large number of hidden layers and have a more composite structure, which gives them the ability to learn complex relations, including contextualized and time-varying processes. Their excessive computational requirements pose restrictions on the size of the datasets that they can handle. There is thus a trade-off, which makes shallow networks preferable for huge datasets, whenever the underlying relations can be satisfactorily represented by a nonlinear classifier, while deep learning is more suitable for capturing more complex relations, provided that there are sufficient computational resources.
Shallow Neural Models
A special type of shallow neural networks, which are the most relevant to RS, are those used in embedding techniques, such as word vector representations (word2vec) [
63]. Inspired by the great success of word2vec in natural language processing (NLP), the embedding models in RS usually contain a shallow network structure [
64], which maps the items within sessions or baskets into a latent space, in which it is more effective to capture inter-item relations. When mapping items into a multidimensional latent space, their positions reflect their relations so that the latent numerical vector representation of each item contains much richer information than the original item ID. These networks are also called “wide”, because they have just one hidden layer with a large number of neurons. The approach can be generalized to represent user profiles (e.g., user2vec) and thus capture user–user and user–item relations. In their more recent papers, Barkan et al. presented an advanced item2vec version, where the user representation includes dynamic characteristics derived from the history of the user’s actions [
65], as well as a combination of item2vec with a hierarchical tag representation, in order to deal with the cold start problem [
66].
A representative work, where a shallow neural model was used for embedding-based RS, was reported by Hu et al. [
67]. Their effort was to improve personalized recommendations within user sessions by adding diversity and reducing the dependence of the result from the strict order of the user’s item selection sequence. Stalidis et al. [
38] applied an embedding-based algorithm on e-grocery RS, comparing it with a statistical factor and clustering method. It was found that the NN approach achieved comparable precision with the statistical method and, at the same time, offered the ability to overcome the limitations of the latter to be applied on large-scale problems.
Deep Neural Networks
Deep neural networks (DNNs) are multilayer perceptrons with multiple hidden layers, initially proposed by Hinton et al. [
68]. Hinton presented an unsupervised greedy layer-by-layer training algorithm, which solved the optimization problem related to deep structures. Deep learning is a relatively new field in machine learning research that has been proved particularly successful in RS. Other areas where it has shown great success are computer vision and automatic translation. In [
118], the authors provided a review of the main deep learning approaches, in which, although not specialized to RS, it clarified the main types of deep neural networks, their features, and strengths. Considering that the most important drawback of DNNs is their excessive demand for computational power and memory, the interesting and highly cited work of Iandola et al. [
69] focused on reducing the size of the deep learning models without significant loss in performance.
One of the most important abilities of DNNs is to learn complex high-order or multiple-level relations among items and users. They are good in learning from low-level features, either raw or combinatorial, such as sets of related products in a user’s interaction history or sequences of actions, to form more abstract high-level feature representations, e.g., user profiles or preferences for product attributes. The learned high-level features are then fed to subsequent components, which generalize user–item relations [
70]. Deep learning is thus often used as an auxiliary component to extract information from raw data sources, which are difficult to process directly, such as free text, images, and video. In other research work, such as the neural collaborative filtering proposed by He et al. [
71], a neural network is also used in the core of a CF setting, i.e., to represent the interactions among users and items, replacing the traditional matrix factorization techniques. Architectures based on deep networks are also found in content-based RS to enable the codification of more complex abstractions as data representations in the higher layers [
72]. The NN captures the intricate relationships hidden in low-level data sources, such as visual, textual, and contextual information, e.g., finds visual similarities between products or detects the user’s style preferences from free-text comments.
A deep learning model most commonly used in e-commerce RS is the recurrent neural network (RNN) [
73], in which, rather than considering the recommendation problem as static, it incorporates transition information by learning user actions as sequences of interdependent steps. The long short-term memory network (LSTM) is a special RNN architecture with additional memory components, which enable it to capture time dependencies in multiple time scales. Representative research work relying on the abilities of RNNs was presented by Lee et al. [
74]. The authors aimed at a RS that would be suitable for market areas such as e-grocery, where repetitive purchases of the same items are common, but also significant changes in customer needs and preferences may occur in time. To this end, they used an RNN model to learn each user’s purchasing patterns as sequences and to recommend item sets that are both relevant and diverse in multiple time periods. AN experimental comparison of their model with a CF-based model showed that the prediction accuracy and the recommendation quality are considerably improved when the purchasing order is considered in markets where regular buys of the same products are common. On the other hand, RNN-based models assume that there is a strict sequential order in items, which may generate false dependencies. Salampasis et al. [
75] compared the performance of RNNs and embedding-based RS in e-commerce, concluding that RNN achieved considerably better results, especially in predicting the next item to be recommended in shopping sessions.
