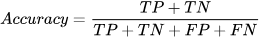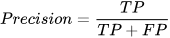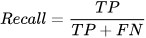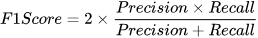Cyber-physical systems (CPSs) integrate sensing, processing, communication, actuation, and control through networks and physical devices [
1,
2]. CPSs are subject to diverse attacks that can affect different aspects of human life [
3], particularly public infrastructures such as Smart Grids (SG), water treatment, and pipeline gas. CPSs are typically organized in three architectural layers: perception, transmission, and application [
1]. The perception layer comprises sensor and actuator devices at the network’s edge, exchanging data with the application layer through the intermediary transmission layer. Due to their resource constraints, perception layer devices are the most vulnerable to attacks [
4,
5].
2. Offline and Online ML
Offline and online ML have different main characteristics, which offer advantages depending on the application. In offline ML, the model is trained and tested on a fixed dataset, which must be available ahead of time. Additionally, offline ML typically requires longer training time as it involves processing the entire dataset ahead of time, which can be resource-intensive, often requiring substantial computational resources to train and test the model on large fixed datasets.
One of the disadvantages of offline ML is the lack of ability to detect Concept Drift, a statistical distribution change in the variables or input attributes over time. In other words, the relationship between the attributes and the classes may evolve, making the model trained on old data less accurate or even invalid for making predictions on new data.
On the other hand, online ML creates the model incrementally, updating the model as new data arrive. It operates with immediate responses able to adapt to evolving patterns or changes in the process [
15] with the use of change detectors. The model is designed to provide predictions or actions based on the incoming data, facilitating quick decision-making. So, the online ML technique is used to continuously monitor sensor data, identify anomalies, predict failures, and make real-time adjustments to optimize the CPS process. Additionally, it can be more resource-efficient as it learns and trains from streaming data indefinitely without compromising memory or process [
16].
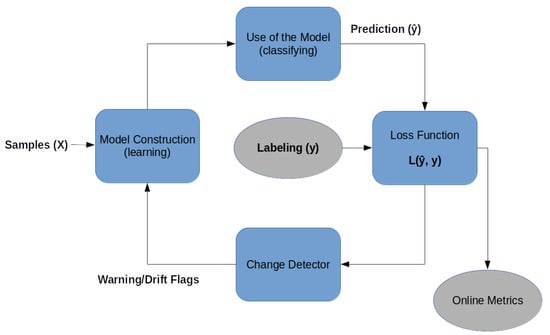
An online ML architecture is given in
Figure 1: the classification process, which is divided into two stages [
15], the loss function, and change detector with the warning or drift flag:
Figure 1. Outline of the online ML with prediction loss function and change detector.
-
Online model construction (learning): each new sample is used to build the model to determine the class with the attributes and values. This model can be represented by classification rules, decision trees, or mathematical formulas. To control the amount of memory used by the model, a forgetting mechanism is used, like a sliding window or fading factor, that discards samples while keeping an aggregate summary/value of these older samples;
-
Use of the model (classifying): it is the classification or estimation of unknown samples using the constructed model. In this step, the model’s performance metrics are also calculated, comparing the known label of the sample y with the classified result of the model (i.e., the predicted label (𝑦^)), for a supervised classification process.
-
Loss function: for each input sample attributes (X), the prediction loss can be estimated as 𝐿(𝑦̂,𝑦). The performance metrics of this method are obtained from the cumulative sum of sequential loss over time, that is, the loss function between forecasts and observed values.
-
Change detector: detects concept drift by monitoring the loss estimation. When change is detected based on a predefined threshold, the warning signal or drift signal is used to retrain the model [
17]. Interestingly, as will be shown below, no concept drift was detected in any of the datasets used in this article.
