1. Graphics Processing Units
Many advances covered in this paper, along with classical ML and scalable general-purpose graphics processing unit (GPU) computing, have become critical components of AI [
1,
10], enabling the processing of massive amounts of data generated each day and lowering the barrier to adoption [
1]. In particular, the usage of GPUs revolutionized the landscape of classical ML and DL models. From the 1990s to the late 2000s, ML research was predominantly focused on SVM, which was considered state-of-the-art [
1]. In the following decade, starting in 2010, GPUs brought new life into the field of DL, jumpstarting a high amount of research and development [
1]. State-of-the-art DL algorithms tend to have higher computational complexity, requiring several iterations to make the parameters converge to an optimal value [
12,
13]. However, the relevance of DL has only become greater over the years, as this technology has gradually become one of the main focuses of ML research [
14].
While research into the use of ML on GPUs predates the recent resurgence of DL, the usage of general-purpose GPUs for computing (GPGPU) became widespread when CUDA was released in 2007 [
1]. Shortly after, CNN started to be implemented on top of GPUs, demonstrating dramatic end-to-end speedup, even over highly optimized CPU implementations. CNNs are a subset of methods that can be used, for example, for image restoration, which has demonstrated outstanding performance [
1]. Some studies have shown that, when compared with traditional neural networks and SVM, the accuracy of recognition using CNNs is notably higher [
12].
Some of these performance gains were accomplished even before the existence of dedicated GPU-accelerated BLAS libraries. The release of the first CUDA Toolkit brought new life to general-purpose parallel computing with GPUs, with one of the main benefits of this approach being the ability of GPUs to enable a multithreaded single-instruction (SIMT) programming paradigm, higher throughput, and more parallel models when compared to SIMD. This process makes several blocks of multiprocessors available, each with many parallel cores (threads), allowing access to high-speed memory [
1].
2. Image Processing
For humans, an image is a visual and meaningful arrangement of regions and objects [
11]. Recent advances in image processing methods find application in different contexts of our daily lives, both as citizens and in the professional field, such as compression, enhancement, and noise removal from images [
10,
15]. In classification tasks, an image can be transformed into millions of pixels, which makes data processing very difficult [
2]. As a complex and difficult image-processing task, segmentation has high importance and application in several areas, namely in automatic visual systems, where precision affects not only the segmentation results but also the results of the following tasks, which, directly or indirectly, depend on it [
11]. In segmentation, the goal is to divide an image into its constituent parts (or objects)—sometimes referred to as regions of interest (ROI)—without overlapping [
16,
17], which can be achieved through different feature descriptors, such as the texture, color, and edges, as well as a histogram of oriented gradients (HOG) and a global image descriptor (GIST) [
11,
17]. While the human vision system segments images on a natural basis, without special effort, automatic segmentation is one of the most complex tasks in image processing and computer vision [
16].
Given its high applicability and importance, object detection has been a subject of high interest in the scientific community. Depending on the objective, it may be necessary to detect objects with a significant size compared to the image where they are located or to detect several objects of different sizes. The results of object detection in images vary depending on their dimensions and are generally better for large objects [
18]. Image processing techniques and algorithms find application in the most diverse areas. In the medical field, image processing has grown in many directions, including computer vision, pattern recognition, image mining, and ML [
19].
In order to use some ML models when problems in image processing occur, it is often necessary to reduce the number of data entries to quickly extract valuable information from the data [
10]. In order to facilitate this process, the image can be transformed into a reduced set of features in an operation that selects and measures the representative data properties in a reduced form, representing the original data up to a certain degree of precision, and mimicking the high-level features of the source [
2]. While deep neural networks (DNNs) are often used for processing images, some traditional ML techniques can be applied to improve the data obtained. For example, in Zeng et al. [
20], a deep convolutional neural network (CNN) was used to extract image features, and principal component analysis (PCA) was applied to reduce the dimensionality of the data.
