Your browser does not fully support modern features. Please upgrade for a smoother experience.
Please note this is an old version of this entry, which may differ significantly from the current revision.
MobDet3, a novel object detection network based on the YOLOv5 framework. By utilizing Attentive Feature Aggregation, MobDet3 provides an improved lightweight solution for object detection in autonomous driving applications. The network is designed to be efficient and effective, even on resource-limited embedded systems such as the NXP BlueBox 2.0.
- MobileNetV3
- lightweight
- object detection
1. Backbone
The backbone of a modern object classifier is responsible for extracting essential features from an input image at different levels of coarseness. This allows the object classifier to detect objects of different sizes and scales. However, for resource-constrained devices, computational efficiency must also be considered, in addition to prediction accuracy. Although the YOLO family employs the Darknet CNN introduced in [1], as its backbone, leading to enhanced detection performance, this approach comes with the drawback of increased parameterization. MobDet3, on the other hand, employs a modified version of the MobileNetV3 CNN architecture as its backbone, which belongs to the family of efficient CNNs designed for mobile and embedded vision applications developed by Google researchers.
This methodology captures spatial information from each layer and efficiently transfers it to subsequent layers in a feed-forward manner. As a result, features can be extracted effectively at various resolutions. To address the vanishing-gradient problem, the proposed network utilizes depthwise separable convolution and pooling layers to fuse information from various resolutions. Figure 1 illustrates the architecture of MobileNetV3. The experiments on various datasets demonstrate that MobDet3 is faster and lighter and can perform object detection efficiently on resource-constrained embedded systems.

Figure 1. Visual representation of MobileNetV3 architecture.
The MobileNetV3 backbone employed in the proposed object detection network, MobDet3, has been optimized for lightweight performance beyond its original image classification design. This is achieved by removing the final fully connected and softmax layers, making the backbone compatible with, and facilitating its integration with the neck module, as explained in the following section.
MobileNetV3 CNN
MobileNetV3 is a lightweight CNN model that is particularly well suited for use on devices with constrained computational resources. It was developed through a platform-aware network architecture search and the implementation of the NetAdapt algorithm [2]. The MobileNetV1 [3] (MobileNet version 1) model introduced depthwise convolution, which reduced the number of parameters. MobileNetV2 [4] introduced an implementation of an expansion layer that was added to each block, creating a system of expansion-filtering-compression, visually represented in Figure 2, using three layers. This system, called the Inverted Residual Block, helped to further improve performance.
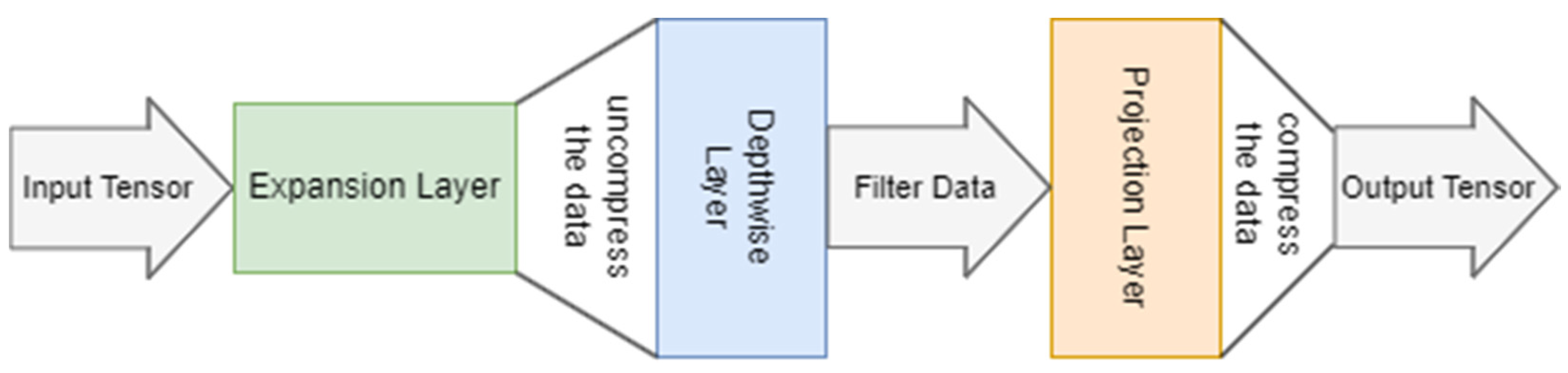
Figure 2. Expansion-Filtering-Compression System of MobileNetV3.
