Your browser does not fully support modern features. Please upgrade for a smoother experience.
Please note this is an old version of this entry, which may differ significantly from the current revision.
Deep Reinforcement Learning (DRL) has been effectively performed in various complex environments, such as playing video games. In many game environments, DeepMind’s baseline Deep Q-Network (DQN) game agents performed at a level comparable to that of humans. However, these DRL models require many experience samples to learn and lack the adaptability to changes in the environment and handling complexity
- deep reinforcement learning
- bottom-up and top-down visual attention
- saliency map
1. Introduction
Reinforcement Learning (RL) has achieved great success in solving several tasks, such as Atari games in the arcade learning environment (ALE) [1], where the sequence of environmental observations serves as the basis for determining decisions [2]. RL algorithms process environmental data to learn a policy that chooses the best action to maximize cumulative reward [3]. During RL, the agent interacts with its environment to arrive at different states by performing actions that cause the agent to obtain positive or negative rewards.
Nevertheless, the limited adaptability of RL approaches poses challenges when dealing with complex tasks. Consequently, developing methods that enable the application of RL to complex environments is a significant research problem [3]. The goal is to enhance the capabilities of RL algorithms to effectively handle intricate tasks, allowing for more robust and efficient learning in complex scenarios.
The combination of deep neural networks (DNNs) and Q-learning [4] led to the deep Q-network (DQN) algorithm [2,5], which has been used in various works to develop models for complex tasks. These agents demonstrate remarkable success, surpassing human-level performance and outperforming baseline benchmarks [6].
However, the DQN algorithm can suffer inefficiency and inflexibility, which can limit its performance [6,7]. It is vulnerable in complex environments regarding data efficiency, as there is an infinite number of possible experiences in such environments, and there is a need to process many states, requiring high computational power [8]. The DQN algorithm has received criticism for its need for more flexibility, specifically when adapting to changes in the environment or incorporating new tasks. In such cases, the algorithm typically requires a complete restart of the learning process, which can be time-consuming and inefficient [7]. It also has certain limitations in terms of generalization compared to regular neural networks [9].
Researchers have developed a range of extensions to the original DQN algorithm to address these issues, such as double DQN [10]. Moreover, several works have proposed the use of visual attention mechanism [11,12,13,14], which allows the network to focus on specific regions of an input image rather than processing the entire image at once [11].
The attention mechanism can be implemented in various ways, such as using convolutional neural networks (CNNs) to extract image features, recurrent neural networks (RNN), and visual question answering (VQA) models that process the textual question input [15,16,17]. The VQA attention mechanism serves the purpose of selectively directing attention toward image regions that are crucial for answering a question. The attention mechanism effectively prioritizes the attended regions by assigning importance scores or weights to different image regions based on their relevance to the question. As a result, these regions are granted a higher degree of significance in the overall analysis [15,16,17,18,19,20].
2. Continually Improving the Performance of Autonomous Game Agents
Reinforcement learning algorithms, such as DQN [2], have shown great success in learning to play Atari 2600 games from raw pixel inputs. While DQN [2] can learn to play games effectively, it can suffer from instability and inefficiency in learning [6,7].
To address these shortcomings, several modifications have been proposed to the original DQN algorithm [6,8,10,21,22]. The prioritized experience replay method, proposed by Schaul et al. [21], prioritizes experience replay based on the importance of the sample, so that it replays critical transitions more frequently, and therefore learns more efficiently. A dueling neural network architecture, which is introduced by Wang et al. [10], separates the state value function and the action function, resulting in more stable learning and better performance than the state of the art on the Atari 2600 domain. Several works have presented a distributed architecture for deep reinforcement learning [8,22,23]. Such architectures distribute the learning process across multiple parallel agents, which enables more efficient exploration of the state space and faster convergence [8]. Another group of work has aimed to learn additional auxiliary functions with denser training rewards to improve the sample efficiency problem [24]. Some research has combined multiple techniques, such as prioritized experience replay, dueling networks, and distributional RL, to achieve performance enhancements over DQN [6].
