Your browser does not fully support modern features. Please upgrade for a smoother experience.
Please note this is a comparison between Version 1 by Jasim Uddin and Version 2 by Rita Xu.
Artificial intelligence has significantly enhanced the research paradigm and spectrum with a substantiated promise of continuous applicability in the real world domain. Artificial intelligence, the driving force of the current technological revolution, has been used in many frontiers, including education, security, gaming, finance, robotics, autonomous systems, entertainment, and most importantly the healthcare sector. With the rise of the COVID-19 pandemic, several prediction and detection methods using artificial intelligence have been employed to understand, forecast, handle, and curtail the ensuing threats.
- COVID-19
- artificial intelligence
- machine learning
- deep learning
1. Introduction
The severe acute respiratory syndrome coronavirus 2 (SARS-CoV-2) is an extremely contagious disease that was detected for the very first time on 31 December 2019, Wuhan, China [1]. It subsequently spread internationally, causing more than 547 million confirmed infections and 6.33 million deaths, making it one of the worst diseases in human history.
Pre-COVID-19, there were three major epidemics in the twenty-first century, starting with severe acute respiratory syndrome coronavirus (SARS-CoV) in 2002–2003. The second one was swine flu in 2009–2010, and the third one was Middle East respiratory syndrome coronavirus (MERS-CoV), which started in 2015 [2]. With various warning shots for the research community [3][4][3,4] relevant to coronavirus and its potential to cause human harm, it was quite inconceivable that another pandemic was imminent. COVID-19 has proven to be a challenging sickness that could present in a variety of forms and degrees of severity, ranging from mild to severe (organ failure and death). Multi-organ failure and death are unusual from a mild, self-limiting respiratory disease, but it can present as a severe, progressive pneumonia. With the progression of the pandemic and the increasing number of verified cases and people suffering from severe respiratory failure and cardiovascular issues, there are strong grounds to be very worried about the effects of this viral infection [5]. A considerable amount of attention has been placed on identifying acceptable strategies for addressing COVID-19-related challenges. Artificial intelligence has recently attracted much research effort towards solving the complex issues in a number of fields, including engineering [6][7][8][6,7,8], medicine [9][10][9,10], economics [4], and psychology [11].
From the molecular level to the most up-to-date data-driven decision-making models, research literature and digital technologies have had significant impacts [12][13][12,13]. They are based on the technological advancement of artificial intelligence, which is inspired by the human brain. Artificial intelligence is the use of algorithms, models, and computer techniques to realize human intelligence [14]. Significant advancements in processing power, virtual (algorithm) dimensions, numerical optimization, and memory have enabled the creation and implementation of cutting-edge AI solutions to combat COVID-19 throughout the past decade. Due to their ability to swiftly adapt to ever-changing inputs, artificial intelligence systems are useful in situations of rapid change.
Machine learning is the subset of artificial intelligence that has the ability to learn from and make predictions based on data. Deep learning is a subset of machine learning that uses data, weights, hyperparameters, and complex structures of algorithms modeled on the human brain. Machine learning and deep learning have reached important milestones in processing, complicated decision making, information analysis, and extremely organized self-learning.
Several research themes are in spotlight due to COVID-19. Alballa et al. [15] exclusively examined machine learning strategies for diagnosis, mortality, and severity risk prediction. Napolitano et al. [12] provided an overview of COVID-19 applications, including molecular virology, molecular pharmacology and biomarkers, epidemiology, clinical medicine, clinical imaging, and AI-based healthcare. The authors have not clarified the limitations they discovered in the previously mentioned areas. El-Rashidy et al. [16] explored applications of artificial intelligence for COVID-19. This research centered on COVID-19 diagnosis, spread, features, treatment, and vaccine development; it included a few supporting applications. Alyasseri et al. [17] reviewed deep learning (DL) and machine learning (ML) techniques for only COVID-19 diagnosis. Kwekha-Rashid et al. [18] reported their study of coronavirus illness cases using just ML (supervised and unsupervised) techniques. Current restrictions and prospective scopes have not been defined by the authors. Bhattacharya et al. [19] and Roberts et al. [20] highlighted medical image processing applications for COVID-19 that use deep learning and machine learning methods. RWesearchers investigated supervised learning techniques for COVID-19 forecasting, clinical-feature-based COVID-19 prediction, medical-image-based COVID-19 detection, the immunological landscape of COVID-19 analysis, and COVID-19 patients’ mortality-risk prediction, among others. For unsupervised learning, researcherswe show exploratory medical image grouping, risk analysis, anomaly detection, differentiation, patient severity detection, patient screening, and discovery of disease-related genes. Object detection approaches researcherswe found are for COVID-19 detection and screening, infection risk assessment, abnormality detection, body temperature measurement, personal protective equipment detection, and social distance monitoring.
