Your browser does not fully support modern features. Please upgrade for a smoother experience.
Please note this is an old version of this entry, which may differ significantly from the current revision.
To achieve an acceptable level of security on the web, the Completely Automatic Public Turing test to tell Computer and Human Apart (CAPTCHA) was introduced as a tool to prevent bots from doing destructive actions such as downloading or signing up. Smartphones have small screens, and, therefore, using the common CAPTCHA methods (e.g., text CAPTCHAs) in these devices raises usability issues.
- CAPTCHA
- authentication
- hand gesture recognition
- genetic algorithm
1. Introduction
The Internet has turned into an essential requirement of any modern society, and almost everybody around the world uses it for daily life activities, e.g., communication, shopping, research, etc. The growing number of Internet applications, the large volume of the exchanged information, and the diversity of services attract the attention of people wishing to gain unauthorized access to these resources, e.g., hackers, attackers, and spammers. These attacks highlight the critical role of information security technologies to protect resources and limit access to only authorized users. To this end, various preventive and protective security mechanisms, policies, and technologies are designed [1,2].
Approximately a decade ago, the Completely Automatic Public Turing test to tell Computers and Humans Apart (CAPTCHA) was introduced by Ahn et al. [3] as a challenge-response authentication measure. The challenge, as illustrated in Figure 1, is an example of Human Interaction Proofs (HIPs) to differentiate between computer programs and human users. The CAPTCHA methods are often designed based on open and hard Artificial Intelligence (AI) problems that are easily solvable for human users [4].

Figure 1. The structure of the challenge-response authentication mechanism.
As attempts for unauthorized access increase every day, the use of CAPTCHA is needed to prevent the bots from disrupting services such as subscription, registration, and account/password recovery, running attacks like spamming blogs, search engine attacks, dictionary attacks, email worms, and block scrapers. Online polling, survey systems, ticket bookings, and e-commerce platforms are the main targets of the bots [5].
The critical usability issues of initial CAPTCHA methods pushed the cybersecurity researchers to evolve the technology towards alternative solutions that alleviate the intrinsic inconvenience with a better user experience, more interesting designs (i.e., gamification), and support for disabled users. The emergence of powerful smartphones motivated the researchers to design gesture-based CAPTCHAs that are a combination of cognitive, psychomotor, and physical activities within a single task. This class is robust, user-friendly, and suitable for people with disabilities such as hearing and in some cases vision impairment. A gesture-based CAPTCHA works based on the principles of image processing to detect hand motions. It analyzes low-level features such as color and edge to deliver human-level capabilities in analysis, classification, and content recognition.
2. CAPTCHA Classification
The increasing popularity of the web has made it an attractive ground for hackers and spammers, especially where there are financial transactions or user information [1]. CAPTCHAs are used to prevent bots from accessing the resources designed for human use, e.g., login/sign-up procedures, online forms, and even user authentication [11]. The general applications of CAPTCHAs include preventing comment spamming, accessing email addresses in plaintext format, dictionary attacks, and protecting website registration, online polls, e-commerce, and social network interactions [1].
Based on the background technologies, CAPTCHAs can be broadly classified into three classes: visual, non-visual, and miscellaneous [1]. Each class then may be divided into several sub-classes, as illustrated in Figure 2.
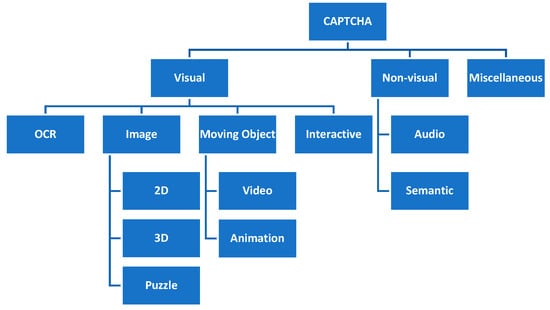
Figure 2. CAPTCHA classification.
