Your browser does not fully support modern features. Please upgrade for a smoother experience.
Please note this is an old version of this entry, which may differ significantly from the current revision.
NextDet, built upon YOLOv5 object detection framework for efficient monocular sparse-to-dense streaming perception, is specially designed for autonomous vehicles and autonomous rovers using edge devices. NextDet is faster, lighter and can perform both, sparse and dense object detection efficiently.
- CondenseNeXt
- object detection
- deep learning
- convolutional neural network
1. Backbone
A backbone of a modern object classifier incorporates a robust image classifier to extrapolate essential features from an input image, at different levels of coarseness. For devices with constrained computational resources, it is crucial to consider computational performance along with prediction accuracy of the image classifier. The versions of the officially published YOLO [1] family utilize Darknet53 architecture as the backbone of the network which results in an improved detection performance at the cost of heavy parametrization.
NextDet incorporates a modified version of the CondenseNeXt [2] CNN architecture as the backbone of the proposed object detection network. CondenseNeXt belongs to the family of DenseNet [3] which provides a novel technique of extracting spatial information from each layer and forwarding it to every other subsequent layer in a feed-forward fashion, allowing this information to be extracted at different levels of coarseness. CondenseNeXt utilizes multiple dense blocks at its core, as seen in Figure 1, and depthwise separable convolution and pooling layers in between these blocks to change feature-map sizes so that features can be extrapolated more efficiently at different resolutions from an input image and then fuse this information to address the vanishing-gradient problem.

Figure 1. A general visual representation of convolution and pooling layers used to change feature map sizes between multiple (𝑛) dense blocks of CondenseNeXt architecture which allows it to efficiently extract information of features from an input image.
