Your browser does not fully support modern features. Please upgrade for a smoother experience.
Please note this is a comparison between Version 1 by Qiang Fu and Version 2 by Lindsay Dong.
Image segmentation, which has become a research hotspot in the field of image processing and computer vision, refers to the process of dividing an image into meaningful and non-overlapping regions, and it is an essential step in natural scene understanding.
- image segmentation
- co-segmentation
- semantic segmentation
- deep learning
- image processing
1. Introduction
Image segmentation is one of the most popular research fields in computer vision, and forms the basis of pattern recognition and image understanding. The development of image segmentation techniques is closely related to many disciplines and fields, e.g., autonomous vehicles [1], intelligent medical technology [2][3][2,3], image search engines [4], industrial inspection, and augmented reality.
Image segmentation divides images into regions with different features and extracts the regions of interest (ROIs). These regions, according to human visual perception, are meaningful and non-overlapping. There are two difficulties in image segmentation: (1) how to define “meaningful regions”, as the uncertainty of visual perception and the diversity of human comprehension lead to a lack of a clear definition of the objects, it makes image segmentation an ill-posed problem; and (2) how to effectively represent the objects in an image. Digital images are made up of pixels, that can be grouped together to make up larger sets based on their color, texture, and other information. These are referred to as “pixel sets” or “superpixels”. These low-level features reflect the local attributes of the image, but it is difficult to obtain global information (e.g., shape and position) through these local attributes.
2. Classic Segmentation Methods
The classic segmentation algorithms were proposed for grayscale images, which mainly consider gray-level similarity in the same region and gray-level discontinuity in different regions. In general, region division is based on gray-level similarity, and edge detection is based on gray-level discontinuity. Color image segmentation involves using the similarity between pixels to segment the image into different regions or superpixels, and then merging these superpixels.2.1. Edge Detection
The positions where the gray level changes sharply in an image are generally the boundaries of different regions. The task of edge detection is to identify the points on these boundaries. Edge detection is one of the earliest segmentation methods and is also called the parallel boundary technique. The derivative or differential of the gray level is used to identify the obvious changes at the boundary. In practice, the derivative of the digital image is obtained by using the difference approximation for the differential. Examples of edge detection results are represented in Figure 12.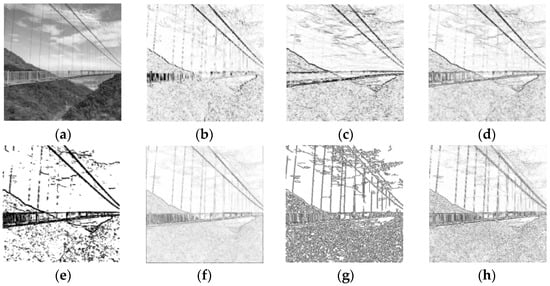
Figure 12.
Edge detection results of different differential operators. (
a
) Original (
b
) SobelX (
c
) SobelY (
d
) Sobel (
e
) Kirsch (
f
) Roberts (
g
) Canny and (
h
) Laplacian.
These operators are sensitive to noise and are only suitable for images with low noise and complexity. The Canny operator performs best among the operators shown in Figure 12. It has strong denoising ability, and also processes the segmentation of lines well with continuity, fineness, and straightness. However, the Canny operator is more complex and takes longer to execute. In the actual industrial production, a thresholding gradient is usually used in the case of high real-time requirement. On the contrary, the more advanced Canny operator is selected in the case of high quality requirement.
Although differential operators can locate the boundaries of different regions efficiently, the closure and continuity of the boundaries cannot be guaranteed due to numerous discontinuous points and lines in the high-detail regions. Therefore, it is necessary to smooth the image before using a differential operator to detect edges.
Another edge detection method is the serial boundary technique, that concatenates points of edges to form a closed boundary. Serial boundary techniques mainly include graph-searching algorithms and dynamic programming algorithms. In graph-searching algorithms, the points on the edges are represented by a graph structure, and the path with the minimum cost is searched in the graph to determine the closed boundaries, which is always computationally intensive. The dynamic programming algorithm utilizes heuristic rules to reduce the search computation.
The active contours method approximates the actual contours of the objects by matching the closed curve (i.e., the initial contours based on gradient) with the local features of the image, and finds the closed curve with the minimum energy by minimizing the energy function to achieve image segmentation. The method is sensitive to the location of the initial contour, so the initialization must be close to the target contour. Moreover, its non-convexity easily leads to the local minimum, so it is difficult to converge to the concave boundary. Lankton and Tannenbaum [5][9] proposed a framework that considers the local segmentation energy to evolve contours, that could produce the initial localization according to the locally based global active contour energy and effectively segment objects with heterogeneous feature profiles.

