Your browser does not fully support modern features. Please upgrade for a smoother experience.
Please note this is an old version of this entry, which may differ significantly from the current revision.
The explosive growth of online short videos has brought great challenges to the efficient management of video content classification, retrieval, and recommendation. Video features for video management can be extracted from video image frames by various algorithms, and they have been proven to be effective in the video classification of sensor systems.
- video classification
- cross-modal fusion
- video features
1. Introduction
In the past few years, the emergence of short video applications has exploded, such as Tiktok, YouTube Shorts, Likee, Bilibili. Most of the short videos in these video applications are tagged when they are released, enabling users to browse videos by category and search within a certain category [1]. These short videos are typically characterized by their brief duration, diverse content, and a wide range of topics. However, the exponential increase in the number of short videos poses significant challenges in terms of effectively classifying and managing this vast video content.
At present, the application of deep learning methods in the classification of violent videos [2] and social media videos [3][4] has achieved good results. However, due to the unique characteristics of short videos, such as the short duration, large amount, and many spliced contents, it is still a difficult task to classify short videos. Research on short video classification predominantly employs single-modal approaches which utilize either visual or textual features for classification. Visual feature extraction involves the extraction of image features from video frames, encompassing attributes such as color histograms, texture features, and shape characteristics. Studies have demonstrated the high efficacy of visual features in short video classification, as they facilitate the capture of visual information within the videos, including objects, scenes, and actions. Traditional techniques for visual feature extraction comprise the histogram of oriented gradient (HOG) [5], histogram of flow (HOF) [6], and motion boundary histograms (MBH) [7]. To leverage the complementarity of these three feature types and enhance the representational capacity of video features, researchers have introduced the dense trajectories (DT) algorithm [8] and its improved variant, the improved dense trajectories (IDT) [9]. These algorithms are both based on decision tree classification approaches, and utilize HOG descriptors as image features derived by statistically analyzing the gradient information of images.
In addition to visual features, textual features are also widely employed in the field of short video classification. These textual features typically originate from metadata information such as video titles, descriptions, and tags. The advantage of textual features lies in their ability to provide semantic information about the video content, thereby enhancing classification accuracy. Researchers have developed various methods for extracting textual features, including those based on traditional natural language processing techniques such as the bag of visual words (BOVW) model [10], as well as deep learning-based methods such as recurrent neural networks (RNNs) and attention mechanisms. The core idea of BOVW is to represent images as a collection of visual words and use the frequency of word occurrences as the image’s feature vector [11]. Firstly, local features are extracted from the image, such as scale-invariant feature transform (SIFT) [12], local binary patterns (LBP) [13], color histograms, etc. Subsequently, all local features are clustered into several clusters, with each cluster corresponding to a visual word. The frequency of each word’s occurrence is computed, and finally, this feature representation is employed for tasks such as training classifiers. The convolutional neural networks (CNNs) primarily decompose videos into a sequence of frames and then extract features from each frame through multiple layers of convolutional and pooling operations. These extracted features from all frames are aggregated and used for classification with the assistance of a classifier.
However, at present, users upload short videos with great randomness and divergence, and users’ understanding of video categories generally varies and there is more and more false information, resulting in inconsistent categories marked by users [14]. This inconsistency not only affects the accuracy of the search and recommendation results of video content categories, but also in the face of these challenges, users are more inclined to make subjective judgments through visual content to meet their personal needs. In addition, there is a significant difference between video content features and hashtag text features. It is difficult to match accurate hashtags to meet users’ content consumption needs due to insufficient video text information in the method of searching for tags with the same text in videos [15][16]. Moreover, some videos usually do not contain classification information, and video feature analysis is mainly based on understanding visual image information, but lacks text semantic mining, resulting in an underutilization of semantic information [17][18].
Thus, short video classification is essential to determine the category of a video so that videos without user-labeled categories can also be organized in the same way as videos with category labels. A distinct video classification framework is introduced herein which leverages both textual and visual features in a new way. Scholars bring together visual features obtained from the training dataset with text features extracted from subtitles across modalities, and integrate them into joint features for downstream classification tasks. Specifically, the text feature uses the bidirectional encoder representation from the Transformers (BERT) pre-training model, adds context using the attention mechanism, and solves the parallel calculation between sentences [19][20][21]. Video features are extended from image space to spatio-temporal three-dimensional volume through a self-attention mechanism, which treats video as a series of patches extracted from a single frame. Like the vision Transformer (VIT), each patch undergoes linear mapping into an embedding, to which positional data are subsequently incorporated [22]. The proposed framework uses textual and visual features to classify short videos, which improves the accuracy of short video classification.
