Your browser does not fully support modern features. Please upgrade for a smoother experience.
Please note this is an old version of this entry, which may differ significantly from the current revision.
Automatic modulation classification (AMC) is a vital process in wireless communication systems that is fundamentally a classification problem. It is employed to automatically determine the type of modulation of a received signal. Deep learning (DL) methods have gained popularity in addressing the problem of modulation classification, as they automatically learn the features without needing technical expertise.
- automatic modulation classification
- deep neural network
- residual learning
1. Introduction
In wireless communication, the complexity of the environment and the signals is rapidly increasing. A vital phenomenon in ad-hoc networks such as cognitive radio (CR) and software-defined radio (SDR) is automatic modulation classification (AMC) [1]. In modulation, information is typically communicated between the transmitter and receiver in a standard communication environment [2], whereas devices in CR transmitters autonomously choose modulation schemes based on external contexts, and CR receivers should independently verify signal modulation patterns [3]. AMC assists the CR receivers in identifying the type of modulation selected by the transmitter. In SDR, AMC is applied to quickly respond to diverse and evolving communication networks whilst avoiding protocols overhead. The current technology in a cognitive jamming scenario involves the automatic discovery of the modulation schemes utilized by both favorable and adversarial signals [1].
While military technology has always been a driving force behind the advancement of AMC, commercial applications such as interference detection and spectrum sensing are also widespread [4]. The development of the 5th generation of telecommunication networks (5G), which is predicted to result in the proliferation of end devices in use and congestion of the electromagnetic spectrum, has sparked renewed interest in AMC. Without knowing the system parameters, AMC is used to determine the transmitter’s modulation configuration from the received signal as shown in Figure 1.
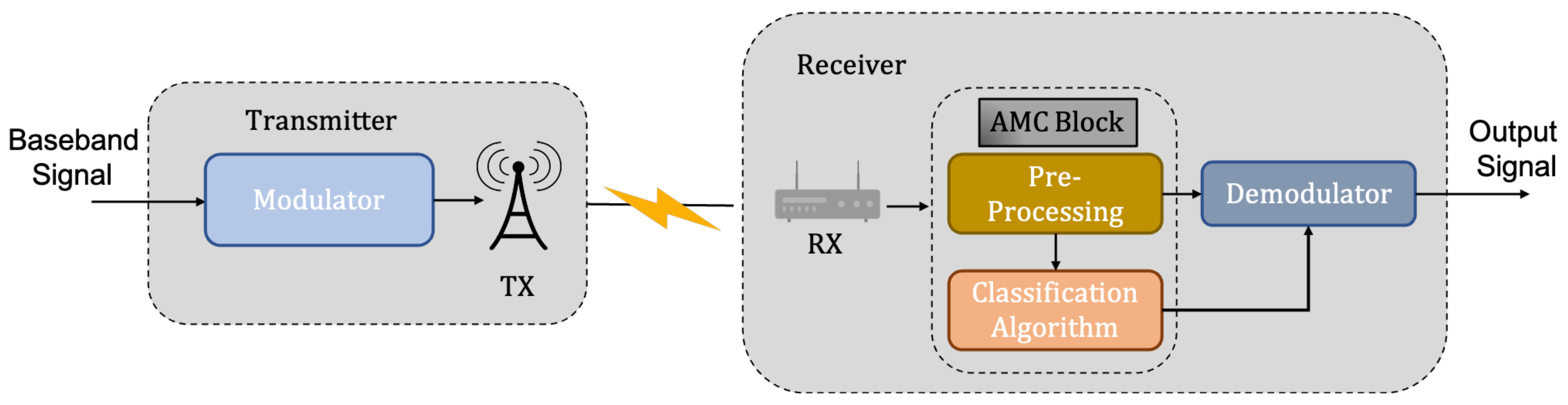
Figure 1. Block diagram of a communication link with automatic modulation classification.