CondenseNeXt backbone utilized in the proposed object detection network, NextDet, is re-engineering to be furthermore lightweight than its initial design for image classification purposes, by deprecating final layers of classification in order to make it compatible and to allow to link the backbone to the neck module and visually represented in Figure 2.
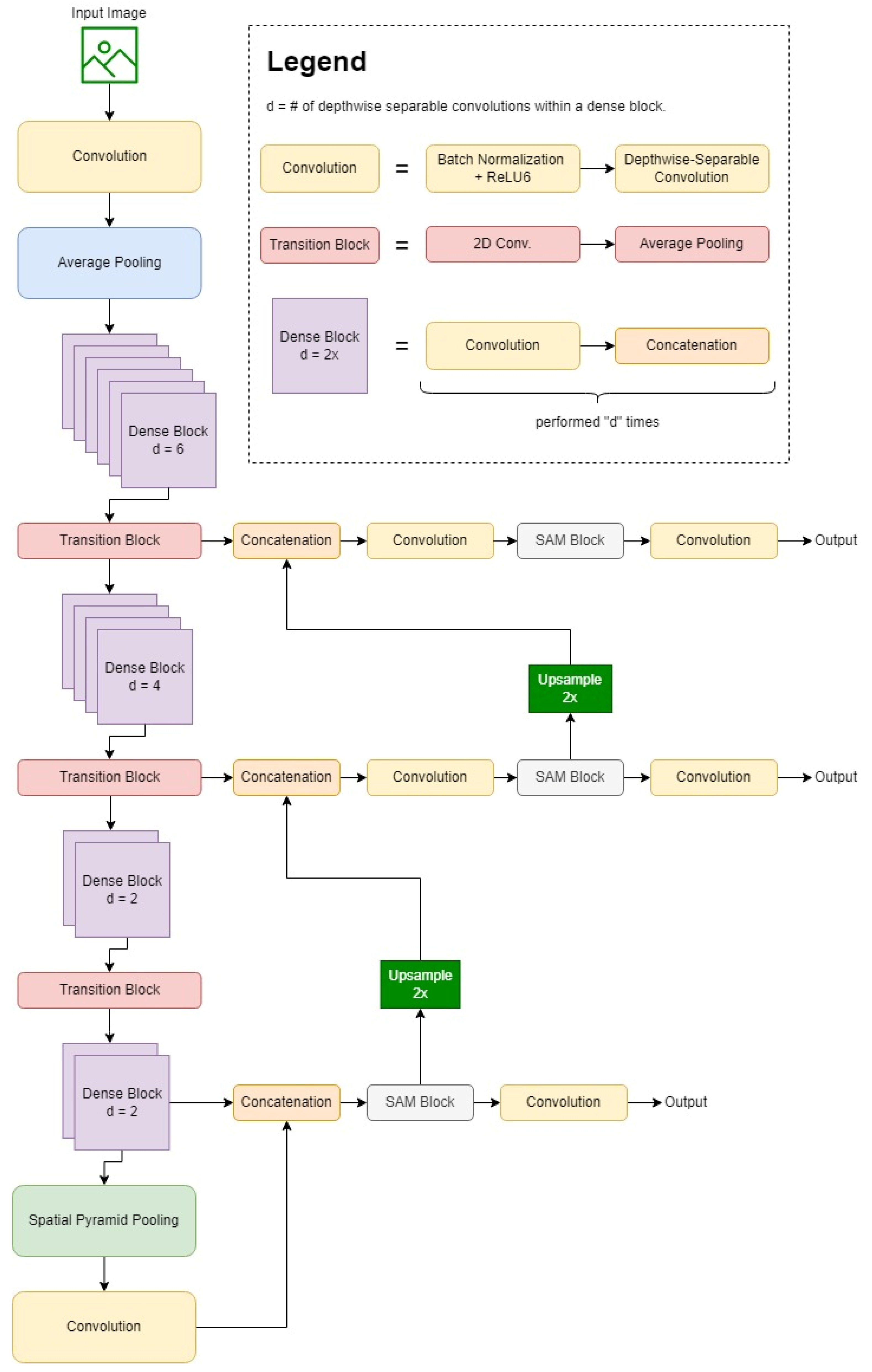
Figure 2. A visual representation of the overall mechanism of the proposed NextDet object detection network. The backbone of this proposed network consists of CondenseNeXt image classifier, the neck consists of Feature Pyramid Network (FPN) with Spatial Pyramid Pooling (SPP) and Path Aggregation Network (PAN) methodologies, and the head consists of an attention block and YOLO pipeline.
1.1. CondenseNeXt CNN
NextDet is designed with CondenseNeXt [2] CNN as the backbone. It is an efficient, yet robust image classification network designed to reduce the amount of computational resources required for real-time inference on resource constrained computing systems. It utilizes depthwise separable convolution wherein, a depthwise convolution layer applies 3 × 3 depthwise convolution 𝐾̂^ to a single input channel instead of all input channels mathematically represented by Equation (1), and then a 1 × 1 pointwise convolution 𝐾̃˜ performs a linear combination of all the output obtained from depthwise convolution mathematically represented by Equation (2) as follows:
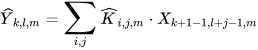
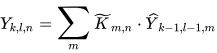
Here, 𝑋 represents input feature map of size 𝐷𝑥×𝐷𝑥×𝐼 and Y represents output feature map of size 𝐷𝑥×𝐷𝑥×𝑂 where 𝐼 corresponds to the number of input channels and 𝑂 corresponds to the number of output channels. Figure 3 provides a graphical representation of the depthwise separable convolution.
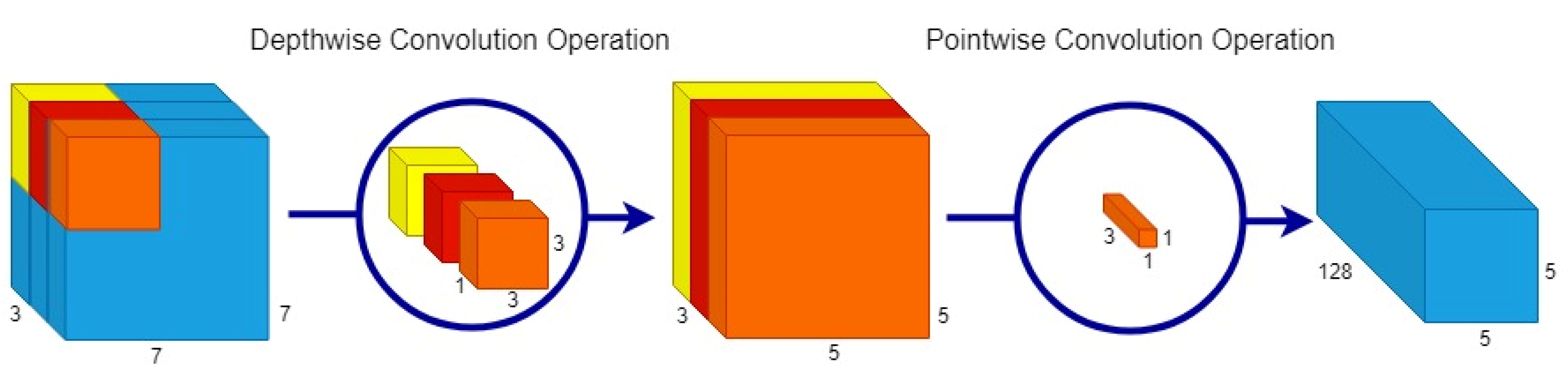
Figure 3. A 3D representation of the efficient Depthwise Separable Convolution (DSC) operation. In this image, DSC operation performs a 3 × 3 depthwise convolution operation on an input image which transforms the image and then performs a 1 × 1 pointwise convolution which elongates this transformed image to over 128 channels. For example, a blue (B) channel from RGB image is elongated only one to obtain different shades of blue channel, instead of transforming the same image multiple times.
