Depth estimation is an important part of the perception system in autonomous driving. Studies often reconstruct dense depth maps from RGB images and sparse depth maps obtained from other sensors. However, existing methods often pay insufficient attention to latent semantic information. Considering the highly structured characteristics of driving scenes, the researchers propose a dual-branch network to predict dense depth maps by fusing radar and RGB images. The driving scene is divided into three parts in the proposed architecture, each predicting a depth map, which is finally merged into one by implementing the fusion strategy in order to make full use of the potential semantic information in the driving scene.
- depth estimation
- camera
- dual-branch network
1. Introduction
2. Fusion of Radar and Camera Applications
3. Monocular Depth Estimation
4. Depth Completion
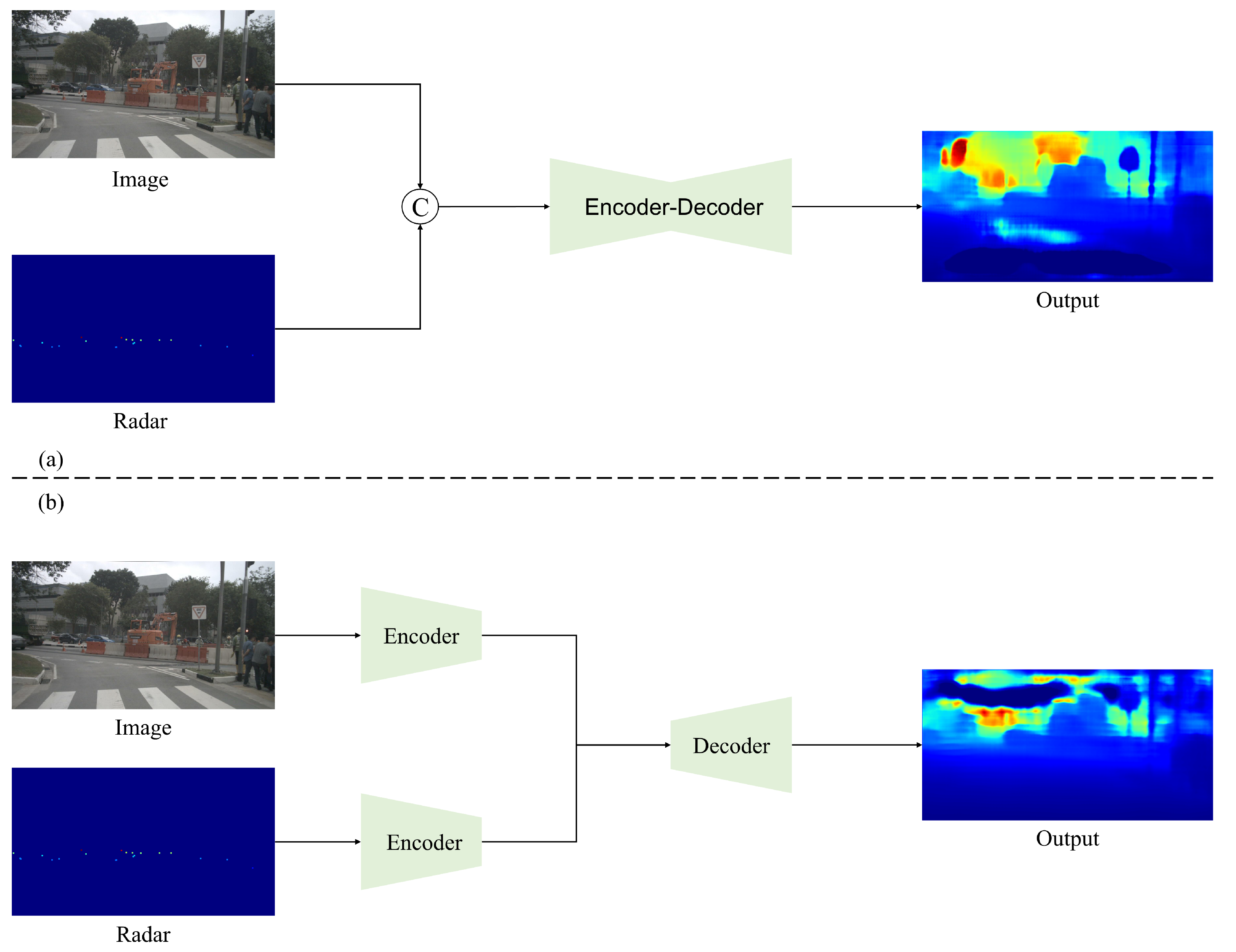
5. Depth Estimation with Semantic Information
This entry is adapted from the peer-reviewed paper 10.3390/s23177560
References
- Ju, Z.; Zhang, H.; Li, X.; Chen, X.; Han, J.; Yang, M. A survey on attack detection and resilience for connected and automated vehicles: From vehicle dynamics and control perspective. IEEE Trans. Intell. Veh. 2022, 7, 815–837.