The first class is visual CAPTCHA, which challenges the user on its ability to recognize the content. Despite the usability issues for visually impaired people, this class is easy to implement and straightforward.
Text-based or Optic Character Recognition (OCR)-based CAPTCHA is the first sub-class of visual CAPTCHAs. While the task is easy for a human, it challenges the automatic character recognition programs by distorting the combination of numbers and alphabets. Division, deformation, rotation, color variation, size variation, and distortion are some examples of techniques used to make the text unrecognizable for the machine [12]. BaffleText [12], Pessimal Print [13], GIMPY and Ez–Gimpy [14], and ScatterType [15] are some of the proposed methods in this area. Google reCHAPTCHA v2 [16], Microsoft Office, and Yahoo! Mail are famous examples of industry-designed CAPTCHAs [17]. Bursztein et al. [18] designed a model to measure the security of text-based CAPTCHAs. They identified several areas of improvement and designed a generic solution.
Due to the complexity of object recognition tasks, the second sub-class of visual CAPTCHAs is designed on the principles of semantic gap [19]—people can understand more from a picture than a computer. Among the various designed image-based CAPTCHAs, ESP-Pix [3], Imagination [20], Bongo [3], ARTiFACIAL [21], and Asirra [22] are the more advanced ones. The image-based CAPTCHAs have two variations: 2D and 3D [23]. In fact, the general design of the methods in this sub-class is 2D; however, some methods utilize 3D images (of characters) as a human is easier to recognize in 3D images. Another type of image-based CAPTCHA is a puzzle game designed by Gao et al. [24]. The authors used variants in color, orientation, and size, and they could successfully enhance the security. They prove that puzzle-based CAPTCHAs need less time than text-based ones. An extended version of [24] that uses animation effects was later developed in [25].
Moving object CAPTCHA is a relatively new trend that shows a video and asks the users to type what they have perceived or seen [26]. Despite being secure, this method is very complicated and expensive compared to the other solutions.
The last sub-class of visual CAPTCHAs, interactive CAPTCHA, tries to increase user interactions to enhance security. This method requires more mouse clicks, drag, and similar activities. Some variations request the user to type the perceived or identified response. Except for the users that have some sort of disabilities, solving the challenges is easy for humans but hard for computers. The methods designed by Winter-Hjelm et al. [27] and Shirali-Shahreza et al. [28] are two interactive CAPTCHA examples.
The second CAPTCHA class contains non-visual methods in which the user is assessed based on audio and semantic tests. The audio-based methods are subjected to speech recognition attacks, while the semantic-based methods are very secure, and it is much harder for them to be cracked by computers. Moreover, semantic-based methods are relatively easy for users, even the ones with hearing or visual impairment. However, the semantic methods might be very challenging for users with cognitive deficiencies [1].
The first audio-based CAPTCHA method was introduced by Chan [29], and later other researchers such as Holman et al. [30] and Schlaikjer [31] proposed more enhanced methods. A relatively advanced approach in this area is to ask the user to repeat the played sentence. The recorded response is then analyzed by a computer to check if the recorded speech is made by a human or a speech synthesis system [28]. Limitations of this method include requiring equipment such as a microphone and speaker and being difficult for people with hearing and speech disabilities.
Semantic CAPTCHAs are relatively a secure CAPTCHA sub-class as computers are far behind the capabilities of humans in answering semantic questions. However, they still are vulnerable to attacks that use computational knowledge engines, i.e., search engines or Wolfram Alpha. The implementation cost of semantic methods is very low as they are normally presented in a plaintext format [1]. The works by Lupkowski et al. [32] and Yamamoto et al. [33] are examples of a semantic CAPTCHA.