MobileNetV3 builds on the strengths of its predecessors by combining inverted residual bottlenecks from MobileNetV2 with Squeeze and Excitation (SE) blocks from Squeeze and Excitation Networks [5]. The SE blocks are included to enhance the classification-relevant feature maps and suppress those that are not useful. The residual bottlenecks in MobileNet V3 also consist of a 1 × 1 expansion convolution layer, followed by a 3 × 3 Depthwise Convolution (DWC) layer, and then a 1 × 1 projection layer.
MobileNetV3 incorporates depthwise separable convolutions as a more efficient alternative to conventional convolution layers. This technique effectively divides traditional convolution into separate layers, separating spatial filtering from feature generation. Depthwise separable convolutions consist of two distinct layers:
-
Depthwise Convolution: A lightweight convolution for spatial filtering mathematically represented by Equation (1) and graphically represented in Figure 3.
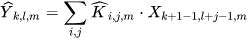
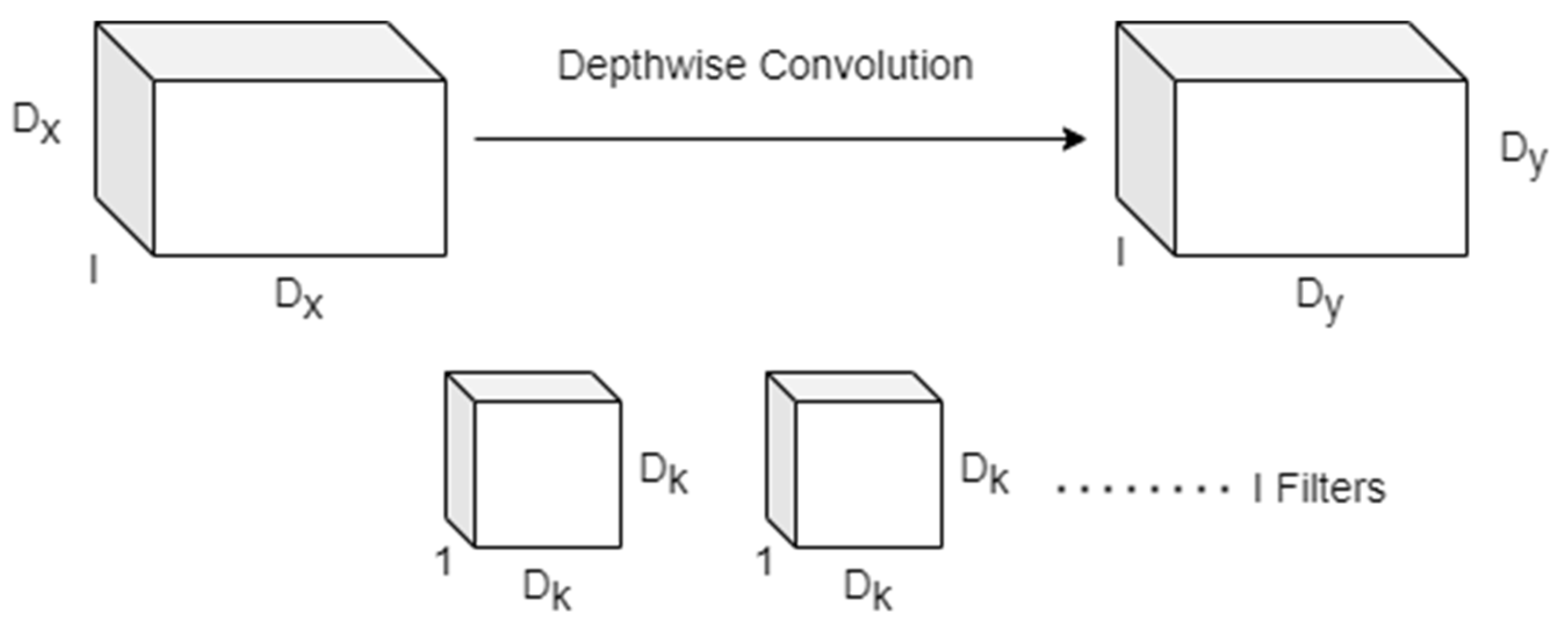
Figure 3. Depthwise convolution used for spatial filtering.
Here, 𝑋 represents the input feature map of size 𝐷𝑥×𝐷𝑥×𝐼, where 𝐼 corresponds to the number of input channels.
- 2.
