Traditional approaches for identifying manipulated images commonly rely on camera and external fingerprints. Camera fingerprints refer to intrinsic fingerprints injected by digital cameras, while external fingerprints result from editing software. Previous manipulation detection methods based on camera fingerprints have utilized various properties such as optical lens characteristics [
9], color filter array interpolation [
10], and compression techniques [
11]. On the other hand, existing manipulation detection approaches based on external fingerprints aim to identify copy-paste fingerprints in different parts of the image [
12], frame rate reduction [
13], and other features. While these approaches have achieved good performance, most of the features used in the training process are handcrafted and heavily reliant on specific settings, making them less effective when applied to testing data in unseen conditions [
14]. Currently, external fingerprints are considered more important than camera fingerprints due to the prevalence of manipulated media being uploaded and shared on social media sites, which automatically modify uploaded images and videos through processes such as compression and resizing operations [
15].
2. Background
Image manipulation dates back to as early as 1860, when a picture of southern politician John C. Calhoun was realistically altered by replacing the original head with that of US President Abraham Lincoln [
29]. In the past, image forgery was achieved through two standard techniques: image splicing and copy-move forgery, wherein objects were manipulated within an image or between two images [
30]. To improve the visual appearance and perspective coherence of the forged image while eliminating visual traces of manipulation, additional post-processing steps, such as lossy JPEG compression, color adjustment, blurring, and edge smoothing, were implemented [
31].
In addition to conventional image manipulation approaches, recent advancements in CV and DL have facilitated the emergence of various novel automated image manipulation methods, enabling the production of highly realistic fake faces [
32]. Notably, hot topics in this domain include the automatic generation of synthetic images and videos using algorithms like GANs and AEs, serving various purposes, such as realistic and high-resolution human face synthesis [
17] and human face attribute manipulation [
33,
34]. Among these, deepfake stands out as one of the trending applications of GANs, capturing significant public attention in recent years.
Deepfake is a technique used to create highly realistic and deceptive digital media, particularly manipulated videos and images, using DL algorithms [
35]. The term “deepfake” is derived from the terms “deep learning” and “fake”. It involves using artificial intelligence, particularly deep neural networks, to manipulate and alter the content of an existing video or image by superimposing someone’s face onto another person’s body or changing their facial expressions [
36]. Deepfake technology has evolved rapidly, and its sophistication allows for the creation of highly convincing fake videos that are challenging to distinguish from genuine footage. This has raised concerns about its potential misuse, as it can be employed for various purposes, including spreading misinformation, creating fake news, and fabricating compromising content [
23,
27]. For example, in May 2019, a distorted video of US House Speaker Nancy Pelosi was meticulously altered to deceive viewers into believing that she was drunk, confused, and slurring her words [
37]. This manipulated video quickly went viral on various social media platforms and garnered over 2.2 million views within just two days. This incident served as a stark reminder of how political disinformation can be easily propagated and exploited through the widespread reach of social media, potentially clouding public understanding and influencing opinions.
Another related term, “cheap fake”, involves audio-visual manipulations produced using more affordable and accessible software [
38]. These techniques include basic cutting, speeding, photoshopping, slowing, recontextualizing, and splicing, all of which alter the entire context of the message delivered in existing footage.
3. Types of Digital Face Manipulation and Datasets
3.1. Digitally Manipulated Face Types
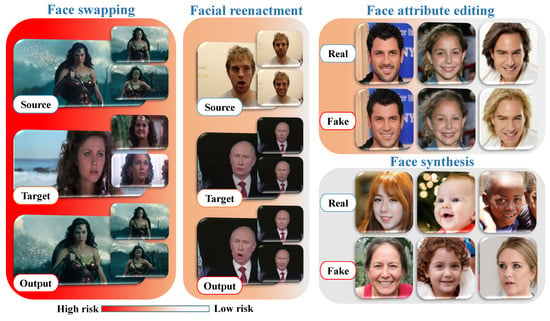
Previous studies on digital facial manipulation can be classified into four primary categories based on the degree of manipulation. Figure 1 provides visual descriptions of each facial manipulation category, ranging from high-risk to low-risk in terms of the potential impact on the public. The high risk associated with face swapping and facial re-enactment arises from the fact that malicious individuals can exploit these techniques to create fraudulent identities or explicit content without consent. Such concerns are rapidly increasing, and if left unchecked, they could lead to widespread abuse.