The third CAPTCHA class utilizes diverse technologies, sometimes in conjunction with visual or audio methods, to present techniques with novel ideas and extended features. Google’s reCAPTCHA is a free service [16] for safeguarding websites from spam or unauthorized access. The method works based on adaptive challenges and an advanced risk analysis system to prevent bots from accessing web resources. In reCAPTCHA, the user first needs to click on a checkbox. If it fails, the user then needs to select specific images from the set of given images. Google, in 2018, released the third version, i.e., reCAPTCHA v3 or NoCAPTCHA [34]. This version monitors the user’s activities and reports the probability of them being human or robot without needing the user to click the “I’m not a robot” checkbox. However, NoCAPTCHA is vulnerable to some technical issues such as erasing cookies, blocking JavaScript, and using incognito web browsing.
Yadava et al. [35] designed a method that displays the CAPTCHA for a fixed time and refreshes it until the user enters the correct answer. The refreshment only changes the CAPTCHA, not the page, and the defined time makes cracking it harder for the bots.
Wang et al. [36] put forward a graphical password scheme based on CAPTCHAs. The authors claimed that it can strengthen security by enhancing the capability to resist brute force attacks, withstand spyware, and reduce the size of password space.
Solved Media presented an advertisement CAPTCHA method in which the user should enter a response to the shown advertisement to pass the challenge. This idea can be extended to different areas, e.g., education or culture [1].
A recent trend is to design personalized CAPTCHAs that are specific to the users based on their conditions and characteristics. In this approach, an important aspect is identifying the cognitive capabilities of the user that must be integrated into the process of designing the CAPTCHA [37]. Another aspect is personalizing the content by considering factors such as geographical location to prevent third-party attacks. As an example, Wei et al. [38] developed a geographic scene image CAPTCHA that combines Google Map information and an image-based CAPTCHA to challenge the user with information that is privately known.
Solving a CAPTCHA on a small screen of a smartphone might be a hassle for the users. Jiang et al. [39] found that wrong touches on the screen of a mobile phone decrease the CAPTCHA performance. Analysis of the user’s finger movements in the back end of the application can help in differentiating between a bot and a human [40]. For example, by analyzing the sub-image dragging pattern, their method can detect whether the action is “BOTish” or “HUMANish”. Some similar approaches, like [41,42], challenge the user to find segmentation points in cursive words.
In the area of hand gesture recognition (HGR), the early solutions used a data glove, hand belt, and camera. Luzhnica et al. [43] used a hand belt equipped with a gyroscope, accelerometer, and Bluetooth for HGR. Hung et al. [44] acquired the input required data from hand gloves. Another research work used the Euclidean distance for analyzing twenty-five different hand gestures and employed an SVM for classification and controlling tasks [45]. In another effort [46], the researchers converted the red, green, and blue (RGB) captured images to grayscale, applied a Gaussian filter for noise reduction, and fed the results to a classifier to detect the hand gesture.
Chaudhary et al. [47] used a normal Windows-based webcam for recording user gestures. Their proposed method extracts the region of interest (ROI) from frames and applies a hue-saturation-value (HSV)-based skin filter on RGB images, in particular, illumination conditions. To help the fingertip detection process, the method analyzes hand direction according to pixel density in the image. It also detects the palm hand based on the number of pixels located in a 30 × 30-pixel mask on the cropped ROI image. The method has been implemented by a supervised neural network based on the Levenberg–Marquardt algorithm and uses eight thousand samples for all fingers. The architecture of the method has five input layers for five input finger poses and five output layers for the bent angle of the fingers. Marium et al. [48] extracted the hand gestures, palms, fingers, and fingertips from webcam videos using the functions and connectors in OpenCV.
Simion et al. [49] researched finger pose detection for mouse control. Their method, in the first step, detects the fingertips (except the thumb) and palm hand. Its second step is to calculate the distances between the pointing and middle fingers to the center of the palm and the distance between the tips of the pointing and middle fingers. The third step is to compute the angles between the two fingers, between the pointing finger and the x-axis, and between the middle finger and the x-axis. The researchers used six hand poses for mouse movements including right/left click, double click, and right/left movement.
This entry is adapted from the peer-reviewed paper 10.3390/electronics12194084
This entry is offline, you can click here to edit this entry!