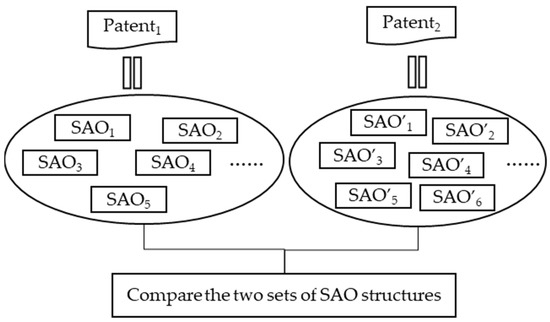
Patent application is one of the important ways to protect innovation achievements that have great commercial value for enterprises; it is the initial step for enterprises to set the business development track, as well as a powerful means to protect their core competitiveness. Manual measurement in patent detection is slow, costly, and subjective, and can only play an auxiliary role in measuring the validity of patents. Protecting the inventive achievements of patent holders and realizing more accurate and effective patent detection were the issues explored by academics. There are five main methods to measure patent similarity: clustering-based method, vector space model (VSM)-based method, subject–action–object (SAO) structure-based method, deep learning-based method, and patent structure-based method.
1. Patent Similarity
The clustering-based PIDM puts all detected patents together to generate one or more clusters, and those clustered with the target patents are more likely to be infringing patents. In particular, Jeong [
8] extracted problem solved concept (PSC) terms and constructed a PSC-based map, clustering and evaluating them to explore opportunities for new patent creation. Zhu [
9] combined a self-organizing neural network (SOM) with fuzzy C-means (FCM) clustering to obtain a SOM-based FCM algorithm, which improved the quality of clustering, automatically identified patents similar to the patents under investigation and designed a patent infringement detection system. Lee et al. [
10] utilized a principal component analysis (PCA) algorithm to cluster and visualize keyword space vectors. Yoon et al. [
11] converted each patent document into a vector by extracting keywords, used PCA to reduce dimensionality, and finally performed SOFM with the vector as input to create patent maps for clustering purposes. Lai et al. [
12] proposed a method, called the bibliometrics-based patent co-citation approach, by analyzing the co-citations of target patents using clustering methods for cited patents and creating a patent classification system. However, the clustering-based approach can only cluster several different classes, and there will be a large number of patents in the same class as the target patent, which cannot effectively reduce the examination work.
VSM-based PIDM converts text into spatial vectors and feeds into patent similarity by comparing spatial vector similarity. Magerman et al. [
13] demonstrated patent similarity using VSM and latent semantic analysis. Yoon et al. [
14] used the Doc2Vec model [
15] to demonstrate patent similarity and predict the future direction of technology development from the constructed patent network. The Doc2Vec model was improved from the Word2Vec model [
16] by replacing the original spatial vector for word detection with the spatial vector for paragraph detection. SAO2Vec [
17,
18] is an improved spatial vector model based on Doc2Vec. It is easier to construct the vector space model, but the dimensionality of the vectors is positively related to the size of the prediction, and the vectors constructed by large-scale prediction are high-dimensional and sparse, which makes the computation more complicated.
SAO-based PIDM analyzes information such as sentence lexicality and obtains the desired structure using natural language processing (NLP) techniques. Park et al. [
19] used the WordNet-based SAO structure to measure patent similarity and used multidimensional scaling to map patent relationships to a two-dimensional space and group patents that could infringe. Li et al. [
20] used the SAO structure to prove patent similarity and extended it by using the Sorensen–Dice index [
21,
22], which has good flexibility and robustness. Yoon [
23,
24] also used the SAO structure to prove patent similarity and then used similarity to analyze potential competitors and partners. Park et al. [
25] proposed a patent infringement map based on SAO semantic similarity to identify patent infringement. The calculation of patent similarity based on SAO structure has a serious dependence on the extracted SAO structure, which requires manual annotation if a higher quality SAO structure is to be obtained.
Deep learning developed rapidly in recent years, with significant achievements in text, image, and radio, and many researchers applied deep learning techniques to the field of patents. Lu et al. [
26] proposed a patent citation classification model based on deep learning by selecting convolutional neural networks (CNN) at the document encoding level and introducing multilayer perceptron to gradually compress and extract the most relevant features and adjust the nonlinear relationships. Ma et al. [
27] constructed a patent model tree and compared the advantages and disadvantages of CNN, RNN, LSTM, and Siamese LSTM, and established that Siamese LSTM [
28,
29] has obvious advantages among them. Deep learning PIDM uses neural network models for vectorized representation, although the accuracy rate is high, the model is poorly interpreted, the data for constructing specialized fields are difficult to obtain, and a large amount of manual involvement is required at the initial stage.
