Your browser does not fully support modern features. Please upgrade for a smoother experience.
Please note this is an old version of this entry, which may differ significantly from the current revision.
Unsupervised domain adaptation (UDA) is a transfer learning technique utilized in deep learning. UDA aims to reduce the distribution gap between labeled source and unlabeled target domains by adapting a model through fine-tuning. To reduce the domain divergence between the source and target domain, there are mainly two main types of UDA methods that have gained significant attention: discrepancy-based UDA methods and adversarial-based UDA methods.
- domain adaptation
- Image Classification
- Object Detection
1. Introduction
Deep learning has achieved significant success in the field of computer vision in recent years, particularly in image classification and object detection using Convolutional Neural Networks (CNNs). Typically, CNNs are trained with supervised learning using large amounts of labeled data, drawn from an identical distribution for both training and testing the model. However, collecting and labeling data can be very time-consuming, labor-intensive, and expensive, especially for new tasks in various domains. In addition, adequate training samples do not always exist. Furthermore, the training of deep CNNs is domain-specific. The existing models show promising results on the dataset used for training. However, they often fail to generalize well to new, similar domains due to the problem of domain shift [1]. Domain shift arises when the distribution of data in the target domain differs from the source domain, posing a significant challenge for image classification and object detection tasks. This discrepancy can occur due to variations in the visual appearance of the data, which leads to several practical implications for real-world applications in the field of image classification and object detection. For instance, consider an intelligent system to detect objects on the road using CCTV (Closed-Circuit Television) footage captured from various camera sensors. If the training data from each of the camera sensors do not encompass variations in noise characteristics, image resolutions, and different weather conditions, the system’s performance may degrade in the presence of adverse conditions. Similarly, if people train an image classification model on data downloaded from e-commerce websites and test it on real camera images, the model’s performance is likely to be compromised due to differences in image characteristics across different domains, such as intra-class variations, camera angles, lighting conditions, and complex backgrounds. Therefore, there is a need to develop algorithms that can address both label scarcity and domain shift problems. The objective of domain adaptation approaches is to overcome these challenges by learning domain-invariant features to align the data distributions of the source and target domains.
Domain adaptation is a type of transfer learning utilized to train a model with unseen data in the target domain by acquiring knowledge from a related source domain [2]. The source domain refers to the data distribution used to train the model with labeled data for the source task, while the target domain refers to data from another related domain used to fine-tune the pre-trained model to learn the target task. There are three types of domain adaptation approaches: supervised, semi-supervised, and unsupervised [3]. Significant progress has been seen in supervised and semi-supervised domain adaptation, while unsupervised domain adaptation (UDA) has recently gained attention. UDA methods aim to learn a domain-invariant feature space by bridging the labeled source domain and unlabeled target domain, as shown in Figure 1. UDA methods can be divided into two main categories: (i) domain discrepancy-based methods, where domain-invariant features are found by fine-tuning the model and minimizing domain shift using statistical measures, and (ii) adversarial-based methods using a generative model, where domain-invariant features are learned by encouraging domain confusion using a discriminator network. This method is more complex, as the discriminator needs to be trained from scratch, and hence it takes more training time.
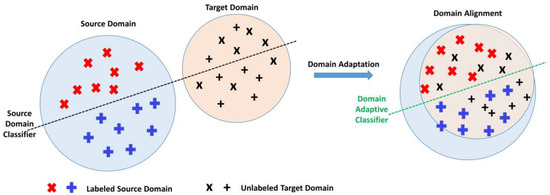
Figure 1. Example of unsupervised domain adaptation; Source domain and the target domain (left) are classified through a source-only classifier with source labeled data and target unlabeled data; Source and target domain (right) are classified after domain adaptation, which aligns the feature distributions of both domains.
Although deep transfer learning-based UDA approaches have seen a lot of success so far, they still face challenges that need to be overcome to improve their performance. The present study mainly focuses on aligning the marginal or conditional distributions and utilizing the pre-trained model for transferability. Transferability depends on the relatedness and size of the source dataset and target dataset. Transferability plays a significant role in fine-tuning the network to improve the performance of the target task; otherwise, negative transfer or overfitting may occur and degrade performance [4]. In domain adaptation, it is unclear how to efficiently fine-tune the model using the feature transferability across the domains. Moreover, the size of the dataset is also not balanced to improve the marginal probability of the task. Additionally, the present study uses various asymmetric statistical distribution measures [5,6,7,8,9]. Furthermore, the majority of current research in object detection utilizes the de-facto object detection model, Faster R-CNN [10], which is a two-stage network.
