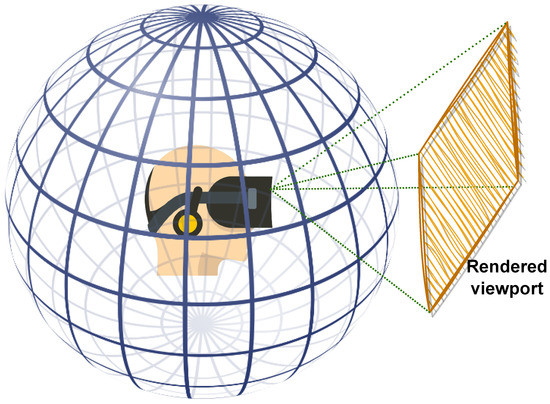
360-degree images provide users with the ability to look in any direction of the 360
∘ environment, creating an immersive experience when viewed through head-mounted displays (HMDs) or other specialized devices. As the user gazes in a particular direction, the HMD display renders a portion of the content corresponding to the current field of view (FoV) from the spherical representation, which is effectively a 2D rendered window as illustrated in
Figure 1. The next viewport depends on the user’s head movement along the pitch, yaw, and roll axes. This exploration behavior makes processing 360-degree images challenging, particularly for quality assessment, as HVS perception requires appropriate considerations. Additionally, 360-degree images require a sphere-to-plane projection for processing, storage, or transmission, which introduces geometric distortions that must be taken into account when designing IQA methodologies or dealing with 360-degree images, in general [
2].
Convolutional neural networks (CNNs) have been successfully used in various fields, including quality assessment, due to their good performance. For 360-degree quality assessment, CNN-based models often adopt the multichannel paradigm, in which multiple CNNs are stacked together to calculate the quality score from selected viewports. However, this architecture can be computationally complex [
3] and may not fully consider the non-uniform contribution of each viewport to the overall quality. To address these issues, end-to-end multichannel models that learn the relationship among inputs and the importance of each viewport have been proposed. These models tend to better agree with the visual exploration and quality rating by observers. Moreover, viewport sampling, combined with an appropriate training strategy, may further improve the robustness of the model. A previous study designed a multichannel CNN model for 360-degree images that considers various properties of user behavior and the HVS [
4]. However, the model has significant computational complexity.
2. Traditional Models
As 360-degree content has become more popular, a few 360-degree IQA models have been proposed based on the rich literature on 2D-IQA. In particular, Yu et al. [
6] introduced the spherical peak signal-to-noise ratio (S-PSNR) which computes the PSNR on a spherical surface rather than in 2D. The weighted spherical PSNR (WS-PSNR) [
7] uses the scaling factor of the projection from a 2D plane to the sphere as a weighting factor for PSNR estimation. Similarly, Chen et al. [
8] extended the structural similarity index (SSIM) [
9] by computing the luminance, contrast, and structural similarities at each pixel in the spherical domain (S-SSIM). The latter uses the same weights as the WS-PSNR. Zakharchenko et al. proposed to compute PSNR on the Craster parabolic projection (CPP) [
10] by re-mapping pixels of both pristine and distorted images from the spherical domain to CPP. In contrast, some works, such as those in [
11,
12,
13], incorporate saliency-based weight allocation in the computation of PSNR. Following the trend of adapting 2D models to the 360-IQA domain, Croci et al. [
14] proposed extending traditional 2D-IQA metrics such as PSNR and SSIM to 360-degree patches obtained from the spherical Voronoi diagram of the content. The overall quality score is computed by averaging the patch scores. This framework is expanded in [
15] by incorporating visual attention as prior to sample Voronoi patches. In a similar vein, the approach proposed by Sui et al. [
16] also employs 2D-IQA models for 360-IQA. Specifically, the approach maps 360-degree images to moving camera videos by extracting sequences of viewports along visual scan-paths, which represent possible visual trajectories and generate the set of viewports. The resulting videos are evaluated using several 2D-IQA models, including PSNR and SSIM, with temporal pooling across the set of viewports.
Most traditional 360-degree IQA methods leverage the rich literature on 2D IQA and focus on measuring signal fidelity, which may not adequately capture the perceived visual quality due to the unique characteristics of omnidirectional/virtual reality perception. Furthermore, these models typically obtain the fidelity degree locally using pixel-wise differences, which may not fully account for global artifacts. Additionally, the computation is performed on the projected content, which can introduce various geometric distortions that further affect the accuracy of the IQA scores.