The composition of a patent includes several structural components, such as inventor, application number, filing date, IPC classification number, abstract, claims, etc. The last patent-based PIDM considers these structures. Zhang et al. [
30] used the IPC classification model and semantic model to evaluate patent similarity by constructing patent terms into different layers of trees, each layer having its own weight value, and equating patent similarity by calculating tree similarity. Fujii et al. [
31] used punctuation to segment the claims and Okapi BM25 [
32] to obtain paragraph similarity, and then cumulatively obtained overall patent text similarity. Among citation methods [
33], Lee et al. [
34] proposed a stochastic patent citation analysis method, and Rodriguez et al. [
35] proposed a similarity measure in citation networks that exploited direct and indirect co-citation links between patents. Klaans and Boyack [
36] compared the accuracy of direct citation-based, bibliographic coupling, and co-citation in representing knowledge classification. In general, the classification in the direct citation classification was better than that in the other classifications. Wu et al. [
37] also proposed a method for evaluating patent similarity by considering direct and indirect citations. Cheng et al. [
38] used USPC and IPC construction techniques and functional class matrices to demonstrate patent similarity. Similarity based on the patent structure is more relevant, but for patent infringement, each part has a different weight, and manual weighting is resource-intensive and less feasible.
2. SAO Semantic Analysis
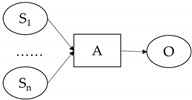
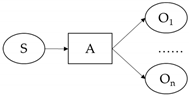
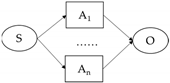
SAO structure is a construction in which the subject (S) and object (O) of a sentence are related under action (A), and an SAO structure simply reflects the content of a sentence, giving a complete picture of how two things are related or affect each other. For example, in the sentence “The shower spray water”, “shower” is the subject, “spray” is the action, and “water” is the object. Similar to the SAO structure, the subject–predicate–object (SPO) structure, which consists of subject elements, object elements, and the relationships between them, can be considered a semantic network and is widely used for knowledge discovery in biomedical literature [
39], while SAO is commonly used for text mining in patent documents [
40].
SAO structure is a technical tool for NLP, which is favored by scholars and received wide attention, and the ability of SAO structure extraction became more powerful in the process of the continuous improvement of machine learning algorithms. For example, Kim et al. [
41] analyzed the “for” and “to” phrases and verbal forms of object elements to effectively explore the purpose and effect of the technique in depth. Miao et al. [
42] used the purpose relationship between the SAO structure and the technology–relationship–technology structure to mine technology solutions and functional information. He et al. [
43] proposed a potential technology requirement identification model based on semantic analysis of the SAO structure. They realized the layout and visualization of requirements based on the technology life cycle to guide the direction of technology development and optimize resource allocation. Li et al. [
44] used the Unified Medical Language System to evaluate the similarity between SAO structures, which was introduced in the field of medical patents. Yoon [
23,
24] also used SAO structures to demonstrate patent similarity and then used similarity to analyze potential competitors and partners. Using NLP techniques, rapid mining of SAO structures from text can be achieved.
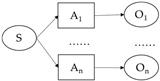
The structure of the SAO patent triad is extracted from the text, and usually the subject and object are in the form of nouns, representing the performer and the event performed, respectively. The predicates are all used as actions to link the subject and object [
45]. A set of SAO structures may be included in a single sentence, or multiple sets of SAO structures may be included. In the patent text, the SAO structure of the patent is summarized as shown in
Table 1. The similarity between patents can be translated into the similarity of the SAO set, as shown in
Figure 1.
Figure 1. Extraction of SAO.
The key point of using the SAO structure applied in the patent field is the quality of the SAO structure, so manual extraction is the most accurate method, but this method is not possible in the presence of a large number of patents, which requires a lot of effort and is very inefficient. However, with the development of NLP, it became possible to extract SAO structures using NLP tools.
3. Contour Detection
Contour detection refers to the process of extracting the target contour by ignoring texture and noise interference within the image [
46]. Traditional contour detection is broadly classified into three types: pixel-based, edge-based, and region-based contour detection methods. The pixel-based approach is concerned with discontinuity of the image boundary, and the occurrence of sharp changes in pixels around the contour indicates that a regional change is generated. This process introduced linear filtering [
47,
48,
49], such as the Prewitt operator, Sobel operator, and Canny operator. Later, many scholars proposed the use of higher-level features such as luminance, color, and texture gradients [
50], and the combination of these features improved robustness. The edge-based approach considers the overall image information and divides the contour extraction process into edge detection and edge grouping [
51]. Individual edge points are collected and then formed into a continuum, irrelevant data are eliminated, and the remaining data are rearranged, with each grouping corresponding to a specific object [
52]. The early determination of edge elements in the likelihood of being in the same contour was based on empirical statistics, after which Elder [
53] added Bayesian inference methods, while Mahamud [
54] introduced the concept of contour saliency to identify smooth closed contours. Finally, with regard to region-based approaches, Arbelaez et al. [
55,
56] proposed the concept of ultrametric contour maps, in which local contrast and regional contribution are involved in the dissimilarity of adjacent regions, and the key to their method lies in the definition of hyperparametric distance. The region-based method is more stable to noise and can adapt to relatively uneven contours.
This entry is adapted from the peer-reviewed paper 10.3390/systems11060294