1. Introduction
Process segmentation of machine tool data is essential for quality control and process improvement to differentiate varying operation states [
6]. These varying operation states are characterised by sub-sequences which can result in variations in the same time series. This can influence the data processing or possible predictions. Because of this, the segmentation process divides the time series into sub-sequences to maximise comparability within a group [
7]. Here, two cases have to be differentiated: online and offline pattern recognition. In offline pattern recognition, the whole time series already exists and is known to the algorithm. In online pattern recognition, the analysed time series is not fully known. Because of this, in the instance of recognition, not all possible sub-sequences and data points are known for comparison [
8].
Process segmentation is needed in the first stage to differentiate a number of features that characterise the time series to recognise the starting point of new sub-sequences. In the next stage, the endpoint of the sub-sequence and the start point of the next sub-sequence, respectively, have to be recognised. The last step is the assignment of a group with maximum comparability. The change in the system behaviour which likely characterises a different operation state can be either a trigger or an anomaly [
9,
10]. Anomaly detection in time series is a well-researched area, with various methods being employed, and they can be classified into different categories. Ref. [
6] presents a comprehensive overview of these methods, which include pattern matching, clustering and predictions, and distance-based, andstatistical and probabilistic methods.
In their study, ref. [
11] developed an unsupervised anomaly detection system for industrial control loops using
an extreme learning machine classifier. They achieved this by mapping the data to a two-dimensional space and then setting limits in that space. To do this, they applied several approaches, including principal component analysis, beta Hebbian learning and curvilinear component analysis. Of these approaches, beta Hebbian learning was found to perform the best. Other researchers, such as [
12], have developed approaches that detect point and collective anomalies using sliding windows and autoencoders, respectively. Predictive maintenance approaches also focus on feature extraction using methods like FRESH [
13]. These features can be used as high-quality inputs to supervised Machine Learning models to achieve high accuracy. However, labelled training data is needed for supervised learning, which may not always be available. Ref. [
14] presented an approach based on time series segmentation followed by anomaly detection, which detects anomalies using a combination of a Recurrent Neural Network for feature extraction and a Convolutional Neural Network-based autoencoder. However, this approach does not provide a clear division into actual processes, making the clear assignment of anomalies to subprocesses potentially difficult.
In conclusion, process segmentation of machine tool data is an important step for process analysis and comparability of operation states. The number of produced parts can influence the choice of algorithm for process segmentation, especially because most Machine Learning-based methods need a large training dataset for accurate estimations. Especially for small production runs, statistical process control methods may be more appropriate due to the limited amount of data available [
10]. Here, approaches that work without fixed thresholds to adapt themselves for autonomous usage can enable a broader usage. This motivates further research into the combination of statistical methods with self-adapting thresholds for an optimised process segmentation.
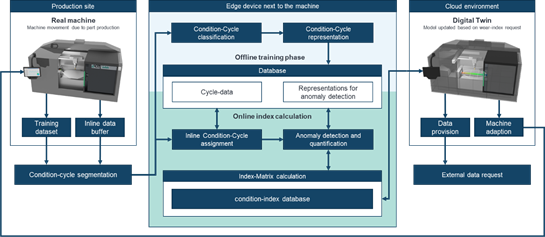
Figure 1. General overview of the presented approach.
2. Tool Wear Detection
During machining, the cutting tool experiences different wear mechanisms, which lead to reduced tool life, poor surface finish and increased tool replacement costs. Therefore, the development of tool wear detection systems has become a focus point of the machining process to optimise tool usage and improve manufacturing efficiency [
15]. Different types of wear mechanisms can occur in machining, including abrasive, adhesion, flank and crater wear. Among these, flank and crater wear are the most relevant wear mechanisms [
16]. Flank wear occurs on the flank face of the cutting tool due to rubbing against the workpiece, while crater wear results from the deformation of the tool surface due to thermal and mechanical stresses during machining. Flank wear can cause an increase in cutting force and chatter vibrations, leading to poor surface finish and dimensional accuracy [
17]. Crater wear can cause a reduction in tool strength and stability, leading to tool breakage [
16]. Different sensor principles can be used to detect these wear mechanisms.
Ref. [
18] used acoustic emission (AE) sensors in combination with a Machine Learning approach to detect the flank wear during machining processes in relation to the cutting speed and cutting time. The achieved quality in the prediction of the tool wear highly correlates with the usage of a feature for the cutting time. Through this feature and additional information on the cutting speed, a reduction in the mean classification error, too, in the worst case of 11.19%, could be achieved [
18]. In opposition to this feature, the preprocessing-based approach from [
19] used a dynameter to continuously measure the process force and classify tool wear based on the raw force signal. For this classification, a Convolutional Neural Network (CNN) classifies three different phases of the tool’s lifetime. Here, it is differentiated between a rapid initial wear phase, a uniform wear phase and the end of the useful life of the tool.