Figure 1. Four primary categories of face manipulation, including face swapping, facial re-enactment, face attribute editing, and face synthesis. Note: the gradient color bar on the bottom left of the image visualizes the risk levels based on the survey outcomes.
-
Face synthesis encompasses a series of methods that utilize efficient GANs to generate human faces that do not exist, resulting in astonishingly realistic facial images.
Figure 1 introduces various examples of entire face synthesis created using the PGGAN structure [
39]. While face synthesis has revolutionized industries like gaming and fashion [
40], it also carries potential risks, as it can be exploited to create fake identities on social networks for spreading false information.
-
Face swapping involves a collection of techniques used to replace specific regions of a person’s face with corresponding regions from another face to create a new composite face. Presently, there are two main methods for face swapping: (i) traditional CV-based methods (e.g., FaceSwap), and (ii) more sophisticated DL-based methods (e.g., deepfake). Figure 1 illustrates highly realistic examples of this type of manipulation. Despite its applications in various industrial sectors, particularly film production, face swapping poses the highest risk of manipulation due to its potential for malevolent use, such as generating pornographic deepfakes, committing financial fraud, and spreading hoaxes.
-
Face attribute editing involves using generative models, including GANs and variational autoencoders (VAEs), to modify various facial attributes, such as adding glasses [
33], altering skin color and age [
34], and changing gender [
33]. Popular social media platforms like TikTok, Instagram, and Snapchat feature examples of this manipulation, allowing users to experiment with virtual makeup, glasses, hairstyles, and hair color transformations in a virtual environment.
-
Facial re-enactment is an emerging topic in conditional face synthesis, aimed at two main concurrent objectives: (1) transferring facial expressions from a source face to a target face, and (2) retaining the features and identity of the target face. This type of manipulation can have severe consequences, as demonstrated by the popular fake video of former US President Barack Obama speaking words that were not real [
41].
3.2. Datasets
To generate fake images, researchers often utilize authentic images from public face datasets, including CelebA [
34], FFHQ [
42], CASIAWebFace [
43], and VGGFace2 [
44]. Essential details about each of these public datasets are provided in
Table 1.
Table 1. Publicly available face datasets used for performing face image manipulation.
3.2.1. Face Synthesis and Face Attribute Editing
Despite the significant progress in GAN-based algorithms [
33,
46], to the best of our knowledge, few benchmark datasets are available for these topics. This scarcity is mainly attributed to the fact that most GAN frameworks can be easily re-implemented, as their codes are accessible online [
47]. As a result, researchers can either download GAN-specific datasets directly or generate their fake datasets effortlessly.
Interestingly, each synthetic image is characterized by a specific GAN fingerprint, akin to the device-based fingerprint (fixed pattern noise) found in images captured by camera sensors. Furthermore, most of the mentioned datasets consist of synthetic images generated using GAN models. Therefore, researchers interested in conducting face synthesis generation experiments need to utilize authentic face images from other public datasets, such as VGGFace2 [
44], FFHQ [
42], CelebA [
34], and CASIAWebFace [
43].
In general, most datasets in the table are relevant because they are associated with well-known GAN frameworks like StyleGAN [
48] and PGGAN [
39]. In 2019, Karras et al. introduced the 100K-Generated-Images dataset [
48], consisting of approximately 100,000 automatically generated face images using the StyleGAN structure applied to the FFHQ dataset [
42]. The unique architecture of StyleGAN enabled it to automatically separate high-level attributes, such as pose and identity (human faces), while also handling stochastic variations in the created images, such as skin color, beards, hair, and freckles. This allowed the model to perform scale-specific mixing operations and achieve impressive image generation results.