2. Short Video Classification Framework
Despite considerable progress having been achieved for image representation architectures over recent years, the realm of video architecture remains devoid of a distinctly defined forefront structure. The current main video classification architectures are shown in Figure 1, where k represents the count of frames within a video, and N represents a subset of adjacent frames of the video. The main differences between these frameworks are: (1) The first differentiation lies in determining whether the convolution and layer operators utilize 2D (image-based) or 3D (video-based) kernels [23][24][25]. (2) Another key variation involves the nature of the input provided to the network. This can be limited to just an RGB video or expanded to encompass both an RGB video and pre-computed optical flow [26][27][28]. (3) In the context of 2D convolutions, a significant consideration is how information propagates across frames. This can be achieved through the incorporation of temporary recurrent layers such as SlowFast or the application of feature aggregation over time [29][30][31].
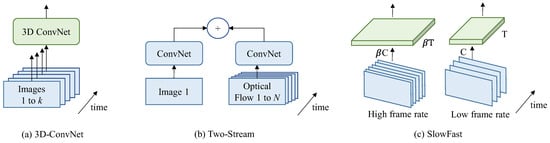
Figure 1. Different types of video classification architectures (a) 3D-ConvNet, (b) Two-Stream and (c) SlowFast.
2.1. I3D Networks
Traditional 2D convolutional neural networks have been a huge success in tasks such as image classification, but there are some challenges in video classification tasks. To make the most of temporal information and motion features in videos, researchers proposed a variety of three-dimensional convolutional network (3D ConvNet) models as shown in Figure 1a [23]. The inflated 3D ConvNet (I3D) model is extended on the basis of a two-dimensional convolutional network. Specifically, it constructs a three-dimensional convolutional network structure by copying and filling the weights of the pre-trained two-dimensional convolutional network in the time dimension [24]. This approach enables the I3D model to simultaneously process features in both spatial and temporal dimensions, thereby better capturing dynamic information in videos. To efficiently train the I3D model, two strategies are adopted: pre-training of the second-rate network and multi-scale cropping [25]. First, by pre-training on a large-scale video dataset, the I3D model can learn rich visual features. Then, it is fine-tuned on the dataset of the target task to improve its performance on the specific task. In addition, to take advantage of the spatio-temporal information in the video, a multi-scale cropping strategy is also introduced, which is trained by extracting multiple cropped segments of different scales from the video. Applications of I3D models have achieved remarkable results in several video understanding tasks.
2.2. Two-Stream Networks
Simulations of high-level changes can be achieved by the long short-term memory (LSTM) networks based on features extracted from the final convolutional layer, but the capturing of essential fine-grained low-level motion, pivotal in numerous scenarios, might be hindered [26]. Training also incurs significant costs, given the necessity for the network to be unrolled across multiple frames to facilitate time-based backpropagation. An enhanced methodology entails the modeling of brief temporal video snapshots, achieved by combining forecasts originating from an individual RGB frame and a compilation of 10 externally generated optical flow frames. This is subsequently followed by the traversal of two iterations of an ImageNet-pre-trained ConvNet [27]. An adapted input convolutional layer is integrated within the two-stream architecture, boasting double the number of input channels in comparison to the frames within the stream as shown in Figure 1b. During the testing phase, numerous video snapshots are sampled and subsequently aggregated to yield action predictions. Experiments validate the achievement of exceptional performance on established benchmarks, concurrently showcasing remarkable efficiency during both training and testing intervals.
Two-stream models have achieved remarkable performance in various computer vision tasks. It has been widely used in action recognition, outperforming previous methods on benchmark datasets such as UCF101 and HMDB51 [28]. Moreover, the two-stream model has also found applications in other domains such as gesture recognition, video captioning, and video segmentation, demonstrating its versatility and effectiveness. Future research directions may focus on developing more efficient architectures, exploring attention mechanisms, and using unsupervised or weakly supervised learning paradigms to further build up the performance and generalization capabilities of two-stream models.
