With the widespread availability and pervasiveness of artificial intelligence (AI) in many application areas across the globe, the role of crowdsourcing has seen an upsurge in terms of importance for scaling up data-driven algorithms in rapid cycles through a relatively low-cost distributed workforce or even on a volunteer basis. However, there is a lack of systematic and empirical examination of the interplay among the processes and activities combining crowd-machine hybrid interaction. To uncover the enduring aspects characterizing the human-centered AI design space when involving ensembles of crowds and algorithms and their symbiotic relations and requirements, a Computer-Supported Cooperative Work (CSCW) lens strongly rooted in the taxonomic tradition of conceptual scheme development is taken with the aim of aggregating and characterizing some of the main component entities in the burgeoning domain of hybrid crowd-AI centered systems. The goal ofA this article is thus to propose a theoreteoretically grounded and empirically validated analytical framework is proposed for the study of crowd-machine interaction and its environment. Based on a scoping review and several cross-sectional analyses of research studies comprising hybrid forms of human interaction with AI systems and applications at a crowd scale, the available literature was distilled and incorporated into a unifying framework comprised of taxonomic units distributed across integration dimensions that range from the original time and space axes in which every collaborative activity take place to the main attributes that constitute a hybrid intelligence architecture. The upshot is that wheWhen turning to the challenges that are inherent in tasks requiring massive participation, novel properties can be obtained for a set of potential scenarios that go beyond the single experience of a human interacting with the technology to comprise a vast set of massive machine-crowd interactions.
- conceptual framework
- crowd-machine hybrid interaction
- design implications
1. Introduction and Context
2. Background and Scope
3. Methodological Approach
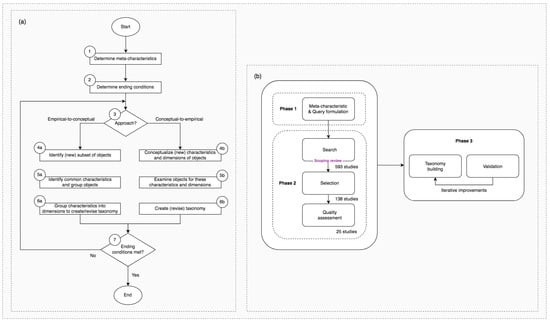
4. ‘Inside the Matrix’: In Pursuit of a Taxonomy for Hybrid Crowd-AI Interaction
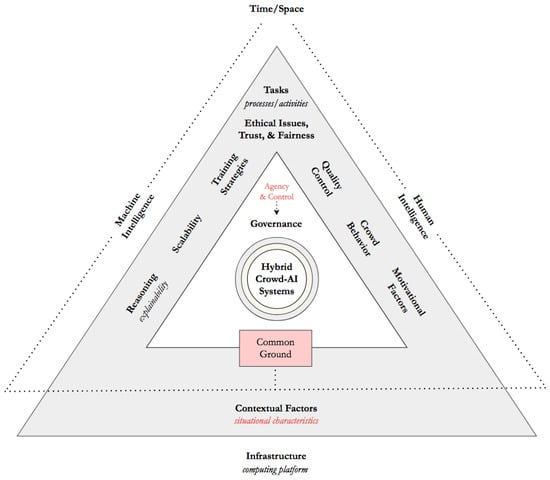
4.1. Temporal and Spatial Axes of Crowd-AI Systems
4.2. Crowd-Machine Hybrid Task Execution and Delegation
4.3. Contextual Factors and Situational Characteristics in Crowd-Computing Arrangements
4.4. Deconstructing the Crowd Behavior Continuum in Hybrid Crowd-Machine Supported Environments
4.5. Hybrid Intelligence Systems at a Crowd Scale: An Infrastructural Viewpoint
4.6. ‘Rebuilding from the Ruins’: Hybrid Crowd-Artificial Intelligence and Its Social-Ethical Caveats
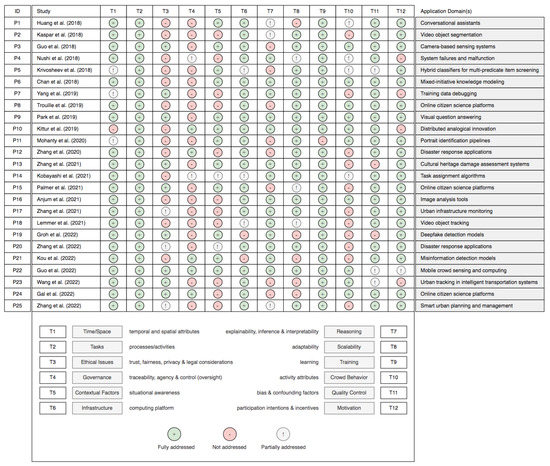
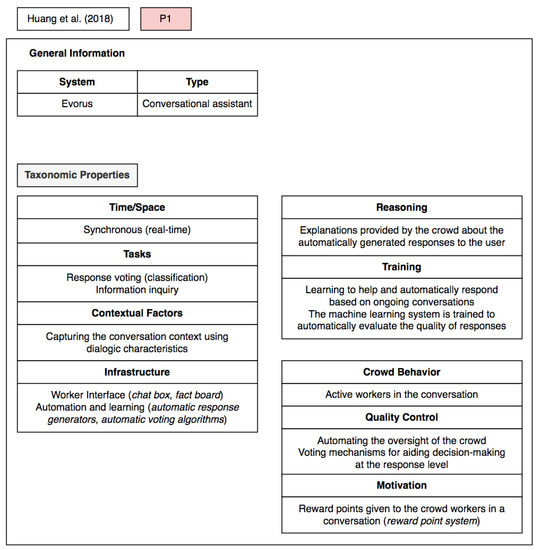
5. Validation and Assessment of the Proposed Taxonomy

6. Concluding Discussion and Challenges Ahead
References
- Lofi, C.; El Maarry, K. Design patterns for hybrid algorithmic-crowdsourcing workflows. In Proceedings of the IEEE 16th Conference on Business Informatics, Geneva, Switzerland, 14–17 July 2014; pp. 1–8.
