Banking and financial institutions heavily rely on data centers to facilitate financial services in conjunction with cloud-based scenarios. Within this service framework, the banking system is responsible for processing the entire collection of the bank’s financial documents in the OFD format before transmitting them to the service scenario side for subsequent business processing. Ensuring the security of financial data during this processing stage is of utmost importance. We present E-SAWM, an implicit watermarking service framework for OFD files based on semantic analysis in an edge cloud computing scenario. Scenario-side edge cloud computing, an extension of the banking institution-side cloud computing center, is positioned closer to the user scenarios. In financial data-sharing scenarios, deploying data protection edge services on the scenario side enables accelerated and secure data processing. By leveraging the close proximity of edge computing to the data and utilizing its real-time capabilities, the scenario side allows for the application of more advanced security algorithms to meet diverse and higher-level financial data protection requirements, ensuring enhanced data security processing.
2. Application of Edge Computing in the Domain of Financial Data Protection
Since 2015, edge cloud computing has emerged as a prominent technology, positioned on the Gartner technology maturity curve and experiencing rapid industrialization and growth. Edge computing represents a distributed computing paradigm that positions primary processing and data storage at the edge nodes of the network. According to the Edge Computing Industry Alliance [
4], it is an open platform integrating network, computing, storage, and application core capabilities at the edge of the network, in close proximity to the data source. This setup enables the provision of intelligent edge services to meet crucial requirements for industrial digitization, including agile connectivity, real-time services, data optimization, application intelligence, and security and privacy protection. International standards organization ETSI [
5] defines edge computing as the provisioning of IT service environments and computing capabilities at the network edge, aiming to reduce latency in network operations and service delivery, ultimately enhancing the user experience. Infrastructure for edge cloud computing encompasses various elements, such as distributed IDCs, carrier communication network edge infrastructure, and edge devices like edge-side client nodes, along with their corresponding network environments.
Serving as an extension of cloud computing, edge cloud computing provides localized computing capabilities and excels in small-scale, real-time intelligent analytics [
6]. These inherent characteristics make it highly suitable for smart applications, where it can effectively support small-scale smart analytics and deliver localized services. In terms of network resources, edge cloud computing assumes the responsibility for data in close proximity to the information source. By facilitating local storage and processing of data, it eliminates the need to upload all data to the cloud [
7]. Consequently, this technology significantly reduces the network burden and substantially improves the efficiency of network bandwidth utilization. In application scenarios that prioritize data security, especially in sectors such as finance, edge clouds offer enhanced compliance with stringent security requirements. By enabling the storage and processing of sensitive data locally, edge clouds effectively mitigate the heightened risks of data leakage associated with placing such critical information in uncontrollable cloud environments.
In the evolving landscape of the financial industry, there is a paradigm shift toward open banking, often referred to as banking 4.0. Departing from the traditional customer-centric approach, open banking places emphasis on user centricity and advocates for data sharing facilitated by technical channels such as APIs and SDKs. Its primary goal is to foster deeper collaboration and forge stronger business connections between banks and third-party institutions, which enables the seamless integration of financial services into customers’ daily lives and production scenarios. The overarching objective is to optimize the allocation of financial resources, enhance service efficiency, and cultivate mutually beneficial partnerships among multiple stakeholders. An illustrative example of this paradigm shift is evident in bank card electronic payment systems, where the deployment of secure and encrypted POS machines at the edge enables convenient electronic payments [
8].
Extensive research has been conducted to address the security challenges in edge cloud environments. M. Ati et al. [
9] proposed an enhanced cloud security solution to enhance data protection against attacks. Similarly, L. Chen et al. [
10] proposed a heterogeneous endpoint access authentication mechanism for a three-tier system (“cloud-edge-end”) in edge computing scenarios, which aimed to support a large number of endpoint authentication requests while ensuring the privacy of endpoint devices. Building upon this, Z. Song et al. [
11] introduced a novel attribute-based proxy re-encryption approach (COAB-PRE) that enables data privacy, controlled delegation, bilateral access control, and distributed access control capabilities for data sharing in cloud edge computing. On the other hand, G. Cui et al. [
6] developed a data integrity checking and corruption location scheme known as ICL-EDI, which focuses on efficient data integrity checking and corruption location specifically for edge data. Additionally, Z. Wang et al. [
12] introduced a flexible time-ordered threshold ring signature scheme based on blockchain technology to secure collected data in edge computing scenarios, ensuring a secure and tamper-resistant environment. However, to the best of our knowledge, the existing research has not extensively addressed the topic of leakage tracking techniques for sensitive data in edge computing scenarios.
3. Edge Cloud-Based Financial Regulatory Outpost Technology
The open sharing of data brings inherent risks to personal privacy data leakage. In the financial industry, it is crucial to ensure compliance with regulations such as the Data Security Law and the Personal Information Protection Law while conducting business operations. To tackle this challenge, we propose the deployment of regulatory outpost at the edge of the data application side, with a specific focus on third-party institutions, which aims to enhance the security and compliance of open banking data within the application side of the ecosystem.
