Your browser does not fully support modern features. Please upgrade for a smoother experience.
Please note this is an old version of this entry, which may differ significantly from the current revision.
Machine learning approaches, in particular graph learning methods, have achieved great results in the field of natural language processing, in particular text classification tasks. However, many of such models have shown limited generalization on datasets in different languages.
- non-English text classification
- graph machine learning
- ensemble learning method
1. Introduction
In the last decade, there has been a tremendous growth in the number of digital documents and complex textual data. Text classification is a classically important task in many natural language processing (NLP) applications, such as sentiment analysis, topic labeling, and question answering. Sentiment analysis is particularly and significantly important in the realms of business and sales, as it enables organizations to gain valuable insights and make informed decisions. In the age of information explosion, processing and classifying large volumes of textual data manually is time-consuming and challenging. Moreover, the accuracy of manual text classification can be easily influenced by human factors such as fatigue and insufficient domain knowledge. It is desirable to automate classification methods using machine learning techniques, which are more reliable. Additionally, this can contribute to increase the efficiency of information retrieval and reduce the burden of information overload by effectively locating the required information [1]. See some of the works on text classification as well as some of its numerous real-world applications in [2][3][4][5].
On the other hand, graphs provide an important data representation that is used in a wide range of real-world problems. Effective graph analysis enables users to gain a deeper understanding of the underlying information in the data and can be applied in various useful applications such as node classification, community detection, link prediction, and more. Graph representation is an efficient and effective method for addressing graph analysis tasks. It compresses graph data into a lower-dimensional space while attempting to preserve the structural information and characteristics of the graph to the maximum extent.
Graph neural networks (GNNs) represent today central notions and tools in a wide range of machine learning areas since they are able to employ the power of both graphs and neural networks in order to operate on data and perform machine learning tasks such as text classification.
2. Preprocessing
The preprocessing stage for the textual dataset before graph construction involves several steps. It is also worth mentioning that, for non-English datasets, the pre-processing stage may be different from some technical aspects relevant to that particular language. Researchers explain the approach here, although similar processes have been followed in earlier works such as in [6]. First, stop words are removed. These are common words that carry little to no semantic importance and their removal can enhance the performance and efficiency of natural language processing (NLP) models. Next, punctuation marks such as colons, semicolons, quotation marks, parentheses, and others are eliminated. This simplifies the text and facilitates processing by NLP models. Stemming is applied to transform words into their base or root form, ensuring standardization of the textual data. Finally, tokenization is performed, which involves dividing the text into smaller units known as tokens, which is usually achieved by splitting it into words. These pre-processing steps prepare the text for subsequent graph construction tasks.
3. Graph Construction
There exist different methods for graph construction in the context of text classification. An important, known method is to construct a graph for a corpus based on word co-occurrence and document–word relations. This graph is a heterogeneous graph that includes word nodes and document nodes, allowing the modeling of global word co-occurrence and the adaptation of graph convolution techniques [7]. After constructing the graph, the next step is to create initial feature vectors for each node in the graph based upon pre-trained models, namely BERT and ParsBERT.
It is worth noting that all the unique words obtained from the pre-processing stage, along with all the documents, altogether form the set of nodes of the graph. Edges are weighted and defined to belong to one of three groups. One group consists of those edges between document–word pairs based upon word occurrence in documents. The second group consists of those edges between word–word pairs based upon word co-occurrence in the entire corpus. The third group consists of those edges between document–document pairs based upon word co-occurrence in the two documents. As shown in Equation (1), the weight 𝐴𝑖,𝑗
of the edges (𝑖,𝑗) is defined using the term frequency-inverse document frequency (TF-IDF) [8] measure (for document–word edges) and the point-wise mutual information (PMI) measure (for word–word edges). The PMI measure captures the semantic correlation between words in the corpus. Moreover, Jaccard similarity is used to define the edge weight by calculating the similarity between two documents [6].Each document is fed to the pre-trained model multi-lingual BERT or the ParsBERT model, resulting in a numerical vector representation. For each word, a min pooling operation is applied over the BERT or ParsBERT representations of the documents containing the word. More precisely, in the same manner as that of reference [6], given a word, the min pooling over the BERT representations of all documents containing that word gives rise to the representation of that word. Now, the feature vector associated to every node is defined.