-
Pointwise Convolution: A more substantial 1×1 Pointwise Convolution for feature generation mathematically represented by Equation (2) and graphically represented in Figure 4.
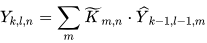
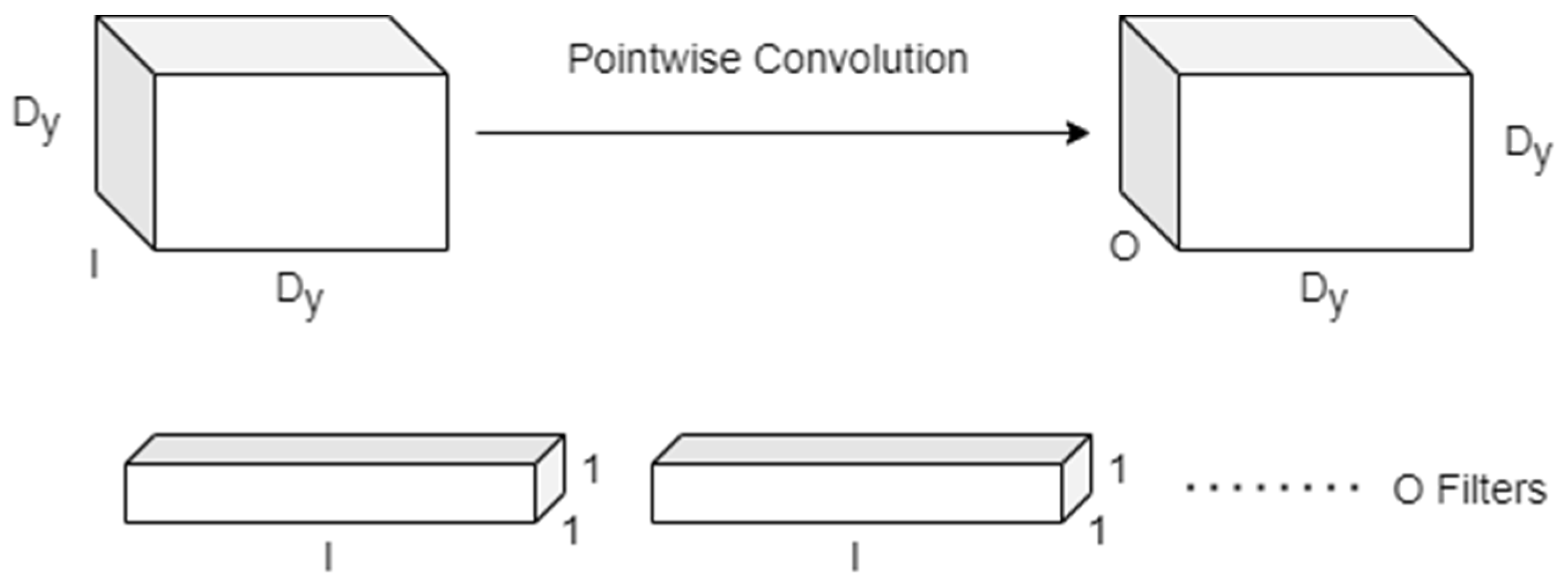 Figure 4. Pointwise convolution for feature generation.
Figure 4. Pointwise convolution for feature generation.
Here, 𝑌 represents the output feature map of size 𝐷𝑦×𝐷𝑦×𝑂, where 𝑂 corresponds to the number of output channels.
Thus, depthwise separable convolution reduces the number of parameters and computations compared to traditional convolution while maintaining high accuracy.
2. Neck
2.1. FPN and PAN
In contemporary object detectors, the neck module is linked to the backbone module and serves as a feature aggregator. It accomplishes this by gathering feature maps from different stages of the backbone and merging them using pyramid networks, such as Feature Pyramid Networks and Path Aggregation Network.
The proposed object detector incorporates the neck module by linking the Path Aggregation Network (PAN) to the Feature Pyramid Network (FPN). The FPN generates feature maps of varying sizes, facilitating the fusion of diverse features. However, due to the different sizes of feature maps within the pyramid, it becomes challenging to merge the bottom features with the top features. To tackle this challenge, the PAN is integrated with the FPN and upsampled by a factor of two using the nearest-neighbor approach. This enables the connection of bottom features with top features. This modified approach enhances detection performance by providing more robust positioning features from the bottom-up and stronger semantic features from the top-down. Figure 5 depicts a simple graphical representation of this technique.
