In recent years, the automotive industry is in an era of change, the rapid development of automated driving-related technologies, Google, Huawei, Baidu, Tesla and other companies are competing to participate in the research, and constantly promote the development of related technologies. Automatic driving technology is a comprehensive subject that crosses many disciplines, and its research content can be roughly divided into three sub-modules: perception, decision-making and control [
1]. Among them, the perception system, as the “eyes” of the automatic driving system, is responsible for collecting road information and processing it to provide the necessary information for subsequent decision-making, and its importance is self-evident. Depth estimation is aimed at estimating the depth information in the scene through image information, which can effectively facilitate the realization of 3D target detection [
2,
3,
4], scene reconstruction [
5,
6,
7] and other tasks [
8], and has extremely important application value for automatic driving.
Accurate depth estimation, which aims to predict the depth value of each pixel from the RGB image, can effectively guarantee the safety of autonomous vehicles. At present, as convolutional neural networks (CNN) have achieved great success in many other fields, it is also introduced into depth estimation tasks extensively, to predict the dense depth map corresponding to the input RGB image in an end-to-end manner, and it indeed shows its strong capability [
9,
10,
11]. Owing to the use of CNN, the existing algorithms have greatly improved the accuracy of depth estimation compared to conventional methods. It is still a common paradigm for addressing this problem today. Many different types of networks and loss functions are proposed successively in order to pursue better performance of depth estimation.
2. Fusion of Radar and Camera Applications
Radar technology is known for its high-precision obstacle detection capability, which can detect a wide range of targets such as vehicles, pedestrians, and buildings. Unlike cameras, radar operates using electromagnetic waves and is therefore unaffected by low-light conditions (e.g., sunset, nighttime, or inclement weather), enabling it to operate reliably in a wide range of environments, significantly improving the reliability of autonomous driving systems.
Fusing radar with sensors, such as cameras, not only provides richer information, but also enables the system to understand the surrounding environment more accurately. Radar–camera fusion has been widely used in many fields, such as security, earthquake relief and autonomous driving. In literature [
15,
16], the fusion of target velocity and azimuth information obtained by radar with image information not only ensures consistency of target tracking but also improves tracking accuracy. It is shown that the fusion of camera and radar is not only effective for target detection, but also plays a role in the fields of gesture recognition [
17], vital signs monitoring [
18], human bone detection [
19] and earthquake rescue [
20], among others.
Especially in the field of autonomous driving, the fusion of radar and camera is of great importance. For example, Hussain et al. [
21] designed a low-cost method for detecting drivable areas in long-distance areas of self-driving cars by fusing radar and camera. Similarly, Wu et al. [
22] solved the challenge of missing parking boundaries on maps or difficult parking spot detection by jointly using radar and cameras. In addition to sensing the external environment, Kubo et al. [
23] proposed a non-contact driver drowsiness detection method that estimates driver drowsiness with high accuracy and detail. De et al. [
24] estimated the vehicle’s position based on the fusion of radar and camera sensors, speed and direction information.
In summary, the fusion of radar and camera plays a key role in multidisciplinary applications, providing more accurate and comprehensive information by integrating the advantages of different sensors and promoting the development of automation technology in various fields.
3. Monocular Depth Estimation
Monocular depth estimation is quite a challenging subject, as 3D information is lost when images are fetched by a monocular camera. Traditional algorithms rely heavily on hand-crafted features, such as texture and geometry, combined with a probabilistic model [
25,
26]. Over the past few years, CNN has achieved a convincing effect on image processing, so it is introduced in depth estimation and gradually becomes the most popular method for this task.
In general, depth estimation is treated as a regression problem. Eigen et al. [
27] construct a multi-scale deep CNN to generate a dense depth map for the first time. Some methods attempt to combine CNN with conditional random field (CRF) to improve network performance [
28], but they also increase the complexity of the system. New architectures are proposed to better extract features. Laina et al. [
29] design a fully convolutional residual network (FCRN) for depth estimation, which is an encoder–decoder structure. In this structure, the FC layer and the last pooling layer are no longer used, instead of an efficient decoder structure consisting of a series of upper convolutional modules, which significantly reduces the number of parameters. Some inspired improvements like [
30] have been proposed since then. Some methods improve the model by introducing attention mechanisms [
31,
32]. Chen et al. [
33] used a novel spatial attention block to guide different feature layers to focus on different structural information, i.e., local details or global structures. On the other hand, many researchers treat depth estimation as a classification problem, which divides the depth value into discrete bins where each pixel falls into one of them, followed by some post-processing means to map to the continuous space and obtain the final continuous depth map. Typical methods include Cao et al. [
34], where CNN was used to determine the appropriate bin that pixels should fall into, and then a fully connected CRF was employed to generate continuous prediction maps from the derived classification result. Fu et al. [
35] discretized the depth values in log space and treated it as an ordinal regression problem.
4. Depth Completion
Depth completion uses RGB images to give sparse depth maps for densification. Two typical challenges are how to better handle sparse data and how to integrate two modalities of data in an efficient manner.
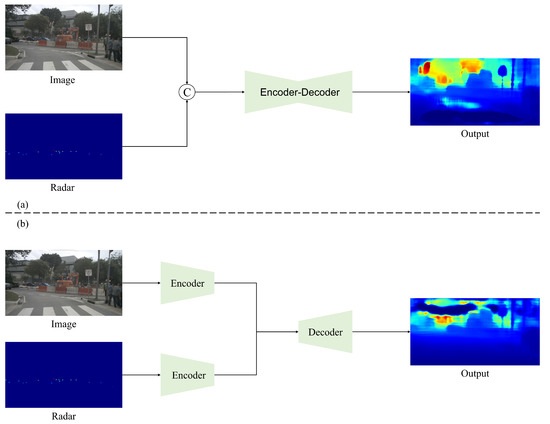
Many methods based on CNN architecture have been proposed so far. As in
Figure 1, early fusion models concatenate a sparse depth map directly with an RGB image and then send it to a network as a whole. Because the initial depth map is highly sparse, conventional convolutional operations have a poor effect on processing. Thus, Uhrig et al. [
36] proposed a sparse invariant convolution that uses a binary validity mask to adapt sparse input. For the late fusion strategy, a dual-branch encoder is universal. The features of RGB image and sparse depth map are usually extracted, fused at intermediate layers and transmitted to the decoder in the following steps [
37]; otherwise, depth maps are inferred by the respective features and the final map is obtained by merging two outputs [
38]. Some work devises a two-stage network, simply predicting a coarse depth map in the first stage before passing it to the fine-tuning stage. Cheng et al. [
39] proposed the convolutional spatial propagation network (CSPN), which refines the results by learning the affinity matrix and propagating sparse depth samples in local neighbors.
Figure 1. Different stages of fusion. (a) Early fusion; (b) late fusion.
5. Depth Estimation with Semantic Information
The depth information in an image describes the spatial relationship of the scene, while the semantic information represents the physical nature of the scene. The two share similar contextual information. Therefore, it is natural for researchers to consider introducing semantic information into the task of depth estimation as an assistant. Typically, depth estimation and semantic segmentation are combined for training, and the parameters of two tasks are shared by a unified structure to promote each other. Zhang et al. [
40] proposed a joint learning framework to recursively refine the results of two tasks. Zhu et al. [
41] used semantic segmentation to smooth the depth quality of object edge regions.