3. Machine Learning Overview
ML draws inspiration from a conceptual understanding of how the human brain works, focusing on performing specific tasks that often involve pattern recognition, including image processing [
1], targeted marketing, guiding business decisions, or finding anomalies in business processes [
4]. Its flexibility has allowed it to be used in many fields owing to its high precision, flexible customization, and excellent adaptability, being increasingly more common in the fields of environmental science and engineering, especially in recent years [
3]. When learning from data, deep learning systems acquire the ability to identify and classify patterns, making decisions with minimal human intervention [
2]. Classical techniques are still fairly widespread across different research fields and industries, particularly when working with datasets not appropriate for modern deep learning (DL) methods and architectures [
1]. In fact, some data scientists like to reinforce that no single ML algorithm fits all data, with proper model selection being dependent on the problem being solved [
21,
22]. In diagnosis modeling that uses the classification paradigm, the learning process is based on observing data as examples. In these situations, the model is constructed by learning from data along with its annotated labels [
2].
While ML models are an important part of data handling, other steps need to be taken in preparation, like data acquisition, the selection of the appropriate algorithm, model training, and model validation [
3]. The selection of relevant features is one of the key prerequisites to designing an efficient classifier, which allows for robust and focused learning models [
23].
There are two main classes of methods in ML: supervised and unsupervised learning, with the primary difference being the presence of labels in the datasets.
-
In supervised learning, we can determine predictive functions using labeled training datasets, meaning each data object instance must include an input for both the values and the expected labels or output values [
21]. This class of algorithms tries to identify the relationships between input and output values and generate a predictive model able to determine the result based only on the corresponding input data [
3,
21]. Supervised learning methods are suitable for regression and data classification, being primarily used for a variety of algorithms like linear regression, artificial neural networks (ANNs), decision trees (DTs), support vector machines (SVMs), k-nearest neighbors (KNNs), random forest (RF), and others [
3]. As an example, systems using RF and DT algorithms have developed a huge impact on areas such as computational biology and disease prediction, while SVM has also been used to study drug–target interactions and to predict several life-threatening diseases, such as cancer or diabetes [
23].
-
Unsupervised learning is typically used to solve several problems in pattern recognition based on unlabeled training datasets. Unsupervised learning algorithms are able to classify the training data into different categories according to their different characteristics [
21,
24], mainly based on clustering algorithms [
24]. The number of categories is unknown, and the meaning of each category is unclear; therefore, unsupervised learning is usually used for classification problems and for association mining. Some commonly employed algorithms include K-means [
3], SVM, or DT classifiers. Data processing tools like PCA, which is used for dimensionality reduction, are often necessary prerequisites before attempting to cluster a set of data.
Some studies make reference to semi-supervised learning, in which a combination of unsupervised and supervised learning methods are used. In theory, a mixture of labeled and unlabeled data is used to help reduce the costs of labeling a large amount of data. The advantage is that the existence of some labeled data should make these models perform better than strictly unsupervised learning [
21].
In addition to the previously mentioned classes of methods, reinforcement learning (RL) can also be regarded as another class of machine learning (ML) algorithms. This class refers to the generalization ability of a machine to correctly answer unlearned problems [
3].
The current availability of large amounts of data has revolutionized data processing and statistical modeling techniques but, in turn, has brought new theoretical and computational challenges. Some problems have complex solutions due to scale, high dimensions, or other factors, which might require the application of multiple ML models [
4] and large datasets [
25]. ML has also drawn attention as a tool in resource management to dynamically manage resource scaling. It can provide data-driven methods for future insights and has been regarded as a promising approach for predicting workload quickly and accurately [
26]. As an example, ML applications in biological fields are growing rapidly in several areas, such as genome annotation, protein binding, and recognizing the key factors of cancer disease prediction [
23]. The deployment of ML algorithms on cloud servers has also offered opportunities for more efficient resource management [
26].
Most classical ML techniques were developed to target structured data, meaning data in a tabular form with data objects stored as rows and the features stored as columns. In contrast, DL is specifically useful when working with larger, unstructured datasets, such as text and images [
1]. Additional hindrances may apply in certain situations, as, for example, in some engineering design applications, heterogeneous data sources can lead to sparsity in the training data [
25]. Since modern problems often require libraries that can scale for larger data sizes, a handful of ML algorithms can be parallelized through multiprocessing. Nevertheless, the final scale of these algorithms is still limited by the amount of memory and number of processing cores available on a single machine [
1].