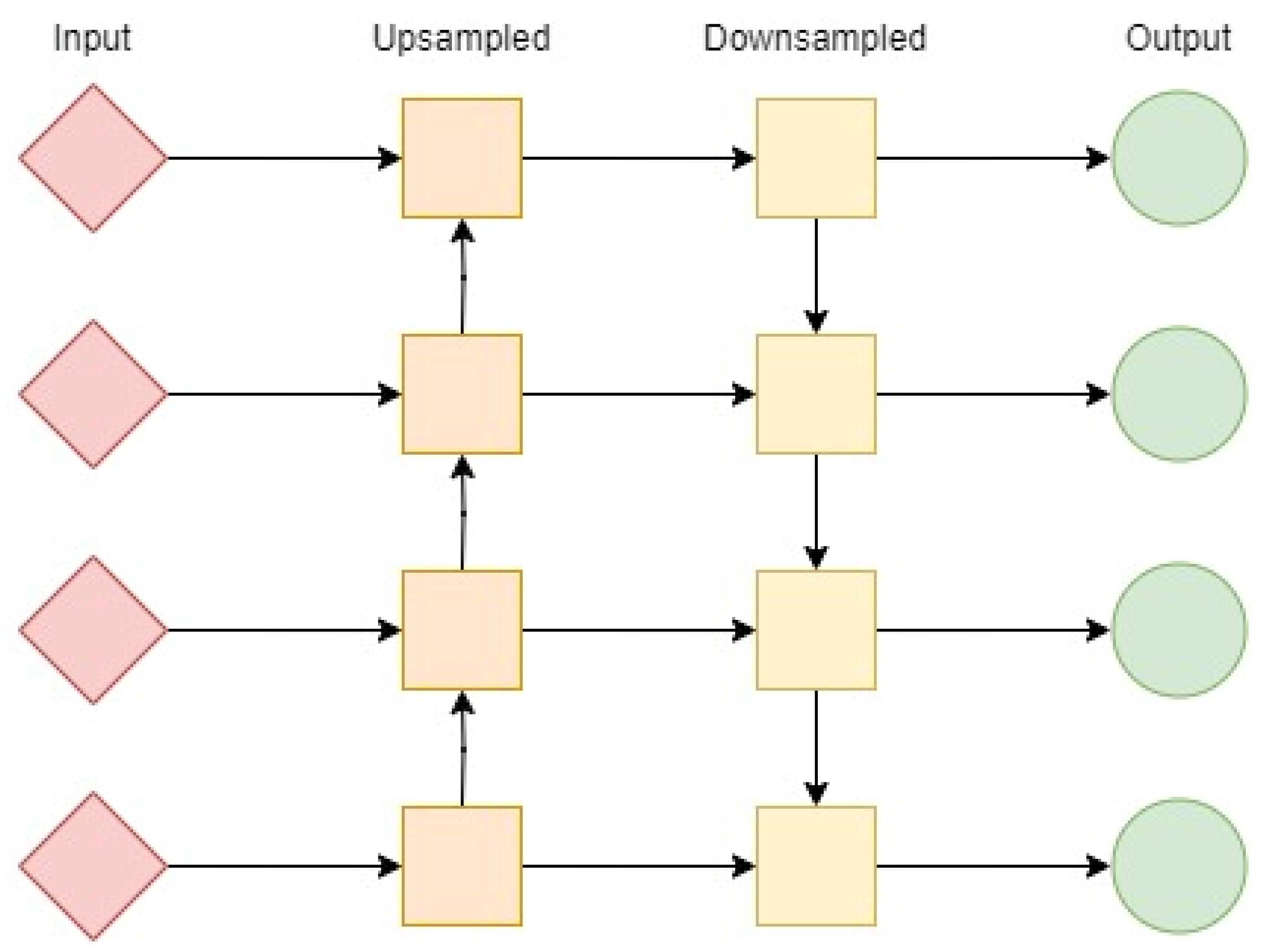
Figure 5. A graphical representation of PAN implementation of the neck of the proposed MobDet3. Here, input is from the backbone of the network, and output is to the head of the network.
2.2. SPP
Spatial pyramid pooling (SPP) is a pooling technique that improves the accuracy of convolutional neural networks (CNNs) by pooling the responses of every filter in each local spatial bin. This preserves the spatial information of the input image, which can be helpful for object detection and other tasks that require spatial information.
SPP is inspired by the bag-of-words approach in computer vision. In bag-of-words, images are represented as a bag of features where each feature is a descriptor of a local region of the image. SPP works similarly, but instead of using a fixed set of features, it uses features extracted by a CNN.