- Peng, X.; Zhu, X.; Wang, T.; Ma, Y. SIDE: Center-based stereo 3D detector with structure-aware instance depth estimation. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 4–8 January 2022; pp. 119–128.
- Li, Y.; Ge, Z.; Yu, G.; Yang, J.; Wang, Z.; Shi, Y.; Sun, J.; Li, Z. Bevdepth: Acquisition of reliable depth for multi-view 3d object detection. In Proceedings of the AAAI Conference on Artificial Intelligence, Washington, DC, USA, 13–14 February 2023; Volume 37, pp. 1477–1485.
- Alaba, S.Y.; Ball, J.E. Deep Learning-Based Image 3-D Object Detection for Autonomous Driving. IEEE Sens. J. 2023, 23, 3378–3394.
- Wei, R.; Li, B.; Mo, H.; Zhong, F.; Long, Y.; Dou, Q.; Liu, Y.H.; Sun, D. Distilled Visual and Robot Kinematics Embeddings for Metric Depth Estimation in Monocular Scene Reconstruction. In Proceedings of the 2022 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Kyoto, Japan, 23–27 October 2022; pp. 8072–8077.
- Sayed, M.; Gibson, J.; Watson, J.; Prisacariu, V.; Firman, M.; Godard, C. SimpleRecon: 3D reconstruction without 3D convolutions. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2022; pp. 1–19.
- Xu, R.; Dong, W.; Sharma, A.; Kaess, M. Learned depth estimation of 3d imaging radar for indoor mapping. In Proceedings of the 2022 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Kyoto, Japan, 23–27 October 2022; pp. 13260–13267.
- Hong, F.T.; Zhang, L.; Shen, L.; Xu, D. Depth-aware generative adversarial network for talking head video generation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 3397–3406.
- Lee, J.H.; Heo, M.; Kim, K.R.; Kim, C.S. Single-image depth estimation based on fourier domain analysis. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 330–339.
- Ramamonjisoa, M.; Du, Y.; Lepetit, V. Predicting sharp and accurate occlusion boundaries in monocular depth estimation using displacement fields. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 14648–14657.
- Qi, X.; Liao, R.; Liu, Z.; Urtasun, R.; Jia, J. Geonet: Geometric neural network for joint depth and surface normal estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 283–291.
- Vandana, G.; Pardhasaradhi, B.; Srihari, P. Intruder detection and tracking using 77 ghz fmcw radar and camera data. In Proceedings of the 2022 IEEE International Conference on Electronics, Computing and Communication Technologies (CONECCT), Bangalore, India, 8–10 July 2022; pp. 1–6.
- Ram, S.S. Fusion of inverse synthetic aperture radar and camera images for automotive target tracking. IEEE J. Sel. Top. Signal Process. 2022, 17, 431–444.
- Hazra, S.; Feng, H.; Kiprit, G.N.; Stephan, M.; Servadei, L.; Wille, R.; Weigel, R.; Santra, A. Cross-modal learning of graph representations using radar point cloud for long-range gesture recognition. In Proceedings of the 2022 IEEE 12th Sensor Array and Multichannel Signal Processing Workshop (SAM), Trondheim, Norway, 20–23 June 2022; pp. 350–354.
- Shokouhmand, A.; Eckstrom, S.; Gholami, B.; Tavassolian, N. Camera-augmented non-contact vital sign monitoring in real time. IEEE Sens. J. 2022, 22, 11965–11978.
- Sengupta, A.; Cao, S. mmpose-nlp: A natural language processing approach to precise skeletal pose estimation using mmwave radars. IEEE Trans. Neural Netw. Learn. Syst. 2022.
- Schroth, C.A.; Eckrich, C.; Kakouche, I.; Fabian, S.; von Stryk, O.; Zoubir, A.M.; Muma, M. Emergency Response Person Localization and Vital Sign Estimation Using a Semi-Autonomous Robot Mounted SFCW Radar. arXiv 2023, arXiv:2305.15795.
- Hussain, M.I.; Azam, S.; Rafique, M.A.; Sheri, A.M.; Jeon, M. Drivable region estimation for self-driving vehicles using radar. IEEE Trans. Veh. Technol. 2022, 71, 5971–5982.
