Your browser does not fully support modern features. Please upgrade for a smoother experience.
Please note this is an old version of this entry, which may differ significantly from the current revision.
The increasing use of deep learning techniques to manipulate images and videos, commonly referred to as “deepfakes”, is making it more challenging to differentiate between real and fake content, while various deepfake detection systems have been developed, they often struggle to detect deepfakes in real-world situations. In particular, these methods are often unable to effectively distinguish images or videos when these are modified using novel techniques which have not been used in the training set.
- deepfake detection
- deep learning
- computer vision
1. Introduction
Deep Learning has greatly impacted society, leading to impressive advancements in various fields. However, its use can also have negative consequences, for example, the creation of deepfakes. Deepfakes are manipulated images or videos that depict subjects in ways they never actually were, which can harm reputations or manipulate reality. Indeed, although deepfakes have numerous potential applications in the fields of entertainment, art, and education, they also pose significant security and ethical risks. For this reason, it is crucial to continue the development of robust deepfake detection methods to counteract such a threat. To tackle this problem, researchers have developed deepfake detection techniques, which are usually based on deep learning as well. These methods try to identify any traces introduced during the manipulation process, but they require large amounts of data for training. Furthermore, deepfakes are generated by resorting to different typologies of techniques and/or procedures (often even unknown) that emerge almost daily, so it is not possible to follow each methodology and consequently to re-adapt the training phase. On this basis, to have more effective deepfake detectors, researchers aim for a system that can generalize the concept of deepfakes and identify them regardless of the manipulation technique used, even if it is novel and not present in the training data. During training, a huge amount of heterogeneous data are needed to provide to the models in order for them to see enough forms of deepfakes to stimulate them to abstract and generalize. A comparison was made among different deep learning architectures in order to validate their generalization capabilities, specifically against deepfake videos. It is worth saying that techniques used to manipulate videos do not necessarily introduce the same anomalies and features that can be embedded when tampering with still images.
2. Experiments
2.1. General Setup
The experiments conducted are divided into two parts. In the first part, researchers used frames from pristine videos and manipulated frames from fake videos generated with one deepfake generation method at a time to compose a training set. Each obtained model is then tested against frames extracted from videos manipulated with the same generation methodology used at training time but also against other methods not seen during the training phase in order to investigate the generalization capacity of the different architectures. The classification task is always conducted frame-by-frame.
portion, consistent for all models, was randomly selected from the training set and referred to as the validation set. The models were trained for up to 50 epochs with a patience of 5 epochs on the validation set, using the Binary Cross Entropy Loss (BCE) and an SGD optimizer with a learning rate of 0.1 that decreases with a step size of 15 and a gamma of 0.1.
2.2. Single Method Training
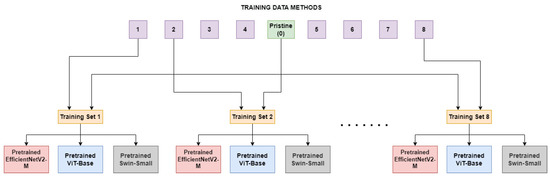
In this section, researchers outline the process used to examine a model’s ability to recognize images manipulated by various deepfake generation methods, despite being trained on real images and images manipulated with only one deepfake method. In the first comparison, the three models under consideration, namely EfficientNetV2-M, ViT-Base, and Swin-Small, were fine-tuned on each of the eight sub-datasets as illustrated in Figure 1. These sub-datasets consisted of both unaltered frames and frames manipulated using specific techniques, specifically FaceShifter(1), FS-GAN(2), DeepFakes(3), BlendFace(4), MMReplacement(5), DeepFakes-StarGAN-Stack(6), Talking-Head Video(7), and ATVG-Net(8). As displayed in Table 1, the sizes of the datasets vary quite largely. Pristine frames are most common within the dataset so, to ensure a good balance without sacrificing too many of them, a subset equal to the number of fake frames of the method under training is randomly selected at each epoch. In this experiment, the models will only encounter, during the training, anomalies generated by one specific deepfake method at a time. This may cause a tendency in the models to learn that a video is manipulated only when some specific artifacts occur, causing a lack of generalization. To validate this and discover architectures’ limitations, the models trained on the sub-datasets were then tested on frames in the test set, including those manipulated by methods not used during training.
Figure 1. The Single Method Training setup: eight different training sets are constructed, each consists of frames manipulated with a deepfake generation method and pristine frames.