The transfer learning-based COVID-19 study rwesearchers investigated included automatic analysis of medical pictures, COVID-19 classification, identification of lung-disease severity, and an automated COVID-19 screening model. Medical images based on COVID-19 infected area segmentation, lung and infection region segmentation, and infected tissue segmentation are key applications in the image segmentation sector. Detection of COVID-19 and medical image analysis are the primary applications in shot learning arena.
2. Machine Learning
2.1. Supervised Learning
The supervised learning technique examines the training data and develops the hypothesized function to map new instances. The supervised learning-based COVID-19 studies concentrate on several fields, such as COVID-19 forecasting, clinical-feature-based COVID-19 prediction, medical-image-based COVID-19 detection, the immunological landscape of COVID-19 analysis, and mortality-risk prediction of COVID-19 patients, among others. Cabitza et al. [21][22] developed blood tests that are inexpensive and deliver results quickly for identifying COVID-19. The authors applied hematochemical results from 1624 patients hospitalized at San Raphael Hospital (52% were COVID-19 positive). For classification purposes, they employed a variety of machine learning methods, including logistic regression, naive bayes, k-nearest neighbor (KNN), random forest, and support vector machine (SVM). KNN had the highest accuracy. Satu et al. [22][23] created a COVID-19 short-term forecasting system. The authors researched instances of COVID-19 infection in Bangladesh. The dataset was taken from the Johns Hopkins University Center for Systems Science and Engineering’s GitHub repository. Several machine learning methods, such as support vector regression (SVR), polynomial regression, linear regression, polynomial multilayer perceptron (PMLP), multilayer perceptron (MLP), and prophet, were employed to anticipate the numbers of infected and fatal cases. Prophet had the lowest error rate for predicting the following seven days of infection and mortality cases. Arpaci et al. [23][24] developed a clinical-characteristics-based method for predicting COVID-19 infection. The dataset included 114 cases gathered from the hospital in Taizhou, Zhejiang Province, China. Positive and negative classes are present in the dataset. On the basis of fourteen clinical characteristics, they utilized six classic classifiers, including a Bayes classifier, meta-classifier, rule learner, decision tree, lazy classifier, and logistic regression. The meta-classifier was accurate 84.21% percent of the time. The mortality prediction approach for COVID-19 patients was examined by Chowdhury et al. [24][25]. The authors utilized a dataset of 375 COVID-19-positive patients admitted to Tongji Hospital (China) between 10 January and 18 February 2020. In addition, they studied the demographics, clinical features, and patient outcomes of COVID-19-positive patients. They utilized the XGBoost algorithm with several trees to forecast patient risk. Patterson et al. [25][26] developed cytokines of the immunological landscape of COVID-19 utilizing algorithms for machine learning. The synthetic oversampling approach waws applied to address the imbalance issue. The model consists of three components: the severe disease binary classifier, the multi-class predictor, and the post-acute sequelae of COVID-19 (PASC) binary classifier. The authors classified data using the random forest algorithm. The accuracy of the binary classifier for severe illness was 95%, the accuracy of the multi-class predictor was 80%, and the accuracy of the PASC binary classifier was 96%. To enhance patient care, Karthikeyan et al. [26][27] presented a COVID-19 mortality-risk prediction approach. The dataset contained 2779 computerized records of COVID-19-infected or suspected-to-be-infected patients from Tongji Hospital in Wuhan, China. The prediction models utilized a combination of lactate dehydrogenase (LDH), neutrophils, lymphocytes, high-sensitivity C-reactive protein (hs-CRP), and age extracted from blood test data. For risk prediction purposes, the researcher used neural networks, XGBoost, SVM, logistic regression, decision trees, and random forests. Compared to XGBoost, SVM, logistic regression, decision trees, and random forests, the neural network obtained higher accuracy. Marcos et al. [27][28], discovered early identifiers for patients who would die or require mechanical breathing during hospitalization. The dataset consisted of 1260 verified COVID-19 patients from Spain’s University Hospital of Salamanca and Hospital Clinic of Barcelona. Their decision-making approach is based on clinical and laboratory characteristics. The authors utilized three different classifiers: logistic regression, random forest, and XGBoost. The three models attained area under the curve (AUC) ratings of 83 percent, 81 percent, and 82 percent, respectively. The COVID-19 patient mortality prediction system was developed by Mahdavi et al. [28][29]. Between 20 February 2020 and 4 May 