Researchers now talk address the pre-trained models BERT and ParsBERT. These models have gained widespread popularity in text processing and natural language processing (NLP). They provide high-quality embeddings that serve as features for downstream tasks. They eliminate the need for manual feature engineering. The BERT vector, also known as BERT embedding, is in fact a high-dimensional vector that represents a text. This embedding is created by encoding words in a sentence using a pre-trained BERT model trained on a large dataset of textual data. The encoding process generates a fixed-length vector for each word in the sentence, which can then serve as input for other natural language processing models. The ParsBERT model, similarly, was pre-trained from diverse sources of Persian textual data.
It is worth noting that, beside the BERT frameworks, there have been many other popular frameworks for finding representations of texts such as “word mover’s embedding”, “Word2vec”, etc. BERT is a language model widely used for a variety of natural language processing tasks, in particular tasks that require an understanding of the context, while some other frameworks, such as the mentioned word mover’s embedding, focuses on word alignment and is useful for tasks involving semantic similarity or semantic distance.
Once the text graph is constructed, it is fed to a two-layer GCN. Each GCN layer performs message passing among the nodes based upon their neighborhood relationships; this allows for the integration of information from larger neighborhoods. Researchers review the message passing step more in detail. As previously mentioned, the initial representation vectors made by BERT and ParsBERT are given as the initial features of the nodes to the input of the graph convolutional neural network (GCN). The information of these nodes is conveyed by the process of messages passing through graph neural networks in such a way that each node in the graph computes a message for each of its neighbors. Messages are in fact a function of nodes, neighbors, and the edges between them. Messages are sent and each node aggregates the messages it receives using a function such as sum or average. After receiving messages, each node updates its attributes as a function of its current attributes and the aggregated messages. The basic GNN message passing formula is defined as follows:
is also the bias term. The final feature vectors obtained for each text data node are considered as the output of the GCN, which are passed through a SoftMax classifier for final prediction. By jointly training the BERT and GCN modules, researchers leverage the advantages of both pre-trained models and graph models.
4. Graph Partitioning
Researchers now address another ingredient of the combination of techniques, which posses both conceptual as well as technical significance in the results. A fundamental challenge in graph neural networks is the need for a large space to store the graph and the representation vectors created for each node. To address this issue, one of the contributions is to apply Cluster-GCN algorithm [9], which partitions the graph into smaller clusters, as will be explained below. The Cluster-GCN algorithm utilizes a graph-clustering structure to address the challenge posed by large-scale graph neural networks. In order to overcome the need for extensive memory and storage for the graph and its node representation vectors, the algorithm divides the graph into smaller subsets by using graph-clustering algorithms like METIS [10]. METIS aims to partition the graph into subgraphs of approximately equal size while minimizing the edge connections between them. The process involves graph coarsening, wherein vertices in the original graph are merged to create a smaller yet representative graph for efficient partitioning. After generating the initial subgraphs using the graph partitioning algorithm, the algorithm refines the partitioning in a recursive manner by the application of an uncoarsening algorithm. This recursive process propagates partitioning information from smaller to larger levels while maintaining the balance and size of the subgraphs. By dividing the graph into smaller clusters, the model’s performance improves in terms of computational space and time. The decision to employ graph-clustering methods is driven by the aim to create partitions wherein connections within each group are strong, capturing the clustering and community structure of the graph effectively. This approach is particularly beneficial in node embeddings, as nodes and their neighbors usually belong to the same cluster; it enables efficient batch processing.
5. Ensemble Learning
One of the other ingredients of the combination of techniques is using ideas from the theory of ensemble learning. Bagging and stacking are important techniques in neural networks.
After the preprocessing stage in the dataset, researchers construct the graph in the way that was described above. Then, using the Cluster-GCN algorithm, researchers divide the input graph into four disjoint-induced subgraphs. Each of these subgraphs is then fed to a separate graph neural network. According to the experiences, graph convolutional networks (GCNs) have shown better performance in text classification processing in many of the attempts. Therefore, researchers highlight the use of GCNs in the combination. In addition to GCNs, researchers also utilize a graph isomorphism networks (GINs) framework as well as graph attention networks (GATs) as two other parts of the ensemble learning in the combination. It is worth noting that the GIN part in the combination here intends to capture the global structure of the graph. An overview of the algorithm used is shown in Figure 1. Once training was conducted over separated individual models, after which researchers obtained four different trained GNN models. In the test stage, test samples pass through all these models and each one creates its own classification output vector. Then, the results of all of these models are combined by taking the average of those output vectors. Via this process, the ensemble method can help to enhance the prediction accuracy by amalgamating the strengths of multiple models.