The convolutional neural network (CNN) is another type of NN, which, although mainly applied to image and video recognition, has also been successful in RS [
76]. CNNs are based on filters that slide along input features, transforming them into secondary feature maps. They are of relatively low complexity and thus more efficient than other deep architectures. However, they may lose some information due to the convolution operation, and they may be limited in capturing long-term dependencies due to the restriction on the size of their filters. CNNs are typically used for extracting features from unstructured data, such as item features (style, category, etc.) from images or semantics from natural text. A representative application of CNN is the research proposed by Addagarla and Amalanathan [
77] to perform top-N recommendations in e-shopping platforms based on the visual similarity of products. They trained a CNN model in order to extract image features, and then generated image embeddings and built an index tree using the approximate nearest neighbors oh yeah (ANNOY) algorithm. According to their experiments, they outperformed other popular models, achieving an accuracy of 96.2%. In another recent paper, Latha and Rao [
78] proposed an enhanced CNN model to analyze the customers’ sentiments on the Amazon product review database.
To deal with the challenges found in basic neural networks, several advanced NN models have been proposed: (a) attention mechanism, a technique for focusing on selective input parts [
65,
79]; (b) memory network, which captures the user and item interactions through incorporating an external memory matrix [
80]; and (c) mixture models, which combine different models that can perform better in modeling sequential dependencies [
81].
Xue et al. [
82] focused on capturing higher-order item relations using a deep structure, while Cheng et al. [
83] presented a wide and deep structure, which performed better than wide embedding-based networks and deep structures alone. Soon afterwards, Guo et al. [
84] proposed a variation of the above wide and deep network called DeepFM. This included a factorization machine (FM) component and a deep component, which were simultaneously trained on a common raw-feature input. The DeepFM algorithm was able to capture low- and high-order feature interactions from raw features without the need for manual feature engineering. In Chen et al. [
85], the authors proposed a transformer-based framework for the Alibaba recommendation system. They used the sequential behavior of each user as features, and they achieved state-of-the-art performance. Another successful combination of multiple NN components is the architecture proposed by Khan et al. [
86], in which they applied a CNN for extracting contextual information from textual item descriptions, along with a W2V component for representing items and users. These modules were integrated with a CF component to provide top-N recommendations. In comparison with several competitive methods, the proposed model provided improved top-N item recommendation accuracy on the Yelp dataset.
Graph Neural Networks
In modern e-commerce RS, it is important to accurately recognize the different types of relationships in which products may participate, such as complements or substitutes, in order to generate recommendations with improved impact and explainability [
87]. For example, substitutable items are interchangeable and can be proposed to increase diversity, while complementary items may be purchased together and can be recommended for up-selling. Such information about products and their associated relationships naturally forms product graphs, which can be exploited by graph neural networks (GNNs) [
88]. GNNs have shown great expressive power in modeling complex relations by introducing deep neural networks into graph data and are widely applied for knowledge graph-based recommendation and social recommendation [
89,
90,
91,
92] and are even adapted to traditional recommendation methods, such as CF [
93,
94].
In Gao et al. [
119], the authors review the literature on GNN-based recommender systems, discuss their strengths and challenges, and provide an overview of existing research in RS applications. Recently, Fan et al. [
90] provided a principled GNN approach with social connections and user purchase history to capture the interactions between users and items. Song et al. [
89] used a dynamic graph attention network and incorporated recurrent neural networks for user behaviors in session-based social recommendation. Grad-Gyenge et al. [
95] built a graph embedding method that took advantage of the knowledge graph to map users and items for recommendation. Considering the user—item interaction, Wang et al. [
93] constructed a user—item interaction bipartite graph and proposed a graph-based CF method to capture higher-order connectivity in the user—item interactions. Another interesting paper in this area is the work of Xu et al. [
120], in which they propose their RElation-aware CO-attentive GCN model to effectively aggregate heterogeneous features in a heterogeneous information network (HIN).
3.3.3. Markovian Methods
A Markov chain is a model representing sequences of random variables and the probabilities of their states, each of which can take values from some set, such as actions in a commercial site. Markov proposed that the outcome of a given experiment can affect the outcome of the next experiment [
121]. This type of process is called Markov chain. Hidden Markov models (HMMs) are a way of relating a sequence of observations to a sequence of hidden states that explain the observations.
Markovian methods can be used for modeling time directionality and logical dependence; i.e., user action predicts the interest in an item, rather than the other way around. For example, a user who has purchased a particular camera is likely to be interested in a matching accessory; however, the interest in an accessory does not justify the recommendation of the camera. In the early work of Eirinaki et al. [
99], the training data were used to calculate the transition probability over a sequence of items. A user’s shopping sequence was then matched to the calculated sequence, and the transition probabilities were used for recommendation by selecting the candidate items with the highest probability. An HMM model was used by Shani et al. [
100], who proposed an RS based on the Markov decision process (MDP). The states of the MDP were
k-tuples of items, the actions corresponded to the recommendation of an item, and the rewards to the benefit from selling an item, e.g., the net profit. The state following each recommendation was the user’s response, such as selecting the recommended item, selecting a nonrecommended item, or nothing. A variation of the basic Markov-chain-based RS was proposed by Zhang and Nasraoui [
101],, who combined a first- and second-order Markov model to make more accurate web recommendations. In their more recent work, Le et al. [
102] developed a hidden Markov-model-based probabilistic model for next-item recommendations by incorporating additional factors like context features to leverage the recommendation accuracy. Another important variant was to adopt a factorization method on the transition probability to estimate the unobserved transitions [
103].