Some of the limitations in using ML algorithms come from the size and quality of the data. Real datasets are a challenge for ML algorithms since the user may face skewed label distributions [
1]. Such class imbalances can lead to strong predictive biases, as models can optimize the training objective by learning to predict the majority label most of the time. The term “ensemble techniques” in ML is used for combinations of multiple ML algorithms or models. These are known and widely used for providing stability, increasing model performance, and controlling the bias-variance trade-off [
1]. Hyperparameter tuning is also a fundamental use case in ML, which requires the training and testing of a model over many different configurations to be able to find the model with the best predictive performance. The ability to train multiple smaller models in parallel, especially in a distributed environment, becomes important when multiple models are being combined [
1].
Over the past few years, frequent advances have occurred in AI research caused by a resurgence in neural network methods that have fueled breakthroughs in areas like image understanding, natural language processing, and others [
27]. One area of AI research that appears particularly inviting from this perspective is deep reinforcement learning (DRL), which marries neural network modeling with RL techniques. This technique has exploded within the last 5 years into one of the most intense areas of AI research, generating very promising results to mimic human-level performance in tasks varying from playing poker [
28], video games [
29], multiplayer contests, and complex board games, including Go and Chess [
27]. Beyond its inherent interest as an AI topic, DRL might hold special interest for research in psychology and neuroscience since the mechanisms that drive learning in DRL were partly inspired by animal conditioning research and are believed to relate closely to neural mechanisms for reward-based learning centering on dopamine [
27].
3.1. Deep Learning Concepts
DL is a heuristic learning framework and a sub-area of ML that involves learning patterns in data structures using neural networks with many nodes of artificial neurons called perceptrons [
10,
19,
30] (see
Figure 2). Artificial neurons can take several inputs and work according to a mathematical calculation, returning a result in a process similar to a biological neuron [
19]. The simplest neural network, known as a single-layer perceptron [
30], is composed of at least one input, one output, and a processor [
31]. Three different types of DL algorithms can be differentiated: multilayered perceptron (MLP) with more than one hidden layer, CNN, and recurrent neural networks (RNNs) [
32].
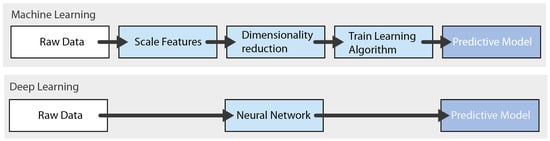
Figure 2. Differences in the progress stages between traditional ML methods and DL methods.
One important consideration towards generic neural networks is they are extremely low-bias learning systems. As dictated by the bias–variance trade-off, this means that neural networks, in the most generic form employed in the first DRL models, tend to be sample-inefficient and require large amounts of data to learn. A narrow hypothesis set can speed the learning process if it contains the correct hypothesis or if the specific biases the learner adopts happen to fit with the material to be learned [
27]. Several proposals for algorithms and models have emerged, some of which have been extensively used in different contexts, such as CNNs, autoencoders, and multilayer feedback RNN [
10]. For datasets of images, speech, and text, among others, it is necessary to use different network models in order to maximize system performance [
33]. DL models are often used for image feature extraction and recognition, given their higher performance when dealing with some of the traditional ML problems [
10].
DL techniques differ from traditional ML in some notable ways (see also Figure 2):
-
Training a DNN implies the definition of a loss function, which is responsible for calculating the error made in the process given by the difference between the expected output value and that produced by the network. One of the most used loss functions in regression problems is the mean squared error (MSE) [
30]. In the training phase, the weight vector that minimizes the loss function is adjusted, meaning it is not possible to obtain analytical solutions effectively. The loss function minimization method usually used is gradient descent [
30].
-
Activation functions are fundamental in the process of learning neural network models, as well as in the interpretation of complex nonlinear functions. The activation function adds nonlinear features to the model, allowing it to represent more than one linear function, which would not happen otherwise, no matter how many layers it had. The Sigmoid function is the most commonly used activation function in the early stages of studying neural networks [
30].
-
As their capacity to learn and adjust to data is greater than that of traditional ML models, it is more likely that overfitting situations will occur in DL models. For this reason, regularization represents a crucial and highly effective set of techniques used to reduce the generalization errors in ML. Some other techniques that can contribute to achieving this goal are increasing the size of the training dataset, stopping at an early point in the training phase, or randomly discarding a portion of the output of neurons during the training phase [
30].