2. Unsupervised Domain Adaptive Image Classification and Object Detection
The problem of transferring knowledge from a labeled source domain to an unlabeled target domain is said to be solved by unsupervised domain adaptation. Significant research contributions have been put into supervised and semi-supervised domain adaptation methods. In recent years, increasing research efforts are focused on unsupervised domain adaptation methods that use deep learning architectures to improve the performance of image classifiers and object detectors. To reduce the domain divergence between the source and target domain, there are mainly two main types of UDA methods that have gained significant attention: discrepancy-based UDA methods and adversarial-based UDA methods. In this section, it describes recent works on these approaches for domain adaptive image classification and object detection.
2.1. Unsupervised Domain Adaptive Image Classification
2.1.1. Discrepancy-Based Approaches
In discrepancy-based methods, domain adaptation is achieved by minimizing the distance between domain distributions using statistical measures to find domain invariance features.
Ghifary et al. [11] introduced the maximum mean discrepancy (MMD) metric for feedforward neural networks with one hidden layer. The MMD measure reduces the mismatch in the latent space distribution between domain representations. Tzeng et al. [5] employed two AlexNet [12] CNNs in the deep domain confusion network (DDC) for source and target domains with shared weights. An adaptation layer with the MMD metric measures domain difference and optimizes the network for classification loss in the source domain. Long et al. [13] developed the deep adaptation network (DAN) to match marginal distributions across domains by adding adaptation layers and evaluating different kernels. A joint adaptation network (JAN) [14] introduced a joint maximum mean discrepancy (JMMD) and applied it in various domain-specific layers of ResNet-50 [15] to find domain invariance features. Yoo et al. [16] recently presented a weighted MMD model that includes an additional weight for each class in the source domain when the target domain class weights are different. In contrast to MMD, Sun et al. [17] proposed a CORrelation ALignment (CORAL) loss function for deep neural networks, which aligns the second-order statistics across domains and minimizes the domain shift. The Contrastive Adaptation Network (CAN) [7] utilized a new metric contrastive domain discrepancy (CCD), which optimizes the intra- and inter-class discrepancy across the domains and trains the CAN in an end-to-end manner. Lee et al. [18] used the task-specific decision boundary in unsupervised domain adaptation to align feature distributions across domains using sliced Wasserstein discrepancy (SWD). Deng et al. [19] proposed a similarity-guided constraint (SGC) in the form of a triplet loss, which is integrated into the network as an additional objective term to optimize the network. Ref. [20] introduced the balanced weight joint geometrical and statistical alignment (BW-JGSA) for UDA to minimize the distribution divergence between marginal and conditional distributions across domains. In order to discover domain-invariant feature representations, Xie et al. [21] used the Wasserstein distance between the two distributions collaboratively and presented the collaborative alignment framework (CAF) to minimize the global domain discrepancy and retain the local semantic consistency. Wang et al. [22] proposed the manifold dynamic distribution adaptation (MDDA) to learn the domain-invariant transfer classifier in the target domain using the Grassmann manifold.
2.1.2. Adversarial-Based Approaches
Adversarial-based methods train discriminator networks to confuse the domain distributions. The domain-adversarial neural network (DANN) was first introduced in [23] for use in adversarial training by a gradient reversal layer (GRL). DANN uses shared feature extraction layers to reduce label prediction loss and GRL to maximize domain confusion loss. Adversarial discriminative domain adaptation (ADDA) [24] unties the weights and initializes the target model parameters with the pre-trained source model. Learning domain-specific feature extractions makes ADDA more adaptable. ADDA minimizes source and target representation distances by iteratively reducing the generative adversarial network (GAN)-based loss function. Cao et al. presented the selective adversarial network (SAN) [25] to handle transfer learning for small domains by filtering outlier source classes and matching data distributions in the common label space by separating the domain discriminator into several class-wise domain discriminators, which reduces negative transfer and promotes positive transfer. In [26], the feature generator is learned by augmenting the source domain data, and the minimax algorithm is employed to find the domain invariant feature. Wasserstein distance is used to measure domain distance in the discriminator by Shen et al. [9]. and improved the feature extractor network to find the invariant features in an adversarial manner. In [27], a feature extractor generates target features that are similar to the source, while discriminators are trained to increase the discrepancy to recognize target samples outside the source’s support. Zhang et al. [28] introduced Domain-Symmetric Networks (SymNets) for domain adaptation. SymNet was built on the symmetric source and target task classifiers and an extra classifier that shares layer neurons. They proposed a unique adversarial learning method based on a two-level domain confusion method to train the SymNet. The category-level confusion loss tried to reduce the object-level loss by forcing intermediate network features to be invariant. The Hierarchical Gradient Synchronization Domain Adaptation (GSDA) [29] method was presented to align the domain hierarchically including global alignment and local alignment. Local alignment is performed using class-wise alignment. In [30], the authors employed a Hybrid Adversarial Network (HAN) with a classification loss to train the discriminative classifier using adversarial training to find the transferable features across domains. To improve target discrimination, structural regularization deep clustering (SRDC) [31] combines the clustering of features of an intermediate network with structural regularisation and a soft selection of less dissimilar source samples. Na et al. [32] provided a solution by augmenting several intermediate domains using a fixed ratio-based mixup approach to bridge the source and target domains (FixBi). They trained the source-leading and target-leading models that shared common characteristics. Pei et al. [33] introduced a multi-adversarial domain adaptation (MADA) technique to leverage multiple domain discriminators to capture the fine-grained alignment of multimodal structures of the source and target domains. Pinheiro et al. [34] presented an end-to-end similarity learning network (SimNets) method to learn a pairwise similarity function for evaluating the similarity between prototype representations of each class. Long et al. [35] proposed a conditional domain adversarial network (CDAN) that uses multilinear conditioning to capture the cross-covariance between feature representations for discriminability and classifier predictions for classification. Chen et al. [36] introduced the discriminator-free adversarial learning network (DALN), which can use the predicted discriminative information for feature alignment and employs nuclear-norm Wasserstein discrepancy (NWD) for performing discrimination. Table 1 presents a comparative summary of the existing state-of-the-art methods of domain adaptation for image classification.
Table 1. Comparative summary of the existing domain adaptive image classification methods.
| Method | Type of Domain Adaptation | Base Network | Loss | Datasets | Year | ||
| Office-31 [37] | Office-Home [38] | Digits (MNIST [39]/USPS [40]) |
|||||
| DDC [5] | Discrepancy-based | AlexNet | MMD | ✓ | - | - | 2014 |
| DAN [13] | Discrepancy-based | AlexNet | MK-MMD | ✓ | - | - | 2015 |
| DANN [23] | Adversarial-based | AlexNet | GAN-based Discriminator |
✓ | - | ✓ | 2015 |
| CORAL [17] | Discrepancy-based | AlexNet | CORAL | ✓ | - | - | 2016 |
| ADDA [24] | Adversarial-based | AlexNet & ResNet-50 |
GAN-based Discriminator |
✓ | - | ✓ | 2017 |
| JAN [14] | Discrepancy-based | ResNet-50 | JMMD | ✓ | - | - | 2017 |
| CDAN [35] | Discrepancy-based | ResNet-50 | Conditional- based Discriminator |
✓ | ✓ | ✓ | 2018 |
| MADA [33] | Adversarial-based | ResNet-50 | GAN-based Discriminator |
✓ | - | - | 2018 |
| SimNets [34] | Adversarial-based | ResNet-50 | GAN-based Discriminator |
✓ | - | ✓ | 2018 |
| CAN [7] | Discrepancy-based | ResNet-50 | CCD | ✓ | - | - | 2019 |
| SymNets [28] | Adversarial-based | ResNet-50 | GAN-based domain confusion |
✓ | ✓ | - | 2019 |
| SGC [19] | Discrepancy-based | ResNet-50 | JMMD | ✓ | ✓ | ✓ | 2020 |
| MDDA [22] | Discrepancy-based | ResNet-50 | MMD | ✓ | ✓ | ✓ | 2020 |
| HAN [30] | Discrepancy & Adversarial-based | ResNet-50 | CORAL and GAN-based Discriminator | ✓ | ✓ | - | 2020 |
| GSDA [29] | Adversarial-based | ResNet-50 | Global and local Adversarial Discriminator | ✓ | ✓ | - | 2020 |
| SRDC [31] | Adversarial-based | ResNet-50 | Clustering-based Discriminator |
✓ | ✓ | - | 2020 |
| FixBi [32] | Adversarial-based | ResNet-50 | Augmentation | ✓ | ✓ | - | 2021 |
| CAF [21] | Discrepancy-based | ResNet-50 | Wasserstein distance | ✓ | - | - | 2022 |
| DALN [36] | Adversarial-based | ResNet-50 | NWD-based Discriminator |
✓ | ✓ | - | 2022 |
2.2. Unsupervised Domain Adaptive Object Detection
In past decades, CNN-based object detection methods have shown significant improvements applied to various datasets and have been successfully utilized in many computer vision applications. Object detection algorithms are categorized into two-stage [10,41,42] and one-stage [43,44,45] object detectors. These object detection algorithms require the annotated datasets and obtain marginal reductions in performance when applied to another domain with the same label space. Recently, research efforts have been focused on aligning domains for object detection tasks.
