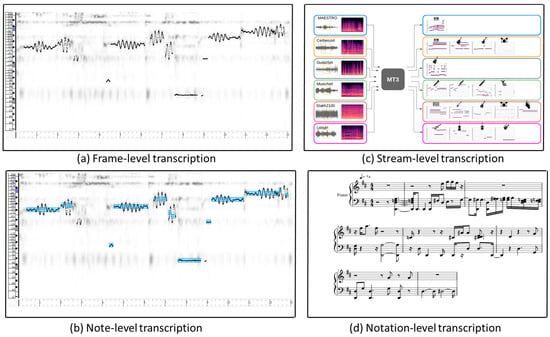
Music transcription is the process of transforming recorded sound of musical performances into symbolic representations such as sheet music or MIDI files. At the most fundamental level, frame-level transcription involves analyzing very short frames of audio and identifying basic sound characteristics of music such as pitch and timbre. In the next step, note-level transcription takes the information gathered from frame-level analysis and assembles it into individual musical notes. This level of transcription can identify the pitch, duration, and timing of each note in the piece of audio. The stream-level transcription looks beyond individual notes to capture the larger musical phrases. This involves recognizing patterns in the sequence of notes, identifying chord progressions, and determining the overall structure of the music like verses and choruses in a song. The highest level of transcription involves creating a formal written representation of the music notation. This includes not only the individual notes and their timing but also various musical symbols such as dynamics, articulations, time signatures, key signatures, and more.
1. Frame-Level Transcription
Frame-level transcription or multi-pitch estimation (MPE) is the estimation of the pitch of notes that are simultaneously present in each time frame of the audio signal. This transcription task has been performed in each time frame independently.
Figure 1a shows an example of frame-level transcription, where every dot in the
x-axis represents the discrete time and the
y-axis dots represent its corresponding pitch. The visualization for this transcription has been carried out using Tony [
18] from the wave file (opera_male5.wav) of the ADC2004 (
http://labrosa.ee.columbia.edu/projects/melody/, accessed on 5 October 2023) vocal melody dataset. Various research studies have been developed using frame-level transcription. The work in [
23] introduced a method for estimating multiple concurrent piano notes, dealing with overlapping overtones by using smooth autoregressive models. It handles background noise to reduce pitch estimation errors, creating a comprehensive model for piano notes. The effectiveness of this model has been validated with real piano recordings of the MAPS [
23] dataset. Similarly, the work in [
24] discusses the challenge of training data for estimating multiple pitches in music. It introduces a new approach called combined frequency and periodicity (CFP), which combines two different types of features to improve the accuracy in simultaneous pitches. The result shows that CFP works well for western polyphonic music and remains effective even when dealing with audio distortions like filtering and compression. The two works described above are conventional approaches for frame-level transcription. However, recently, the neural network-based methods [
12,
25] have garnered increased attention from researchers. The work in [
12] introduced a supervised neural network model for a polyphonic transcription task on the MAPS dataset. It consists of an acoustic model and a music language model. The acoustic model, based on neural networks, estimates pitch probabilities in audio frames, while the recurrent neural network-based language model captures pitch correlations over time. The acoustic and music language model predictions are combined using a probabilistic graphical model, with inference performed using the beam search algorithm. The experimental results demonstrate that convolutional neural network-based acoustic models outperform popular unsupervised models. Similarly, the work in [
25] analyzed neural network based frame-level piano transcription by comparing four different input representations: spectrograms with linearly spaced bins, spectrograms with logarithmically spaced bins, spectrograms with logarithmically spaced bins and a logarithmically scaled magnitude, as well as the constant-Q transform. This study highlights the significance of choosing the right input representation and fine-tuning the hyper-parameters, especially the learning rate and its schedule, which can improve the accuracy of frame-level transcription. Frame-level transcription has several advantages as well as disadvantages. First, it provides a high temporal resolution which can enable the detailed representations of music at a fine time scale. Second, it is useful for in-depth music analysis where precise timing information is required. However, there are some notable disadvantages in frame-level transcription. First, it requires high computational resources due to the need to analyze audio at a very fine level, which can make it less efficient for real-time applications. Second, the fine-scale high temporal resolution generates a large volume of data, which makes it challenging to manage, store, and process efficiently due to its size and complexity. Lastly, it focuses deeply on the technical details but fails to capture the broader musical context.
Figure 1. An example for the illustration of four different levels of music transcription.
2. Note-Level Transcription
The note-based transcription approaches directly estimates notes, including pitches and onsets. This note-based transcription is one level higher than frame-level transcription because the objective of frame-level transcription is to estimate only pitch in a particular time period. But note-level transcription needs to estimate the pitch, onset time, and offset time of a specific note in a particular time period.