Regulatory outpost is a standalone software system designed to monitor data operations on the application side, aiming to prevent data violations and mitigate the risk of data leakage. The system offers comprehensive monitoring capabilities throughout different stages of the application’s data operations, including data storage, reading, and sharing, as well as intermediate processing tasks, such as sensitive data identification, desensitization, and watermarking. In addition, the regulatory outpost maintains meticulous records of all user data operation logs, facilitating log audits, leak detection, and generation of data flow maps and enabling situational awareness regarding data security.
In light of the above considerations, regulatory outpost operates at the edge side of data processing and plays a significant role in the data processing process. To ensure optimal efficiency and cost-effectiveness, the deployment of regulatory outposts should satisfy the following requirements in the context of data operations:
- 1.
-
Elastic and scalable resource allocation: Data processing applications necessitate computational resources, but the overall data volume tends to vary. For instance, during certain periods, the data volume processed by the application side may increase, requiring more CPU performance, memory, hard disk space, and network throughput capacity. Conversely, when the processing data volume decreases, these hardware resources remain underutilized, leading to wastage. Therefore, it is essential for regulatory outposts to support the elastic scaling of resources to minimize input costs associated with data processing operations;
- 2.
-
Low bandwidth consumption cost and data processing latency: The application’s data traffic is directed through the regulatory outpost, which can lead to increased bandwidth consumption costs and higher network latency, especially if the outpost is deployed in a remote location like another city. The current backbone network, which is responsible for interconnecting cities, incurs higher egress bandwidth prices, and its latency is relatively higher compared to the metropolitan area network and local area network. To minimize the impact on the application experience, it is essential to maintain low bandwidth utilization costs and minimize data processing latency;
- 3.
-
Data compliance: Due to concerns about open banking data leakage, the application side tends to prefer localized storage of open banking data to the greatest extent possible, which enables the application side to more conveniently monitor the adequacy of security devices and the effectiveness of security management protocols.
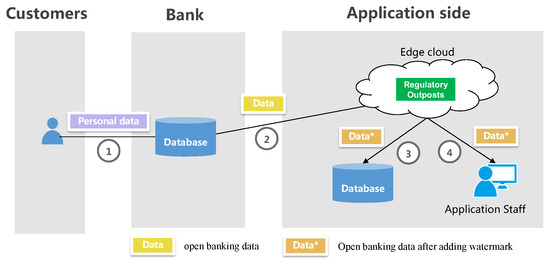
Edge clouds provide significant advantages due to their proximity to data endpoints, including cost savings in network bandwidth, low latency in data processing, and improved data security. Moreover, they offer the scalability, elasticity, and resource-sharing benefits commonly associated with centralized cloud computing. Hence, deploying regulatory outposts in the edge cloud is a logical decision. Figure 1 showcases an example deployment scenario.
Figure 1. Deployment of Regulatory Outposts on Edge Clouds.
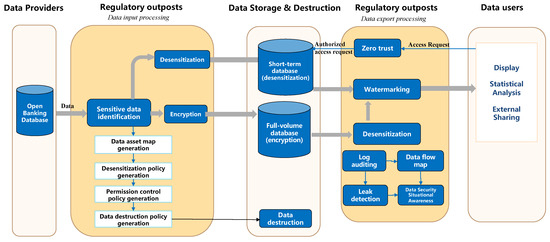
The regulatory outpost consists of two components: “regulatory outpost—data input processing” and “regulatory outpost—data export processing”. The specific data processing work flow is illustrated in Figure 2.
Figure 2. Data processing work flow in regulatory outposts within edge cloud scenarios. Components of the regulatory outpost data process: (1) Data provider: a bank or transit platform responsible for data processing and forwarding. (2) Data storage and destruction: a database provided by the application, subject to audit by regulatory outposts. (3) Data user: terminal equipment or other business systems accessing the database for tasks such as data display, statistical analysis, and external sharing.
3.1. Regulatory Outpost—Data Input Processing
This component automatically identifies sensitive data on among inflowing data and generates a data asset map, data desensitization policy, a permission control policy for the zero trust module, and a data destruction policy based on the identified sensitive data. To cater to the frequent viewing of short-term data such as logs by application-side users, a two-tier data storage approach is employed. The desensitized data are saved in a short-term database, while a full-volume database retains all the data. In cases in which the data contain highly confidential information, they are encrypted prior to being written into the full-volume database.
3.2. Regulatory Outpost—Data Export Processing
In the data access scenario, the zero trust module of the regulatory outpost plays a critical role in verifying access privileges for data users. When accessing data from a short-term database, open banking data are transmitted to the data user after incorporating watermark information, such as the data user’s identity, data release date, and usage details. However, if the data are retrieved from the full-volume database, they must undergo desensitization based on the desensitization policy before the inclusion of watermark information and subsequent transmission to the data user. To ensure accountability, the log auditing module captures and logs all data operations for auditing purposes. The audit results are then utilized to generate data flow maps, detect instances of data leakage, and provide valuable insights into data security situational awareness. These insights facilitate the identification of existing data security risks and offer suggestions for improvement measures.
