Image segmentation refers to the segmentation of an image into several disjoint regions based on features such as grayscale, color, spatial texture, and geometric shape, so that these features exhibit consistency or similarity within the same region and differences between different regions. The aim of this operation is to segment objects from the background. Image segmentation can be divided into semantic segmentation, instance segmentation, and panoptic segmentation. Semantic segmentation refers to the classification of pixels of an image into semantic categories; pixels belonging to a particular category are classified only to that category without considering other information. Instance segmentation classifies pixels by “instances” rather than categories. Panoptic segmentation, on the other hand, involves segmenting the entire image and separating each instance of an object in the image, while also predicting the identity of the object. Most of the existing semantic segmentation models are based on convolutional neural networks (CNNs) [
1], and their network architecture is typically an encoder–decoder-based one [
2], whereby the encoder is typically a pre-trained classification network, such as Visual Geometry Group (VGG-16) [
3], Residual Network (ResNet) [
4], Hierarchical Vision Transformer using Shifted Windows (Swin Transformer) [
5], ConvNeXt [
6], and so on. The commonly used semantic segmentation models include Fully Convolutional Networks (FCN) [
7], SegNet [
8], DeepLab v1 [
9], DeepLab v2 [
9], DeepLab v3 [
10], DeepLab v3+ [
11], Pyramid Scene Parsing Network (PSPNet) [
12], etc. These models have shown brilliant results in semantic segmentation. U-Net [
13] represents one of the most classic models in medical image segmentation, and its improved versions, such as U-Net++ [
14], U-Net++ [
15], DoubleU-Net [
16], and U2Net [
17], have also shown excellent results. Based on U-Net, this paper proposes a novel U-Net_dc model for performing better endometrial cancer cell segmentation.
2. Classic Image Segmentation Models
2.1. Fully Convolutional Networks (FCNs)
In 2014, Long et al. in [
7] proposed the FCN model, which represents a pioneering work of deep learning in the field of image segmentation. As the name implies, FCN only includes convolutional layers, with fully connected layers removed, so it can accept images of any size. Then, it trains an end-to-end full convolutional network for pixel-by-pixel classification. The continuous use of convolution operations to extract features in FCN leads to increasingly lower image resolution. Thus, it is necessary to upsample the low-resolution image in order to restore the value of the original image, thereby classifying and predicting each pixel on the original image. In the model proposed in this paper, an upsampling operation is first performed and then followed by a deconvolution operation to restore the image resolution to the value of the original image.
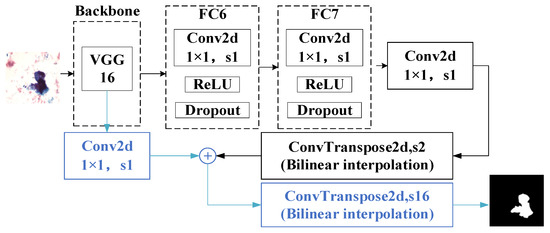
FCN is divided into FCN-32S, FCN-16S, and FCN-8S. For FCN-32S, the convolutional portion of VGG16 is used as its backbone, and the last three fully connected layers of VGG16 are changed to convolutional layers. In the upsampling section, a transposed convolution with a step size of 32 is used to upsample the feature map 32 times and restore the image to the original size. The disadvantage of FCN-32S is that during the upsampling process, the final feature map is sampled 32 times at a time, and many details could be lost during the upsampling process due to the small feature map of the last layer. For FCN-16S and FCN-8S, improvements are made to address this problem. In FC-16S, a branch is added based on FCN-32S. The input part of this branch is the output feature map of the fourth pooling layer in VGG16. Finally, the outputs of the two branches are added, and then a six-fold upsampling is conducted to restore the image to the original size, as shown in Figure 1. In FCN-8S, a branch is added based on FCN-16S. The input part of this branch is the output feature map of the third pooling layer in VGG16. Finally, the outputs of the three branches are added, and then an eight-fold upsampling is performed to restore the image to its original size.