Signal, noise, and channel models have a significant effect on the classification result. Therefore, they are all used to develop AMC techniques. When the expected signal model or noise model does not fit the actual signal or noise, the corresponding classification model fails to perform adequately. A more sophisticated model may be expected to mostly reduce the gap with the real scenario. There are many unspecified parameters to evaluate, which leads to greater estimation mistakes, and the additional computing complexity cannot be overlooked. Furthermore, certain situations, such as molecular communications may not have manageable predictive methods, severely decreasing the classification accuracy of the typical design classifier [5]. Due to computing complexity, they have been restricted in their relevancy to a wider range of fields. Data-driven AMC methods have been designed to address these complexities [6].
2. A Lightweight Deep Learning Model for Automatic Modulation Classification Using Residual Learning and Squeeze–Excitation Blocks
2.1. Likelihood-Based (LB) Method
AMC is treated as a hypothesis-testing problem in the LB method. The algorithm based on the LB method can be efficient from a Bayesian perspective, and it is beneficial for reducing the likelihood of a hypothesis problem occurring. High computational complexity often affects accurate decisions, which can be difficult to obtain in actual systems. The LB method can reduce the probability of misclassification and can obtain the best classification accuracy, as such methods maximize the chance of correct classification with perfect channel situations. Furthermore, in real-world scenarios, uncertainty factors must be considered, and the likelihood function is ineffective in handling any unknown parameters. The unknown parameters problem is replaced with the essential component of their probability density function (PDF) in the average-likelihood ratio test (ALRT) [7]. However, as the number of missing factors grow, the likelihood function in ALRT becomes more sophisticated, resulting in a significant processing cost. To solve the complexity, the generalized likelihood ratio test (GLRT) was developed. The parameters in GLRT are estimated by using a maximum likelihood (ML) estimator [8]. This biased classifier affects the performance of nested modulations such as 16-quadrature amplitude modulation (QAM) and 64-QAM. The hybrid likelihood ratio test (HLRT) improves the performance of the likelihood function with respect to the unknown function. It first evaluates the likelihood of the data symbols as discrete random variables, consistently allocated across the alphabet set, and considers the carrier phase as a predetermined variable [9]. Since this method requires prior information about the signal, including its carrier frequency and other channel parameters, its implementation becomes difficult in the presence of complex and unknown parameters. Despite their ability to provide optimal solutions, they may not be appropriate in practical scenarios [10].
2.2. Feature-Based (FB) Method
FB methods, which are widely used for AMC, extract features from the received signal and feed them into a classification system [11]. They are found to outperform LB techniques in terms of reliability and computational overhead. To detect the modulation type of a signal, FB methods have been employed on a set of data description features, which assist in formulating decisions [6]. There are two steps to the creation of FB modulation classification method: preprocessing and a classification algorithm.
-
Preprocessing: This stage is responsible for extracting features from the received signal. Different features can be chosen based on various circumstances and predictions. Certain immediate aspects of the signal, such as instantaneous signal power, frequency, phase, amplitude, and so on, are retrieved during the feature extraction phase [12]. As a result, these characteristics transform the raw data into patterns that must be learned by the classifier for the purpose of recognition.
-
Classification Algorithm: The classification algorithm utilizes the features from the preprocessor as an input, and outputs the modulation type of the signal for each received signal.
The FB approach creates a higher-dimensional environment in which signal characteristics can be isolated using a hyperplane [13]. Among the most commonly utilized features in FB approaches, high-order cumulants [14], wavelet transform [15], and cyclostationary features [16] are principally employed for feature extraction. In noncooperative circumstances, these statistical characteristics are often combined to improve reliability. A classifier processes and compares the obtained statistical properties of the incoming signal, with preset limits, to identify the modulation type in the classifier step.