The design of CondenseNeXt also incorporates group-wise pruning to prune and to exorcise inconsequential filters before the first stage of the depthwise separable convolution during the training process which is arbitrated by L1-Normalization and balanced focal loss function techniques to smoothen the harsh effects of the pruning process. Equation (3) defines the count of inconsequential filters exorcised during this pruning stage, where 𝐺 denotes group convolution, 𝐶 denotes cardinality and 𝑝 is a hyper-parameter defined for the training process to indicate a desired number of filters to be pruned, as follows:
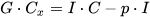
A new dimension is added into the design of this CNN, called Cardinality, to help improve and recover accuracy lost during the filter pruning process. To help improve the classification accuracy performance even further, ReLU6 (Rectified Linear Units capped at 6) [4] activation function has been implemented into the design by allowing the network to learning sparse features earlier than it would using ReLU activation function. ReLU6 also addresses ReLU’s exploding gradient problem [5]. ReLU6 can be mathematically defined as follows:
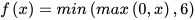
CondenseNeXt utilizes multiple dense blocks at its core where ReLU6 activation function, Batch Normalization (BN) and convolution blocks sequentially constitute a single dense block, as seen in Figure 2. Such a dense block with 𝑛 number of convolutions can be defined by the following operation where 𝑦𝑖 denotes feature maps obtained from a 𝐴𝑖(·) non-linear function, as follows:
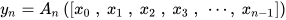
2. Neck
2.1. FPN and PAN
The neck module of a modern object detector is linked to the backbone module which acts like a feature aggregator by collecting feature maps from different stages of the backbone and fusing them together with the help of pyramid networks such as Feature Pyramid Networks (FPN) [6] and Path Aggregation Network (PANet or PAN) [7]. The neck of the proposed object detector is implemented by connecting the PAN to the FPN. The FPN provides feature maps of different sizes in order to fuse different features together. However, since the feature maps are of different sizes in the feature pyramid, the bottom features cannot be fused with the features on the top. To address this issue, the PAN is connected to the FPN and up sampled by a factor of two using the nearest neighbor approach, allowing bottom features to be connected to the top features. The bottom-up approach provides strong positioning features, and the top-down approach provides strong semantic features, resulting in an improvement in object detection performance. Figure 4 provides a simple graphical representation of this technique.