-
In order to increase stability and reduce convergence times in DL algorithms, optimizers are used, with which greater efficiency in the hyperparameter adjustment process is also possible [
30].
In the last decades, three main mathematical tools have been studied for image modeling and representation, mainly because of their proven modeling flexibility and adaptability. These methods are the ones based on probability statistics, wavelet analysis, and partial differential equations [
34,
35]. In image processing procedures, it is sometimes necessary to reduce the number of input data. An image can be translated into millions of pixels for tasks, such as classifications, meaning that data entry would make the processing very difficult. In order to overcome some difficulties, the image can be transformed into a reduced set of features, selecting and measuring some representative properties of raw input data in a more reduced form [
2]. Since DL technologies can automatically mine and analyze the data characteristics of labeled data [
13,
14], this makes DL very suitable for image processing and segmentation applications [
14]. Several approaches use autoencoders, a set of unsupervised algorithms, for feature selection and data dimensionality reduction [
31].
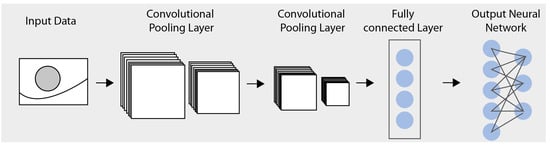
Among the many DL models, CNNs have been widely used in image processing problems, proving more powerful capabilities in image processing than traditional algorithms [
36]. As shown in
Figure 3, a CNN, like a typical neural network, comprises an input layer, an output layer, and several hidden layers [
37]. A single hidden layer in a CNN typically consists of a convolutional layer, a pooling layer, a fully connected layer [
38], and a normalization layer.
Figure 3. Illustration of the structure of a CNN.
Additionally, the number of image-processing applications based on CNNs is also increasing daily [
10]. Among the different DL structures, CNNs have proven to be more efficient in image recognition problems [
20]. On the other hand, they can be used to improve image resolution, enhancing their applicability in real problems, such as the transmission or storage of images or videos [
39].
DL models are frequently used in image segmentation and classification problems, as well as object recognition and image segmentation, and they have shown good results in natural language processing problems. As an example, face recognition applications have been extensively used in multiple real-life examples, such as airports and bank security and surveillance systems, as well as mobile phone functionalities [
10].
There are several possible applications for image-processing techniques. There has been a fast development in terms of surveillance tools like CCTV cameras, making inspecting and analyzing footage more difficult for a human operator. Several studies show that human operators can miss a significant portion of the screen action after 20 to 40 minutes of intensive monitoring [
18]. In fact, object detection has become a demanding study field in the last decade. The proliferation of high-powered computers and the availability of high-speed internet has allowed for new computer vision-based detection, which has been frequently used, for example, in human activity recognition [
18], marine surveillance [
40], pedestrian identification [
18], and weapon detection [
41].
One alternative application of ML in image-processing problems is image super-resolution (SR), a family of technologies that involve recovering a super-resolved image from a single image or a sequence of images of the same scene. ML applications have become the most mainstream topic in the single-image SR field, being effective at generating a high-resolution image from a single low-resolution input. The quality of training data and the computational demand remain the two major obstacles in this process [
42].
3.2. Reinforcement Learning Concepts
RL is a set of ML algorithms that use a mathematical framework that can learn to optimize control strategies directly from the data [
4,
43] based on a reward function in a Markov decision process [
44,
45]. The Markov decision process (MDP) is a stochastic process used to model the decision-making process of a dynamic system. The decision process is sequential, where actions/decisions depend on the current state and the system environment, influencing not only the immediate rewards but also the entire decision process [
4]. One commonly referenced RL problem is
the multi-armed bandit, in which an agent selects one of
n different options and receives a reward depending on the selection. This problem illustrates how RL can provide a trade-off between exploration (trying different arms) and exploitation (playing the arm with the best results) [
44]. This group of algorithms is derived from behaviorist psychology, where an intelligent body explores the external environment and updates its strategy with feedback signals to maximize the cumulative reward [
43], which means the action is exploitative [
46].