Comparison between Likelihood-Based and Feature-Based Method
In contemporary research, several classifiers have been presented, notably maximum likelihood [17], distribution test-based [12], and machine learning-based classifiers. Notably, the efficiency and statistical complexity of each classifier are routinely measured. For every realistic implementation, choosing the proper classifier is crucial [18]. In contrast to the processes employed in likelihood-based AMC, statistical methods for feature extraction are often particularly less complex in terms of processing cost. Due to their intrinsic low complexity and the use of blind modulation schemes, feature-based techniques are increasingly popular for real-life scenarios, which demand no extra information about the signal or channel [19]. Therefore, owing to the aforementioned features, these two types of classifiers have dominated AMC for decades. In comparison, the LB classifier can find the best solution using Bayes sense to reduce the likelihood of incorrect classification. The FB method can achieve high reliability for recognizing basic modulation types such as BPSK and QPSK [20]. Moreover, for assessing unknown values, LB classifications possess a high computing complexity [21], whilst the FB classifier’s efficacy is significantly impacted by feature cohesion. Conventional AMC innovation has always relied on likelihood- and feature-based techniques. It seeks to develop more effective features and classifiers [22]. With the advancement of artificial intelligence in the past few decades, deeper learning-based algorithms have been utilized to tackle the AMC issues presented in [23][24]. With the data presented in [23], a convolutional neural network (CNN) for AMC and investigated structure optimal depth was proposed. Furthermore, in [24], a data-driven model based on LSTM was presented to overcome the AMC problem. A design composed of LSTM and CNN modules was considered as a solution for achieving high efficiency of AMC with different SNR regions. AMC approaches usually depend on feature extraction to reduce the complexity of signal data and classification accuracy [20]. In modern times, deep learning has made significant progress in a variety of applications, including resource allocation in LoRaWAN [25], edge computing [26], control science [27], voice recognition [28], and bioinformatics [29][30]. The capability of DL to easily discover features, from data in an end-to-end process, is partly responsible for the achievement of conceptual tasks due to its superior feature extraction and classification abilities. Therefore, the DL-based AMC technique can accurately analyze and detect modulated signals [31].
2.3. Deep Learning Techniques for Automatic Modulation Classification
Model-driven approaches mostly choose their features based on experience [32]. FB techniques lose certain original details whilst extracting some statistical features. This affects the performance of categorization, especially in low-SNR circumstances, while the DL-based network may extract highly representative features from the source signals and incorporate feature extraction as part of the classifier training process. Consequently, it surpasses conventional FB approaches in terms of classification performance [33].
For AMC problems, the first DL technique was used in [34], which consisted of a convolutional neural network (CNN) based on synthetic datasets for model learning, testing, and analysis (known as RML2016.10A and RML2016.04C). Due to the simplistic architecture of the convolution design, the accuracy rate was 71.30%71.30% and 87.4%87.4% with RML2016.10A and RML2016.04C, respectively. The datasets RML2016.10A and RML2016.04C will be referred to as 𝐷1 and 𝐷2, respectively. The authors of [35] utilized the dataset of [34] to demonstrate the response of a convolutional neural network to temporal radio signals with complex values. The researchers evaluated the efficacy of radio modulation categorization by comparing naively learned features with expert feature-based approaches that are commonly used today. The study results revealed that the former approach had superior performance. The researchers evaluated the efficacy of radio modulation categorization by comparing naively learned features with expert feature-based approaches that are commonly used today. The study results revealed that the former approach had superior performance.