2020, the authors analyzed the electronic medical data of 628 patients at Masih Daneshvari Hospital. The dataset is divided into three sections: clinical, demographic, and laboratory. Three SVM models were utilized by the authors. The steps were: First, providing clinical and demographic information. The second step is to enter clinical, demographic, and laboratory information. Third, just enter laboratory data. Three linked models attained the highest degree of precision. Li et al. [29][30] established a COVID-19 patient mortality prediction system. In Wuhan, China, the authors collected clinical data from COVID-19 patients. They constructed three classification-based models. Model one was a decision tree and gradient boosting classifier combination. Model two was a logistic regression classifier. Model three was a logistic regression classifier with three or five features. The best accuracy was attained by the decision tree with gradient boosting. The serum-glucose-based COVID-19 prediction method was introduced by Podder et al. [30][31]. There are 5644 rows and 111 columns in the dataset obtained from Hospital Israelita Albert Einstein in Sao Paulo, Brazil. The dataset contains significant shortcomings, such as an imbalance between classes and missing values. To balance the dataset, the undersampling approach was utilized. For classification objectives, XGBoost, random forest, decision tree, and logistic regression were utilized. The XGBoost algorithm outperformed the competition. Chandra et al. [31][32] explored a categorization approach based on chest X-ray images. COVID-Chestxray set, Montgomery set, and NIH ChestX-ray14 set are three public repositories with which datasets were compiled. The authors distinguished between nCOVID and pneumonia, and normal and aberrant. They utilized the artificial neural network, support vector machine (kernel: RBF, poly, linear), decision tree, k-nearest neighbor, and naive bayes for classification purposes. Additionally, they utilized the majority voting algorithm. Among the previously described models, the majority vote algorithm performed the best. The short-term cumulative COVID-19 case forecasting model was introduced by Balli et al. [32][33]. The dataset comprises the weekly confirmed case and cumulative confirmed case data compiled by the World Health Organization. They utilized linear regression, MLP, random forest, and SVM to forecast the pandemic trend. SVM has the best trend among the listed algorithms. Li et al. [33][34] found unique risk variables for COVID-19 patients. In order to train the model, the LASSO (least absolute shrinkage and selection operator) technique was used. The authors have added blood types such as B and AB as protective variables, and A as a risk factor. In addition to age, gender, temperature, humidity, health expenditure, social distance, smoking, urbanization level, and race, they found a number of other characteristics. Kang et al. [34][35] established a prediction model based on clinical data for COVID-19 patients with severe symptoms. China’s Tongji Medical College-affiliated Union Hospital’s Tumor Center created the dataset. This dataset includes 151 instances between 26 January and 20 March 2020. They created a four-layer ANN model with six nodes in the input layer, thirteen and thirteen nodes in the two hidden levels, and one node in the output layer. The ANN model attained an average of 96.9 percent accuracy. The clinical prognostic evaluation of COVID-19 patients was proposed by Kocadagli et al. [35][36]. The COVID-19 patient dataset was retrieved from Koc University Hospital in Istanbul, Turkey. The data collection included symptoms, demographic features, blood test results, and illness histories from individuals of all ages and genders. For purposes of classification, ANNs, SVMs, and AdaBoost (weak learner: decision trees) were implemented. The best accuracy was reached by ANNs. Udhaya Sankar et al. [36][37] investigated mobile voice analytic applications for COVID-19 detection. The authors did not specify the methods used or the performances of those algorithms. Gokcen et al. [37][38] created artificial neural networks for detecting COVID-19 using cough data. Experiments have utilized available speech data from the Massachusetts Institute of Technology (MIT). Using a filter, cough sounds were cleaned, and the mel-frequency cepstral coefficient was applied to extract characteristics. The model is comprised of four layers, with 256, 128, 64, and 1 neurons in each. The accuracy of the model was 79 percent. Nalini et al. [38][39] have explored sentiment analysis of COVID-19 from Twitter. The dataset consists of 3090 tweets in four classes: fear, sad, anger, and joy. They created four models: bidirectional encoder representations from transformers (BERT), logistic regression (LR), support vector machines (SVM), and long-short-term memory (LSTM). Models produced accuracies of 89%, 75%, 74.75%, and 65% respectively.Table 1. The systematic overview of problems and solutions addressed through the supervised learning methods for COVID-19.
