Your browser does not fully support modern features. Please upgrade for a smoother experience.
Please note this is an old version of this entry, which may differ significantly from the current revision.
Face anti-spoofing is critical for enhancing the robustness of face recognition systems against presentation attacks. Existing methods predominantly rely on binary classification tasks. An adversarial learning process is designed to narrow the differences between domains, achieving the effect of aligning the features of multiple sources, thus resulting in multi-domain alignment.
- multi-domain feature alignment domain generalization (MADG)
- face anti-spoofing
- feature alignment
- multiple source domain
1. Introduction
With the extensive use of deep learning in computer vision, face recognition (FR) [1,2] technology has become increasingly important in daily life, particularly in scenarios that require user identification and authorization. Despite significant progress in FR, these systems remain susceptible to various types of attacks, such as print attacks, replayed video attacks, and 3D mask attacks. To address these challenges, current state-of-the-art research has proposed various methods for face anti-spoofing (FAS) [3,4,5,6]. These methods can be broadly categorized into two groups: hand-crafted feature-based and deep learning feature-based approaches.
Despite the notable achievements of previous face anti-spoofing (FAS) methods in intra-domain testing, their performance significantly deteriorates in cross-domain testing. This is primarily due to the introduction of bias resulting from the distinct characteristics of domains and the inability to address such bias by considering their internal relationships. Consequently, the generalization effect of the model on the novel domain is insufficient. To mitigate this limitation, recent studies have utilized unsupervised-learning-based domain adaptation (DA) techniques to eliminate the domain bias between source and target domains. Nevertheless, the target domain usually denotes an unseen domain for the source domain, and acquiring an adequate amount of target domain data for training in real-world scenarios is not typically feasible.
In response to the weakness of a model’s generalization in the unseen domain, several studies related to domain generalization (DG) have been proposed. Conventional DG [7] proposed a novel multi-adversarial discriminative method to learn a discriminative multi-domain feature space and improve the generalization performance. This method aimed to find a feature space with multiple source domains aligned, assuming that the feature extracted from the unseen domain can map near that feature space, indicating that the model is well generalized over the target domain. However, Conventional DG fails to account for the difference in generalization between real and fake faces. To address this limitation, SSDG [8] proposed an end-to-end single-side method that separates the feature distributions of real and fake faces by pulling all the real faces and pushing the fake faces of different domains, resulting in a higher classification capacity than Conventional DG. However, this method is insufficient in eliminating the interference of domain-related cues in the domain generalization problem. Motivated by the above works, this study aims to align the feature spaces corresponding to multiple source domains while dividing the distribution of fake and real faces. As shown in Figure 1, the method aligns multiple source domains to obtain a more generalizable feature space, outperforming the baseline method in terms of generalization and classification performance.
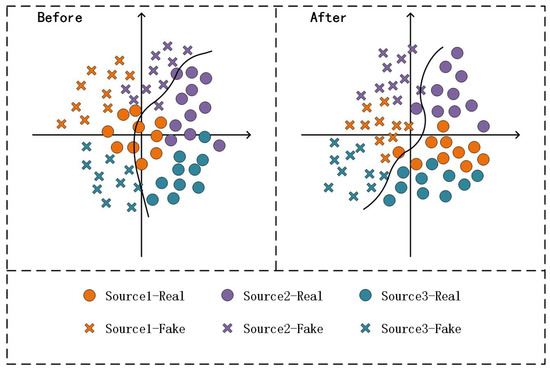
Figure 1. Schematic diagram of the multi-source domain alignment algorithm proposed in this method. The distribution plot on the left illustrates the sample distribution from the source domain before feature alignment, while the plot on the right demonstrates the distribution after feature alignment in the feature space. Notably, the original distributions from different domains exhibit distinct dissimilarities; however, the feature alignment enhances the uniformity of each domain’s distribution in the feature space.
2. Face Anti-Spoofing Methods
There exist two principal categories of conventional face anti-spoofing (FAS) techniques: appearance-based and temporal-based methods. Appearance-based methods involve the extraction of hand-crafted features for classification, such as local binary patterns (LBPs) [9,10] and scale-invariant feature transform (SIFT) [11]. However, temporal-based FAS methods detect attack faces by extracting temporal cues from a sequence of consecutive face frames. Mouth movement detection [12] and eye blink detection [13,14] are examples of the earliest dynamic texture-detection methods. However, these methods do not generalize well to cross-dataset testing scenarios due to the dissimilarities in feature spaces among diverse domains, which often lead to feature bias during generalization.