- Heim, E.; Roß, T.; Seitel, A.; März, K.; Stieltjes, B.; Eisenmann, M.; Lebert, J.; Metzger, J.; Sommer, G.; Sauter, A.W.; et al. Large-scale medical image annotation with crowd-powered algorithms. J. Med. Imaging 2018, 5, 034002.
- Vargas-Santiago, M.; Monroy, R.; Ramirez-Marquez, J.E.; Zhang, C.; Leon-Velasco, D.A.; Zhu, H. Complementing solutions to optimization problems via crowdsourcing on video game plays. Appl. Sci. 2020, 10, 8410.
- Bharadwaj, A.; Gwizdala, D.; Kim, Y.; Luther, K.; Murali, T.M. Flud: A hybrid crowd–algorithm approach for visualizing biological networks. ACM Trans. Comput. Interact. 2022, 29, 1–53.
- Grudin, J.; Poltrock, S. Taxonomy and theory in computer supported cooperative work. Oxf. Handb. Organ. Psychol. 2012, 2, 1323–1348.
- Nickerson, R.C.; Varshney, U.; Muntermann, J. A method for taxonomy development and its application in information systems. Eur. J. Inf. Syst. 2013, 22, 336–359.
- Harris, A.M.; Gómez-Zará, D.; DeChurch, L.A.; Contractor, N.S. Joining together online: The trajectory of CSCW scholarship on group formation. Proc. ACM Hum.-Comput. Interact. 2019, 3, 1–27.
- McGrath, J.E. Groups: Interaction and Performance; Prentice-Hall: Englewood Cliffs, NJ, USA, 1984.
- Shaw, M.E. Scaling group tasks: A method for dimensional analysis. JSAS Cat. Sel. Doc. Psychol. 1973, 3, 8.
- Modaresnezhad, M.; Iyer, L.; Palvia, P.; Taras, V. Information technology (IT) enabled crowdsourcing: A conceptual framework. Inf. Process. Manag. 2020, 57, 102135.
- Bhatti, S.S.; Gao, X.; Chen, G. General framework, opportunities and challenges for crowdsourcing techniques: A comprehensive survey. J. Syst. Softw. 2020, 167, 110611.
- Johansen, R. Groupware: Computer Support for Business Teams; The Free Press: New York, NY, USA, 1988.
- Lee, C.P.; Paine, D. From the matrix to a model of coordinated action (MoCA): A conceptual framework of and for CSCW. In Proceedings of the 18th ACM Conference on Computer Supported Cooperative Work & Social Computing, Vancouver, BC, Canada, 14–18 March 2015; pp. 179–194.
- Renyi, M.; Gaugisch, P.; Hunck, A.; Strunck, S.; Kunze, C.; Teuteberg, F. Uncovering the complexity of care networks—Towards a taxonomy of collaboration complexity in homecare. Comput. Support. Cooperative Work. (CSCW) 2022, 31, 517–554.
- Thomer, A.K.; Twidale, M.B.; Yoder, M.J. Transforming taxonomic interfaces: “Arm’s length” cooperative work and the maintenance of a long-lived classification system. Proc. ACM Hum.-Comput. Interact. 2018, 2, 1–23.
- Akata, Z.; Balliet, D.; de Rijke, M.; Dignum, F.; Dignum, V.; Eiben, G.; Fokkens, A.; Grossi, D.; Hindriks, K.V.; Hoos, H.H.; et al. A research agenda for hybrid intelligence: Augmenting human intellect with collaborative, adaptive, responsible, and explainable artificial intelligence. Computer 2020, 53, 18–28.
- Pescetelli, N. A brief taxonomy of hybrid intelligence. Forecasting 2021, 3, 633–643.
- Dellermann, D.; Calma, A.; Lipusch, N.; Weber, T.; Weigel, S.; Ebel, P. The future of human-AI collaboration: A taxonomy of design knowledge for hybrid intelligence systems. In Proceedings of the 52nd Hawaii International Conference on System Sciences, Maui, HI, USA, 8–11 January 2019; pp. 274–283.
- Dubey, A.; Abhinav, K.; Jain, S.; Arora, V.; Puttaveerana, A. HACO: A framework for developing human-AI teaming. In Proceedings of the 13th Innovations in Software Engineering Conference, Jabalpur, India, 27–29 February 2020; pp. 1–9.
- Littmann, M.; Suomela, T. Crowdsourcing, the great meteor storm of 1833, and the founding of meteor science. Endeavour 2014, 38, 130–138.
- Corney, J.R.; Torres-Sánchez, C.; Jagadeesan, A.P.; Regli, W.C. Outsourcing labour to the cloud. Int. J. Innovation Sustain. Dev. 2009, 4, 294–313.