Ref. [
19] achieved a classification accuracy of 90% for these classes. Ref. [
21] uses vibration signals of the workpiece in combination with a support vector machine (SVM) as a classifier. The differentiated classes were also the same three phases as in [
18]. Ref. [
21] focused in their research on achievable accuracy through specific combinations of dimension reduction and varying kernels for the SVM. Through this, they could achieve, in the optimal case for their experiments, an accuracy of up to 96.13%. Ref. [
22] uses a Deep Learning approach combined with images of different tools to classify in the first stage, the visible tool, and in the next step the degree of wear. The classification of the toll type [
22] could achieve an accuracy of 95.6%. The results were 73% for the tool wear, but this could only be achieved on the test data. Unknown and slightly disturbed data could only achieve a coefficient of 0.37%. Ref. [
23] also uses an indirect approach for the detection of tool wear through the spindle power. Through the wear progress on the tool, the necessary power for a constant milling process increases. They acquire the power through an additional sensor which in the next step will be processed through a neuronal network for a curve fit to estimate the Remaining Useful Life (RUL). This enables prediction with a mean estimation error of <2 min for RUL.
The current approaches for tool wear detection have some limitations. AE sensors are non-invasive and can detect tool wear in real time. However, they can be affected by environmental noise and may require complex signal processing because of high sample rates [
24]. Force sensors can provide accurate and reliable cutting force measurements, but they are costly and require contact with the workpiece, limiting their application to small sizes. Vibration sensors can detect wear in real time and are non-invasive. But they can be affected like AE sensors through external vibrations and also require complex signal processing. Optical sensors, in contrast, are non-contact and can provide accurate measurements of tool deformation, but they require a clear view of the tool surface and may be affected by ambient light [
22]. Additionally, these sensors require frequent calibration and can be affected by tool geometry changes, which can lead to necessary retraining or possible modification steps in signal processing. The data processing methods depend on the application and machining process. Feature extraction and selection can reduce the dimensionality of the data and improve the accuracy of the wear detection system. However, they may require prior knowledge of the wear mechanism and the machining process [
18] Machine Learning algorithms can provide accurate and reliable wear detection, but they require a large amount of labelled data and may require frequent updates as the machining process changes.
In conclusion, tool wear detection is a critical component of the machining process to optimise tool usage and improve manufacturing efficiency. However, the addition of specialised sensors has downsides as an additional cost, and, more importantly, the addition of a new component increases the failing potential.
3. Current-Based Component Wear Detection
Condition monitoring of drive components is important in the industry, and several approaches have been developed for detecting and characterising wear mechanisms. Two different approaches are used to monitor these different effects. A distinction is made between detection by sensors and “sensorless” detection. For the usage of machine tools, additional sensors should always be avoided, as this results in costs and failure potential. In addition, there is the necessity of corresponding experts for the integration and evaluation of results [
25]. Sensorless detection in this context describes using existing information, such as the motor current, position, etc. (soft sensors), that can be extracted from the plc [
25]. There are many approaches for condition monitoring of components through investigations of the motor current [
26]. These range from wear detection of motors and bearings to characterisation [
14,
27] and system property change monitoring [
28] he different system properties can result from geometrical differences in the components or different forms of wear [
14,
29]. Research results in condition monitoring by the motor current of ball screws drives (BSD) will be reviewed in depth. As an essential high-precision drive component, subject to high loads and thus wear due to the drive function, ball screws are particularly relevant for condition monitoring.
The different wear mechanisms in ball screws can be classified into four tribological categories: adhesion, surface disruption, abrasion and tribochemical reaction [
30]. These mechanisms cause a decrease in ball diameter, which leads to a backlash and loss of preload, affecting the stiffness of the ball screw [
31]. This phenomenon is the basis of condition-monitoring approaches. Ref. [
32] is researching the estimation of ball screw wear based on the motor current of the actuating servo motor and other control variables such as feedback position and motor torque. For this purpose, ref. [
32] uses quasi-sweep sine wave motions of varying. By relating the change in position and motor torque amplitudes the degree of wear is estimated. However, this approach has optimisation potential due to a high estimator error of up to 27%. Ref. [
33] also deals with the prediction of the wear of a BSD. The approach also addresses the prediction of wear based on the motor current but without any additional reference runs. This is achieved with additional compensation current. Identifying the rapid traverse in the first step and determining the resulting current from the three phases in the next step enables the evaluation and statistical characterisation of the signals. By progressively increasing the ratio of the specific band energy, ref. [
33] successfully classify and characterise a normal lifetime phase, an accelerated wear phase and a strong wear phase. However, this requires the use of external, more expensive measurement systems. External sensors are also used by [
34] to obtain the motor current signal. The aim of their work is fault diagnosis of BSD in industrial robots based on the motor current alone. For this purpose, a data processing pipeline using a short-time Fourier transform and wavelet decomposition is proposed. Statistical parameters are extracted and selected for further processing within the pipeline based on an evaluation measure. Using logistic regression, the wear behaviour is classified, thus enabling the diagnosis of faulty BSDs. Through this, they do not require any special reference runs. The disadvantage is that only defective conditions can be detected and not predicted. Ref. [
28] deals with detecting preload losses, which can be traced back to wear. Here, too, external sensors are used, which, in contrast to [
33], can be easily retrofitted. These are Hall sensors and acceleration sensors to detect changes in the natural frequency response of a dynamic feed axis model. The change in the natural frequency response can be used to infer the change in stiffness and, ultimately, the loss of preload. For this purpose [
28], establish a dynamic model of the feed axis. Using the test bench, the natural frequencies of the feed axis are detected through defined motion sequences. The natural frequencies are validated using other types of excitation. This enables the preload to be classified as low, normal, or overly high. Thus, the positioning error of the carriage can be traced back to the change in the natural frequency.