Recently, deep neural networks, specifically convolutional neural networks (CNNs), have gained widespread adoption in computer vision tasks and have been extensively applied to FAS. Yang et al. [15] were the pioneers in utilizing binary classification CNNs for FAS. Jourabloo et al. [16] proposed a face de-spoofing technique that performs fake face classification by reverse decomposition into real faces and spoof noise. Liu et al. [17] presented a CNN-RNN network that combines both appearance and temporal cues to detect spoof attacks using remote photoplethysmography (rPPG) signals. Similarly, 3D mask detection attack methods [18,19] also exploit rPPG information. Yang et al. [20] combined temporal and appearance cues to detect fake faces from real ones. Roy et al. [21] investigated frame-level FAS to enhance biometric authentication security against face-spoofing attacks. More recently, deep neural networks have been applied to FAS [4,7,8,22,23,24], achieving superior performance compared to conventional methods [15,25,26,27].
In conclusion, traditional FAS methods include appearance-based and temporal-based methods, which extract hand-crafted features and mine temporal cues, respectively. However, deep neural networks, especially CNNs, have achieved state-of-the-art performance in FAS by combining the appearance and temporal cues, using techniques such as reverse decomposition and frame-level FAS for improved biometric authentication security.
3. Multi-Domain Learning
The use of multiple datasets has recently sparked research interest in multi-domain processing. In particular, the research community has amassed several large-scale FAS datasets with rich annotations [28,29,30,31]. The work on multi-source domain processing shares similarities with domain adaptation (DA) methods [32,33,34,35,36,37,38,39] that require a retrained model to perform well on both source and target domain data. Specifically, Zhang et al. [37] introduced the concept of margin disparity discrepancy to characterize the differences between source and target domains, which has inspired the researchers' work. Ariza et al. [40] conducted a comparative study of several classification methods, which informed the researchers' experimental design. Additionally, Liu et al. [41] proposed the YOLOv3-FDL model for successful small crack detection from GPR images using a four-scale detection layer. Notably, the common approaches of Mancini et al. [34] and Rebuffi et al. [35] employ the ResNet [42] architecture, which offers benefits over architectures such as VGG [43] and AlexNet [44] by increasing abstraction through convolutional layers. Yang et al. [45] recently enriched FAS datasets from a different perspective to achieve multi-domain training, while Guo et al. [46] proposed a novel multi-domain model that overcomes the forgetting problem when learning new domain samples and exhibits high adaptability.
4. Domain Generalization
Domain adaptation (DA) and domain generalization (DG) are two fundamental methods used in FAS research. While the DG method mines the relationships among multiple domains, the DA method aims to adapt the model to a target domain. In this work, the researchers propose a novel domain generalization method that introduces a new loss function inspired by the work of Motiian et al. [47], which encourages feature extraction in similar classes. To align multiple source domains for generalization, previous works such as Ghifary et al. [48] and Li et al. [49] have proposed autoencoder-based approaches. The method follows a similar approach of learning a shared feature space across multiple source domains that can generalize to the target domain. Previous works such as Shao et al. [7], Saha et al. [50], Jia et al. [8], and Kim et al. [51] have also attempted to achieve this goal. Among them, the single-side adversarial learning method proposed in SSDG [8] is the work most related to ours. However, this end-to-end approach overlooks the relationships between different domains. To address the overfitting and generalization problems of adversarial generative networks, Li et al. [5] proposed a multi-channel convolutional neural network (MCCNN). Additionally, meta-learning formulations [52,53,54] have been utilized to simulate the domain shift during training to learn a representative feature space. However, recent works such as Wang et al. [6] have not adopted a domain-alignment approach but have instead increased the diversity of labeled data by reassembling different styles and content features in their SSAN method.
This entry is adapted from the peer-reviewed paper 10.3390/s23084077
This entry is offline, you can click here to edit this entry!