- Rouse, A.C. A preliminary taxonomy of crowdsourcing. In Proceedings of the Australasian Conference on Information Systems, Brisbane, Australia, 1–3 December 2010; Volume 76.
- Malone, T.W.; Laubacher, R.; Dellarocas, C. The collective intelligence genome. IEEE Eng. Manag. Rev. 2010, 38, 38–52.
- Zwass, V. Co-creation: Toward a taxonomy and an integrated research perspective. Int. J. Electron. Commer. 2010, 15, 11–48.
- Doan, A.; Ramakrishnan, R.; Halevy, A.Y. Crowdsourcing systems on the world-wide web. Commun. ACM 2011, 54, 86–96.
- Saxton, G.D.; Oh, O.; Kishore, R. Rules of crowdsourcing: Models, issues, and systems of control. Inf. Syst. Management 2013, 30, 2–20.
- Nakatsu, R.T.; Grossman, E.B.; Iacovou, C.L. A taxonomy of crowdsourcing based on task complexity. J. Inf. Sci. 2014, 40, 823–834.
- Gadiraju, U.; Kawase, R.; Dietze, S. A taxonomy of microtasks on the web. In Proceedings of the 25th ACM Conference on Hypertext and Social Media, Santiago, Chile, 1–4 September 2014; pp. 218–223.
- Hosseini, M.; Shahri, A.; Phalp, K.; Taylor, J.; Ali, R. Crowdsourcing: A taxonomy and systematic mapping study. Comput. Sci. Rev. 2015, 17, 43–69.
- Alabduljabbar, R.; Al-Dossari, H. Towards a classification model for tasks in crowdsourcing. In Proceedings of the Second International Conference on Internet of Things and Cloud Computing, Cambridge, UK, 22–23 March 2017; pp. 1–7.
- Chen, Q.; Magnusson, M.; Björk, J. Exploring the effects of problem- and solution-related knowledge sharing in internal crowdsourcing. J. Knowl. Manag. 2022, 26, 324–347.
- Chilton, L.B.; Little, G.; Edge, D.; Weld, D.S.; Landay, J.A. Cascade: Crowdsourcing taxonomy creation. In Proceedings of the CHI Conference on Human Factors in Computing Systems, Paris, France, 27 April–2 May 2013; pp. 1999–2008.
- Sharif, A.; Gopal, P.; Saugstad, M.; Bhatt, S.; Fok, R.; Weld, G.; Dey, K.A.M.; Froehlich, J.E. Experimental crowd+AI approaches to track accessibility features in sidewalk intersections over time. In Proceedings of the 23rd International ACM SIGACCESS Conference on Computers and Accessibility, Virtual Event, 18–22 October 2021; pp. 1–5.
- Zhang, D.Y.; Huang, Y.; Zhang, Y.; Wang, D. Crowd-assisted disaster scene assessment with human-AI interactive attention. In Proceedings of the Thirty-Fourth AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; pp. 2717–2724.
- Kaspar, A.; Patterson, G.; Kim, C.; Aksoy, Y.; Matusik, W.; Elgharib, M. Crowd-guided ensembles: How can we choreograph crowd workers for video segmentation? In Proceedings of the CHI Conference on Human Factors in Computing Systems, Montreal, QC, Canada, 21–26 April 2018.
- Zhang, Y.; Zong, R.; Kou, Z.; Shang, L.; Wang, D. CollabLearn: An uncertainty-aware crowd-AI collaboration system for cultural heritage damage assessment. IEEE Trans. Comput. Soc. Syst. 2021, 9, 1515–1529.
- Maier-Hein, L.; Ross, T.; Gröhl, J.; Glocker, B.; Bodenstedt, S.; Stock, C.; Heim, E.; Götz, M.; Wirkert, S.J.; Kenngott, H.; et al. Crowd-algorithm collaboration for large-scale endoscopic image annotation with confidence. In Proceedings of the 19th International Conference on Medical Image Computing and Computer-Assisted Intervention, Athens, Greece, 17–21 October 2016; pp. 616–623.
- Mohanty, V.; Thames, D.; Mehta, S.; Luther, K. Photo Sleuth: Combining human expertise and face recognition to identify historical portraits. In Proceedings of the 24th International Conference on Intelligent User Interfaces, Marina del Ray, CA, USA, 17–20 March 2019; pp. 547–557.
- Huang, T.H.; Chang, J.C.; Bigham, J.P. Evorus: A crowd-powered conversational assistant built to automate itself over time. In Proceedings of the CHI Conference on Human Factors in Computing Systems, Montreal, QC, Canada, 21–26 April 2018; p. 295.
- Guo, A.; Jain, A.; Ghose, S.; Laput, G.; Harrison, C.; Bigham, J.P. Crowd-AI camera sensing in the real world. Proc. ACM Interactive, Mobile, Wearable Ubiquitous Technol. 2018, 2, 1–20.
- Correia, A.; Paredes, H.; Schneider, D.; Jameel, S.; Fonseca, B. Towards hybrid crowd-AI centered systems: Developing an integrated framework from an empirical perspective. In Proceedings of the IEEE International Conference on Systems, Man and Cybernetics, Bari, Italy, 6–9 October 2019; pp. 4013–4018.
- Xu, W.; Dainoff, M.J.; Ge, L.; Gao, Z. Transitioning to human interaction with AI systems: New challenges and opportunities for HCI professionals to enable human-centered AI. Int. J. Human–Computer Interact. 2022, 39, 494–518.
