In the early 2000s, technological advances in genome sequencing and bioinformatics on filamentous fungi began to reveal a discrepancy between the number of biosynthetic gene clusters (BGCs) encoding the biosynthesis of fungal secondary metabolites and the actual number of identified fungal compounds from the target strain. The discovery of cryptic BGCs in microorganisms, including fungi, has spurred the development of new experimental methodologies for identifying the secondary metabolites of these clusters, which led to the realization that they have the potential to produce novel specialized metabolites, giving rise to a new field of research called genome-guided natural product discovery.
- fungi
- biosynthetic gene cluster
- natural products
1. Introduction
2. Organization of Biosynthetic Gene Clusters of Fungi and Their Regulation
3. Characterization of Biosynthetic Gene Clusters and Natural Product Discovery
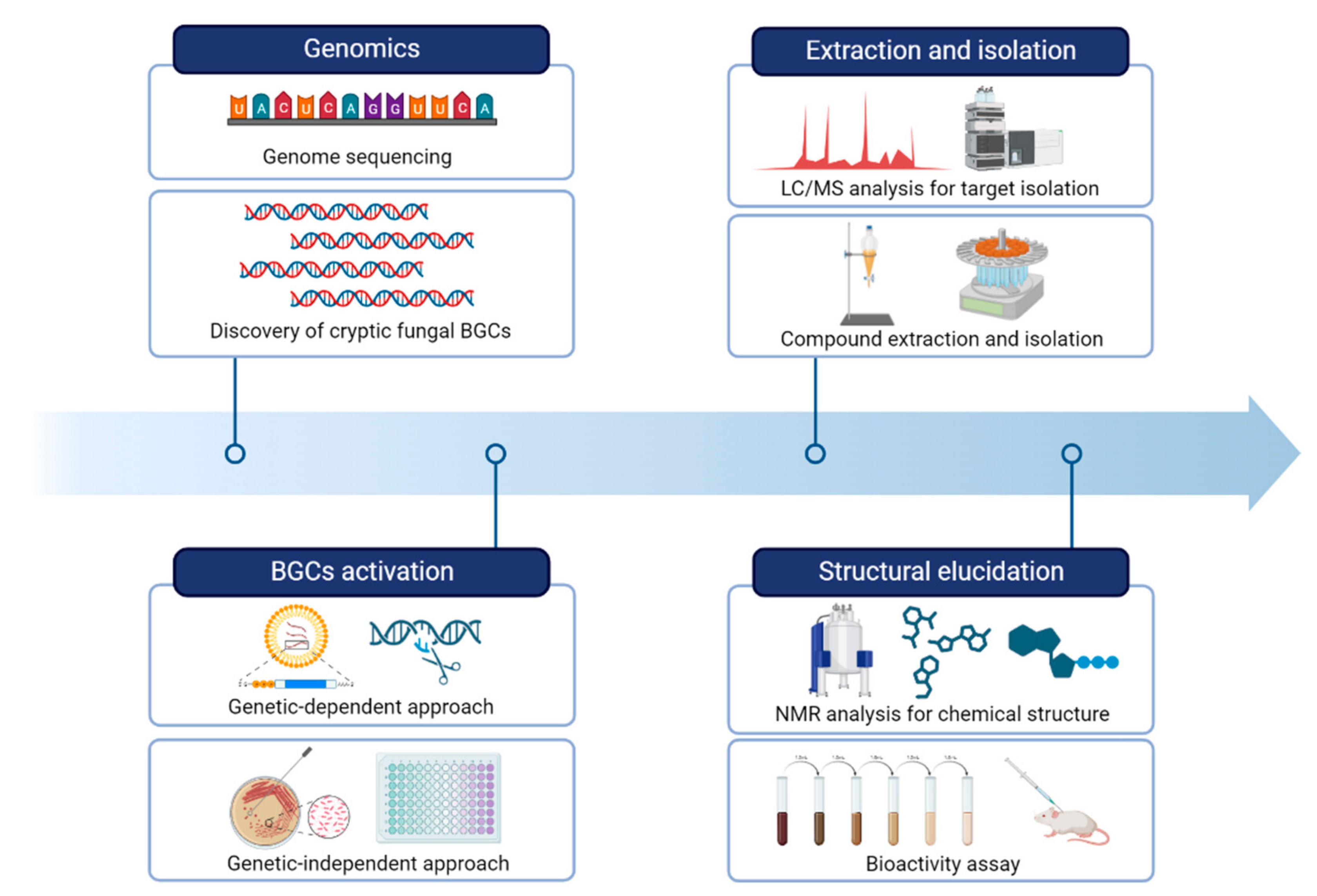
This entry is adapted from the peer-reviewed paper 10.3390/separations10060333
References
- Newman, D.J.; Cragg, G.M. Natural products as sources of new drugs over the nearly four decades from 01/1981 to 09/2019. J. Nat. Prod. 2020, 83, 770–803.