2.2. Region Division
The region division strategy includes serial region division and parallel region division. Thresholding is a typical parallel region division algorithm. The threshold is generally defined by the trough value in a gray histogram with some processing to make the troughs in the histogram deeper or to convert the troughs into peaks. The optimal grayscale threshold can be determined by the zeroth-order or first-order cumulant moment of the gray histogram to maximize the discriminability of the different categories. The serial region technique involves dividing the region segmentation task into multiple steps to be performed sequentially, and the representative steps are region growing and region merging. Region growing involves taking multiple seeds (single pixels or regions) as initiation points and combining the pixels with the same or similar features in the seed neighborhoods in the regions where the seed is located, according to a predefined growth rule until no more pixels can be merged. The principle of region merging is similar to the region growing, except that region merging measures the similarity by judging whether the difference between the average gray value of the pixels in the region obtained in the previous step and the gray value of its adjacent pixels is less than the given threshold K. Region merging can be used to solve the problem of hard noise loss and object occlusion, and has a good effect on controlling the segmentation scale and processing unconventional data; however, its computational cost is high, and the stopping rule is difficult to affirm.2.3. Graph Theory
The image segmentation method based on graph theory maps an image to a graph, that represents pixels or regions as vertices of the graph, and represents the similarity between vertices as weights of edges. Image segmentation, based on graph theory, is regarded as the division of vertices in the graph, analyzing the weighted graph with the principle and method based on graph theory, and obtaining optimal segmentation with the global optimization of the graph (e.g., the min-cut). Graph-based region merging uses different metrics to obtain optimal global grouping instead of using fixed merging rules in clustering. Felzenszwalb et al. [6][11] used the minimum spanning tree (MST) to merge pixels after the image was represented as a graph. Image segmentation based on MRF (Markov random field) introduces probabilistic graphical models (PGMs) into the region division to represent the randomness of the lower-level features in the images. It maps the image to an undigraph, where each vertex in the graph represents the feature at the corresponding location in the image, and each edge represents the relationship between two vertices. According to the Markov property of the graph, the feature of each point is only related to its adjacent features.2.4. Clustering Method
K-means clustering is a special thresholding segmentation algorithm that is proposed based on the Lloyd algorithm. The algorithm operates as follows: (i) initialize K points as clustering centers; (ii) calculate the distance between each point i in the image and K cluster centers, and select the minimum distance as the classification ki; (iii) average the points of each category (the centroid) and move the cluster center to the centroid; and (iv) repeat steps (ii) and (iii) until algorithm convergence. Simply put, K-means is an iteration process for computing the cluster centers. The K-means has noise robustness and quick convergence, but it is not conducive to processing nonadjacent regions, and it can only converge to the local optimum solution instead of the global optimum solution. Spectral clustering is a common clustering method based on graph theory, that divides the weighted graph and creates subgraphs with low coupling and high cohesion. Achanta et al. [7][15] proposed a simple linear iterative clustering (SLIC) algorithm that used K-means to generate superpixels; its segmentation results are shown in Figure 3. SLIC can be applied to 3D supervoxel generation.Figure 23. SLIC segmentation results (number of superpixels: 10, 20, 50, and 100).
2.5. Random Walks
Random walks is a segmentation algorithm based on graph theory, that is commonly used in image segmentation, image denoising [8][9], and image matching [10]. By assigning labels to adjacent pixels in accordance with predefined rules, pixels with the same label can be represented together to distinguish different objects.
3. Co-Segmentation Methods
The classic segmentation methods usually focus on the feature extraction of a single image, which makes it difficult to obtain the high-level semantic information of the image. In 2006, Rother et al. [11] proposed the concept of collaborative segmentation for the first time. Collaborative segmentation, or co-segmentation for short, involves extracting the common foreground regions from multiple images with no human intervention, to obtain prior knowledge. SLIC segmentation results (number of superpixels: 10, 20, 50, and 100).
2.5. Random Walks
Random walks is a segmentation algorithm based on graph theory, that is commonly used in image segmentation, image denoising [17,18], and image matching [19]. By assigning labels to adjacent pixels in accordance with predefined rules, pixels with the same label can be represented together to distinguish different objects.
4 shows a set of examples of co-segmentation results.

3. Co-Segmentation Methods
The classic segmentation methods usually focus on the feature extraction of a single image, which makes it difficult to obtain the high-level semantic information of the image. In 2006, Rother et al. [24] proposed the concept of collaborative segmentation for the first time. Collaborative segmentation, or co-segmentation for short, involves extracting the common foreground regions from multiple images with no human intervention, to obtain prior knowledge.Figure 3 shows a set of examples of co-segmentation results.
Figure 34.
Two examples of co-segmentation results.
3.1. MRF-Based Co-Segmentation
Rother et al. [11][24] extended the MRF segmentation and utilized prior knowledge to solve the ill-posed problems in multiple image segmentation. First, they segmented the foreground of the seed image, and assumed that the foreground objects of a set of images are similar; then, they built the energy function according to the consistency of the MRF probability distribution and the global constraint of the foreground feature similarity; finally, they estimated whether each pixel belongs to the foreground or background by minimizing the energy function to achieve the segmentation of the foreground and background.