- Colazo, M.; Alvarez-Candal, A.; Duffard, R. Zero-phase angle asteroid taxonomy classification using unsupervised machine learning algorithms. Astron. Astrophys. 2022, 666, A77.
- Mock, F.; Kretschmer, F.; Kriese, A.; Böcker, S.; Marz, M. Taxonomic classification of DNA sequences beyond sequence similarity using deep neural networks. Proc. Natl. Acad. Sci. USA 2022, 119, e2122636119.
- Rasch, R.F. The nature of taxonomy. Image J. Nurs. Scholarsh. 1987, 19, 147–149.
- Tricco, A.C.; Lillie, E.; Zarin, W.; O’Brien, K.; Colquhoun, H.; Kastner, M.; Levac, D.; Ng, C.; Sharpe, J.P.; Wilson, K.; et al. A scoping review on the conduct and reporting of scoping reviews. BMC Med. Res. Methodol. 2016, 16, 15.
- Sokal, R.R. Phenetic taxonomy: Theory and methods. Annu. Rev. Ecol. Syst. 1986, 17, 423–442.
- Oberländer, A.M.; Lösser, B.; Rau, D. Taxonomy research in information systems: A systematic assessment. In Proceedings of the 27th European Conference on Information Systems, Stockholm and Uppsala, Sweden, 8–14 June 2019.
- Gerber, A. Computational ontologies as classification artifacts in IS research. In Proceedings of the 24th Americas Conference on Information Systems, New Orleans, LA, USA, 16–18 August 2018.
- Webster, J.; Watson, R.T. Analyzing the past to prepare for the future: Writing a literature review. MIS Q. 2002, 26, 2.
- Schmidt-Kraepelin, M.; Thiebes, S.; Tran, M.C.; Sunyaev, A. What’s in the game? Developing a taxonomy of gamification concepts for health apps. In Proceedings of the 51st Hawaii International Conference on System Sciences, Hilton Waikoloa Village, HI, USA, 3–6 January 2018; pp. 1–10.
- Sai, A.R.; Buckley, J.; Fitzgerald, B.; Le Gear, A. Taxonomy of centralization in public blockchain systems: A systematic literature review. Inf. Process. Manag. 2021, 58, 102584.
- Andraschko, L.; Wunderlich, P.; Veit, D.; Sarker, S. Towards a taxonomy of smart home technology: A preliminary understanding. In Proceedings of the 42nd International Conference on Information Systems, Austin, TX, USA, 12–15 December 2021.
- Larsen, K.R.; Hovorka, D.; Dennis, A.; West, J.D. Understanding the elephant: The discourse approach to boundary identification and corpus construction for theory review articles. J. Assoc. Inf. Syst. 2019, 20, 15.
- Elliott, J.H.; Turner, T.; Clavisi, O.; Thomas, J.; Higgins, J.P.T.; Mavergames, C.; Gruen, R.L. Living systematic reviews: An emerging opportunity to narrow the evidence-practice gap. PLoS Med. 2014, 11, e1001603.
- Singh, V.K.; Singh, P.; Karmakar, M.; Leta, J.; Mayr, P. The journal coverage of Web of Science, Scopus and Dimensions: A comparative analysis. Scientometrics 2021, 126, 5113–5142.
- Kittur, A.; Nickerson, J.V.; Bernstein, M.; Gerber, E.; Shaw, A.; Zimmerman, J.; Lease, M.; Horton, J.J. The future of crowd work. In Proceedings of the ACM Conference on Computer Supported Cooperative Work, San Antonio, TX, USA, 23–27 February 2013; pp. 1301–1318.
- Zhang, D.; Zhang, Y.; Li, Q.; Plummer, T.; Wang, D. CrowdLearn: A crowd-AI hybrid system for deep learning-based damage assessment applications. In Proceedings of the 39th IEEE International Conference on Distributed Computing Systems, Dallas, TX, USA, 7–10 July 2019; pp. 1221–1232.
- Landolt, S.; Wambsganss, T.; Söllner, M. A taxonomy for deep learning in natural language processing. In Proceedings of the 54th Hawaii International Conference on System Sciences, Kauai, HI, USA, 5 January 2021; pp. 1061–1070.
- Straus, S.G. Testing a typology of tasks: An empirical validation of McGrath’s (1984) group task circumplex. Small Group Research 1999, 30, 166–187.
- Chesbrough, H.W. Open Innovation: The New Imperative for Creating and Profiting from Technology; Harvard Business Press: Boston, MA, USA, 2003.
- Karachiwalla, R.; Pinkow, F. Understanding crowdsourcing projects: A review on the key design elements of a crowdsourcing initiative. Creativity Innov. Manag. 2021, 30, 563–584.
- Hemmer, P.; Schemmer, M.; Vössing, M.; Kühl, N. Human-AI complementarity in hybrid intelligence systems: A structured literature review. In Proceedings of the 25th Pacific Asia Conference on Information Systems, Virtual Event, Dubai, United Arab Emirates, 12–14 July 2021; p. 78.
- Holstein, K.; Aleven, V.; Rummel, N. A conceptual framework for human-AI hybrid adaptivity in education. In Proceedings of the 21st International Conference on Artificial Intelligence in Education, Ifrane, Morocco, 6–10 July 2020; pp. 240–254.