Figure 1b shows an example of note-level transcription. The blue rectangle shows the note events after the post-processing of frame-level transcription on a continuous pitch based on a hidden Markov model. The visualization for this transcription has also been carried out using Tony [
18] from the wave file (opera_male5.wav) of the ADC2004 vocal melody dataset. The note offset in this level of transcription is ambiguous, so they are sometimes neglected during the inference time and only evaluate the pitch and onset time of a note. The work in [
26,
27] estimates the pitches and onsets in a single architecture. One example for this is [
28], which jointly estimates the different attributes of notes like the pitch, intensity, onset, and duration. It estimates the properties of notes concurrently using harmonic temporal structured clustering. The note-level transcription can also be achieved after the post-processing in frame-level transcription. First, the fundamental frequency is estimated concurrently, and post-processing is applied to estimate the musical notes in the second step. The methods used during the post-processing steps are median filtering, hidden Markov Models, and Neural networks [
24,
29,
30]. The work in [
24] uses a median filter by comparing the estimated pitch in nearby frames for temporal smoothing. The moving median filter is used with 0.25 s, with a hop size of 0.01 s. This post-processing method is reliable for connecting non-continuous pitch and can effectively delete the isolated one. Similarly, the work in [
29] converted the output of the support vector machine to a posterior probability. The steps for pitch smoothing were performed for each note class by using the Viterbi search method on the transition matrix of 2 × 2. The note onset and offset were finally gathered from both the posterior probability of the support vector machine and the training data. Note-level transcription can provide the highest level of detail, capturing individual notes’ onset and offset along with pitch. It allows for an in-depth analysis of musical elements like melody, harmony, and rhythm. However, there are some disadvantages of note-level transcription. First, transcribing note by note can be time-consuming, which is not practical for longer pieces of music. Second, to make an accurate transcription, expert musicians are required for the annotation of onset, offset, and pitch. Third, it is challenging and difficult to capture the musical nuances like vibrato and articulation in note level-transcription because it is highly subjective and depends on the interpretation and style of the performer.
3. Stream-Level Transcription
Stream-level transcription is also called multi-pitch streaming (MPS), which can group estimated pitches or notes into separate streams. The grouped or separated stream typically corresponds to an individual instrument.
Figure 1c shows an example of stream-level transcription which was obtained from a multi-task multitrack music transcription (MT3) model [
31]. The estimated pitches and notes for each instrument in this model have been grouped into separate streams using various music transcription datasets. The pitch streams of different instruments in this transcription can be visually distinguished using varying colors. This level of transcription offers a broader perspective, involving the transcription of musical events or attributes across entire segments or streams of music. These segments may span longer durations and encompass multiple notes or musical phrases. Stream-level transcription has the capacity to capture higher-level musical structures, such as chords, sections, or phrases, thereby aiming to provide a comprehensive and holistic representation of the analyzed music. This level of transcription is useful when the goal is the simplified arrangement of a musical piece. It works well for music with a smaller number of notes. However, it reduced some level of detail compared to note-level transcription, which may limit the accuracy of the transcription. Stream-level transcription is less suitable for complex music because it captures larger musical sections, which means it provides a more generalized overview of the music but does not capture the complex compositions such as rapid note sequences or variations in dynamics. In stream-level transcription, recent research efforts [
32] have addressed the challenge by considering three key inputs: the original audio mixture, an existing multi-pitch estimation system, and the number of sources within the audio mixture. The approach undertaken in this work formulates the transcription problem as a clustering task, with a focus on maintaining timbral consistency. This is achieved by assuming that sound objects originating from the same source exhibit similar timbral characteristics. Similarly, other studies [
33,
34] serve as additional examples of stream-level transcription. Both of these works also operate under the assumption that notes belonging to the same source stream demonstrate comparable timbral traits in contrast to notes from different source streams.
4. Notation-Level Transcription
Notation-level transcription is the higher level of transcription which is the process of converting audio recordings into a traditional musical notation format such as sheet music or a musical score.
Figure 1 illustrates an example of notation-level transcription. The visualization for this transcription has been carried out using AnthemScore [
35] from a wave file (opera_male5.wav) of the ADC2004 vocal melody dataset. This transcription maps the audio signals to specific symbols, notes, rhythms, and other notation elements that can be read and performed by musicians. It focuses on capturing the basic structure, melody, and harmony, making it suitable for less complex music. It provides a quick overview of the musical content which can be easily understood by individuals with limited musical training. However, it is not suitable for in-depth musical analysis or the complex composition of the music. Notation-level transcription is often used to preserve and communicate musical compositions and performances in a standardized form. The transcription in this level requires a deeper understanding of musical structures, including harmonic, rhythmic, and stream structures. Transcribers use specialized music notation software to create the symbolic representation of the music. The popular software for notation-level transcription include Finale V27 (
https://www.finalemusic.com/, accessed on 5 October 2023), Sibelius for desktop and mobile version 2023.8 (
https://www.avid.com/sibelius, accessed on 5 October 2023), MuseScore 4.x (
https://musescore.org/, accessed on 5 October 2023), LilyPond 2.24.2 (
http://lilypond.org/, accessed on 5 October 2023), AnthemScore version 4 [
35], and more. These tools provide a user-friendly interface for inputting and editing musical elements.
This entry is adapted from the peer-reviewed paper 10.3390/app132111882