Your browser does not fully support modern features. Please upgrade for a smoother experience.
Please note this is an old version of this entry, which may differ significantly from the current revision.
Subjects:
Computer Science, Theory & Methods
In network attacks based on malicious documents, the PDF document type accounts for a large proportion. Traditional PDF document detection technology usually builds a rule or feature library for specific vulnerabilities and therefore is only fit for single detection targets and lacks anti-detection ability.
- PDF document detection
- multiple features
1. Introduction
In recent years, the number of network attacks through malicious documents has increased dramatically. Such attacks are often accompanied by serious harm, such as phishing, organization monitoring, and denial of service attacks. In network attacks based on malicious documents, the PDF document type accounts for a large proportion. According to the statistics of F-Secure Security, in 2020, malicious document attacks related to Adobe Reader accounted for 60% of total document attacks. Attackers can use embedded scripts, remote links and other means to carry out attacks through the plentiful functions of Adobe related products. The detection of such concealed attacks is difficult [1].
Among PDF-related attacks, constructing document vulnerabilities by exploiting defects of Adobe software is extremely harmful [2,3,4,5]. Through exploiting the vulnerabilities of document readers or parsers, such attacks can cause various types of harm, including downloading malicious programs remotely, implementing backdoor implantation, and executing malicious code directly. In 2020, Adobe released a security update bulletin to disclose the vulnerability CVE-2020-24432, the principle of which is that Adobe Acrobat Reader lacks strictness while censoring input validation. Attackers can execute arbitrary code in the context of the current user and cause serious damage.
Since 2018, Adobe Acrobat Reader has released more than 30 security update bulletins and disclosed more than 200 CVE vulnerabilities. Among them, there are more than 50 document vulnerabilities which are destructive and widely disseminated. Table 1 presents the typical document vulnerability information disclosed by Adobe in recent years. It can be seen that document vulnerabilities are usually accompanied by harmful attacks, such as arbitrary code execution.
Table 1. Adobe typical document vulnerability information.
| Number | Vulnerability | Dangerous Effects |
|---|---|---|
| CVE-2022-27787 | Buffer overflow | Arbitrary code execution |
| CVE-2021-44709 | Buffer overflow | Arbitrary code execution |
| CVE-2021-28564 | Buffer overflow | Arbitrary code execution |
| CVE-2021-21017 | Buffer overflow | Arbitrary code execution |
| CVE-2021-21045 | Improper access control | Privilege escalation attack |
| CVE-2020-9704 | Buffer overflow | Arbitrary code execution |
| CVE-2019-8249 | Logical flaw | Arbitrary code execution |
| CVE-2019-8066 | Buffer overflow | Arbitrary code execution |
| CVE-2018-19716 | Buffer overflow | Arbitrary code execution |
In recent years, researchers have presented various methods for detecting malicious documents. The detection types are mainly divided into two categories: static and dynamic detection methods. The static method usually determines the document’s nature through analyzing the content, basic attributes, basic structure, metadata, and other document features without running them [6,7,8,9], whereas the dynamic method usually achieves detection through analyzing the system calls, operation behavior, and other features in a virtual environment’s running process [10,11,12]. Traditional static and dynamic detection methods have advantages and limitations. Static detection does not need to execute actual samples and is thus relatively secure with high detection efficiency, fast speed, and low cost, but it ignores the malicious code extraction from documents [13]. Dynamic detection does not need to learn samples and can intuitively find the purpose of attack via running behavior, leading to a strong robustness. However, it faces such challenges as low efficiency, low speed, enormous cost, and sometimes threats from the anti-virtual machine and anti-sandbox technology [14,15,16].
2. PDF Background
The newest format of PDF was published as ISO 32000-1:2020 [17]. According to the standard, the basic structure of PDF documents is mainly divided into four parts: objects, physical structure, logical structure, and content stream [18,19], as shown in Figure 1.
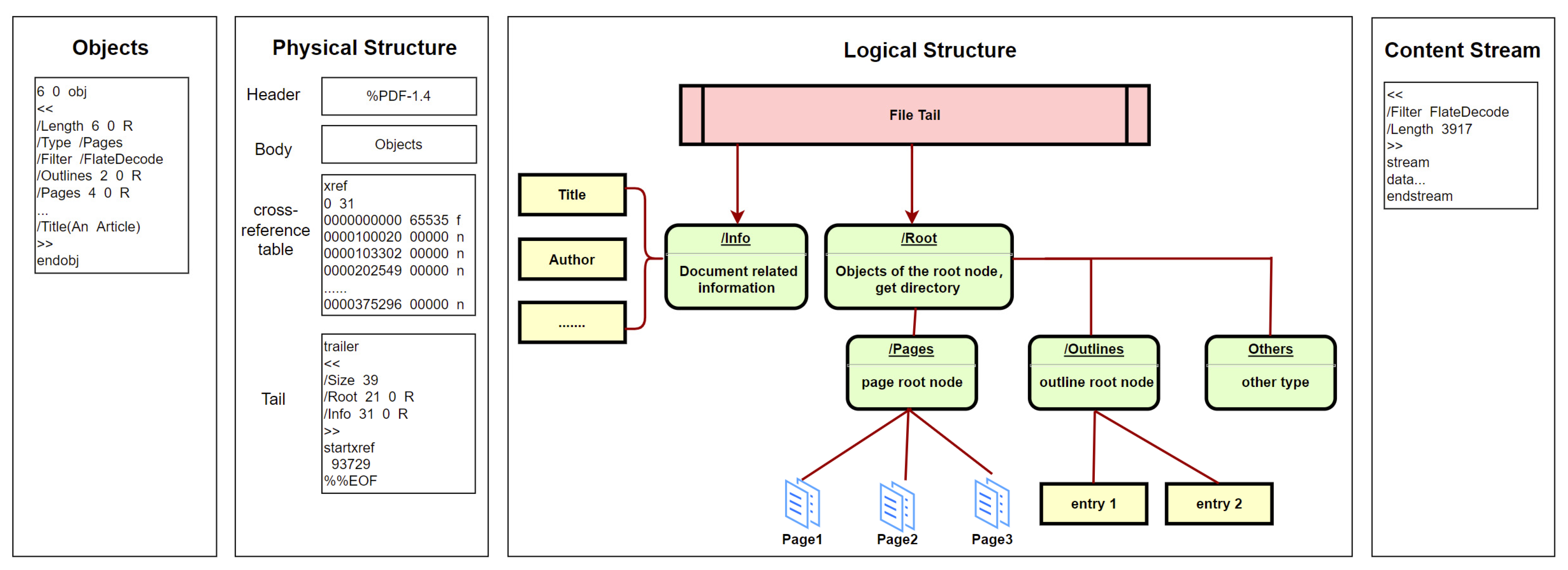
Figure 1. The basic structure of PDFs.