4. Document Watermarking Techniques
The file is a prominent data format used for data sharing. In the process of sharing files from the cloud (bank side) to the edge cloud (application side), it becomes crucial to monitor potential data leakage at each step. This concern is particularly relevant for the edge side, where the development of a watermarking algorithm that possesses high levels of transparency, concealment, robustness, and capacity has become a subject of significant academic interest.
Electronic document formats can be categorized into two types: streaming documents and versioned documents. Streaming documents, such as Word and TXT files, support editing, and their display may vary depending on the operating system and reader version. On the other hand, versioned documents have a fixed layout that remains consistent across different operating systems and readers.
OFD is an innovative electronic document format that conforms to the “GB/T 33190-2016 Electronic Document Storage and Exchange Format—Layout Documents” standard [
13]. OFD was specifically developed to fulfill the demands of effectively managing and controlling layout documents while ensuring their long-term preservation. By offering a dependable and standardized format, OFD facilitates the maintenance of consistent layouts and supports the preservation of electronic documents. Our work primarily concentrates on the watermarking technology for OFD files, which serves as the prevalent file format utilized in the financial sector.
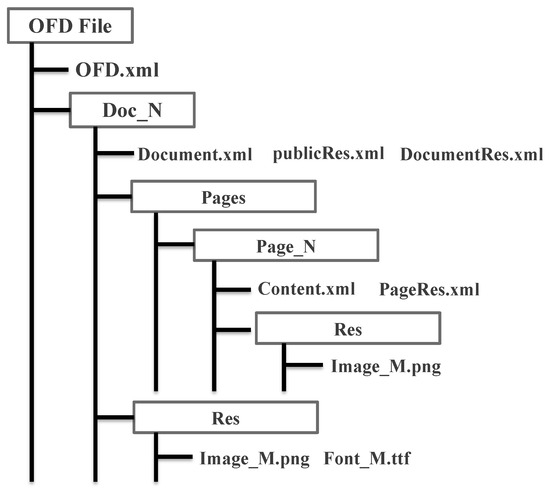
The OFD file format adopts XML (Extensible Markup Language) to define document layout, employing a “container + document” structure to store and describe data. The content of a document is represented by multiple files contained within a zip package, as illustrated in Figure 3. A detailed analysis and explanation of the internal structure components of an OFD file are provided in Table 1.
Figure 3. Structure of OFD.
Table 1. Internal Structural file description of OFD.
In the realm of layout document formats, OFD and PDF are widely utilized. Watermarking techniques for layout documents can be categorized into several methods:
- 1.
-
Syntax- or semantics-based approaches: leveraging natural language processing techniques to replace equivalent information, perform morphological conversions, and adjust statement structures to facilitate watermark embedding [
6,
14];
- 2.
-
Format-based approaches encompass techniques such as line shift coding, word shift coding, space coding, modification of character colors, and adjustment of glyph structures [
15];
- 3.
-
Document structure-based approaches leverage PDF structures like PageObject, imageObject, and cross-reference tables, enabling the embedding of watermarks while preserving the original explicit location [
16].
The field of PDF watermarking has reached a relatively mature stage of development. However, watermarking algorithms that rely on syntax and format modifications may alter the original text content, which conflicts with the requirement of preserving the originality of digital products. Consequently, watermarking algorithms based on the document structure are commonly employed to add watermarks to PDF files. ZHONG Zheng-yan et al. [
17] presented a novel method for watermarking PDF documents, which involves embedding watermarks based on the redundant identifier found at the end of the PDF cross-reference table. By leveraging this technique, the original text content and display of the PDF remain unaltered, thereby achieving complete transparency when viewed using PDF readers. Kijun Han et al. [
18] added watermarks based on the PageObject structure within the PDF structure, which offers resistance against attacks such as adding or deleting text to manipulate the page content. By utilizing these document structure-based watermarking techniques, PDF files can be effectively watermarked without compromising the original content and maintaining transparency and integrity in PDF readers.
The field of watermarking in the context of OFD has received limited attention in both academia and industry. In academia, there is a noticeable dearth of research studies and published papers specifically dedicated to OFD watermarking. On the industry front, existing OFD watermarking techniques primarily rely on explicit watermarks, which are implemented based on the following principles:
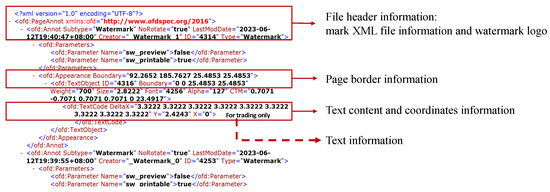
The watermark text content, along with relevant information such as position, transparency, size, and color, is defined within the annotation structure file named Annotation.xml. This file is an integral part of the internal structure of the OFD file and is typically located in the Annots/Page_n folder. The details of watermark addition are depicted in Figure 4 and Figure 5.
Figure 4. OFD annotation file contents for watermarking.
Figure 5. Illustration of OFD page with added explicit watermark.
Although the structure of the watermark may seem clear and straightforward, it is susceptible to various attacks. Adversaries have the ability to manipulate the Annotation.xml folder, leading to vulnerabilities in the watermark’s integrity, decryption, and identification, with potential for malicious removal. Consequently, the task of tracing compromised data becomes significantly challenging.