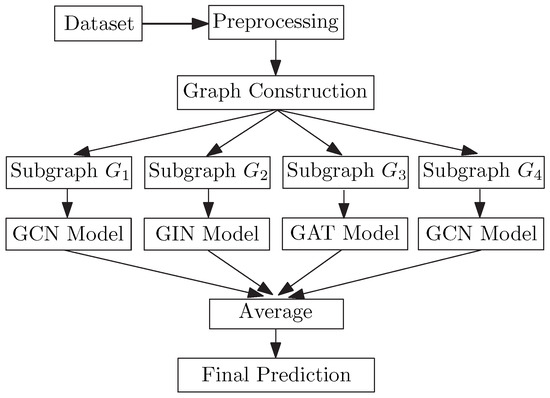
Figure 1. Using group algorithms in graph neural networks.
As another part of the combination, researchers employ frameworks of ParsBERT (instead of BERT) when addressing Persian or Arabic datasets in the method to obtain the initial representations of the words and documents as nodes of the graph, as mentioned earlier. BERT is a known language model which associates a vector to a text. ParsBERT is a specified version of BERT which is fine-tuned for text classification in the Persian language. Both BERT and ParsBERT create the initial feature vector of the nodes in the learning tasks. researchers employed both in the different experiments but with an emphasis on ParsBERT, and later researchers will provide a report of the results as well as an explanation of the idea behind emphasizing the use of ParsBERT. After obtaining an initial representation from ParsBERT, the different mentioned GNN methods started to operate on them and, eventually, an averaging of the results produced the final classification results.
Through this classification process, researchers made several observations. First, researchers observed how applying GNN models achieves better scores on the task of text classification by better capturing the topological information between users and their opinions. Second, researchers observed that the performance of ParsBERT had been better than that of BERT in both balanced and imbalanced data scenarios. This can be attributed to the nature of the data being in the Persian language (or even similar non-English languages such as Arabic). Since ParsBERT was trained on a large collection of Persian texts, it allows ParsBERT to learn better textual representation vectors for Persian text compared to the original BERT. This results in significantly higher encoding power in the beginning of the process of generating representations, which eventually leads to better ultimate representation after passing through the several layers and steps of operations of the GNN. Eventually, this results in a better final performance. This observation suggests and emphasizes using the language-specific pre-trained language model (like ParsBERT, instead of BERT) for obtaining better initial and final representations in the context of non-English language classification problems.
This entry is adapted from the peer-reviewed paper 10.3390/a16100470
References
- Li, Q.; Peng, H.; Li, J.; Xia, C.; Yang, R.; Sun, L.; Yu, P.S.; He, L. A Survey on Text Classification: From Traditional to Deep Learning. ACM Trans. Intell. Syst. Technol. 2022, 13, 1–41.
- Zhang, L.; Wang, S.; Liu, B. Deep learning for sentiment analysis: A survey. Wiley Interdiscip. Rev. Data Min. Knowl. Dis. 2018, 8, e1253.
- Aggarwal, C.C.; Zhai, C.; Aggarwal, C.C.; Zhai, C. A survey of text classification algorithms. In Mining Text Data; Springer: Berlin/Heidelberg, Germany, 2012; pp. 163–222.
- Zeng, Z.; Deng, Y.; Li, X.; Naumann, T.; Luo, Y. Natural language processing for ehr-based computational phenotyping. IEEE/ACM Trans. Comput. Biol. Bioinform. 2018, 16, 139–153.
- Dai, Y.; Liu, J.; Ren, X.; Xu, Z. Adversarial training based multi-source unsupervised domain adaptation for sentiment analysis. In Proceedings of the AAAI Conference on Artificial Intelligence 2020, New York, NY, USA, 7–12 February 2020; pp. 7618–7625.
- Han, S.C.; Yuan, Z.; Wang, K.; Long, S.; Poon, J. Understanding Graph Convolutional Networks for Text Classification. arXiv 2022, arXiv:2203.16060.
- Yao, L.; Mao, C.; Luo, Y. Graph convolutional networks for text classification. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27–28 January 2019; Volume 33, pp. 7370–7377.
- Salton, G.; Buckley, C. Term-weighting approaches in automatic text retrieval. Inf. Process. Manag. 1988, 24, 513–523.
- Chiang, W.-L.; Liu, X.; Si, S.; Li, Y.; Bengio, S.; Hsieh, C. Cluster-GCN: An efficient algorithm for training deep and large graph convolutional networks. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Anchorage, AK, USA, 4–8 August 2019; pp. 257–266.
- Karypis, G.; Kumar, V. A fast and high quality multilevel scheme for partitioning irregular graphs. SIAM J. Sci. Comput. 1998, 20, 359–392.
This entry is offline, you can click here to edit this entry!