The work in [36] used the 𝐷1 dataset from [34], and an 80%80% classification accuracy was achieved through the implementation of a signal distortion correction module (CM). Recently, in DL-based methods, researchers have utilized residual learning techniques that were used for the feature-based approach initially introduced by He et al. [37]. The residual structure was employed to overcome the degradation issue and extract discriminative features to achieve sufficient performance. For AMC, the residual learning-based method was deployed in [38]. The ResNet structure was employed to identify the modulation formats for AMC, in which they yield moderate classification accuracy without any network structure adjustments. The authors of [39] proposed an innovative shared model based on a deep learning network using CNN-LSTM utilizing two expert features: wideband frequency modulation (WBFM) and quadrature amplitude modulation (QAM), to improve classification accuracy, and achieved better accuracy with 𝐷1. In [40], a DL-based technique for categorizing signal modulation was proposed. The researchers compared multiple DL algorithms by leveraging insights from previous studies and utilizing a diverse set of layers to enhance the existing designs. They employed various techniques such as convolutional layers, dropout layers, and Gaussian noise layers to reduce overfitting and modify the scenario. Additionally, they improved accuracy while minimizing compute time by using a reduced number of filters in each layer. In [41], three efficient models for AMC—a convolutional long short-term deep neural network (CLDNN), a long short-term memory neural network (LSTM), and a deep residual network (ResNet)—were investigated, with the goal of ensuring high accuracy whilst shortening the time needed in order to train the systems.
This entry is adapted from the peer-reviewed paper 10.3390/app13085145
References
- Liu, X.; Wang, Q.; Wang, H. A Two-Fold Group Lasso Based Lightweight Deep Neural Network for Automatic Modulation Classification. In Proceedings of the 2020 IEEE International Conference on Communications Workshops (ICC Workshops), Dublin, Ireland, 7–11 June 2020; pp. 1–6.
- Kim, B.; Kim, J.; Chae, H.; Yoon, D.; Choi, J.W. Deep neural network-based automatic modulation classification technique. In Proceedings of the 2016 International Conference on Information and Communication Technology Convergence (ICTC), Jeju, Republic of Korea, 19–21 October 2016; pp. 579–582.
- Liang, Y.C.; Chen, K.C.; Li, G.Y.; Mahonen, P. Cognitive radio networking and communications: An overview. IEEE Trans. Veh. Technol. 2011, 60, 3386–3407.
- Triantaris, P.; Tsimbalo, E.; Chin, W.H.; Gündüz, D. Automatic modulation classification in the presence of interference. In Proceedings of the 2019 European Conference on Networks and Communications (EuCNC), Valencia, Spain, 18–21 June 2019; pp. 549–553.
- Huang, S.; Dai, R.; Huang, J.; Yao, Y.; Gao, Y.; Ning, F.; Feng, Z. Automatic modulation classification using gated recurrent residual network. IEEE Internet Things J. 2020, 7, 7795–7807.
- Dobre, O.A.; Abdi, A.; Bar-Ness, Y.; Su, W. Survey of automatic modulation classification techniques: Classical approaches and new trends. IET Commun. 2007, 1, 137–156.
- Ramezani-Kebrya, A.; Kim, I.M.; Kim, D.I.; Chan, F.; Inkol, R. Likelihood-based modulation classification for multiple-antenna receiver. IEEE Trans. Commun. 2013, 61, 3816–3829.
- Polydoros, A.; Kim, K. On the detection and classification of quadrature digital modulations in broad-band noise. IEEE Trans. Commun. 1990, 38, 1199–1211.
- Panagiotou, P.; Anastasopoulos, A.; Polydoros, A. Likelihood ratio tests for modulation classification. In Proceedings of the MILCOM 2000 Proceedings. 21st Century Military Communications. Architectures and Technologies for Information Superiority (Cat. No. 00CH37155), Los Angeles, CA, USA, 22–25 October 2000; IEEE: Piscataway, NJ, USA, 2000; Volume 2, pp. 670–674.
- Majhi, S.; Gupta, R.; Xiang, W.; Glisic, S. Hierarchical hypothesis and feature-based blind modulation classification for linearly modulated signals. IEEE Trans. Veh. Technol. 2017, 66, 11057–11069.
- Usman, M.; Lee, J.A. AMC-IoT: Automatic Modulation Classification Using Efficient Convolutional Neural Networks for Low Powered IoT Devices. In Proceedings of the 2020 International Conference on Information and Communication Technology Convergence (ICTC), Jeju, Republic of Korea, 21–23 October 2020; pp. 288–293.
