Your browser does not fully support modern features. Please upgrade for a smoother experience.
Please note this is an old version of this entry, which may differ significantly from the current revision.
Convolutional neural networks learn directly from data and are widely used for image recognition and classification. CNNs have been considered one of the best machine learning algorithms to analyze grid-like structured data, such as images.
- skin cancer
- segmentation
- classification
- deep learning
1. Introduction
Skin cancer is one of the most common types of cancer that begins with the uncontrolled reproduction of skin cells. It can occur because of the ultraviolet radiation from sunshine or tanning beds, and it causes skin cells to multiply and form malignant tumors.
Skin cancer is one of the primary reasons for deaths worldwide. According to statistics published by [1], 97,160 Americans were diagnosed with skin cancer in 2023, which is 5.0% of the total cancer cases reported in the United States, and 7990 people died because of skin cancer which is 1.3% of the total deaths because of skin cancer in the United States [1]. Melanoma is one of the most common and dangerous types of skin cancer that can spread quickly to other body parts. Approximately 21 out of 100,000 melanoma cases were diagnosed in the United States between 2016 and 2020. The death rate because of melanoma was 2.1 per 100,000 diagnosed cases, and 1,413,976 people were living with melanoma in 2020 [1]. The five-year survival rate of skin melanoma is 93.5% which is relatively high [1]. The five-year survival rate is 99.6% when skin melanoma is diagnosed at an early stage [1]. There are more chances of survival when skin melanoma is localized, which means it does not spread to other body parts, but only 77.6% of skin melanomas are diagnosed at the local stage. The number of deaths because of skin melanoma can be reduced if it is detected at its early stages.
The most common method of diagnosing skin cancer is by visual examinations by dermatologists, which has an accuracy of about 60% [2]. The diagnostic accuracy of skin cancers increases to 89% by using dermoscopy. Dermoscopy has a sensitivity of 82.6% for detecting melanocytic lesions, 98.6% for basal cell carcinoma, and 86.5% for squamous cell carcinoma [3]. Dermoscopy increases the accuracy of melanoma diagnosis, but it may still be challenging to diagnose some lesions, particularly early melanomas accurately, that lack distinctive dermoscopic features. Though dermoscopy diagnoses skin melanoma with very good accuracy, it is not well suited for diagnosing featureless melanoma, and there is still a need to improve accuracy further to increase the survival rate of patients. The problems with dermoscopy and the need to increase the diagnostic accuracy of skin cancer further laid the foundation for developing computer-aided detection methods for diagnosing skin cancers.
Generally, there are five steps in computer-aided skin cancer diagnosis: image acquisition, pre-processing, segmentation, feature extraction, and classification [4,5]. The most essential steps in computer-aided diagnosis of skin cancers are segmentation and classification [6,7]. However, diagnosing skin cancer using computer-aided methods is not straightforward, and many factors for an accurate diagnosis must be considered. For example, artifacts such as hairs, dark corners, water bubbles, marker signs, ink marks, and ruler signs, as shown in Figure 1 [6,8,9] can result in misclassification and inaccurate segmentation of skin lesions.
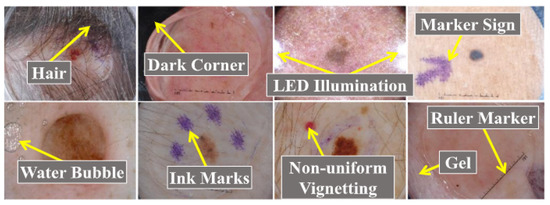
Figure 1. Skin cancers with artifacts adapted from [8].
2. Convolutional Neural Networks (CNNs) for Image Classification
Convolutional neural networks learn directly from data and are widely used for image recognition and classification. CNNs have been considered one of the best machine learning algorithms to analyze grid-like structured data, such as images. CNNs have shown exceptional performance in image processing problems and computer vision tasks such as localization and segmentation, classification, and detection [15]. A convolutional neural network typically contains tens or hundreds of layers, each of which can be trained to recognize distinct aspects of an image. The output of each convolved picture is utilized as the input to the following layer after filters are applied while training an image with various resolutions. The filters start with detecting basic features such as brightness and edges and become more complex until they reach features that specifically identify the object [15]. There are several hidden layers between a CNN’s input and output layers. These layers carry out operations that alter the data to learn features specific to the data. Convolution, activation (or ReLU), and pooling are the most used layers. The Conv layer is a Convolutional Network’s core building block that does most of the computational heavy lifting. With convolution, convolutional filters are applied to the input images, activating different aspects of the images. By setting negative values to zero and keeping positive values constant, an activation function facilitates faster and more effective training because only the activated characteristics are carried over to the following layer; this is frequently referred to as activation. Pooling reduces the number of parameters the network needs to learn by conducting nonlinear downsampling on the output. Over tens or hundreds of layers, these operations are repeated while each layer learns to recognize various features. The output for the final classification is provided by a classification layer in the CNN architecture’s top layer [15].
2.1. Commonly Used CNN Architectures for Image Classification
This section overviews the most commonly used CNN architectures in the image classification task. Researchers have proposed deep-learning-based skin cancer detection systems based on these architectures.