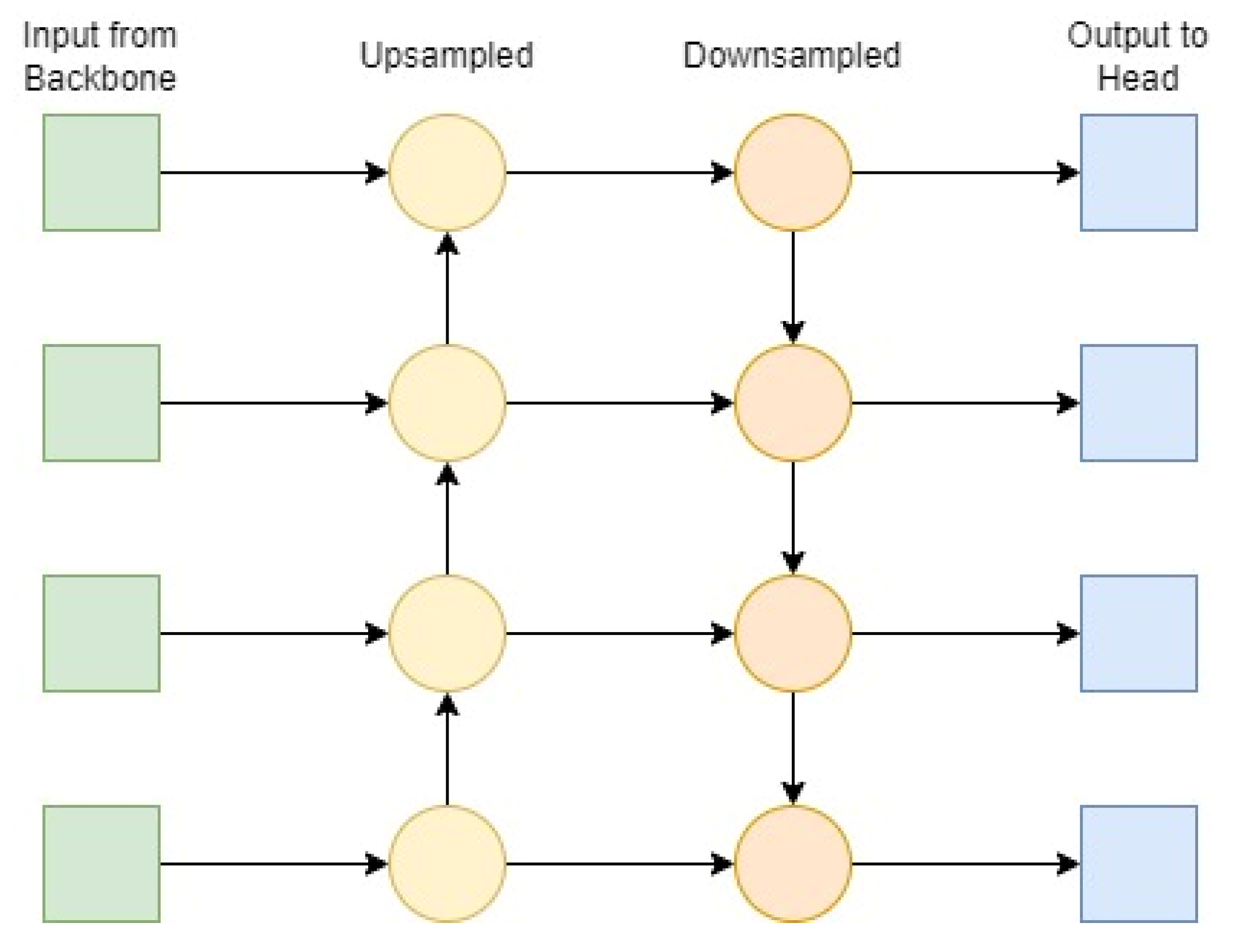
Figure 4. A graphical representation of the PANet implementation of neck of the proposed NextDet.
2.2. SPP
Spatial Pyramid Pooling (SPP) [8] is a novel pooling strategy to boost recognition accuracy performance of CNNs by pooling responses of every filter in each local spatial bin and maintaining this spatial information, inspired by the famous Bag of Words [9] approach in computer vision. This approach utilizes three different sizes of max-pooling operations in order to identify analogous feature maps irrespective of varying resolutions of input feature patterns. The output from these max-pooling operations is then flattened, concatenated, and sent to the Fully Connected (FC) layer with fixed-size output irrespective of the input size, as seen in Figure 5. The fixed-size output constraint of the CNNs is due to the FC layer, not the convolution layer. Hence, in the design of the proposed object detection network, SPP is implemented in the final stages of feature extraction, as seen in Figure 2.