The SPP uses three different sizes of max-pooling operations to identify similar feature maps. This allows the SPP to be more robust to variations in input feature patterns. For example, if an object is rotated or scaled, the SPP will still be able to identify the object because it will be able to find similar feature maps in the different rotated or scaled versions of the object.
Following the max-pooling operations, the resulting outputs are flattened, concatenated, and directed to a fully connected (FC) layer that produces an output of a fixed size. This process is illustrated in Figure 6. The limitation of having a fixed-size output in CNNs is primarily attributed to the fully connected (FC) layer rather than the convolution layer. In the proposed object detection network, Spatial Pyramid Pooling (SPP) is integrated into the latter stages, where features are extracted.
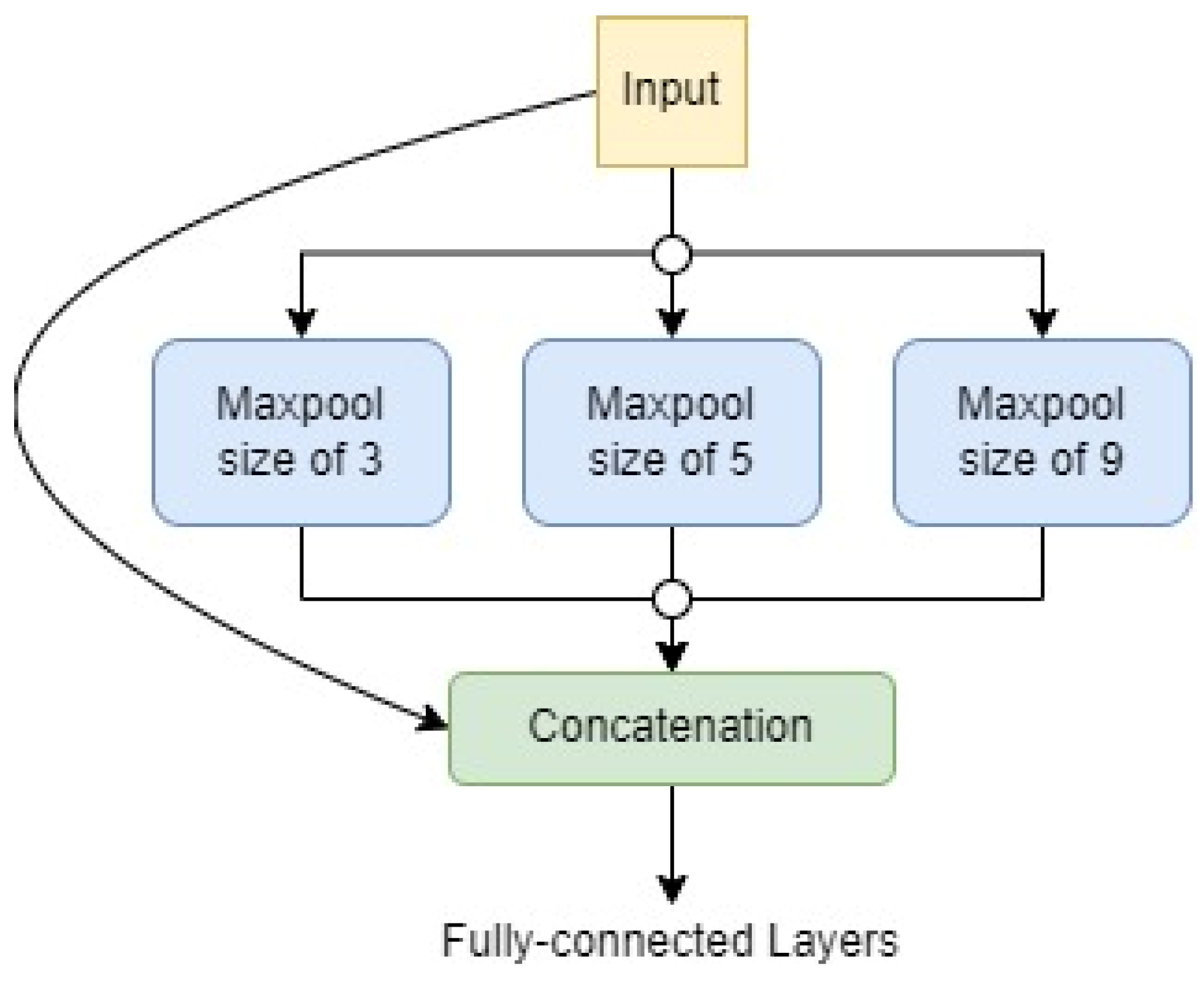
Figure 6. A graphical representation of the SPP implementation of the neck of the proposed MobDet3.