2.3. SlowFast Networks
During the preceding years, an array of video action recognition networks has been put forth by researchers, including 2D CNN, 3D CNN, and I3D network. However, these methods have certain limitations when dealing with challenging scenarios such as long-term dependencies and fast actions. The SlowFast network as shown in Figure 1c addresses the problem of spatio-temporal scale differences in videos by introducing two branches, slow and fast [29][30]. The slow branch is used to process low-frequency information to capture long-term timing dependencies by reducing the frame rate of the input video. The fast branch is used to process high-frequency information to capture instantaneous actions by preserving the high frame rate of the input video. This design can effectively balance information on both temporal and spatial scales. It primarily comprises two main components: the slow path and the fast path [31]. The slow path is processed at a lower frame rate, typically 1/8 or 1/16 of the input video. The fast path is processed at native framerate. The two paths extract feature representations, C and C, at different scales, respectively, and integrate information through the fusion module. Finally, after global average pooling and classification layers, T and T, the network outputs the behavior category of the video. The SlowFast network achieves significant performance gains on video action recognition tasks [32]. Compared with the traditional 2D CNN network and 3D CNN network, the SlowFast network can better handle long-term dependencies and fast actions, and improve the accuracy and robustness of behavior recognition. In addition, the SlowFast network structure is simple and efficient, with low computing and storage overhead, and is suitable for training and reasoning on large-scale video data [33][34].
This entry is adapted from the peer-reviewed paper 10.3390/s23208425
References
- Jin, M.; Ning, Y.; Liu, F.; Zhao, F.; Gao, Y.; Li, D. An Evaluation Model for the Influence of KOLs in Short Video Advertising Based on Uncertainty Theory. Symmetry 2023, 15, 1594.
- Ali, A.; Senan, N. A review on violence video classification using convolutional neural networks. In Recent Advances on Soft Computing and Data Mining, Proceedings of the Second International Conference on Soft Computing and Data Mining (SCDM-2016), Bandung, Indonesia, 18–20 August 2016; Springer: Berlin/Heidelberg, Germany, 2016; pp. 130–140.
- Trzcinski, T. Multimodal social media video classification with deep neural networks. In Photonics Applications in Astronomy, Communications, Industry, and High-Energy Physics Experiments; SPIE: Washington, DC, USA, 2018; pp. 879–886.
- Ntalianis, K.; Doulamis, N. An automatic event-complementing human life summarization scheme based on a social computing method over social media content. Multimed. Tools Appl. 2016, 75, 15123–15149.
- Jain, A.; Singh, D. A Review on Histogram of Oriented Gradient. IITM J. Manag. IT 2019, 10, 34–36.
- Ragupathy, P.; Vivekanandan, P. A modified fuzzy histogram of optical flow for emotion classification. J. Ambient Intell. Hum. Comput. 2021, 12, 3601–3608.
- Fan, M.; Han, Q.; Zhang, X.; Liu, Y.; Chen, H.; Hu, Y. Human Action Recognition Based on Dense Sampling of Motion Boundary and Histogram of Motion Gradient. In Proceedings of the 2018 IEEE 7th Data Driven Control and Learning Systems Conference (DDCLS), Enshi, China, 25–27 May 2018; pp. 1033–1038.
- Wang, H.; Klaser, A.; Schmid, C.; Liu, C.-L. Action recognition by dense trajectories. In Proceedings of the CVPR 2011, Colorado Springs, CO, USA, 20–25 June 2011; pp. 3169–3176.
- Wang, H.; Schmid, C. Action recognition with improved trajectories. In Proceedings of the IEEE International Conference on Computer Vision, Sydney, Australia, 2–8 December 2013; pp. 3551–3558.
- Silva, F.B.; Werneck, R.d.O.; Goldenstein, S.; Tabbone, S.; Torres, R.d.S. Graph-based bag-of-words for classification. Pattern Recognit. 2018, 74, 266–285.
- Karim, A.A.; Sameer, R.A. Image Classification Using Bag of Visual Words (BoVW). Al-Nahrain J. Sci. 2018, 21, 76–82.
- Li, R.; Liu, Z.; Tan, J. Reassessing hierarchical representation for action recognition in still images. IEEE Access 2018, 6, 61386–61400.
- Singhal, S.; Tripathi, V. Action recognition framework based on normalized local binary pattern. Progress in Advanced Computing and Intelligent Engineering. Proc. ICACIE 2017, 1, 247–255.
- Hu, Y.; Gao, J.; Xu, C. Learning dual-pooling graph neural networks for few-shot video classification. IEEE Trans. Multimedia 2020, 23, 4285–4296.