The evaluation of classical learning methods that use finite sets of data, such as cross-validation and training/test techniques, are not appropriate for data streams due to the unrestricted dataset size and the non-stationary independent samples. Two alternatives are more usual for data stream [
18]:
-
Holdout: applies tests and training samples to the classification model at regular time intervals (configurable by the user);
-
Prequential: all samples are tested (prediction) and then used for training (learning).
The most suitable methodology for online ML models dealing with concept drift is the prequential method [
18,
19]. It combines the predictive and sequential aspects with memory window mechanisms, which maintain an aggregated summary of recent samples while discarding older ones in order to process new samples. This approach is based on the notion that statistical inference aims to make sequential probability predictions for future observations, rather than conveying information about past observations.
In online supervised ML the data-predicting process can be conducted in real time through the forecast model (Figure 1) to identify anomalies or failures in an industrial process. The labeling process is provided from CPS sensors after an additional delay. For example, consider a smart grid system where sensors continuously monitor power generation and distribution. In the absence of labeled data in real time, data prediction is crucial to detect anomalies or failures in the grid, thereby alerting operators to potential issues. By employing the labeling from the sensors after a delay, the system can analyze the loss and make corrections to the prediction model. The datasets presented in this article already include their respective classification labels, thereby enabling the use of supervised approaches for both online and offline algorithms.
The following online data stream classifiers will be used in this article because they were the most used in the studied references [
20,
21]:
-
Naive Bayes (NB) is a probabilistic classifier, also called simple Bayes classifier or independent Bayes classifier, capable of predicting and diagnosing problems through noise-robust probability assumptions;
-
Hoeffding Tree (HT) combines the data into a tree while the model is built (learning) incrementally. Classification can occur at any time;
-
Hoeffding Adaptive Tree (HAT) adds two elements to the HT algorithm: change detector and loss estimator, yielding a new method capable of dealing with concept change. The main advantage of this method is that it does not need to know the speed of change in the data stream.
For the offline ML, the researchers selected five popular classifiers from the literature [
16]:
-
Naive Bayes (NB) is available for both online and offline ML versions, making it possible to compare them;
-
Random Tree (RaT) builds a tree consisting of K randomly chosen attributes at each node;
-
J48 builds a decision tree by recursively partitioning the data based on attribute values, it quantifies the randomness of the class distribution within a node (also known as entropy), to define the nodes of the tree;
-
REPTree (ReT) consists of a fast decision tree learning algorithm that, similarly to J48, is also based on entropy;
-
Random Forest (RF) combines the prediction of several independent decision trees to perform classification. Each tree is constructed to process diverse training datasets, multiple subsets of the original training data. The trees are built by randomly chosen attributes used to divide the data based on the reduction in entropy. The results of all trees are aggregated to decide on the final class based on majority or average, across all trees.
Four traditional ML metrics (overall accuracy (Acc); precision (P); recall (R); and F1-score) [
1] will be used in this article to evaluate the performance of the classification based on the numbers of true positive (TP), true negative (TN), false positive (FP), and false negative (FN). Those metrics are defined as follows [
16,
22]:
3. CPS Related Datasets
Several datasets are widely used in IDS research, such as KDD Cup [
10], CICIDS [
12], UNSW-NB15 [
13], and SUTD-IoT [
31]. They are often cited in the literature, but these datasets are only based on classic IT networks and, as such, they are not representative of the traffic in industrial facilities networks. Therefore, they are not suitable for building or evaluating an IDS that operates with CPSs.
Seven specific CPS datasets can be seen in
Table 2 and the percentage of samples that represent attacks, known as
balance. The Secure Water Treatment (SWaT) [
3] and BATtle of the Attack Detection ALgorithms (BATADAL) [
32] datasets are related to large-scale water treatment. The Morris datasets are related to Industrial Control System (ICS) and they are analyzed by Hink et al. [
33], Morris and Gao [
34], and Morris et al. [
35]. ERENO is a Smart Grid (SG) dataset [
22].
Table 2. CPS datasets profile.