- Newman, D.J.; Cragg, G.M. Natural products as sources of new drugs from 1981 to 2014. J. Nat. Prod. 2016, 79, 629–661.
- Helaly, S.E.; Thongbai, B.; Stadler, M. Diversity of biologically active secondary metabolites from endophytic and saprotrophic fungi of the ascomycete order Xylariales. Nat. Prod. Rep. 2018, 35, 992–1014.
- Demain, A.L. Valuable secondary metabolites from fungi. In Biosynthesis and Molecular Genetics of Fungal Secondary Metabolites; Springer: New York, NY, USA, 2014; pp. 1–15.
- Bills, G.F.; Gloer, J.B. Biologically active secondary metabolites from the fungi. Microbiol. Spectr. 2017, 4, 1087–1119.
- Atanasov, A.G.; Zotchev, S.B.; Dirsch, V.M.; Supuran, C.T. Natural products in drug discovery: Advances and opportunities. Nat. Rev. Drug Discov. 2021, 20, 200–216.
- Fischer, M.S.; Glass, N.L. Communicate and fuse: How filamentous fungi establish and maintain an interconnected mycelial network. Front. Microbiol. 2019, 10, 619.
- Dias, D.A.; Urban, S.; Roessner, U. A historical overview of natural products in drug discovery. Metabolites 2012, 2, 303–336.
- Robey, M.T.; Caesar, L.K.; Drott, M.T.; Keller, N.P.; Kelleher, N.L. An interpreted atlas of biosynthetic gene clusters from 1000 fungal genomes. Proc. Natl. Acad. Sci. USA 2021, 118, e2020230118.
- Clevenger, K.D.; Bok, J.W.; Ye, R.; Miley, G.P.; Verdan, M.H.; Velk, T.; Chen, C.; Yang, K.; Robey, M.T.; Gao, P. A scalable platform to identify fungal secondary metabolites and their gene clusters. Nat. Chem. Biol. 2017, 13, 895–901.
- Hoskisson, P.A.; Seipke, R.F. Cryptic or silent? The known unknowns, unknown knowns, and unknown unknowns of secondary metabolism. MBio 2020, 11, e02642-20.
- Amos, G.C.; Awakawa, T.; Tuttle, R.N.; Letzel, A.-C.; Kim, M.C.; Kudo, Y.; Fenical, W.; Moore, B.S.; Jensen, P.R. Comparative transcriptomics as a guide to natural product discovery and biosynthetic gene cluster functionality. Proc. Natl. Acad. Sci. USA 2017, 114, E11121–E11130.
- Honda, S.; Eusebio-Cope, A.; Miyashita, S.; Yokoyama, A.; Aulia, A.; Shahi, S.; Kondo, H.; Suzuki, N. Establishment of Neurospora crassa as a model organism for fungal virology. Nat. Commun. 2020, 11, 5627.
- Keller, N.P. Fungal secondary metabolism: Regulation, function and drug discovery. Nat. Rev. Microbiol. 2019, 17, 167–180.
- Dunlap, J.C.; Borkovich, K.A.; Henn, M.R.; Turner, G.E.; Sachs, M.S.; Glass, N.L.; McCluskey, K.; Plamann, M.; Galagan, J.E.; Birren, B.W. Enabling a community to dissect an organism: Overview of the Neurospora functional genomics project. Adv. Genet. 2007, 57, 49–96.