- Ghasemzadeh, P.; Banerjee, S.; Hempel, M.; Sharif, H. Accuracy analysis of feature-based automatic modulation classification with blind modulation detection. In Proceedings of the 2019 International Conference on Computing, Networking and Communications (ICNC), Honolulu, HI, USA, 18–21 February 2019; pp. 1000–1004.
- Khan, R.; Yang, Q.; Ullah, I.; Rehman, A.U.; Tufail, A.B.; Noor, A.; Rehman, A.; Cengiz, K. 3D convolutional neural networks based automatic modulation classification in the presence of channel noise. IET Commun. 2022, 16, 497–509.
- Huang, S.; Yao, Y.; Wei, Z.; Feng, Z.; Zhang, P. Automatic modulation classification of overlapped sources using multiple cumulants. IEEE Trans. Veh. Technol. 2016, 66, 6089–6101.
- Ho, K.; Prokopiw, W.; Chan, Y. Modulation identification of digital signals by the wavelet transform. IEE Proc.-Radar, Sonar Navig. 2000, 147, 169–176.
- Dobre, O.A.; Oner, M.; Rajan, S.; Inkol, R. Cyclostationarity-based robust algorithms for QAM signal identification. IEEE Commun. Lett. 2011, 16, 12–15.
- Huynh-The, T.; Nguyen, T.V.; Pham, Q.V.; Kim, D.S.; Da Costa, D.B. MIMO-OFDM Modulation Classification Using Three-Dimensional Convolutional Network. IEEE Trans. Veh. Technol. 2022, 71, 6738–6743.
- Cardoso, C.; Castro, A.R.; Klautau, A. An efficient FPGA IP core for automatic modulation classification. IEEE Embed. Syst. Lett. 2013, 5, 42–45.
- Hou, C.; Liu, G.; Tian, Q.; Zhou, Z.; Hua, L.; Lin, Y. Multi-signal Modulation Classification Using Sliding Window Detection and Complex Convolutional Network in Frequency Domain. IEEE Internet Things J. 2022, 9, 19438–19449.
- Hazza, A.; Shoaib, M.; Alshebeili, S.A.; Fahad, A. An overview of feature-based methods for digital modulation classification. In Proceedings of the 2013 1st International Conference on Communications, Signal Processing, and Their Applications (ICCSPA), Sharjah, United Arab Emirates, 12–14 February 2013; pp. 1–6.
- Hameed, F.; Dobre, O.A.; Popescu, D.C. On the likelihood-based approach to modulation classification. IEEE Trans. Wirel. Commun. 2009, 8, 5884–5892.
- Abdel-Moneim, M.A.; Al-Makhlasawy, R.M.; Abdel-Salam Bauomy, N.; El-Rabaie, E.S.M.; El-Shafai, W.; Farghal, A.E.; Abd El-Samie, F.E. An efficient modulation classification method using signal constellation diagrams with convolutional neural networks, Gabor filtering, and thresholding. Trans. Emerg. Telecommun. Technol. 2022, 33, e4459.
- Zhou, Y.; Fadlullah, Z.M.; Mao, B.; Kato, N. A deep-learning-based radio resource assignment technique for 5G ultra dense networks. IEEE Netw. 2018, 32, 28–34.
- Huang, H.; Guo, S.; Gui, G.; Yang, Z.; Zhang, J.; Sari, H.; Adachi, F. Deep learning for physical-layer 5G wireless techniques: Opportunities, challenges and solutions. IEEE Wirel. Commun. 2019, 27, 214–222.
- Farhad, A.; Kim, D.H.; Yoon, J.S.; Pyun, J.Y. Deep Learning-Based Channel Adaptive Resource Allocation in LoRaWAN. In Proceedings of the 2022 International Conference on Electronics, Information, and Communication (ICEIC), Jeju, Republic of Korea, 6–9 February 2022; pp. 1–5.