2.2. AlexNet
Krizhevsky et al. [16] proposed an AlexNet, a CNN network that consists of five convolutions and three fully connected layers [17] as shown in Figure 2. AlexNet was trained using 60 million parameters and solved an overfitting problem using dropout layers. AlexNet achieved top-1 and top-5 error rates of 37.5% and 17.0% on ImageNet LSVRC-2010.
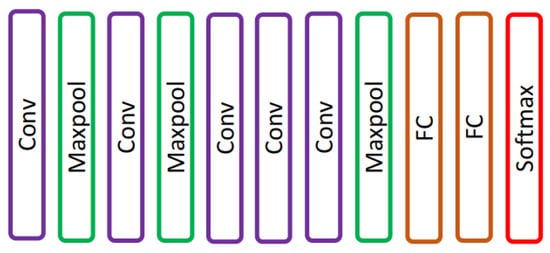
Figure 2. AlexNet network presented in [16].
2.3. VGG
VGG is a convolutional architecture proposed by Karen Simonyan and Andrew Zisserman of the Visual Geometry Group, Oxford University. The VGG-16 [18] model achieved 92.7% top-5 test accuracy on an ImageNet [19] dataset that contains 14 million images of 1000 classes. Simonyan and Zisserman [18] replaced large-size kernel filters with several 3 × 3 kernel-sized filters, achieving better performance than AlexNet. VGG has different variants depending on the number of convolution layers; the most common VGG architectures are VGG-16 and VGG-19. The architecture of VGG-16 is shown in Figure 3. VGG-16 comprised thirteen convolution layers, a max-pooling layer, three fully connected layers, and the output layer.
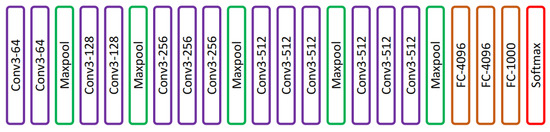
Figure 3. VGG-16 network presented in [18].
2.4. ResNet
AlexNet won an ImageNet 2012 competition consisting of eight layers. In deep learning, more layers are added to improve performance and minimize the error rate. Adding more layers results in a vanishing gradient in which the gradient becomes zero and exploding gradient in which the gradient becomes too large. He et al. [20] solved the problem of exploding and vanishing gradients by introducing a concept of skip connections. The skip connection bypasses some levels in between to link layer activations to subsequent layers to make residual blocks stacked together to create a ResNet architecture. The layer causing a problem during training can be skipped avoiding exploding and vanishing gradients, and helps train deep neural networks. ResNet architecture is shown in Figure 4.
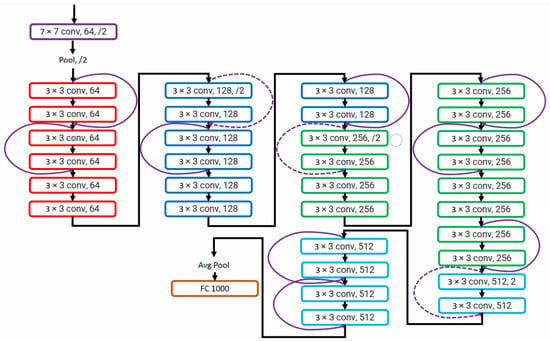
Figure 4. ResNet network presented in [20].
2.5. DenseNet
Huang et al. [21] presented a densely connected convolution network in which each layer was connected to every other layer as shown in Figure 5. In DenseNet, all previous layers’ feature maps are utilized as inputs for each layer, and that layer’s feature map is used as an input for all layers that come after it. DenseNet architecture helped to solve the vanishing gradient problem and allowed feature reuse. Connecting each layer with every other also helped strengthen feature propagation and decrease the number of parameters required to train a deep neural network.
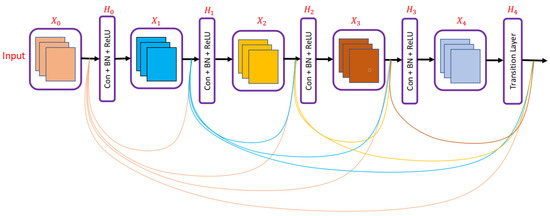
Figure 5. DenseNet network presented in [21].
2.6. MobileNet
Howard et al. [22] presented a lightweight network, MobileNet, for mobile applications. MobileNet replaces the 3×33×3 convolution operation in standard CNN with the 3×33×3 depthwise convolution and 1×11×1 pointwise convolution operation; using depthwise separable convolution operation instead of standard convolution operation helps in reducing the number of training parameters. The difference between standard convolution operation and depthwise separable convolution used in MobileNet is shown in Figure 6.
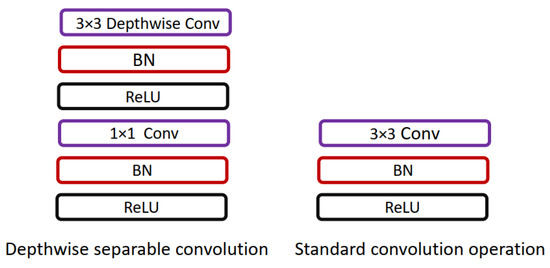
Figure 6. Comparison of standard convolution operation and depthwise separable convolution used in [22].
The most commonly used deep-learning models used in skin cancer analysis are listed in Table 2.
This entry is adapted from the peer-reviewed paper 10.3390/diagnostics13111911
This entry is offline, you can click here to edit this entry!