- Liu, Z.; Lin, Z.; Nielsen, J. Expression of fungal biosynthetic gene clusters in S. cerevisiae for natural product discovery. Synth. Syst. Biotechnol. 2021, 6, 20–22.
- Reen, F.J.; Romano, S.; Dobson, A.D.; O’Gara, F. The sound of silence: Activating silent biosynthetic gene clusters in marine microorganisms. Mar. Drugs 2015, 13, 4754–4783.
- Almeida, H.; Tsang, A.; Diallo, A.B. Improving candidate Biosynthetic Gene Clusters in fungi through reinforcement learning. Bioinformatics 2022, 38, 3984–3991.
- Mózsik, L.; Iacovelli, R.; Bovenberg, R.A.; Driessen, A.J. Transcriptional activation of biosynthetic gene clusters in filamentous fungi. Front. Bioeng. Biotechnol. 2022, 10, 1199.
- Chiang, Y.-M.; Szewczyk, E.; Nayak, T.; Davidson, A.D.; Sanchez, J.F.; Lo, H.-C.; Ho, W.-Y.; Simityan, H.; Kuo, E.; Praseuth, A. Molecular genetic mining of the Aspergillus secondary metabolome: Discovery of the emericellamide biosynthetic pathway. Chem. Biol. 2008, 15, 527–532.
- Drott, M.; Bastos, R.; Rokas, A.; Ries, L.; Gabaldón, T.; Goldman, G.; Keller, N.; Greco, C. Diversity of secondary metabolism in Aspergillus nidulans clinical isolates. Msphere 2020, 5, e00156-20.
- Scherlach, K.; Hertweck, C. Mining and unearthing hidden biosynthetic potential. Nat Commun. 2021, 12, 3864.
- Machado, H.; Tuttle, R.N.; Jensen, P.R. Omics-based natural product discovery and the lexicon of genome mining. Curr. Opin. Microbiol. 2017, 39, 136–142.
- Kwon, M.J.; Steiniger, C.; Cairns, T.C.; Wisecaver, J.H.; Lind, A.L.; Pohl, C.; Regner, C.; Rokas, A.; Meyer, V. Beyond the biosynthetic gene cluster paradigm: Genome-wide coexpression networks connect clustered and unclustered transcription factors to secondary metabolic pathways. Microbiol. Spectr. 2021, 9, e00898-21.
- Medema, M.H.; Cimermancic, P.; Sali, A.; Takano, E.; Fischbach, M.A. A systematic computational analysis of biosynthetic gene cluster evolution: Lessons for engineering biosynthesis. PLoS Comput. Biol. 2014, 10, e1004016.
- Calvo, A.M.; Wilson, R.A.; Bok, J.W.; Keller, N.P. Relationship between secondary metabolism and fungal development. Microbiol. Mol. Biol. Rev. 2002, 66, 447–459.
- Manzoni, M.; Rollini, M. Biosynthesis and biotechnological production of statins by filamentous fungi and application of these cholesterol-lowering drugs. Appl. Microbiol. Biotechnol. 2002, 58, 555–564.
- Gluck-Thaler, E.; Haridas, S.; Binder, M.; Grigoriev, I.V.; Crous, P.W.; Spatafora, J.W.; Bushley, K.; Slot, J.C. The architecture of metabolism maximizes biosynthetic diversity in the largest class of fungi. Mol. Biol. Evol. 2020, 37, 2838–2856.
- Arnison, P.G.; Bibb, M.J.; Bierbaum, G.; Bowers, A.A.; Bugni, T.S.; Bulaj, G.; Camarero, J.A.; Campopiano, D.J.; Challis, G.L.; Clardy, J. Ribosomally synthesized and post-translationally modified peptide natural products: Overview and recommendations for a universal nomenclature. Nat. Prod. Rep. 2013, 30, 108–160.