A number of studies have used attentional mechanisms to improve the performance of their models [12,13,25,26,27]. Some of these use bottom-up attention, allowing the agent to selectively attend to different parts of the input, regardless of the agent’s task. Others have applied attention to DRL problems in the Atari game domain [11,12,28]. Additionally, several others have explored attention by incorporating a saliency map [29] as an extra layer [30] that modifies the weights of CNN features.
Studies that use the basic bottom-up saliency map [29] as an attention mechanism in RL have used many hand-crafted features as inputs [31]. Yet, these models show an inability to attend to multiple input information with sufficient importance simultaneously. Top-down attention mechanisms can also be used to improve the performance of DQNs by allowing the agent to selectively attend to relevant parts of the input based on its current tasks [32].
Most of the previous DRL studies that use attention mechanisms are generally based on back-propagation learning [13,27], which is actually not ideal to be used by DRL [25,30] as it can lead to inflexibility [33]. Few other works have proposed to learn attention without back-propagation [25,30]. Yuezhang et al. infer that attention from optical flow only applies to issues involving visual movement [30]. The Mousavi attention mechanism uses a bottom-up approach, which is directed by the inherent characteristics of the input information regardless of the reward [25].
3. Background on Q-Learning and DQN
Basic Q-learning learns a function that updates an action-value (Q) table for different states and actions, enabling an agent to learn the optimal policy for taking actions in an environment by maximizing expected cumulative rewards based on the current, as represented by the variable s in (Equation (1)) [34]:
In the above; the Q-value for a state s when taking action a is calculated as the sum of the immediate reward 𝑅(𝑠,𝑎) and the highest Q-value achievable from the subsequent state 𝑠′. The variable 𝛾, referred to as the discount factor, governs the extent to which future rewards contribute to this calculation.
The agent performs the sequences of actions to maximize the total expected reward. The Q-value is formalized as follows [34]:
where 𝛼 is the learning rate, and [𝑅(𝑠,𝑎)+𝛾𝑚𝑎𝑥𝑄(𝑠′,𝑎′)−𝑄(𝑠,𝑎)] is called the temporal difference error.
To address the limitations of basic Q-learning, such as slow convergence and the need for manual feature engineering, Mnih et al. proposed a deep Q-network (DQN) [2] to utilize deep neural networks to approximate the learning function, allowing for more complex and efficient learning directly from raw sensory inputs. The DQN architecture (Figure 2) uses a CNN to process the input image representing the game state and produces Q-values for all available actions. The CNN’s convolutional layers extract important features, generating a feature map. This feature map is then flattened and fed into a fully connected (FC) network, which computes the Q-values for the actions in the current state.
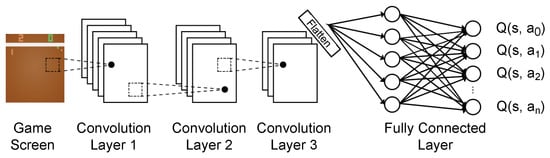
Figure 2. DQN architecture.
In traditional supervised neural networks, learning the target is always fixed at each step, and only estimates are updated. In contrast, there is no specific target in reinforcement learning: the target itself is estimated, and therefore, it changes during learning. However, changing the target during the training process leads to unstable learning. To resolve this issue, DQN uses a dual neural network architecture, referred to as the prediction and target network, in which there are two Q-networks with identical structures but different parameters. Learning is primarily accomplished through the update of the prediction network at each step to minimize the loss between its present Q-values and the target Q-values. The target network is a copy of the prediction network that is updated less frequently, usually by copying the weights of the prediction network every n step. This way, the target network serves to maintain stability and to prevent the prediction network from overfitting to the current data by keeping the target values fixed for a window of n time steps.
This entry is adapted from the peer-reviewed paper 10.3390/electronics12214405
This entry is offline, you can click here to edit this entry!