| Ref. | Problem Definition | ML Models | Sample | Performance | |
|---|---|---|---|---|---|
| [39] | [40] | Prediction of COVID-19 infection | Logistic regresseaturion, Decision tree, SVM, naive Bayes, ANN | RT-PCR test 263,007 records, 41 features | Accuracy: 94.41%, 94.99%, 92.4%, 94.36%, 89.2% |
| [40] | [41] | The number of the positive cases prediction method | Nonlinear regression, decision tree, random forest | Six features (deaths, recovered, confirmed, amount of testing, lockdown, lockdown features) | MAPE: 0.24%, 0.18%, 0.02%. |
| [41] | [42] | Prediction model for mortality in COVID-19 infection | SVM | 398 patients (43 expired and 355 non-expired) | Sensitivity: 91%, specificity: 91% |
| [42] | [43] | COVID-19 computed tomography scan dataset for ML | – | 169 patients positive, 76 normal patients, and 60 patients with CAP | – |
| [43] | [44] | Risk factors analysis of COVID-19 patients and ARDS or no-ARDS prediction method | Decision tree, logistic regression, random forest, SVM, DNN | 659 COVID-19 patients and clinical features | Accuracy: 97%, 93%, 92%, 83%, 90% |
| [44] | [45] | Patient intensive care and mechanical ventilation prediction method | Random Forest | Socio-demographic, clinical data 212 patients (123 males, 89 females) | AUC: 80%, AUC: 82% |
| [45] | [46] | Prediction of COVID-19 diagnosis based on symptoms | Gradient-boosting | Test records of 5183 individual (cough, fever, sore throat, shortness of breath, etc) | Sensitivity: 87.30%, specificity: 71.98% |
| [20] | Early risk identification of (SARS-CoV-2) patients | Logistic regression, decision tree, random forest, KNN, SVM, AdaBoost, MLP | Total 198 patients (135 non-severe, 63 severe COVID-19) | SVM: median 96%. Other model performance result unclear in the paper | |
| [46] | [47] | Chest X-ray images based COVID-19 infection detection | KNN, decision tree, random forest, L-SVC, SVC | 371 positive, 1341 normal chest X-ray images | Precision: 98.96%, 94.89%, 97.58%, 99.3%, 99.66% |
| [47] | [48] | SARS-CoV-2 pre-miRNAs detection | KNN, RUNN-COV, logistic regression, random forest, SVM | positive 569 and negative 999,888 pre-miRNA samples | F1 score: 89.86%, 98.26%, 89.47%, 91.55%, 89.83% |
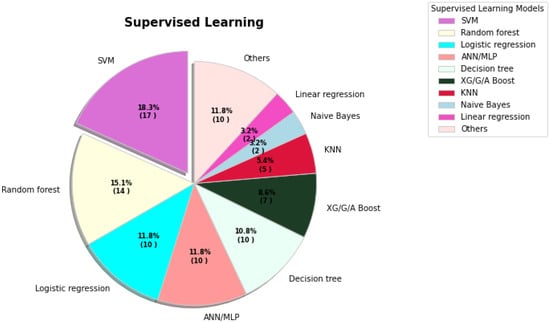
Figure 1. The percentages of various supervised learning models being used for COVID-19 tasks.
2.2. Unsupervised Learning
Models of unsupervised learning find hidden objects, patterns, and groupings without data labels or human interaction. Unsupervised models provide a solution for exploratory medical picture grouping, risk analysis, anomaly detection, differentiation, patient severity detection, patient screening, and discovery of disease-related genes. Boussen et al. [51][52] created a clustering-based COVID-19 patient severity and intubation monitoring system. Green, orange, and red are the classifications for the patient monitoring and decision-making sections, respectively. Each group has distinct characteristics, such as a lesser risk of intubation, a high degree of hypoxia, and the prompt consideration of intubation for a patient in the red category. Gaussian mixture represents the clustering model. The model achieved 87.8 percent accuracy. Zhao et al. [52][53] built an unsupervised model to identify anomalous changes in PM2.5 in Chinese cities between 2017 and 2020. The dataset is comprised of 9,721,023 samples. Encoder, decoder, and anomaly assessment make up the method’s three blocks. This technology can help monitor air quality in response to abrupt changes. Lai et al. [53][54] evaluated publicly accessible and pertinent COVID-19 data sources, addressed the difficulty of data heterogeneity by clustering, and categorized counties based on underlying variations. For clustering purposes, the k-means clustering method was implemented. Chen et al. [54][55] investigated the segmentation network for the COVID-19 computed tomography (CT) infection. Data were compiled from the Italian Society of Medicine, International Radiology, and prior research. Their dataset consists of 10,200 2D CT scans synthesized in a laboratory. The authors utilized the unsupervised domain adaptation learning architecture. The proposed network is divided into multiple modules, including a feature extractor, pixel-wise classifier, and domain adaption module. Convolutional and max-pooling layers were employed to extract features. The network’s dice performance was 86.54 percent, its sensitivity was 85.54 percent, and its specificity was 99.80 