The details of each part are as follows. (a) Objects. As the main part of PDF documents, objects carry various content, such as text information, fonts, embedded pictures, embedded videos, hyperlinks, and bookmarks. But the basic structure of different objects is similar regardless of the content classification. As shown in Figure 1, the first line in objects is the identifier, which consists of two numbers. The first is the serial number of objects. The second is the generation number of objects and is used to indicate whether the object has been modified. (b) Physical structure. This is mainly composed of four parts: file header, file body, cross-reference table, and file tail. The file header with a simple and fixed format is used to indicate the PDF version. The file body composed of document objects is the core part of the PDF. The cross-reference table is used to index document objects. The file tail is mainly used to save the summary, location, and other related information of the cross-reference table. (c) Logical structure. In the actual parsing process, PDFs are not parsed through physical structure but through logical structure. Parsing begins with the root node indicated by the file tail. The node indicates the directory, which contains pages, outlines, and other types of information. Each type of information is also organized in a tree structure. (d) Content stream. This is a common form of objects in PDFs and plays a key role in storing data. Stream objects are composed of three parts. The first part is a dictionary, which mainly stores the length and encoding method. The second part is the keyword, which is unified in different stream objects. It usually starts with “stream” and ends with “endstream”. The third part is the data between keywords.
3. Static Detection Method
Currently, the common static detection methods are mainly divided into three categories. The first category tends to detect the content features of files, mainly to extract suspicious JavaScript code fragments, shellcode data fragments, and metadata content in PDF documents. According to Tzermias et al. [11], more than 90% of malicious PDF document attacks need to be implemented with JavaScript and other codes. The detection model proposed by Laskov et al. [20] extracts JavaScript and uses lexical tagging to build an OCSVM classification. However, such methods are insufficient for PDF documents that do not rely on JavaScript code. Some document vulnerabilities build attack chains with the help of the document format. The second category tends to detect the structural features of documents. It achieves detection mainly through extracting document structure and combining features such as metadata. Šrndić et al. [21] extracted vast features of basic structure for PDF but also had limitations in extracting malicious features. Cohen et al. [7] adopted the SFEM method to extract features from the document structure. Chandran et al. [22] scanned the structure of the PDFs through PeePDF and used the GRU model to employ classification. Srndic et al. [23] processed metadata in a similar way to structural paths and then substituted the data into classification models to achieve detection. But such methods have limited abstraction of features and are not comprehensive enough to detect content features. The static methods above are not comprehensive in feature extraction, resulting in insufficient detection for various attack methods. The third category tends to build the feature library and use multiple features. Wen Weiping et al. [24] designed a feature library for document vulnerabilities. The malicious document can be identified when it matches the relevant features of the feature library. However, such methods only apply to malicious PDF documents with disclosed vulnerabilities and have no detection effect on 0-day vulnerabilities. Falah et al. [25] used feature engineering to evaluate multiple features and detect malicious PDFs, but they ignored malicious features in JavaScript code, and the feature evaluation method deserves improvement.
4. Dynamic Detection Method
Dynamic detection methods mainly focus on JavaScript code and shellcode data fragments embedded in the document. The MDScan method [14] mainly executes the extracted JavaScript code. It extracts the relevant operation performance of memory as a sequence and performs subsequent detection. But these similar matching methods have limitation in detecting new type of attacks. Iwamoto et al. [26] used the simulation method to execute the document shellcode. It is mainly based on the entropy of the byte sequence, which can solve the problem of difficult vulnerability triggering to some extent. However, this detection is insufficient for some malicious codes that can be only triggered in a specific situation. Xu et al. [27] proposed opening the PDF document with the same reader in the heterogeneous operating system and identified malicious documents through the similarity performance of system calls and process tracking. However, such methods have an excessive overhead and low detection efficiency. Liu et al. [28] executed JavaScript code in PDF documents through their own built-in execution environment and monitored common malicious behaviors. But such methods can only detect traditional and common attack methods. It is insufficient to detect the document using new anti-detection method. In summary, the dynamic detection method is expensive and consumes large amounts of resources and memory space. It is not suitable for situations with large numbers of samples, short time requirements, and low resource requirements [29].
This entry is adapted from the peer-reviewed paper 10.3390/e25071099
This entry is offline, you can click here to edit this entry!