- Wu, B.X.; Lin, J.J.; Kuo, H.K.; Chen, P.Y.; Guo, J.I. Radar and Camera Fusion for Vacant Parking Space Detection. In Proceedings of the 2022 IEEE 4th International Conference on Artificial Intelligence Circuits and Systems (AICAS), Incheon, Republic of Korea, 13–15 June 2022; pp. 242–245.
- Kubo, K.; Ito, T. Driver’s Sleepiness Estimation Using Millimeter Wave Radar and Camera. In Proceedings of the 2022 IEEE CPMT Symposium Japan (ICSJ), Kyoto, Japan, 9–11 November 2022; pp. 98–99.
- de Araujo, P.R.M.; Elhabiby, M.; Givigi, S.; Noureldin, A. A Novel Method for Land Vehicle Positioning: Invariant Kalman Filters and Deep-Learning-Based Radar Speed Estimation. IEEE Trans. Intell. Veh. 2023, 1–12.
- Liu, B.; Gould, S.; Koller, D. Single image depth estimation from predicted semantic labels. In Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010; pp. 1253–1260.
- Ladicky, L.; Shi, J.; Pollefeys, M. Pulling things out of perspective. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 89–96.
- Eigen, D.; Puhrsch, C.; Fergus, R. Depth map prediction from a single image using a multi-scale deep network. In Proceedings of the Advances in Neural Information Processing Systems 27 (NIPS 2014), Montreal, QC, USA, 8–13 December 2014.
- Li, B.; Shen, C.; Dai, Y.; Van Den Hengel, A.; He, M. Depth and surface normal estimation from monocular images using regression on deep features and hierarchical crfs. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1119–1127.
- Laina, I.; Rupprecht, C.; Belagiannis, V.; Tombari, F.; Navab, N. Deeper depth prediction with fully convolutional residual networks. In Proceedings of the 2016 Fourth International Conference on 3D Vision (3DV), Stanford, CA, USA, 25–28 October 2016; pp. 239–248.
- Hu, J.; Ozay, M.; Zhang, Y.; Okatani, T. Revisiting single image depth estimation: Toward higher resolution maps with accurate object boundaries. In Proceedings of the 2019 IEEE Winter Conference on Applications of Computer Vision (WACV), Waikoloa Village, HI, USA, 7–11 January 2019; pp. 1043–1051.
- Chen, Y.; Zhao, H.; Hu, Z.; Peng, J. Attention-based context aggregation network for monocular depth estimation. Int. J. Mach. Learn. Cybern. 2021, 12, 1583–1596.
- Xu, D.; Wang, W.; Tang, H.; Liu, H.; Sebe, N.; Ricci, E. Structured attention guided convolutional neural fields for monocular depth estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 3917–3925.
- Chen, T.; An, S.; Zhang, Y.; Ma, C.; Wang, H.; Guo, X.; Zheng, W. Improving monocular depth estimation by leveraging structural awareness and complementary datasets. In Proceedings of the Computer Vision—ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; pp. 90–108.
- Cao, Y.; Wu, Z.; Shen, C. Estimating depth from monocular images as classification using deep fully convolutional residual networks. IEEE Trans. Circuits Syst. Video Technol. 2017, 28, 3174–3182.
- Fu, H.; Gong, M.; Wang, C.; Batmanghelich, K.; Tao, D. Deep ordinal regression network for monocular depth estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 2002–2011.
- Uhrig, J.; Schneider, N.; Schneider, L.; Franke, U.; Brox, T.; Geiger, A. Sparsity invariant cnns. In Proceedings of the 2017 International Conference on 3D Vision (3DV), Qingdao, China, 10–12 October 2017; pp. 11–20.
- Jaritz, M.; De Charette, R.; Wirbel, E.; Perrotton, X.; Nashashibi, F. Sparse and dense data with cnns: Depth completion and semantic segmentation. In Proceedings of the 2018 International Conference on 3D Vision (3DV), Verona, Italy, 5–8 September 2018; pp. 52–60.
- Hu, M.; Wang, S.; Li, B.; Ning, S.; Fan, L.; Gong, X. Penet: Towards precise and efficient image guided depth completion. In Proceedings of the 2021 IEEE International Conference on Robotics and Automation (ICRA), Xi’an, China, 30 May–5 June 2021; pp. 13656–13662.
- Cheng, X.; Wang, P.; Yang, R. Learning depth with convolutional spatial propagation network. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 42, 2361–2379.
- Zhang, Z.; Cui, Z.; Xu, C.; Jie, Z.; Li, X.; Yang, J. Joint task-recursive learning for RGB-D scene understanding. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 42, 2608–2623.
- Zhu, S.; Brazil, G.; Liu, X. The edge of depth: Explicit constraints between segmentation and depth. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 13116–13125.