Table 1. Number of frames for Single Methods Training and Test setup.
| Video Manipulation Methods | Training Frames | Test Frames |
|---|---|---|
| 0 (Pristine) | 118,255 | 47,369 |
| 1 (FaceShifter) | 13,337 | 1889 |
| 2 (FS-GAN) | 48,122 | 8732 |
| 3 (DeepFakes) | 8550 | 1157 |
| 4 (BlendFace) | 9827 | 1335 |
| 5 (MMReplacement) | 270 | 115 |
| 6 (DeepFakes-StarGAN-Stack) | 3610 | 509 |
| 7 (Talking-Head Video) | 26,338 | 2199 |
| 8 (ATVG-Net) | 37,449 | 5383 |
2.3. Multiple Methods Training
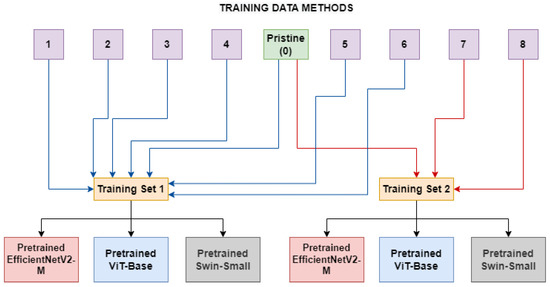
A second experiment has been conducted by training the models on real frames and frames manipulated using a group of methods belonging to the same category (ID-Replaced or ID-Remained), as shown in Figure 2. This was examined to determine if the networks can better generalize in the presence of diverse categories of manipulation methods, which may introduce a greater variety of artifacts. Hopefully, the models trained in this setup will need to abstract the concept of deepfake to a level which is not highly related to the seen artifacts.
Figure 2. The Multiple Method Training setup: two different training sets are constructed, each consists of frames manipulated with deepfake generation methods related to the same category (blue lines for ID-Replaced and red lines for ID-Remained) and pristine frames.
In Table 2, the sizes, in terms of available frames, of the two different categories can be seen. As depicted in Figure 2, two models (for each network architecture) have been trained: the first one (ID-Replaced) is based on frames crafted by using methods belonging to the ID-Replaced category (methods from 1 to 6), while the second one (ID-Remained) is based on those ones coming from the ID-Remained category (methods 7 and 8). In both of them, also pristine images from unaltered videos are added to the training dataset.
Table 2. Number of frames for Multiple Methods Training and Test.
| Video Manipulation Categories | Training Frames | Test Frames |
|---|---|---|
| 0 (Pristine) | 118,255 | 47,369 |
| ID-Replaced | 83,716 | 13,737 |
| ID-Remained | 63,787 | 7582 |
3. Single Method Training
Figure 3 shows the accuracies achieved by the three considered models trained in the Single Method Training setup, presented in the previous section, with respect to each of the methods comprised within the test set. Looking at the accuracies of the three models, it can be pointed out that the EfficientNetV2-M and the Swin-Small maintain results often above 80%
in correspondence of test frames manipulated with the same methods used in the training set (as expected) and, at the same time, obtain a certain degree of generalization. In fact, the same models sometimes succeed in detecting frames manipulated with methods unseen during training, although only reaching values of accuracy that are quite limited. The case of method number 5 (MMReplacement) is rather anomalous, though the detection percentage is often very high indeed; this behaviour is probably induced by the low number of available examples (see Table 1).
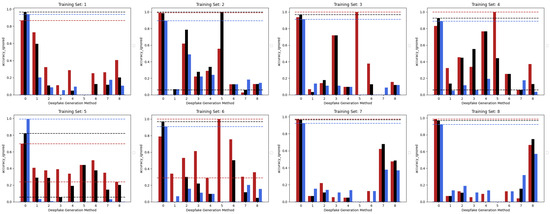
Figure 3. The performance in terms of accuracy achieved by each of the three considered models with respect to the eight different training sets following the Single Method Training setup: EfficientNetV2-M (red), Swin-Small (black), and ViT-Base (blue).
On the contrary, it can be easily noticed that, in all the cases, the ViT-Base is substantially unable to learn in the presence of relatively few training images. In fact, for instance, by training the model on methods 3, 4, 5, and 6 and then testing it on the test set, it is evident that the model is substantially underfitting and practically unusable compared to the two others taken into consideration. Interestingly, the Swin Transformer, although also based on the attention mechanism, is not particularly affected by this phenomenon and instead succeeds in obtaining competitive results in all contexts. This probably lies in the hierarchical nature that emulates the convolutional layers of traditional CNNs and thus allows it to exploit implicit inductive biases better. Good performances are preserved, in any case, with respect to pristine frame detection. In this setup, the architecture based on a convolutional network seems to prove more capable of generalization. The accuracies obtained from the three models are also shown in the confusion matrices in Figure 4 where all previously commented trends are reconfirmed again.