- Wang, Y.; Liu, Y.; Zhao, J.; Zhang, Q. A Low-Complexity Fast CU Partitioning Decision Method Based on Texture Features and Decision Trees. Electronics 2023, 12, 3314.
- Liu, C.; Wang, Y.; Zhang, N.; Gang, R.; Ma, S. Learning Moiré Pattern Elimination in Both Frequency and Spatial Domains for Image Demoiréing. Sensors 2022, 22, 8322.
- Zhang, X.; Jiang, X.; Song, Q.; Zhang, P. A Visual Enhancement Network with Feature Fusion for Image Aesthetic Assessment. Electronics 2023, 12, 2526.
- Yi, Q.; Zhang, G.; Liu, J.; Zhang, S. Movie Scene Event Extraction with Graph Attention Network Based on Argument Correlation Information. Sensors 2023, 23, 2285.
- Gudaparthi, H.; Niu, N.; Yang, Y.; Van Doren, M.; Johnson, R. Deep Learning’s fitness for purpose: A transformation problem Frame’s perspective. CAAI Trans. Intell. Technol. 2023, 8, 343–354.
- Luo, X.; Wen, X.; Li, Y.; Li, Q. Pruning method for dendritic neuron model based on dendrite layer significance constraints. CAAI Trans. Intell. Technol. 2023, 8, 308–318.
- Yan, M.; Lou, X.; Chan, C.A.; Wang, Y.; Jiang, W. A semantic and emotion-based dual latent variable generation model for a dialogue system. CAAI Trans. Intell. Technol. 2023, 8, 319–330.
- Han, K.; Wang, Y.; Chen, H.; Chen, X.; Guo, J.; Liu, Z.; Tang, Y.; Xiao, A.; Xu, C.; Xu, Y.; et al. A survey on vision transformer. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 45, 87–110.
- Ji, S.; Xu, W.; Yang, M.; Yu, K. 3D convolutional neural networks for human action recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 35, 221–231.
- Wu, Q.; Zhu, A.; Cui, R.; Wang, T.; Hu, F.; Bao, Y.; Snoussi, H. Pose-Guided Inflated 3D ConvNet for action recognition in videos. Signal Process. Image Commun. 2021, 91, 116098.
- Chen, H.; Li, Y.; Fang, H.; Xin, W.; Lu, Z.; Miao, Q. Multi-Scale Attention 3D Convolutional Network for Multimodal Gesture Recognition. Sensors 2022, 22, 2405.
- Donahue, J.; Anne Hendricks, L.; Guadarrama, S.; Rohrbach, M.; Venugopalan, S.; Saenko, K.; Darrell, T. Long-term recurrent convolutional networks for visual recognition and description. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 2625–2634.
- Simonyan, K.; Zisserman, A. Two-stream convolutional networks for action recognition in videos. Adv. Neural Inf. Process. Syst. 2014, 27.
- Feichtenhofer, C.; Pinz, A.; Zisserman, A. Convolutional two-stream network fusion for video action recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 1933–1941.
- Feichtenhofer, C.; Fan, H.; Malik, J.; He, K. Slowfast networks for video recognition. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 6202–6211.
- Jin, C.; Luo, C.; Yan, M.; Zhao, G.; Zhang, G.; Zhang, S. Weakening the Dominant Role of Text: CMOSI Dataset and Multimodal Semantic Enhancement Network. IEEE Trans. Neural Netw. Learn. Syst. 2023, 1–15.
- Patrick, S.C.; Réale, D.; Potts, J.R.; Wilson, A.J.; Doutrelant, C.; Teplitsky, C.; Charmantier, A. Differences in the temporal scale of reproductive investment across the slow-fast continuum in a passerine. Ecol. Lett. 2022, 25, 1139–1151.
- Wei, D.; Tian, Y.; Wei, L.; Zhong, H.; Chen, S.; Pu, S.; Lu, H. Efficient dual attention slowfast networks for video action recognition. Comput. Vis. Image Underst. 2022, 222, 103484.
- Jiang, Y.; Cui, K.; Chen, L.; Wang, C.; Xu, C. Soccerdb: A large-scale database for comprehensive video understanding. In Proceedings of the 3rd International Workshop on Multimedia Content Analysis in Sports, Seattle, WA, USA, 16 October 2020; pp. 1–8.
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16 × 16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929.
This entry is offline, you can click here to edit this entry!