- Le Govic, Y.; Papon, N.; Le Gal, S.; Bouchara, J.-P.; Vandeputte, P. Non-ribosomal peptide synthetase gene clusters in the human pathogenic fungus Scedosporium apiospermum. Front. Microbiol. 2019, 10, 2062.
- Cox, R.J.; Simpson, T.J. Fungal type I polyketide synthases. Methods Enzymol. 2009, 459, 49–78.
- Palmer, J.M.; Keller, N.P. Secondary metabolism in fungi: Does chromosomal location matter? Curr. Opin. Microbiol. 2010, 13, 431–436.
- Tamaru, H. Confining euchromatin/heterochromatin territory: Jumonji crosses the line. Genes Dev. 2010, 24, 1465–1478.
- Lai, Y.; Wang, L.; Zheng, W.; Wang, S. Regulatory roles of histone modifications in filamentous fungal pathogens. J. Fungi 2022, 8, 565.
- Tran, P.N.; Yen, M.-R.; Chiang, C.-Y.; Lin, H.-C.; Chen, P.-Y. Detecting and prioritizing biosynthetic gene clusters for bioactive compounds in bacteria and fungi. Appl. Microbiol. Biotechnol. 2019, 103, 3277–3287.
- Jouhten, P.; Ponomarova, O.; Gonzalez, R.; Patil, K.R. Saccharomyces cerevisiae metabolism in ecological context. FEMS Yeast Res. 2016, 16, fow080.
- Salem-Bango, Z.; Price, T.K.; Chan, J.L.; Chandrasekaran, S.; Garner, O.B.; Yang, S. Fungal whole-genome sequencing for species identification: From test development to clinical utilization. J. Fungi 2023, 9, 183.
- Blin, K.; Shaw, S.; Kloosterman, A.M.; Charlop-Powers, Z.; Van Wezel, G.P.; Medema, M.H.; Weber, T. antiSMASH 6.0: Improving cluster detection and comparison capabilities. Nucleic Acids Res. 2021, 49, W29–W35.
- Kautsar, S.A.; Blin, K.; Shaw, S.; Navarro-Muñoz, J.C.; Terlouw, B.R.; Van Der Hooft, J.J.; Van Santen, J.A.; Tracanna, V.; Suarez Duran, H.G.; Pascal Andreu, V. MIBiG 2.0: A repository for biosynthetic gene clusters of known function. Nucleic Acids Res. 2020, 48, D454–D458.
- Russell, A.H.; Truman, A.W. Genome mining strategies for ribosomally synthesised and post-translationally modified peptides. Comput. Struct. Biotechnol. J. 2020, 18, 1838–1851.
- Alam, K.; Hao, J.; Zhong, L.; Fan, G.; Ouyang, Q.; Islam, M.; Islam, S.; Sun, H.; Zhang, Y.; Li, R. Complete genome sequencing and in silico genome mining reveal the promising metabolic potential in Streptomyces strain CS-7. Front. Microbiol. 2022, 13, 3751.
- Koboldt, D.C.; Steinberg, K.M.; Larson, D.E.; Wilson, R.K.; Mardis, E.R. The next-generation sequencing revolution and its impact on genomics. Cell 2013, 155, 27–38.
- Slatko, B.E.; Gardner, A.F.; Ausubel, F.M. Overview of next-generation sequencing technologies. Curr. Protoc. Mol. Biol. 2018, 122, e59.
- Amarasinghe, S.L.; Su, S.; Dong, X.; Zappia, L.; Ritchie, M.E.; Gouil, Q. Opportunities and challenges in long-read sequencing data analysis. Genome Biol. 2020, 21, 30.
- Louwen, J.J.; Medema, M.H.; van der Hooft, J.J. Enhanced correlation-based linking of biosynthetic gene clusters to their metabolic products through chemical class matching. Microbiome 2023, 11, 13.
- Van Der Hooft, J.J.; Mohimani, H.; Bauermeister, A.; Dorrestein, P.C.; Duncan, K.R.; Medema, M.H. Linking genomics and metabolomics to chart specialized metabolic diversity. Chem. Soc. Rev. 2020, 49, 3297–3314.