- Siemon, D. Elaborating team roles for artificial intelligence-based teammates in human-AI collaboration. Group Decis. Negot. 2022, 31, 871–912.
- Weber, E.; Marzo, N.; Papadopoulos, D.P.; Biswas, A.; Lapedriza, A.; Ofli, F.; Imran, M.; Torralba, A. Detecting natural disasters, damage, and incidents in the wild. In Proceedings of the 16th European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; pp. 331–350.
- Vaughan, J.W. Making better use of the crowd: How crowdsourcing can advance machine learning research. J. Mach. Learn. Res. 2017, 18, 7026–7071.
- Hamadi, R.; Ghazzai, H.; Massoud, Y. A generative adversarial network for financial advisor recruitment in smart crowdsourcing platforms. Appl. Sci. 2022, 12, 9830.
- Alter, S. Work system theory: Overview of core concepts, extensions, and challenges for the future. J. Assoc. Inf. Syst. 2013, 14, 2.
- Venumuddala, V.R.; Kamath, R. Work systems in the Indian information technology (IT) industry delivering artificial intelligence (AI) solutions and the challenges of work from home. Inf. Syst. Front. 2022, 1–25.
- Nardi, B. Context and Consciousness: Activity Theory and Human-Computer Interaction; MIT Press: Cambridge, MA, USA, 1996.
- Neale, D.C.; Carroll, J.M.; Rosson, M.B. Evaluating computer-supported cooperative work: Models and frameworks. In Proceedings of the ACM Conference on Computer Supported Cooperative Work, Chicago, IL, USA, 6–10 November 2004; pp. 112–121.
- Lee, S.W.; Krosnick, R.; Park, S.Y.; Keelean, B.; Vaidya, S.; O’Keefe, S.D.; Lasecki, W.S. Exploring real-time collaboration in crowd-powered systems through a UI design tool. Proc. ACM Human-Computer Interact. 2018, 2, 1–23.
- Wang, X.; Ding, L.; Wang, Q.; Xie, J.; Wang, T.; Tian, X.; Guan, Y.; Wang, X. A picture is worth a thousand words: Share your real-time view on the road. IEEE Trans. Veh. Technol. 2016, 66, 2902–2914.
- Agapie, E.; Teevan, J.; Monroy-Hernández, A. Crowdsourcing in the field: A case study using local crowds for event reporting. In Proceedings of the Third AAAI Conference on Human Computation and Crowdsourcing, San Diego, CA, USA, 8–11 November 2015; pp. 2–11.
- Lafreniere, B.J.; Grossman, T.; Anderson, F.; Matejka, J.; Kerrick, H.; Nagy, D.; Vasey, L.; Atherton, E.; Beirne, N.; Coelho, M.H.; et al. Crowdsourced fabrication. In Proceedings of the 29th Annual Symposium on User Interface Software and Technology, Tokyo, Japan, 16–19 October 2016; pp. 15–28.
- Aristeidou, M.; Scanlon, E.; Sharples, M. Profiles of engagement in online communities of citizen science participation. Comput. Hum. Behav. 2017, 74, 246–256.
- Bouwer, A. Under which conditions are humans motivated to delegate tasks to AI? A taxonomy on the human emotional state driving the motivation for AI delegation. In Marketing and Smart Technologies; Springer: Singapore, 2022; pp. 37–53.
- Lubars, B.; Tan, C. Ask not what AI can do, but what AI should do: Towards a framework of task delegability. In Proceedings of the Annual Conference on Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019; pp. 57–67.
- Sun, Y.; Ma, X.; Ye, K.; He, L. Investigating crowdworkers’ identify, perception and practices in micro-task crowdsourcing. Proc. ACM Hum.-Comput. Interact. 2022, 6, 1–20.
- Khan, V.J.; Papangelis, K.; Lykourentzou, I.; Markopoulos, P. Macrotask Crowdsourcing—Engaging the Crowds to Address Complex Problems; Human-Computer Interaction Series; Springer: Cham, Switzerland, 2019.
- Teevan, J. The future of microwork. XRDS Crossroads ACM Mag. Stud. 2016, 23, 26–29.
- Zulfiqar, M.; Malik, M.N.; Khan, H.H. Microtasking activities in crowdsourced software development: A systematic literature review. IEEE Access 2022, 10, 24721–24737.
- Rahman, H.; Roy, S.B.; Thirumuruganathan, S.; Amer-Yahia, S.; Das, G. Optimized group formation for solving collaborative tasks. VLDB J. 2018, 28, 1–23.
- Schmitz, H.; Lykourentzou, I. Online sequencing of non-decomposable macrotasks in expert crowdsourcing. ACM Trans. Soc. Comput. 2018, 1, 1–33.
- Jin, Y.; Carman, M.; Zhu, Y.; Xiang, Y. A technical survey on statistical modelling and design methods for crowdsourcing quality control. Artif. Intell. 2020, 287, 103351.
- Moayedikia, A.; Ghaderi, H.; Yeoh, W. Optimizing microtask assignment on crowdsourcing platforms using Markov chain Monte Carlo. Decis. Support Syst. 2020, 139, 113404.
- Amershi, S.; Weld, D.; Vorvoreanu, M.; Fourney, A.; Nushi, B.; Collisson, P.; Suh, J.; Iqbal, S.T.; Bennett, P.N.; Inkpen, K.; et al. Guidelines for human-AI interaction. In Proceedings of the CHI Conference on Human Factors in Computing Systems, Glasgow, Scotland, UK, 4–9 May 2019.