2.2. Deep Convolutional Encoder–Decoder Architecture (SegNet)
SegNet [
8] is a deep network of image semantic segmentation proposed by the University of Cambridge for the purposes of autonomous driving or intelligent robotics. SegNet is a semantic segmentation network, based on FCN, obtained by modifying VGG-16. Its idea is quite similar to FCN, except for the encoding and decoding techniques used. For the encoder part of SegNet, the first 13 convolutional layers of VGG-16 are used, whereby each encoder layer corresponds to a decoder layer. The final output of the decoder is fed into a SoftMax classifier [
35], which classifies each pixel independently.
Specifically, the same convolution is used in SegNet to extract features during the encoding process so that the size of the image does not change before and after the convolution. In the decoding process, the same convolution is also used, but the goal of doing so is to enrich the feature information for the images upon upsampling. As a result, the information lost during the pooling process can be obtained through learning during the decoding process. The biggest highlight of SegNet lies in that the upsampling operation in the decoding process is not realized through transposed convolution but by maximum unpooling. To put it simply, the index of the maximum value is recorded when performing the maximum pooling operation.
When performing the maximum unpooling operation, each weight is assigned to the corresponding position according to the index, with the other positions filled with zeroes. This can reduce the number of parameters and computation workload relative to the transposed convolution and eliminate the need for learning upsampling.
2.3. Pyramid Scene Parsing Network (PSPNet)
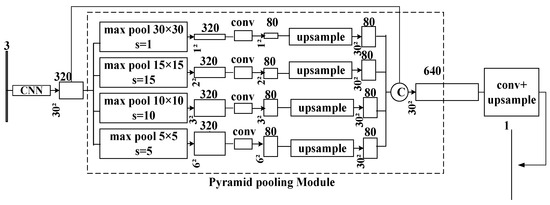
When it comes to the disadvantage of FCN, it does not use global scene classification information well. Comparatively, PSPNet combines local and global information by building a pyramid pooling module to make the final prediction more reliable. The model performs feature fusion at four different scales, rough or fine, through a pyramid pooling module. The roughest scale performs global average pooling of feature maps to produce a single-grid output, while the finest scale divides the feature map into sub-regions, resulting in multi-grid output. Different scales of outputs correspond to different sizes of feature maps. The low-dimensional feature maps are then upsampled through bilinear interpolation to obtain features of the same size. Finally, the different levels of features are spliced into the final global feature of pyramid pooling, as shown in Figure 2.
Specifically, the feature extraction network of PSPNet is a Mobilenet V2 structure [
36], in which features are extracted through multiple convolutions, pooling, and cross-layer connections, until the feature map is finally outputted. Then, a pyramid pooling module is used for feature fusion at four different scales, rough or fine. A 30 × 30 global pooling, a 15 × 15 maximum pooling with a step size of 15, a 10 × 10 maximum pooling with a step size of 10, and a 5 × 5 maximum pooling with a step size of 5 for feature maps extracted from the trunk are performed separately. Then, a bilinear interpolation upsampling on these new feature maps is conducted at different scales to restore images to their original size, and these feature maps are spliced with the feature maps extracted from the trunk. Finally, one round of convolution is performed to switch the number of channels to the desired number for outputting.