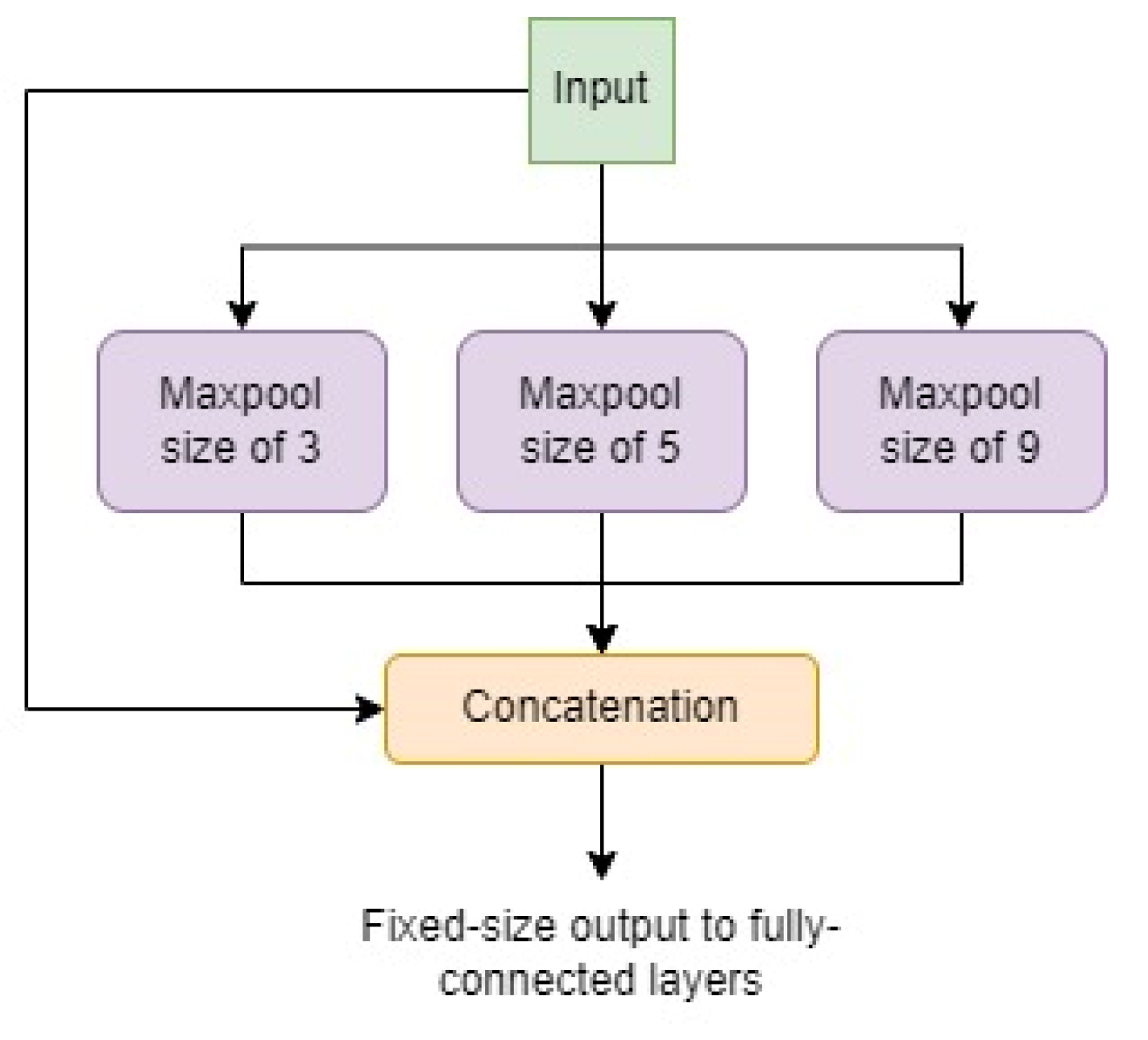
Figure 5. A graphical representation of the SPP block in the neck of the proposed NextDet object detector.
3. Head
The head module of a modern object detector determines bounding boxes and outputs detection results such as object class, score, location, and size. The general design of such systems incorporates multiple head modules in order to precisely detect objects in an input image and predict scores by exploiting a common feature set from earlier in the network. The design of the proposed NextDet object detection network utilizes 3 heads using the YOLO layer as seen in Figure 2.