- Rafner, J.; Gajdacz, M.; Kragh, G.; Hjorth, A.; Gander, A.; Palfi, B.; Berditchevskiaia, A.; Grey, F.; Gal, K.; Segal, A.; et al. Mapping citizen science through the lens of human-centered AI. Hum. Comput. 2022, 9, 66–95.
- Shneiderman, B. Bridging the gap between ethics and practice: Guidelines for reliable, safe, and trustworthy human-centered AI systems. ACM Trans. Interact. Intell. Syst. 2020, 10, 1–31.
- Ramírez, J.; Sayin, B.; Baez, M.; Casati, F.; Cernuzzi, L.; Benatallah, B.; Demartini, G. On the state of reporting in crowdsourcing experiments and a checklist to aid current practices. Proc. ACM Hum.-Comput. Interact. 2021, 5, 1–34.
- Robert, L.; Romero, D.M. Crowd size, diversity and performance. In Proceedings of the 33rd Annual ACM Conference on Human Factors in Computing Systems, Seoul, Republic of Korea, 18–23 April 2015; pp. 1379–1382.
- Blandford, A. Intelligent interaction design: The role of human-computer interaction research in the design of intelligent systems. Expert Syst. 2001, 18, 3–18.
- Huang, K.; Zhou, J.; Chen, S. Being a solo endeavor or team worker in crowdsourcing contests? It is a long-term decision you need to make. Proc. ACM Hum.-Comput. Interact. 2022, 6, 1–32.
- Venkatagiri, S.; Thebault-Spieker, J.; Kohler, R.; Purviance, J.; Mansur, R.S.; Luther, K. GroundTruth: Augmenting expert image geolocation with crowdsourcing and shared representations. Proc. ACM Hum.-Comput. Interact. 2019, 3, 1–30.
- Zhou, S.; Valentine, M.; Bernstein, M.S. In search of the dream team: Temporally constrained multi-armed bandits for identifying effective team structures. In Proceedings of the CHI Conference on Human Factors in Computing Systems, Montreal, QC, Canada, 21–26 April 2018.
- Gray, M.L.; Suri, S.; Ali, S.S.; Kulkarni, D. The crowd is a collaborative network. In Proceedings of the 19th ACM Conference on Computer-Supported Cooperative Work & Social Computing, San Francisco, CA, USA, 27 February–2 March 2016; pp. 134–147.
- Zhang, X.; Zhang, W.; Zhao, Y.; Zhu, Q. Imbalanced volunteer engagement in cultural heritage crowdsourcing: A task-related exploration based on causal inference. Inf. Process. Manag. 2022, 59, 103027.
- McNeese, N.J.; Demir, M.; Cooke, N.J.; She, M. Team situation awareness and conflict: A study of human–machine teaming. J. Cogn. Eng. Decis. Mak. 2021, 15, 83–96.
- Dafoe, A.; Bachrach, Y.; Hadfield, G.; Horvitz, E.; Larson, K.; Graepel, T. Cooperative AI: Machines must learn to find common ground. Nature 2021, 593, 33–36.
- Alorwu, A.; Savage, S.; van Berkel, N.; Ustalov, D.; Drutsa, A.; Oppenlaender, J.; Bates, O.; Hettiachchi, D.; Gadiraju, U.; Gonçalves, J.; et al. REGROW: Reimagining global crowdsourcing for better human-AI collaboration. In Proceedings of the CHI Conference on Human Factors in Computing Systems, Extended Abstracts, New Orleans, LA, USA, 29 April–5 May 2022; pp. 1–7.
- Santos, C.A.; Baldi, A.M.; de Assis Neto, F.R.; Barcellos, M.P. Essential elements, conceptual foundations and workflow design in crowd-powered projects. J. Inf. Sci. 2022.
- Valentine, M.A.; Retelny, D.; To, A.; Rahmati, N.; Doshi, T.; Bernstein, M.S. Flash organizations: Crowdsourcing complex work by structuring crowds as organizations. In Proceedings of the CHI Conference on Human Factors in Computing Systems, Denver, CO, USA, 6–11 May 2017; pp. 3523–3537.
- Kamar, E. Directions in hybrid intelligence: Complementing AI systems with human intelligence. In Proceedings of the Twenty-Fifth International Joint Conference on Artificial Intelligence, New York, NY, USA, 9–15 July 2016; pp. 4070–4073.
- Tocchetti, A.; Corti, L.; Brambilla, M.; Celino, I. EXP-Crowd: A gamified crowdsourcing framework for explainability. Front. Artif. Intell. 2022, 5, 826499.
- Barbosa, N.M.; Chen, M. Rehumanized crowdsourcing: A labeling framework addressing bias and ethics in machine learning. In Proceedings of the CHI Conference on Human Factors in Computing Systems, Glasgow, Scotland, UK, 4–9 May 2019; pp. 1–12.
- Basker, T.; Tottler, D.; Sanguet, R.; Muffbur, J. Artificial intelligence and human learning: Improving analytic reasoning via crowdsourcing and structured analytic techniques. Comput. Educ. 2022, 3, 1003056.
- Mirbabaie, M.; Brendel, A.B.; Hofeditz, L. Ethics and AI in information systems research. Commun. Assoc. Inf. Syst. 2022, 50, 38.