The SWaT dataset [
3] was created for specific studies in the CPS area. It is available from the iTrust Lab website and was generated from an actual CPS for a modern six-stage water treatment system. In total, it contains 946,722 samples, each with 53 attributes collected from sensors and actuators in 11 days. The attack models of this dataset comprise several variations of fake data injection. In summary, the attacker captures the network messages to manipulate their values. Then, the tampered packets are transmitted to the PLCs. All attacks succeeded. All the attacks on SWaT dataset appear during the last 4 days of data collection—which corresponds to approximately
1313 of the samples. As can be seen in Equations (
2)–(
4), precision, recall, and F1-score can only be defined in the presence of attacks—so that TP, FP, and FN are not all zero. Thus, for SWaT, those metrics can only be computed for the final third of the dataset.
Another dataset, known by the academic competition BATADAL [
32], was created to test attack detection algorithms in CPS water distribution systems. The dataset consisted of a network of 429 pipes, 388 junctions, 7 tanks, 11 hydraulic pumps, 5 valves, and 1 reservoir. In total, there are nine PLCs to control the status of the valves (open or closed), the inlet pressure, and the outlet pressure of the pumps, as well as the flow of water. It contains 13,938 samples, 43 attributes, and 14 attack types, and it is available for the academic community. The attacks on BATADAL dataset only appear during the last
1515 of the dataset, when their occurrences must be identified in the competition. Therefore, like with the SWaT dataset, precision, recall, and F1-score can only be defined after the occurrence of these attacks.
Morris-1 [
33] consists of a set of supervisory controls interacting with various SG devices along with network monitoring devices. The network consists of four circuit breakers controlled by smart relays, which are connected to a switch substation, through a router, to the supervisory control and the network acquisition system. The attack scenarios were built on the assumption that the attacker already has access to the substation network and can inject commands from the switch. In total, 76,035 samples were collected containing 128 attributes and four attacks.
The datasets on Morris-3 [
34] were captured using network data logs that monitor and store MODBUS traffic from an RS-232 connection. Two laboratory-scale SCADA systems of a pipeline network (dataset Morris-3 gas) and a water storage tank (dataset Morris-3 water) were used. The Wireshark program was used to capture and store network traffic during normal and under-attack operations. The datasets have 97,019 samples for the gas system (Morris-3 gas) and 236,179 samples for the water system (Morris-3 water), with 26 and 23 attributes, respectively, and seven attacks each.
The Morris-4 dataset [
35] also refers to a pipeline network simulation. This dataset has the same origin as the Morris-3 gas, but it has improvements such as 35 labeled random cyberattacks simulated in a virtual gas network. The virtual environment was chosen because it allows other experiments without the need to have access to physical devices and the possibility of expansion. The dataset has 274,628 samples with 16 attributes.
ERENO [
22] was developed as a synthetic traffic generation framework based on the IEC-61850 [
36] standard for SG. Its development was motivated by the absence of specific security datasets for SG. Therefore, the objective is to provide a reference for research in the area of intrusion detection. The dataset starts with the SG generation by means of simulations using the Power Systems Computer-Aided Design (PSCAD) tool. This allows the generation of realistic data from the Generic Object Oriented Substation Events (GOOSE) and Sampled Value (SV) protocols. In the end, the final dataset is composed of samples from seven different Use Cases (scenarios) in sequence (i.e., each at a different time), corresponding to seven different new sequential attacks, as well as normal operations.
4. Main Results
By evaluating various online and offline machine learning techniques for intrusion detection in the CPS domain, this study reveals that: (i) when known signatures are available, offline techniques present higher precision, recall, accuracy, and F1-Score, whereas (ii) for real-time detection, online methods are more suitable, as they learn and test almost 10 times faster. Furthermore, while offline ML's robust classification metrics are important, the adaptability and real-time responsiveness of online classifiers cannot be overlooked. Thus, a combined approach may be key to effective intrusion detection in CPS scenarios.