Chen et al. [46] proposed the first-of-its-kind domain-adaptive object detection algorithm using Faster R-CNN with adversarial feature adaptation to minimize distribution divergence at the image and instance levels. Saito et al. [47] employed strong local and weak global alignments to propose strong-weak distribution alignment (SWDA) for shallow receptive fields and image-level features on deep convolutional layers respectively.
Zhu et al. [48] aligned the region proposal generated by the Faster R-CNN detectors from the source and target domain by applying the k-means clustering algorithm using selective cross-domain alignment (SCDA). Zheng et al. [49] performed adversarial feature learning with the coarse-to-fine adaptation (CFA) approach by proposing the attention-based region transfer (ART) and prototype-based semantic alignment (PSA) to learn domain invariant features. In [50], the authors applied image-level alignment at multiple layers of the backbone network and trained it using an adversarial manner with the multi-adversarial Faster R-CNN (MAF) framework. Kim et al. [51] trained the domain adaptive object detector by augmenting the samples from both domains and learned the domain invariant features across the domains. Conditional Domain Normalization (CDN) is introduced to reduce the domain divergence between the domains in [52]. CDN encodes characteristics from different domains into a latent space with the same domain attribute. It is applied in multiple convolutional layers of the detection model to align the domains. A Hierarchical Transferability Calibration Network (HTCN) is employed by Chen et al. [53] to learn the transferability and discriminability of feature representations hierarchically. They proposed three components consisting of Weighted Adversarial Training, Context-aware Instance-Level Alignment, and local feature masks. Rodriguez et al. [54] proposed domain adaptive object detection using the style consistency (ODSC) framework based on SSD [43] and trained the framework with the style transfer method for pixel-level adaptation and pseudo labeling to reduce the negative samples from the unlabeled target domain. Wang et al. [55] introduced the sequence feature alignment (SFA) technique on the deformable detection transformer (DefDETR) network [45] to adapt the domain discriminative features. The SFA comprises two distinct modules: a token-wise feature alignment (TDA) module and a domain query-based feature alignment (DQFA) module. Zhou et al. [56] utilized the multi-granularity alignment (MGA) with three-level domain alignment losses to learn the domain-invariant features between the domains including pixel-level, instance-level, and category-level. The MGA method has been developed based on faster R-CNN and fully convolutional one-stage (FCOS) [44] backbone detectors. Gong et al. [57] introduced the O2net method with the object-aware alignment (OAA) and optimal transport-based alignment (OTA) modules to apply pixel and instance levels domain alignment loss. Table 2 summarizes the existing state-of-the-art methods for domain adaptation in object detection.
Table 2. Comparative summary of the existing domain adaptive object detection methods.
| Method | Detection Network | Loss | Datasets | Year | ||
| Cityscapes [58] | Foggy Cityscapes [58] | KITTI [59] | ||||
| DA-Faster [46] | Faster R-CNN | H-divergence based Discriminator |
✓ | ✓ | ✓ | 2018 |
| SWDA [47] | Faster R-CNN | Weak Global and Strong local Feature Alignment | ✓ | ✓ | ✓ | 2019 |
| SCDA [48] | Faster R-CNN | Region-Level Adversarial Alignment | ✓ | ✓ | - | 2019 |
| CFA [49] | Faster R-CNN | Prototype-based Semantic Alignment | ✓ | ✓ | ✓ | 2020 |
| MAF [50] | Faster R-CNN | Adversarial domain alignment loss | ✓ | ✓ | ✓ | 2019 |
| CDN [52] | Faster R-CNN | CDN-based adversarial loss | ✓ | ✓ | ✓ | 2020 |
| HTCN [53] | Faster R-CNN | Pixel-wise adversarial loss | ✓ | ✓ | - | 2020 |
| ODSC [54] | SSD | Pseudo Labels and Style Transfer alignment | ✓ | ✓ | - | 2020 |
| SFA [55] | DefDETR | Token-wise and Hierarchical Sequence Feature Alignment loss | ✓ | ✓ | - | 2021 |
| MGA [56] | Faster R-CNN & FCOS | Pixel-level, instance-level, and category-level. | ✓ | ✓ | ✓ | 2022 |
| O2net [57] | DefDETR | Pixel- and instance-level | ✓ | ✓ | - | 2022 |
This entry is adapted from the peer-reviewed paper 10.3390/s23094436
This entry is offline, you can click here to edit this entry!