- Sundar, S.S. Rise of machine agency: A framework for studying the psychology of human–AI interaction (HAII). J. Comput. Commun. 2020, 25, 74–88.
- Liu, B. In AI we trust? Effects of agency locus and transparency on uncertainty reduction in human–AI interaction. J. Comput. Commun. 2021, 26, 384–402.
- Kang, H.; Lou, C. AI agency vs. human agency: Understanding human–AI interactions on TikTok and their implications for user engagement. J. Comput. Commun. 2022, 27, zmac014.
- Daniel, F.; Kucherbaev, P.; Cappiello, C.; Benatallah, B.; Allahbakhsh, M. Quality control in crowdsourcing: A survey of quality attributes, assessment techniques, and assurance actions. ACM Comput. Surv. 2018, 51, 1–40.
- Pedersen, J.; Kocsis, D.; Tripathi, A.; Tarrell, A.; Weerakoon, A.; Tahmasbi, N.; Xiong, J.; Deng, W.; Oh, O.; de Vreede, G.-J. Conceptual foundations of crowdsourcing: A review of IS research. In Proceedings of the 46th Hawaii International Conference on System Sciences, Wailea, HI, USA, 7–10 January 2013; pp. 579–588.
- Hansson, K.; Ludwig, T. Crowd dynamics: Conflicts, contradictions, and community in crowdsourcing. Comput. Support. Coop. Work. 2019, 28, 791–794.
- Gimpel, H.; Graf-Seyfried, V.; Laubacher, R.; Meindl, O. Towards artificial intelligence augmenting facilitation: AI affordances in macro-task crowdsourcing. Group Decis. Negot. 2023, 1–50.
- Wu, T.; Terry, M.; Cai, C.J. AI chains: Transparent and controllable human-AI interaction by chaining large language model prompts. In Proceedings of the CHI Conference on Human Factors in Computing Systems, New Orleans, LA, USA, 29 April–5 May 2022.
- Kobayashi, M.; Wakabayashi, K.; Morishima, A. Human+AI crowd task assignment considering result quality requirements. In Proceedings of the Ninth AAAI Conference on Human Computation and Crowdsourcing, Virtual, 14–18 November 2021; pp. 97–107.
- Eggert, M.; Alberts, J. Frontiers of business intelligence and analytics 3.0: A taxonomy-based literature review and research agenda. Bus. Res. 2020, 13, 685–739.
- Chan, J.; Chang, J.C.; Hope, T.; Shahaf, D.; Kittur, A. SOLVENT: A mixed initiative system for finding analogies between research papers. Proc. ACM Hum.-Comput. Interact. 2018, 2, 1–21.
- Zhang, Y.; Shang, L.; Zong, R.; Wang, Z.; Kou, Z.; Wang, D. StreamCollab: A streaming crowd-AI collaborative system to smart urban infrastructure monitoring in social sensing. In Proceedings of the Ninth AAAI Conference on Human Computation and Crowdsourcing, Virtual, 14–18 November 2021; pp. 179–190.
- Yang, J.; Smirnova, A.; Yang, D.; Demartini, G.; Lu, Y.; Cudré-Mauroux, P. Scalpel-CD: Leveraging crowdsourcing and deep probabilistic modeling for debugging noisy training data. In Proceedings of the World Wide Web Conference, San Francisco, CA, USA, 13–17 May 2019; pp. 2158–2168.
- Schlagwein, D.; Cecez-Kecmanovic, D.; Hanckel, B. Ethical norms and issues in crowdsourcing practices: A Habermasian analysis. Inf. Syst. J. 2018, 29, 811–837.
- Gadiraju, U.; Demartini, G.; Kawase, R.; Dietze, S. Crowd anatomy beyond the good and bad: Behavioral traces for crowd worker modeling and pre-selection. Comput. Support. Cooperative Work. 2018, 28, 815–841.
- Palmer, M.S.; Huebner, S.E.; Willi, M.; Fortson, L.; Packer, C. Citizen science, computing, and conservation: How can “crowd AI” change the way we tackle large-scale ecological challenges? Hum. Comput. 2021, 8, 54–75.
- Mannes, A. Governance, risk, and artificial intelligence. AI Mag. 2020, 41, 61–69.
- Choung, H.; David, P.; Ross, A. Trust and ethics in AI. AI Soc. 2022, 1–13.
- Zheng, Q.; Tang, Y.; Liu, Y.; Liu, W.; Huang, Y. UX research on conversational human-AI interaction: A literature review of the ACM Digital Library. In Proceedings of the CHI Conference on Human Factors in Computing Systems, New Orleans, LA, USA, 29 April–5 May 2022.
- Heath, C.; Svensson, M.S.; Hindmarsh, J.; Luff, P.; Vom Lehn, D. Configuring awareness. Comput. Support. Coop. Work. 2002, 11, 317–347.
- Park, J.; Krishna, R.; Khadpe, P.; Fei-Fei, L.; Bernstein, M. AI-based request augmentation to increase crowdsourcing participation. In Proceedings of the Seventh AAAI Conference on Human Computation and Crowdsourcing, Stevenson, WA, USA, 28–30 October 2019; pp. 115–124.
- Star, S.L.; Ruhleder, K. Steps towards an ecology of infrastructure: Complex problems in design and access for large-scale collaborative systems. In Proceedings of the ACM Conference on Computer Supported Cooperative Work, Chapel Hill, NC, USA, 22–26 October 1994; pp. 253–264.
