Currently, laser point clouds have been widely used in many fields, such as autonomous driving, augmented reality and so on. Point cloud classification and segmentation are key to scene understanding. Therefore, many scholars have systematically studied point cloud classification and segmentation. Machine learning approaches are the most commonly used data analysis methods. In the field of point cloud data analysis, deep learning is used for point cloud classification and segmentation. To improve the accuracy of point cloud classification and segmentation, some researchers have drawn on image methods to handle point clouds.
1. Introduction
There are three main categories of point cloud segmentation methods: projection-based methods, voxel-based methods and methods that directly operate on point clouds. Projection-based methods project the point cloud onto a 2D plane to form an image and use 2D CNNs to extract image features. Voxel-based methods divide the point cloud into blocks, and each block of points represents a voxel. Features are extracted from each voxel point cloud and fused to segment the entire point cloud. Point-cloud-based methods directly perform convolutional operations on point clouds, which can effectively obtain feature information from point cloud data.
2. Projection-Based Methods
The key to projection-based methods is constructing multi-view point clouds and then learning the 2D features of the multi-view projections through 2D convolutional operations. Ultimately, the features from the multi-view point clouds are fused. Su et al. [
11] proposed a novel CNN architecture that combines information from multiple views of a 3D shape into a single and compact shape descriptor, offering even better recognition performance. The feature information of multiple views is integrated into a single, compact 3D shape descriptor by convolution and pooling layers, and the aggregated features are fed into a fully connected layer to obtain classification results. Qi et al. [
12] improved multi-view CNN performance through a multi-resolution extension with improved data augmentation, which introduced multi-resolution 3D filtering to capture information at multiple scales. Thereby, the performance of the classification model is enhanced. Xu et al. [
13] designed spatially adaptive convolution based on the structure of the SqueezeSeg model [
14]. The model has the ability to achieve spatial adaptation and content awareness, which solves the problem of network performance degradation caused by traditional convolution applied to LiDAR images.
3. Voxel-Based Methods
Point cloud voxelization [
15] means to voxelize disordered point clouds into regular structures and then use a neural network architecture for feature learning to achieve semantic segmentation of point clouds. Considering the sparsity of point clouds, Graham [
16] designed a sparse convolutional network and applied it to 3D segmentation [
17]. Tchapmi et al. [
18] used the SEGCloud method to subdivide the large point cloud into voxel grids and post-processed them by using trilinear interpolation and conditional random fields. Li et al. [
19] attempted to sample sparse 3D data and then feed the sampled results into a network for processing to reduce the computational effort. Le et al. [
20] proposed the PointGrid method, which employs a 3DCNN to learn grid cells containing fixed points to obtain local geometric details. In addition, Hua et al. [
21] proposed a lightweight, fully convolutional network based on an attention mechanism and a sparse tensor for the semantic segmentation of point clouds.
4. Point-Cloud-Based Methods
The above two methods have high computational complexity. In view of this, the network model based on the original point cloud is gradually proposed. PointNet [
22] was among the earliest approaches to apply deep learning network architectures for processing raw point cloud data. A limitation of this method is that it only extracts global features of point clouds to enable point cloud classification or semantic segmentation without accounting for local features, leading to less-than-ideal network performance for semantic segmentation in large scenes. In order to improve the segmentation performance of point clouds, Charles et al. [
23] proposed PointNet++ by improving the PointNet framework. PointNet++ aims to address the limitation of the original PointNet that only considers global features of point clouds. The addition of the local region segmentation module allows PointNet++ to learn and utilize local geometric features at different scales, thereby improving its performance on large-scene semantic segmentation. Jiang et al. [