3. Head
In a modern object detector, the primary module is responsible for identifying bounding boxes and providing detection outcomes, including the object’s class, location, size, and score. In order to accomplish accurate object detection in an input image and generate score predictions, it is common practice to employ multiple head modules in the design of object detectors. These head modules utilize a shared feature set from earlier stages in the network.
The MobDet3 object detection network proposed in this study utilizes three heads, each with a Spatial Attention Module (SAM) block for attentive feature aggregation, based on the CBAM [6]. This approach generates a spatial attention map that prioritizes important areas. Inter-spatial relationships of features are obtained using average-pooling and max-pooling operations along the channel axis, and this can be expressed mathematically as follows, as seen in Figure 2.
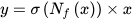
Here, the input feature map is represented by 𝑥, and the output feature map is represented by 𝑦. The SAM block’s output is computed using a non-linear function denoted by 𝑁𝑓. The attention function, 𝜎(𝑁𝑓(𝑥)), is responsible for assigning a value between 11 and 00 to the spatial features of the input 𝑥 based on their priority level. Specifically, higher priority spatial features receive a value closer to 11, while lower priority spatial features receive a value closer to 00.
4. Bounding Box Regression
To simplify the intricate task of object detection, it can be broken down into two sub-tasks: object classification and object localization. Object localization employs Bounding Box Regression (BBR) to precisely locate the object of interest within an image and to generate predictions of a rectangular bounding box surrounding it. The predicted bounding box is then compared to the ground truth bounding box to calculate the Intersection over Union (IoU) [7] loss, which represents the overlap area between the two boxes. IoU, also known as the Jaccard Index, is a commonly used metric for measuring the similarity and diversity between two arbitrary shapes. It is calculated as the ratio of the intersection and union of the predicted bounding box (𝐴) and the ground-truth bounding box (𝐵), and can be expressed mathematically as follows:
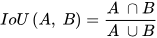
The use of IoU loss in BBR is common, but it fails when the predicted bounding box and ground truth bounding box fail to overlap (i.e., when 𝐼𝑜𝑈(𝐴, 𝐵)=0). To address this issue of disjoint 𝐴 and 𝐵 in IoU, the proposed MobDet3 object detector incorporates the Generalized IoU (GIoU) [7] loss. By iteratively adjusting the position of the predicted bounding box toward the ground truth box, the GIoU metric enhances the overlap area between the two boxes. This effectively resolves the issue of disjointedness encountered in the standard Intersection over Union (IoU) measurement. The GIoU loss is expressed mathematically as follows:
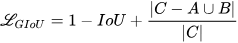
In this equation, 𝐶 represents the smallest box that encompasses both 𝐴 and 𝐵. The experiments conducted in [7] reveal that GIoU surpasses Mean Squared Error (MSE) and IoU losses in performance. These experiments also demonstrate the effectiveness of GIoU in addressing the problem of vanishing gradients that arise in cases where objects do not overlap.
This entry is adapted from the peer-reviewed paper 10.3390/jlpea13030049
References
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767.
- Yang, T.-J.; Howard, A.; Chen, B.; Zhang, X.; Go, A.; Sandler, M.; Sze, V.; Adam, H. NetAdapt: Platform-Aware Neural Network Adaptation for Mobile Applications. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018.
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications. arXiv 2017, arXiv:1704.04861.
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.-C. MobileNetV2: Inverted Residuals and Linear Bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018.
- Hu, J.; Shen, L.; Albanie, S.; Sun, G.; Wu, E. Squeeze-and-Excitation Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 42, 2011–2023.
- Woo, S.; Park, J.; Lee, J.-Y.; Kweon, I.S. CBAM: Convolutional Block Attention Module. In Proceedings of the Computer Vision—ECCV 2018, Munich, Germany, 8–14 September 2018; Ferrari, V., Hebert, M., Sminchisescu, C., Weiss, Y., Eds.; Springer International Publishing: Cham, Switzerland, 2018; pp. 3–19.
- Rezatofighi, H.; Tsoi, N.; Gwak, J.; Sadeghian, A.; Reid, I.; Savarese, S. Generalized Intersection Over Union: A Metric and a Loss for Bounding Box Regression. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 658–666.
This entry is offline, you can click here to edit this entry!