Each head of the proposed NextDet network incorporates a highly efficient Spatial Attention Module (SAM) block, introduced in Convolutional Block Attention Module (CBAM) [10], for attentive feature aggregation. In this approach, a spatial attention map is generated with a focus on more important parts. Average-pooling and max-pooling operations along the channel axis is utilized to obtain inter-spatial relationships of features and can be defined mathematically as follows:
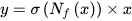
Here, 𝑥 denotes the input feature map, 𝑦 denotes the output feature map and 𝑁𝑓 denotes non-linear function for computing a SAM block’s output. 𝜎(𝑁𝑓(𝑥)) corresponds to the attention function which assigns a value up to 11 for spatial features of a higher priority and a value down to 00 for spatial features of a lower priority of the input 𝑥.
4. Bounding Box Regression
The complex task of object detection can be divided into following two sub-tasks for simplicity: object classification and object localization. The task of object localization depends on Bounding Box Regression (BBR) to locate an object of interest within an image and draw a predicted rectangular bounding box around it by overlapping the area within the predicted bounding box and the ground truth bounding box. This overlap area is called as Intersection over Union (IoU) loss. IoU, also known as Jaccard Index, is a popular metric used to measure diversity and similarity of two arbitrary shapes. It can be defined as the ratio of the intersection and union of the predicted bounding box (𝐴) and the ground-truth bounding box (𝐵), and can be mathematically defined as follows:
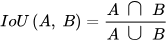
IoU loss is a popular BBR approach, but it does not work when predicted bounding box and the ground truth bounding box do not overlap i.e., when 𝐼𝑜𝑈(𝐴, 𝐵)=0. To overcome this disjoint condition of 𝐴 and 𝐵 in IoU, Generalized IoU (GIoU) [11] loss has been implemented into the design of the proposed NextDet object detector. GIoU solves IoU’s disjoint problem by increasing the overlap area size between the predicted bounding box and the ground truth bounding box, and slowly moving the predicted bounding box towards the target ground truth box. GIoU loss can be mathematically represented by Equation (8) as follows:
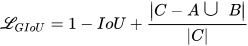
Here, 𝐶 is the smallest box covering 𝐴 and 𝐵. Experiments in [11] demonstrate that GIoU achieves an improved performance over Mean Squared Error (MSE) and IoU losses. Furthermore, the experiments demonstrate that GIoU is effective in addressing vanishing gradients in non-overlapping cases.
This entry is adapted from the peer-reviewed paper 10.3390/fi14120355
References
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016.
- Kalgaonkar, P.; El-Sharkawy, M. CondenseNeXt: An Ultra-Efficient Deep Neural Network for Embedded Systems. In Proceedings of the 2021 IEEE 11th Annual Computing and Communication Workshop and Conference (CCWC), Virtual Conference, 27–30 January 2021; pp. 524–528.
- Huang, G.; Liu, Z.; Maaten, L.V.D.; Weinberger, K.Q. Densely Connected Convolutional Networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2261–2269.
- Krizhevsky, A. Convolutional Deep Belief Networks on CIFAR-10. 2012; 9, Unpublished manuscript.
- Alkhouly, A.A.; Mohammed, A.; Hefny, H.A. Improving the Performance of Deep Neural Networks Using Two Proposed Activation Functions. IEEE Access 2021, 9, 82249–82271.
- Lin, T.-Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017.
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path Aggregation Network for Instance Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018.
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition. In Proceedings of the Computer Vision—ECCV 2014; Fleet, D., Pajdla, T., Schiele, B., Tuytelaars, T., Eds.; Springer International Publishing: Cham, Switzerland, 2014; pp. 346–361.
- Zhang, Y.; Jin, R.; Zhou, Z.-H. Understanding Bag-of-Words Model: A Statistical Framework. Int. J. Mach. Learn. & Cyber. 2010, 1, 43–52.
- Woo, S.; Park, J.; Lee, J.-Y.; Kweon, I.S. CBAM: Convolutional Block Attention Module. In Proceedings of the Computer Vision—ECCV 2018; Ferrari, V., Hebert, M., Sminchisescu, C., Weiss, Y., Eds.; Springer International Publishing: Cham, Switzerland, 2018; pp. 3–19.
- Rezatofighi, H.; Tsoi, N.; Gwak, J.; Sadeghian, A.; Reid, I.; Savarese, S. Generalized Intersection Over Union: A Metric and a Loss for Bounding Box Regression. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 658–666.
This entry is offline, you can click here to edit this entry!