percent. Kurniawan et al. [55][56] introduced a clustering and correlation matrix-based COVID-19 risk analysis technique for pandemic nations. The authors retrieved information from Worldometers. For clustering applications, the k-means method has been used. Five experiments were conducted based on varying numbers of clusters. Five was the optimal number of clusters. Zheng et al. [56][57] investigated unsupervised meta-learning for distinguishing COVID-19 and pneumonia patients. They presented a dataset consisting of 2696 images of COVID-19 pneumonia; and 10,155 images of SARS, MERS, influenza, and bacterial pneumonia. The data augmentation approach was employed to produce images. This framework was comprised of two modules: one based on network-based learning and the other on relational models. Utilizing the DenseNet-121 architecture, network-based learning characteristics were extracted. The relation model is represented by an 8-pooling layer network architecture. This model performs better than supervised models such DenseNet-121, DenseNet-161, ResNet-34, and VGG-19. Oniani et al. [57][58] investigated relationships between several biological entities and COVID-19. Experiments were conducted using the CORD-19-on-FHIR dataset. T-distributed stochastic neighbor (t-SNE) and the density-based clustering method (DBSCAN) were used for clustering purposes. Ewen et al. [58][59] suggested online unsupervised learning approach for COVID-19-CT-scan image classification. The components of online unsupervised learning include online machine learning and unsupervised learning. In the experiment, the COVID-19-CT-scan-images dataset from the signal processing grand challenge (SPGC) was utilized. The dataset includes three categories: healthy, COVID-19, and CAP. The technique of horizontally flipped data augmentation was used to increase the number of image copies. The baseline adopted the DenseNet169 architecture. The accuracy of the proposed model was 86.7%. Miao et al. [59][60] created an unsupervised meta-learning model for the screening of COVID-19 patients. The author gathered three datasets from publicly accessible sources, including BIMCV-COVID19+, Kaggle-pneumonia, and CC-CXRI. The unsupervised meta-learning model was composed of both the DL model and gradient-based optimization. Convolution, max-pooling, and batch normalization are a few of the DL model’s layers. This model is superior to the LeNet, Alexnet, visual geometry group (VGG), CovXNet CNN-RNN, and EMCNet models. Fujisawa et al. [60][61] examined the COVID-19 disease-related gene identification approach using unsupervised main-component-analysis-based feature extraction (PCAUFE). PCAUFE was applied to the RNA expression patterns of 18 healthy individuals and 16 patients with COVID-19. The expression of RNA yielded the identification of 123 genes. The authors classified COVID-19 patients and non-patients based on 123 genes identified by PCAUFE using logistic regression (LR), support vector machine (SVM), and random forest (RF) models. Three models attained areas under the curve (AUC) in excess of 90%. King et al. [61][62] investigated the grouping of COVID-19 chest X-ray images using self-organizing feature maps (SOFM). The authors obtained the dataset from a freely accessible source. This dataset consists of two classes: infected and non-infected. They compared and measured the distributions of pixels in the non-infected cluster and the infected cluster using the overlapping coefficient. Xu et al. [62][63] developed an unsupervised technique for lung segmentation and pulmonary opacity identification using CT scan images. The datasets were obtained from Osaka University, Zhejiang University, Hangzhou Second People’s Hospital, Jingmen First People’s Hospital, Taizhou Hospital, and Sir Run Shaw Affiliated Hospital of Zhejiang University School of Medicine, among others. The image augmentations approach was utilized to produce training images. The lung segmentation model had U-shaped convolutional neural network (U-Net) architecture and many pre-trained encoders, including VGG19, MobileNetV2, and ResNet50. For opacity detection, an auto-encoder based on generative adversarial networks (GAN) was utilized. Classification techniques utilizing support vector machine, random forest, adaptive boosting, and XGBoost were compared. Overall, the accuracy of this method was 95.5%.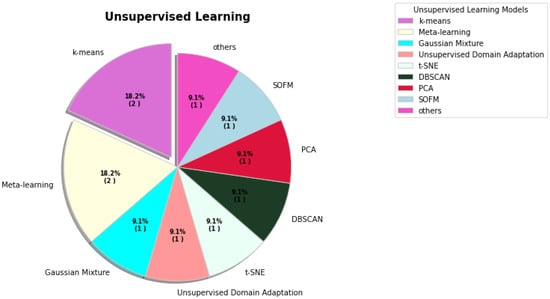
Figure 2. The percentages of various unsupervised learning models used for COVID-19.