Another publicly available dataset is 100K-Faces [
49], comprising 100,000 synthesized face images created using the PGGAN model at a resolution of 1024 by 1024 pixels. Compared to the 100K-Generated-Images dataset, the StyleGAN model in the 100K-Faces dataset was trained using about 29,000 images from a controlled scenario with a simple background. This resulted in the absence of strange artifacts in the image backgrounds created by the StyleGAN model.
Recently, Dang et al. introduced the DFFD dataset [
50], containing 200,000 synthesized face images using the pre-trained StyleGAN model [
48] and 100,000 images using PGGAN [
39]. Finally, the iFakeFaceDB dataset was released by Neves et al. [
51], comprising 250,000 and 80,000 fake face images generated by StyleGAN [
48] and PGGAN [
39], respectively. An additional challenging feature of the iFakeFaceDB dataset is that GANprintR [
51] was used to eliminate the fingerprints introduced by the GAN architectures while maintaining a natural appearance in the images.
3.2.2. Face Swapping and Facial Re-Enactment
Some small datasets, such as WildDeepfake [
66], UADFV [
69], and Deepfake-TIMIT [
71], are early versions and contain less than 500 unique faces. For instance, the WildDeepfake dataset [
66] consists of 3805 real face sequences and 3509 fake face sequences originating from 707 fake videos. The Deepfake-TIMIT database has 640 fake videos created using Faceswap-GAN [
69]. Meanwhile, the UADFV dataset [
71] contains 98 videos, with half of them generated by FakeAPP.
In contrast, more recent generations of datasets have exponentially increased in size. FaceForensics++ (FF++) [
67] is considered the first large-scale benchmark for deepfake detection, consisting of 1000 pristine videos from YouTube and 4000 fake videos created by four different deepfake algorithms: deepfake [
72], Face2Face [
73], FaceSwap [
74], and NeuralTextures [
75]. The Deepfake Detection (DFD) [
68] dataset, sponsored by Google, contains an additional 3000 fake videos, and video quality is evaluated in three categories: (1) RAW (uncompressed data), (2) HQ (constant quantization parameter of 23), and (3) LQ (constant quantization parameter of 40). Celeb-DF [
65] is another well-known deepfake dataset, comprising a vast number of high-quality synthetic celebrity videos generated using an advanced data generation procedure.
Facebook introduced one of the biggest deepfake datasets, DFDC [
62], with an earlier version called DFDC Preview (DFDC-P) [
63]. Both DFDC and DFDC-P present significant challenges, as they contain various extremely low-quality videos. More recently, DeeperForensics1.0 [
64] was published, modifying the original FF++ videos with a novel end-to-end face-swapping technique. Additionally, OpenForensics [
55] was introduced as one of the first datasets designed for deepfake detection and segmentation, considering that most of the abovementioned datasets were proposed for performing deepfake classification.
Figure 2 displays two sample images from each of the five well-known face synthesis datasets.
Figure 2. Comparison of fake images extracted from various deepfake datasets.
While the number of public datasets has gradually increased due to advancements in face manipulation generation and detection, it is evident that Celeb-DF, FaceForensics++, and UADFV are currently among the most standard datasets. These datasets boast a vast collection of videos with varying categories that are appropriately formatted. However, there is a difference in the number of classes between the datasets. For example, the UADFV database is relatively simple and contains only two classes: pristine and fake. In contrast, the FaceForensics++ dataset is more complex, involving different types of video manipulation techniques and encompassing five main classes.
One common issue among existing deepfake datasets is that they were generated by splitting long videos into multiple short ones, leading to many original videos sharing similar backgrounds. Additionally, most of these databases have a limited number of unique actors. Consequently, synthesizing numerous fake videos from the original videos may result in machine learning models struggling to generalize effectively, even after being trained on such a large dataset.