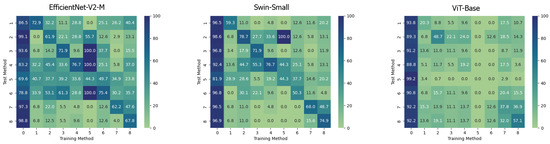
Figure 4. Confusion matrices of the frame-level accuracy values for the three models under consideration trained in the Single Method Training setup and tested on frames manipulated with all the available methods, respectively.
4. Multiple Methods Training
The behaviour of the three networks is now analysed in the second considered setup, namely Multiple Methods Training, and corresponding results are shown in Figure 5. In this case, the datasets are composed of frames extracted from videos manipulated by not only one method, so the models will have more difficulty focussing on specific artifacts and be forced to generalize. In this setup, the situation is significantly different from the previous one. Surprisingly, the classic Vision Transformer, which previously struggled to train effectively, is now the only model capable of generalizing well to frames that have been manipulated using techniques that were not present in the training data. This result probably stems from the fact that the training set consists of significantly more images than in the previous setup and it is strongly in line with what is presented in [1]. This particular architecture shows in many contexts a major need for data and resources which, when available, enable it to achieve very competitive results. In this case, the confusion matrices (see Figure 6) clearly show the greater generalization capacity of the Vision Transformer although at the expense of more false positives. In fact, the “pristine” class is less accurately classified by this latter. This may be a problem since in a real-world context researchers may want to reduce as much as possible the number of false alarms, in particular, if the system is fully automated.
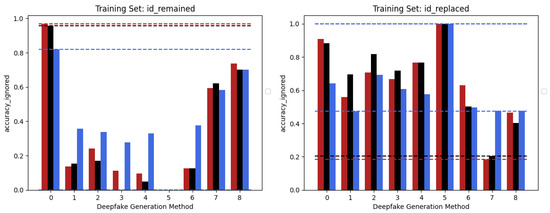
Figure 5. Accuracy performances achieved by each of the models considered in the two different training sets constructed following the Multiple Methods Training setup: EfficientNetV2-M (red), Swin-Small (black), and ViT-Base (blue). ID-Replaced methods (1–6), ID-Remained methods (7–8), and Pristine (0).
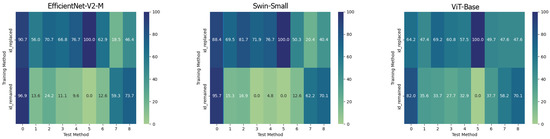
Figure 6. Confusion matrices of the frame-level accuracy of the three models trained in the Multiple Method Training setup and tested on frames manipulated with all available methods.
5. Cross-Dataset Evaluation
To further evaluate the generalization capability of the trained models researchers also tested them in a cross-dataset context. In particular, researchers considered the three architectures trained on videos manipulated with ID-Remained or with ID-Replaced methods (ForgeryNet dataset) and tested on the well-known DFDC Preview test set. Researchers report the AUC values of the trained models compared with previous works in the literature. This is probably the most challenging scenario since both the contexts and the manipulation methods are significantly different, and indeed the performances of the models are pretty low. In particular, the EfficientNets are totally incapable of detecting these deepfakes with a very low AUC value. On the other hand, attention-based methods manifest better performances even if, as expected, they are worse than other, more complicated and articulated, methods in the literature. The Swin-Small trained on the videos manipulated with ID-Replaced methods perform pretty well with an AUC of 71.2%, demonstrating a good level of generalization. Again, also in this context, it seems that attention may be the key to achieve better generalization performances while the considered CNN is in any case too tied with the methods seen during training. Furthermore, the trained models which achieve better performances are the ones trained on a more complete and heterogeneous dataset, namely the videos manipulated with ID-Replaced methods, highlighting again the need for these architectures for a huge amount of data.
This entry is adapted from the peer-reviewed paper 10.3390/jimaging9050089
References
- Coccomini, D.A.; Caldelli, R.; Falchi, F.; Gennaro, C.; Amato, G. Cross-Forgery Analysis of Vision Transformers and CNNs for Deepfake Image Detection. In Proceedings of the 1st International Workshop on Multimedia AI against Disinformation, New York, NY, USA, 27–30 June 2022; pp. 52–58.
This entry is offline, you can click here to edit this entry!