In RL, the behavior of the Markov decision process is determined by a reward function [
4]. The basis of a DRL network is made up of an agent and an environment, following an action-reward type of operation. The interaction begins in the environment with the sending of its state to the agent, which takes an action consistent with the state received, according to which it is subsequently rewarded or penalized by the environment [
4,
44,
46,
47,
48]. RL is considered an autonomous learning technique that does not require labeled data but for which search and value function approximation are vital tools [
4]. Often, the success of RL algorithms depends on a well-designed reward function [
45]. Current RL methods still present some challenges, namely the efficiency of the learning data and the ability to generalize to new scenarios [
49]. Nevertheless, this group of techniques has been used with tremendous theoretical and practical achievements in diverse research topics such as robotics, gaming, biological systems, autonomous driving, computer vision, healthcare, and others [
44,
48,
50,
51,
52,
53].
One common technique in RL is random exploration, where the agent makes a decision on what to do randomly, regardless of its progress [
46]. This has become impractical in some real-world applications since learning times can often become very large. Recently, RL has shown a significant performance improvement compared to non-exploratory algorithms [
46,
54]. Another technique, inverse reinforcement learning (IRL), uses an opposite strategy by aiming to find a reward function that can explain the desired behavior [
45]. In a recent study using IRL, Hwang et al. [
45] proposed a new RL method, named
option compatible reward inverse reinforcement learning, which applies an alternative framework to the compatible reward method. The purpose was to assign reward functions to a hierarchical IRL problem that is introduced while making the knowledge transfer easier by converting the information contained in the options into a numerical reward value. While the authors concluded that their novel algorithm was valid in several classical benchmark domains, they remarked that applying it to real-world problems still required extended evaluation.
RL models have been used in a wide variety of practical applications. For example, the COVID-19 pandemic was one of the health emergencies with the widest impact that humans have encountered in the past century. Many studies were directed towards this topic, including many that used ML techniques to several effects. Zong and Luo (2022) [
55] conducted a study where they employed a custom epidemic simulation environment for COVID-19 where they applied a new multi-agent RL-based framework to explore optimal lockdown resource allocation strategies. The authors used real epidemic transmission data to calibrate the employed environment to obtain results more consistent with the real situation. Their results indicate that the proposed approach can adopt a flexible allocation strategy according to the age distribution of the population and economic conditions. These insights could be extremely valuable for decision-makers in supply chain management.
Some technical challenges blocked the combination of DNN with RL until 2015, when breakthrough research demonstrated how the integration could work in complex domains, such as Atari video games [
29,
56], leading to rapid progress toward improving and scaling DRL [
27]. Some of the first successful applications of DRL came with the success of the deep Q network algorithm [
56]. Currently, the application of DRL models to computer vision problems, such as object detection and tracking or image segmentation, has gained emphasis, given the good results it has produced [
31]. RL, along with supervised and unsupervised methods, are the three main pattern recognition models used for research [
57].
The initial advances in RL were boosted by the good performance of the [
56] replay algorithm, as well as the use of two networks, one with fixed weights, which serves as the basis for a second network, for which the weights are iteratively updated during training, replacing the first one when the learning process ends. With the aim of reducing the high convergence times of DRL algorithms, several distributed framework approaches [
58] have been proposed. This suit of methods has been successfully used for applications in computer vision [
59] and in robotics [
58].
4. Current Challenges
Considering everything that has been discussed previously, some of the main challenges that AI image processing faces are common across multiple subjects. Most applications require a large volume of images that are difficult to obtain. Indeed, due to the large amount of data, the process of extracting features from a dataset can become very time and resource-consuming. Some models, such as CNNs, can potentially have millions of parameters to be learned, which might require considerable effort to obtain sufficient labeled data [
60]. Since AI models are heavily curated for a given purpose, the model obtained will likely be inapplicable outside of the specific domain in which it was trained. The performance of a model can be heavily impacted by the data available, meaning the accuracy of the outcome can also vary heavily [
61]. An additional limitation that has been identified during research is the sensitivity of models regarding noisy or biased data [
60]. A meticulous and properly designed data-collection plan is essential, often complemented by a prepossessing phase to ensure good-quality data. Some researchers have turned their attention to improving the understanding of the many models. Increased focus has been placed on the way the weights of a neural network can sometimes be difficult to decipher and extract useful information from, which can lead to wrong assumptions and decisions [
62]. In order to facilitate communication and discussion, some authors have also attempted to provide a categorization system of DL methodologies based on their applications [
31].
This entry is adapted from the peer-reviewed paper 10.3390/jimaging9100207