- Blanco-Filgueira, B.; Garcia-Lesta, D.; Fernández-Sanjurjo, M.; Brea, V.M.; López, P. Deep learning-based multiple object visual tracking on embedded system for IoT and mobile edge computing applications. IEEE Internet Things J. 2019, 6, 5423–5431.
- Usama, M.; Lee, I.Y. Data-Driven Non-Linear Current Controller Based on Deep Symbolic Regression for SPMSM. Sensors 2022, 22, 8240.
- Deng, L.; Hinton, G.; Kingsbury, B. New types of deep neural network learning for speech recognition and related applications: An overview. In Proceedings of the 2013 IEEE International Conference on Acoustics, Speech and Signal Processing, Vancouver, BC, Canada, 26–31 May 2013; pp. 8599–8603.
- Usman, M.; Khan, S.; Lee, J.A. Afp-lse: Antifreeze proteins prediction using latent space encoding of composition of k-spaced amino acid pairs. Sci. Rep. 2020, 10, 7197.
- Usman, M.; Khan, S.; Park, S.; Lee, J.A. AoP-LSE: Antioxidant Proteins Classification Using Deep Latent Space Encoding of Sequence Features. Curr. Issues Mol. Biol. 2021, 43, 1489–1501.
- Wei, X.; Luo, W.; Zhang, X.; Yang, J.; Gui, G.; Ohtsuki, T. Differentiable Architecture Search-Based Automatic Modulation Classification. In Proceedings of the 2021 IEEE Wireless Communications and Networking Conference (WCNC), Nanjing, China, 29 March–1 April 2021; pp. 1–6.
- Ullah, A.; Abbas, Z.H.; Zaib, A.; Ullah, I.; Muhammad, F.; Idrees, M.; Khattak, S. Likelihood ascent search augmented sphere decoding receiver for MIMO systems using M-QAM constellations. IET Commun. 2020, 14, 4152–4158.
- Guo, Y.; Liu, Y.; Oerlemans, A.; Lao, S.; Wu, S.; Lew, M.S. Deep learning for visual understanding: A review. Neurocomputing 2016, 187, 27–48.
- O’shea, T.J.; West, N. Radio machine learning dataset generation with gnu radio. In Proceedings of the 6th GNU Radio Conference, Boulder, CO, USA, 12–16 September 2016; Volume 1.
- O’Shea, T.J.; Corgan, J.; Clancy, T.C. Convolutional radio modulation recognition networks. In International Conference on Engineering Applications of Neural Networks; Springer: Cham, Switzerland, 2016; pp. 213–226.
- Yashashwi, K.; Sethi, A.; Chaporkar, P. A learnable distortion correction module for modulation recognition. IEEE Wirel. Commun. Lett. 2018, 8, 77–80.
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778.
- Liu, X.; Yang, D.; El Gamal, A. Deep neural network architectures for modulation classification. In Proceedings of the 2017 51st Asilomar Conference on Signals, Systems, and Computers, Pacific Grove, CA, USA, 29 October–1 November 2017; pp. 915–919.
- Yao, T.; Chai, Y.; Wang, S.; Miao, X.; Bu, X. Radio signal automatic modulation classification based on deep learning and expert features. In Proceedings of the 2020 IEEE 4th Information Technology, Networking, Electronic and Automation Control Conference (ITNEC), Chongqing, China, 12–14 June 2020; Volume 1, pp. 1225–1230.
- Zhang, H.; Huang, M.; Yang, J.; Sun, W. A Data Preprocessing Method for Automatic Modulation Classification Based on CNN. IEEE Commun. Lett. 2020, 25, 1206–1210.
- Ramjee, S.; Ju, S.; Yang, D.; Liu, X.; Gamal, A.E.; Eldar, Y.C. Fast deep learning for automatic modulation classification. arXiv 2019, arXiv:1901.05850.
This entry is offline, you can click here to edit this entry!