- Mosconi, G.; Korn, M.; Reuter, C.; Tolmie, P.; Teli, M.; Pipek, V. From Facebook to the neighbourhood: Infrastructuring of hybrid community engagement. Comput. Support. Coop. Work (CSCW) 2017, 26, 959–1003.
- Ehsan, U.; Liao, Q.V.; Muller, M.; Riedl, M.O.; Weisz, J.D. Expanding explainability: Towards social transparency in AI systems. In Proceedings of the CHI Conference on Human Factors in Computing Systems, Yokohama, Japan, 8–13 May 2021; pp. 1–19.
- Thieme, A.; Cutrell, E.; Morrison, C.; Taylor, A.; Sellen, A. Interpretability as a dynamic of human-AI interaction. Interactions 2020, 27, 40–45.
- Walzner, D.D.; Fuegener, A.; Gupta, A. Managing AI advice in crowd decision-making. In Proceedings of the International Conference on Information Systems, Copenhagen, Denmark, 9–14 December 2022; p. 1315.
- Anjum, S.; Verma, A.; Dang, B.; Gurari, D. Exploring the use of deep learning with crowdsourcing to annotate images. Hum. Comput. 2021, 8, 76–106.
- Trouille, L.; Lintott, C.J.; Fortson, L.F. Citizen science frontiers: Efficiency, engagement, and serendipitous discovery with human-machine systems. Proc. Natl. Acad. Sci. USA 2019, 116, 1902–1909.
- Zhou, Z.; Yatani, K. Gesture-aware interactive machine teaching with in-situ object annotations. In Proceedings of the 35th Annual ACM Symposium on User Interface Software and Technology, Bend, OR, USA, 29 October–2 November 2022; pp. 1–14.
- Avdic, M.; Bødker, S.; Larsen-Ledet, I. Two cases for traces: A theoretical framing of mediated joint activity. Proc. ACM Hum.-Comput. Interact. 2021, 5, 1–28.
- Tchernavskij, P.; Bødker, S. Entangled artifacts: The meeting between a volunteer-run citizen science project and a biodiversity data platform. In Proceedings of the Nordic Human-Computer Interaction Conference, Aarhus, Denmark, 8–12 October 2022; pp. 1–13.
- Rzeszotarski, J.M.; Kittur, A. Instrumenting the crowd: Using implicit behavioral measures to predict task performance. In Proceedings of the 24th Annual ACM Symposium on User Interface Software and Technology, Santa Barbara, CA, USA, 16–19 October 2011; pp. 13–22.
- Newman, A.; McNamara, B.; Fosco, C.; Zhang, Y.B.; Sukhum, P.; Tancik, M.; Kim, N.W.; Bylinskii, Z. TurkEyes: A web-based toolbox for crowdsourcing attention data. In Proceedings of the CHI Conference on Human Factors in Computing Systems, Honolulu, HI, USA, 25–30 April 2020; pp. 1–13.
- Goyal, T.; McDonnell, T.; Kutlu, M.; Elsayed, T.; Lease, M. Your behavior signals your reliability: Modeling crowd behavioral traces to ensure quality relevance annotations. In Proceedings of the Sixth AAAI Conference on Human Computation and Crowdsourcing, Zürich, Switzerland, 5–8 July 2018; pp. 41–49.
- Hettiachchi, D.; Van Berkel, N.; Kostakos, V.; Goncalves, J. CrowdCog: A cognitive skill based system for heterogeneous task assignment and recommendation in crowdsourcing. Proc. ACM Hum.-Comput. Interact. 2020, 4, 1–22.
- Zimmerman, J.; Oh, C.; Yildirim, N.; Kass, A.; Tung, T.; Forlizzi, J. UX designers pushing AI in the enterprise: A case for adaptive UIs. Interactions 2020, 28, 72–77.
- Hettiachchi, D.; Kostakos, V.; Goncalves, J. A survey on task assignment in crowdsourcing. ACM Comput. Surv. 2022, 55, 1–35.
- Pei, W.; Yang, Z.; Chen, M.; Yue, C. Quality control in crowdsourcing based on fine-grained behavioral features. Proc. ACM Hum.-Comput. Interact. 2021, 5, 1–28.
- Bakici, T. Comparison of crowdsourcing platforms from social-psychological and motivational perspectives. Int. J. Inf. Manag. 2020, 54, 102121.
- Truong, N.V.-Q.; Dinh, L.C.; Stein, S.; Tran-Thanh, L.; Jennings, N.R. Efficient and adaptive incentive selection for crowdsourcing contests. Appl. Intell. 2022, 1–31.
- Correia, A.; Jameel, S.; Paredes, H.; Fonseca, B.; Schneider, D. Hybrid machine-crowd interaction for handling complexity: Steps toward a scaffolding design framework. In Macrotask Crowdsourcing—Engaging the Crowds to Address Complex Problems; Human-Computer Interaction Series; Springer: Cham, Switzerland, 2019; pp. 149–161.
- Sutherland, W.; Jarrahi, M.H.; Dunn, M.; Nelson, S.B. Work precarity and gig literacies in online freelancing. Work Employ. Soc. 2019, 34, 457–475.
- Salminen, J.; Kamel, A.M.S.; Jung, S.-G.; Mustak, M.; Jansen, B.J. Fair compensation of crowdsourcing work: The problem of flat rates. Behav. Inf. Technol. 2022, 1–22.