3. U-Net Models
3.1. U-Net
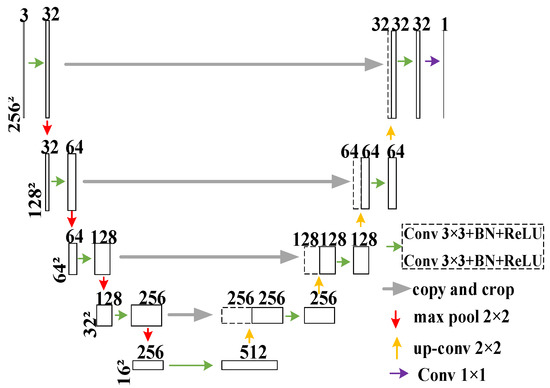
Proposed in 2015, U-Net is a model aimed at solving the problem of medical image segmentation. It has a U-shaped structure in its entirety. Convolutional layers are used during the whole process, with fully connected layers removed, so that the size of the input image is not constrained. The entire network is divided into two parts, encoding and decoding, from shallow to deep layers and from bottom to top. For encoding, two 3 × 3 convolutions, a Batch Normalization (BN) layer [
37], and a Rectified Linear Unit (ReLU) activation function [
38] are used at each layer. The number of channels is increased without changing the image size. Then, a 2 × 2 maximum pooling layer is adopted to reduce the image size to half of the original size to continuously extract image features. For decoding, an upsampling operation is first performed on the image through transposed convolution to double the size of the image while reducing the number of channels by half. Then, feature fusion is performed on these upsampling images and images produced by the encoding process at the same level. Finally, the number of channels upon feature fusion is reduced by half through two 3 × 3 convolutions. This process continues until the size of the image is restored to its original value. As the final step of the network, the final number of output channels is converted into the desired number while maintaining the same image size via a 1 × 1 convolution, as shown in
Figure 3.
The features extracted from each layer differ greatly as the network deepens. High-level features tend to have a lower resolution but stronger semantic information, whereas low-level features have higher resolution but perceive details better. Thus, both high-level and low-level extracted features have their respective meanings. U-Net fuses features at different levels by using the advantages of both low levels and high levels. Generally, the edges of a larger feature map obtained through upsampling contain insufficient information. It is impossible for the lost features to be retrieved through upsampling. However, U-Net realizes the retrieval of edge features through feature splicing.
3.2. U-Net++
As an improved version of U-Net, U-Net++ combines the structural ideas of U-Net and eliminates its shortcomings. U-Net++ indirectly integrates multiple features at different levels through short connections, upsampling, and downsampling, rather than simply splicing the same-level features of the encoder and decoder. It is precisely due to this reason that the decoder can perceive objects of different sizes in different sensory fields, thereby improving the segmentation performance of the model.
To be specific, U-Net++ uses a dense skip connection to establish a skip path between the encoder and decoder to make up for the lack of semantic similarity caused by simply splicing the encoding and decoding features at the same level in U-Net. The use of dense blocks in this model is inspired by DenseNet [
39]. The output of the previous convolutional layer for the same dense block is integrated with the corresponding upsampling output of the dense block at the lower layer, which makes the semantic level of the encoded feature closer to the semantic level of the feature mapping that waits in the decoder. Moreover, a deep supervision strategy is adopted in U-Net++ to adjust the complexity of the model through pruning operations, thus striking a balance between speed and performance.
3.3. DoubleU-Net
DoubleU-Net is a new model that connects two U-Nets together. Structurally, its network can be roughly divided into two parts, NETWORK1 and NETWORK2, both of which are quite similar to U-Net, with slight differences in details. The VGG-19 module is used in the encoding process of NETWORK1, and the atrous spatial pyramid pooling (ASPP) block [
9] is used in the intermediate process of encoding and decoding. In the ASPP module, atrous convolutions with different expansion rates are utilized to obtain multiscale object information and finally fuse these features to generate the final result. The squeeze-and-excitation (SE) block [
40], which is used after the decoding process, is designed to reduce redundant information and transfer only the most relevant information.
More specifically, both NETWORK1 and NETWORK2 maintain the splicing of same-level encoding and decoding features in U-Net. However, the skip connection of NETWORK2 connects both the information of its own encoding network and the information of the NETWORK1 encoding network. The result of multiplying the input and output in NETWORK1 is used as the input to NETWORK2, so that the feature map output of NETWORK1 can be further improved by obtaining the information of the original input image again. Finally, the outputs of the two networks are spliced to retain both the final output characteristics and output characteristics of NETWORK1.