3.3.4. Graph Database Modeling
The use of graph databases (GDBs) is one of the newest approaches to RS engine modeling. In a GDB, data are represented by graphs and stored using nodes, edges, and properties (or attributes). A graph database is a data model that focuses on entities and the relations between them. Rule-based recommendation systems can be implemented using graph databases. Konno et al. [
104] modeled a recommendation system based on data-driven rules. They applied a two-layer approach to retail transaction data, where the knowledge graph database included a concept layer for semantic ontology representation and an instance layer for associating sets of retail business data to concept nodes. Using the Neo4j graph database [
122], a clustering step was adopted to group customers into communities using RFM (recency, frequency, monetary) analysis [
123]. Then, a list of recommended products was created for each group with a reasoning engine. The performance of the system in terms of time efficiency and the novelty of recommendations was found to be reasonably good. Another rule-based recommendation approach is described in Sen et al. [
105], where the Neo4j tool was used for data modeling and product recommendation purposes. Raw text data were modeled on an Neo4j graph database with Cypher queries to build a graph data model. The proposed model captures the influence of a product on another product so that if a user bought the influential product, then the influenced products can be recommended by the system to the users. The authors demonstrated an RS based on the graph data model and compared it with the Apriori algorithm.
A graph-based solution developed using the Neo4j graph database was presented by Delianidi et al. [
124]. In this paper, the authors focused on the efficient operation of the next-item recommendations for an e-commerce retail store. With the appropriate data modeling, by defining nodes and relationships between the nodes and by executing Cypher queries, the system first learns the pairs of co-occurring products that appear in the same sessions and calculates their degree of similarity. The next product recommendation is then derived from the similar products co-occurring with the product that the user is currently viewing.
3.3.5. Matrix Factorization
Matrix factorization (MF) is the most representative technique in CF and probably the most widely adopted in early recommenders. It fits very well to the prediction of user ratings, dealing with the limitations posed by sparse data. Several methods have been developed for performing matrix factorization, the most typical of which are singular value decomposition (SVD), principal component analysis (PCA), probabilistic matrix factorization (PMF), and non-negative matrix factorization (NMF) [
107]. The basic idea in all cases is to transform the sparse
𝑢𝑠𝑒𝑟𝑠×𝑖𝑡𝑒𝑚𝑠 matrix into a latent factor space of low dimensionality, where user–item interactions are represented by dense vectors, with minimum loss of information. Recent research in e-commerce RS that is based on MF, at least at its traditional form, is relatively limited, since it has moved towards neural networks that perform better in representing user–item interactions and are not limited to linear relations [
71]. As an example of recent work based on MF, Le et al. [
108] proposed an advanced factorization machine that introduces the notion of basket and is aiming at detecting the customer’s latent intentions. The model then predicts the items that the customer may still need to complete his/her shopping goal and adjusts the recommendations according to the items already in the basket.
3.3.6. Natural Language Processing Methods
Most of the e-shops, as well as search engines, are nowadays collecting customer reviews that contain valuable information about customers’ needs and preferences. RSs can benefit by extracting sentiment and semantic information from such natural text. Recommendation models based on natural language processing (NLP) may have various approaches: sentiment analysis, word representation with embeddings, topic detection, keyword extraction, and in general any task that makes use of a free text description. Srifi et al. [
109] presented research efforts where CF techniques were applied on customer review texts. The technologies used for NLP mostly involve shallow or deep neural networks, and the approaches followed can be categorized as those based on words, on topics, or on review sentiment. Representative recent papers on e-shopping RSs that employ NLP are:
In Tarnowska and Ras [
110], the authors proposed a customer loyalty improvement RS employing an unstructured database. After transforming the unstructured text to structured, they applied sentiment analysis on the comments of their users to produce recommendations. In another study, Sharma et al. [
111] built a system for product recommendations using the titles of the products as the text features and the word2vec methodology for creating embeddings for the similarity between them. Shoja and Tabrizi [
112], showed that the insights from the customers’ text reviews are crucial for RS. They applied the latent Dirichlet allocation method and association rules to extract knowledge from text. In a similar research work [
113], the authors implemented a fuzzy-logic-based product recommendation system using sentiment analysis and ontologies. They showed that the negativity of text reviews affects significantly the users’ behavior.
The current state of the art in incorporating sentiment analysis, at least as regards the technologies used, is the methodology proposed by Karn et al. [
114]. The authors developed a sophisticated hybrid sentiment analysis component, employing deep neural networks (Bert-MCARU-GP-SoftMax model). This model was combined with a hybrid RS engine, which consisted of a CF component employing support vector machines (SVMs), a CB component based on item text descriptions and the term frequency-inverse document frequency (TF-IDF) algorithm, and a deep NN decision component employing the growing hierarchical self-organizing map (GHSOM). By comparing their methods with four competitive methods on an Amazon fine food dataset, they established that through the incorporation into conventional RS of additional information extracted from user reviews, the performance of personalized recommendations to e-shop customers is considerably improved.