24] proposed a hierarchical point–edge interaction network for point cloud semantic segmentation. It introduces an edge convolution operation to interact between point features and edge features for capturing local geometric structures. Unbalanced point cloud scenarios will affect the semantic segmentation accuracy of PointNet++. In view of this problem, Deng et al. [
25] proposed a weighted sampling method based on farthest point sampling (FPS), which can make the sampling process more balanced and reduce the influence of point cloud scene imbalance. Dang et al. [
26] proposed hierarchical parallel group convolution, which can capture both a single point feature and local geometric features of point clouds. Therefore, the model improves the ability of the network to recognize complex classes. He et al. [
27] proposed a multi-feature PointNet (MSMF-PointNet) deep learning point cloud model that can extract multiscale, multi-neighborhood features for classification. Liu et al. [
28] introduces a relation module to learn the relations between points and aggregate neighbor information. Additionally, a shape module is presented to encode absolute geometric features of each point. The two modules are combined to extract comprehensive shape representations. The network can reason about the spatial information features of the point cloud and realize the shape context perception. The global features are obtained through the fully connected layer and then classified. Hu et al. [
29] proposed an efficient and lightweight RandLA-Net network. The model used a local feature aggregation module to expand the range of k-nearest neighbor points to reduce information loss. The random sampling is used to reduce the storage cost and improve computational efficiency. Landrieu et al. [
30] proposed a method for large-scale point cloud semantic segmentation using superpoint graphs. The approach first oversegments the point cloud into a set of superpoints. It then constructs a graph to represent relationships between superpoints. Graph convolutional networks are applied to perform semantic segmentation on the superpoint graph. It can greatly reduce the number of points in a point cloud, and the network can be applied in the field of large-scale point cloud datasets.
5. Proposed Network Architecture
The flowchart of the proposed method is described in Figure 1. First, the input point cloud data are locally partitioned using three different scales of k-nearest neighbors (KNN), and a directed graph is constructed for the extraction of features between points.
Figure 1. Flowchart of the proposed method.
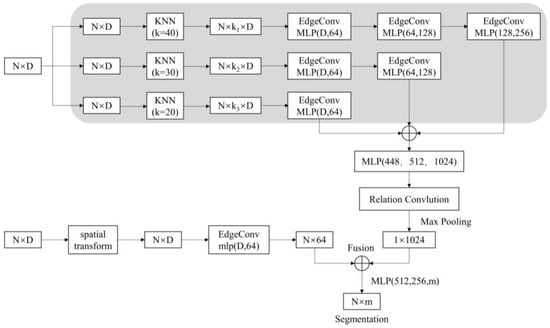
Simultaneously, researchers utilize EdgeConv (edge convolution) layers to extract and aggregate local features of the point cloud. The regular network is then extended to the irregular structures by using relation convolution to further extract the features of the points. Finally, global features are output through maximum pooling. The point cloud deep learning network proposed in this paper is constructed, as shown in Figure 2. The input of the network is the point set P = {p1, p2, …, pn} ⊆ RF, N is the number of sampled points and D is the feature dimension of each point of input.
Figure 2. Proposed network architecture.
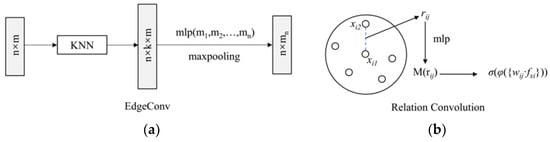
When D = 3, the input points have only three dimensions, which means that the input point cloud data are (x, y, z). The N × D dimensional point clouds are input to the spatial transform networks (STN). The spatial transformation matrix learned by this module can align the coordinates of the input point cloud data. The aligned data are manipulated using a layer of the dynamic graph convolutional network module to obtain local neighborhood features, which are mapped to 64, 128 and 1024 dimensions in sequence by Multi-Layer Perceptron (MLP). The local features of the point cloud are extracted and aggregated by using EdgeConv, as shown in Figure 3a. Deeper feature extraction is then performed using a relation-shape convolution network module, as shown in Figure 3b. It utilizes relation-shape convolution to capture local geometric structures by modeling pairwise spatial relations between points. Global features are obtained through max pooling of the local features.
Figure 3. Structure of edge and relation convolution. (a) Edge Convolution Module. (b) Relation Convolution Module.
Point cloud classification is achieved by applying max pooling and an MLP to the global features. Point cloud segmentation is realized according to the combination of global and local features. It concatenates global and local features and outputs the score per point.
This entry is adapted from the peer-reviewed paper 10.3390/app131910804