3. Learning-Based Models
Deep-learning-based solutions, particularly convolutional neural networks (CNNs), have shown impressive performances in various image processing tasks, including IQA. In the context of 360-degree IQA, CNN-based methods have emerged, and they have shown promising results with the development of efficient training strategies and adaptive architectures. The multichannel paradigm is the primary architecture adopted for 360-degree IQA, and viewport-based training is one of the most commonly used strategies. A multichannel model consists of several CNNs running in parallel, with each CNN processing a different viewport, and the quality scores are obtained by concatenating the outputs of these CNNs. The end-to-end model is trained to predict a single quality score based on several inputs. However, a major drawback of this approach is the number of channels or CNNs, which can significantly increase the computational complexity and may affect the robustness of the model [
3]. To mitigate this drawback, some techniques such as weight sharing across channels can be helpful. In contrast to multichannel models, a few attempts have been made to design patch-based CNNs for 360-degree image quality assessment, which can reduce the computational complexity. In the following section, we provide a literature review of works that have used different CNN architectures for 360-degree IQA.
3.1. Patch-Based Models
Patch-based solutions for 360-degree IQA are mainly used to address the limited availability of training data. By sampling a large number of patches from 360-degree images, the training data can be artificially augmented. Patch-based models consider each input as a separate and individual content item. This makes the training data rich and somehow sufficient for training CNN models. Based on this idea, Truong et al. [
17] used equirectangular projection (ERP) content to evaluate the quality of 360-degree images, where patches of
64×64are sampled according to a latitude-based strategy. During validation, an equator-biased average pooling of patches’ scores is applied to estimate the overall quality. Miaomiao et al. [
18] integrated saliency prediction in the design of a CNN model combining the spatial saliency network (SP-NET) [
19] for saliency feature extraction, and ResNet-50 [
20] for visual feature extraction. The model is trained using cube-map projection (CMP) faces as patches, and is then fine-tuned directly on ERP images. Yang et al. [
21] proposed to use ResNet-34 [
20] as a backbone where input patches are enhanced using a wavelet-based enhancement CNN and used as references to compute error maps. All these models used projected content to sample the input patches, not taking into account the geometric distortions generated by such a projection nor the relevance of the patch content. Moreover, labeling each patch individually using mean opinion scores (MOSs) regardless of its importance may not accurately reflect the overall quality of the 360-degree image. This is because the local (patch) perceptual quality may not always be consistent with the global (360-degree image) quality due to the large variability of image content over the sphere and the complex interactions between the content and the distortions [
22].
3.2. Multichannel Models
In the literature, several multichannel models have been proposed for 360-degree IQA. For instance, Sun et al. [
23] developed the MC360IQA model, which uses six pre-trained ResNet-34 [
20] models. Each channel corresponds to one of the six faces of the CMP, and a hyper-architecture is employed, where the earliest activations are combined with the latest ones. The outputs are concatenated and regressed to a final quality score. Zhou et al. [
24] followed a similar approach by using CMP faces as inputs and proposed to use the Inception-V3 [
25] model with shared weights to reduce complexity. However, the authors chose not to update the different weights of the pre-trained model, thereby losing the benefits of weight sharing. Kim et al. [
26] proposed a model that uses 32 ResNet-50 to encode visual features of extracted
256×256patches from the ERP images. The 32 channels are augmented with a multi-layer perceptron (MLP) to incorporate patches’ locations using their spherical positions. However, the resulting model is highly complex. It should be noted that predicting quality based on ERP content is not ideal due to severe geometric distortions. Xu et al. [
27] proposed the VGCN model, which exploits the dependencies among viewports by incorporating a graph neural network (GNN) [
28]. This approach allows for modeling the relationships between viewports in a more effective way. The VGCN model uses twenty ResNet-18 [
20] as channels for the sampled viewports, along with a subnetwork based on the deep bi-linear CNN (DB-CNN) [
22] that takes ERP images as input. This makes the model significantly complex. Building on the VGCN architecture, Fu et al. [
29] proposed a similar solution that models interactions among viewports using a hyper-GNN [
30].
As previously mentioned, the use of a higher number of channels in a multichannel model can significantly increase its complexity. Additionally, the learned features from each channel are concatenated automatically, requiring perceptual guiding to consider the importance of each input with respect to the MOS. Relying solely on the CNN to fuse the different representations may not be sufficient. Therefore, a more effective approach is to assist the model in automatically weighting each input based on its importance and significance with respect to various HVS characteristics. In the following section, we describe a multichannel 360-IQA model designed to accurately estimate the contribution of each input by considering different HVS characteristics.