In conclusion, component wear detection is a critical factor in predicting downtimes or changes in the kinematic characteristics of the drive train. However, the addition of specialised sensors for wear detection in ball screw drives has the same downside as tool wear monitoring.
4. Self-Adapting Digital Twins
Digital Twins are virtual replicas of physical systems that can be used to simulate, monitor and control their real-world counterparts. They are typically built by combining data from sensors, models and other sources to represent the physical system digitally [
35]. One potential downside of Digital Twins is that they are typically designed with a fixed set of parameters and configurations that may not be optimal in all situations [
36]. This is where self-adapting Digital Twins come in. Self-adapting Digital Twins, also known as adaptive Digital Twins or self-optimising Digital Twins, are designed to adjust their parameters and configurations in response to changes in their environments or objectives [
37]. Using Machine Learning algorithms and optimisation techniques, self-adapting Digital Twins can analyse data from sensors and other sources in real time and predict the system’s behaviour [
38]. Without human intervention, they can learn from their experiences and optimise their performance over time [
37]. This ability to adapt to changing conditions and objectives makes self-adapting Digital Twins a powerful tool for improving physical systems’ efficiency, reliability and safety. Several frameworks exist to implement self-adapting Digital Twins, including model-based and data-driven approaches. Model-based frameworks use mathematical models to simulate the behaviour of physical systems and optimise their performance, while data-driven frameworks use Machine Learning algorithms to analyse data from sensors and other sources and make predictions about system behaviour [
5]. Realising self-adapting Digital Twins requires a combination of hardware and software components, including sensors and actuators for collecting data and controlling physical systems, and Machine Learning algorithms and optimisation techniques for analysing and adapting to changes in data and objectives. Advances in sensor technology, Machine Learning algorithms and Cloud Computing infrastructure have all contributed to the development of self-adapting Digital Twins [
5]. Self-adapting Digital Twins can realise several positive effects, including improved system performance, reduced maintenance costs and increased operational efficiency. By adapting to changes in their environments and objectives, self-adapting Digital Twins can help ensure physical systems operate at peak efficiency and minimise the risk of failures or downtime.
5. Data Transfer for Digital Twins
The direct data dependency shows the necessity of considering the data flow between the sensor and Digital Twin. Here, two different structures of data flow exist in state of the art [
39]:
- (a)
-
Direct data flow from the data source into the Digital Twin;
- (b)
-
Indirect data flow from the data source through a processing step into the Digital Twin.
Due to substantial differences in the existing infrastructure, there are significant differences in the possible data rate between the data source and Digital Twin. Ref. [
39] distinguishes between volatile and non-volatile data. Volatile data is data with a higher frequency that results, for example, from axis movement or material flow. Non-volatile data describes data that presents relatively static information, such as a product or machine list. The limited processing capacities of a Digital Twin require local (pre)processing for highly volatile data [
5]. The pre-processing function is fulfilled by Edge Computing, which sits directly at the application through an Edge Device (ED). Edge Computing pursues the goal of processing data and executing applications closer to the source of the data, i.e., to the end devices and sensors, to avoid latencies or to realise time-critical processing in the first place. For this purpose, computing and storage resources are provided as micro data centres at the network’s edges [
40]. The disadvantage of an individualised and decentralised computing architecture using Edge Computing is, on the one hand, the efficiency and, on the other hand, the resource commitment [
41]. Centralised instances or defined data centres enable a considerably more efficient operation of the corresponding computing resources [
42]. Additional soft factors, such as the shortage of skilled personnel, continue to make the local operation of computing resources or an individualised processing structure more difficult [
43]. On the other hand, there are centralised networks in the form of cloud infrastructure. This represents a global network in which IT services of varying complexity and for different user segments can be provided [
42]. Infrastructure and platform providers offer basic services and the necessary application infrastructure, while application providers enable flexible and easy-to-maintain application operations. This enables low capital lockup, reduced complexity of IT operations and the ability to respond quickly and flexibly to changing capacity needs [
44].
Digital Twins can be managed centrally in the company or across companies using a cloud infrastructure structure, for example, or integrated into an Edge Device like the pre-processing [
44]. Ref. [
45] argue that the centralisation of different Digital Twins of the same equipment opens the possibility to exchange information among each other and thus achieve optimisation of used models. Ref. [
41] shows that a combination of edge and cloud computing can ideally exploit computational and transfer capacities when adequately distributed. This motivates a combined use of the technologies. In which the Digital Twins are managed centrally and highly volatile data is processed on edge, i.e., close to the process for latency reduction, and only the resulting indices can be transferred at a significantly lower frequency and in a smaller band.
This entry is adapted from the peer-reviewed paper 10.3390/machines11111032