1. Introductiory Remarksn and Context
ThCrowd-centered de
sign functional sis far from a trivial undertaking, and this is even more challenging when trying to implement hybrid intelligence models incorporating human cognition into algorithmic-crowdsourcing workflows [1]. In fact
, cr
ucture of intelligent owd-algorithm interaction has recently reached a certain level of maturity, and a vast range of crowd-powered algorithms have successfully been applied in areas like medical image segmentation [2] and games
y with a purpose (GWAP) [3]. In these instances, crowds
of unt
ems has been augmented with new properties in recent yrained (non-expert) online workers have proved to provide similar results in terms of detection accuracy when compared to other groups such as domain knowledge experts, medical students, and experienced crowd workers. Further investigations in this burgeoning domain have also shown that the use of crowd-algorithm hybrids can outperform crowd-only techniques in accomplishing tasks like examining protein interactions and chemical reactions that are very common in the field of network biology [4]. None
theless, the ta
rs principally owing to the advancements in the fielxonomic rationale behind the mass interaction efforts between crowds and machines as an integrated and complex socio-technical system is not completely understood, and there is a need to find novel ways of characterizing this body of work in its whole range. To mitigate this brittleness, a review of the main activities and contexts in which such crowd-AI ensembles have been investigated was carried out to develop a taxonomic scheme as comprehensive as possible to capture the nuances that are unique in comparison with other types of interactions between humans and computational systems.
For more than three d
ecades, of artifitaxonomy development has been seen as a crucial part of socio-technical research within the field of CSCW [5]. To some extent, taxonomies provide a useful guide and theoretic
al foundati
al intelon for assessing technological developments due to their capability to organize complex concepts and knowledge structures into understandable formats [6]. By going back in the course of time, one may find several
taxonomi
gence c approaches that formed the basis for the understanding of the task types that are currently present in many crowdsourcing systems. For a review of prior taxonomic proposals, the reader is referred to Harris and co-authors [7]. In retrospect, McGrath [8] proposed a circumplex model of group tasks intended to characterize their nature (
AIe.g., decision-making)
. From a into four quadrants that reflect the processes involved in their execution (i.e., generate, choose, negotiate, and execute). When moving even further back in history, Shaw [9] asserted the importanc
e o
ncef aspects like task difficulty and intrinsic interest which are seen as foundational in several conceptual
poinframeworks proposed to characterize the broader crowdsourcing phenomena (e.g., [10,11]). According t
o osome authors, Johansen’s [12] time-space matrix is a landmark in the f
ield of CSCW vieand inspired the development of descriptive models such as the Model of Coordinated Action (MoCA) [13], which frames each collaborative w
ork arrangement on a continuum of synchronicity (synchronous vs. asynchronous),
hybrid intellphysical distribution, scale (i.e., number of participants), number of communities of practice involved, nascence and planned permanence of coordinated actions, and turnover. More recently, Renyi and colleagues [14] executed a set of data collecti
on and processing
ence can be understoo procedures involving structured interviews in order to create a taxonomic scheme covering the components related to the collaboration technology support in home care work, while other authors have devoted most of their efforts to the design of innovative taxonomic interfaces [15]. In ad
dition, as the there is now an emerging body of research documenting the different levels of hybrid intelligence in human-algorithm interactions.
From a more generic view, the concept of hybrid intelligence has been defined as the “combination of human and machine intelligence, augmenting human intellect and capabilities instead of replacing them and achieving goals that were unreachable by either humans or machines”
[1][16].
IStemming from this definition, experiments have shown that the time is now appropriate to develop a new taxonomic proposal that can
line with this definition, Dellermann anbe used for planning and assessing activities among humans (crowds) and algorithms in a hybrid mode. To the best of the authors’ knowledge, no other previous work has specifically focused on crowd-AI interaction, although there are some research works addressing the particularities of hybrid human-AI intelligence at a taxonomic level. For example, Pescetelli [17] stressed
the role of algorithms as assistants, peers, fac
o-authorsilitators, and system-level operators. On the other hand, Dellermann and associates [2][18] characterized the design space of hybrid intelligence systems
and recalled t
aking into account the importance of the task itself and its characteristics as a central aspect of collaboration among humans and machines. In the same vein, Dubey et al. [19] proposed a taxonomy of h
uman-AI te
structural co-evolvability of their constituent parts. By propaming comprised of task properties, trust-related aspects, teaming characteristics (e.g., shared awareness), and the learning paradigm involved. However, these taxonomies have hitherto not yet fully explored the particularities of hybrid crowd-AI systems and their use cases in real-world applications. Through a qualitative inspection of conceptual frameworks, artifacts, case studies, and empirical results comprising some type of human-AI hybrid interaction at a massive scale, this article’s contribution lies in systematically structuring a set of attributes and characteristics into an integrated taxonomy that arises as a continuum of co-evolving crowd-algorithmic partnerships intended to solve complex problems that neither humans nor machines can solve separately.
The article is set o
ut as
ing follows. After a discussion of background work in Section 2, a
desc
onceptription of the methodological steps follows until the development of a taxonomy for hybrid crowd-AI systems is provided in Section 3. The resu
lting ta
lxonomic framework
to deis then presented and discussed in detail in Section 4, while Section 5 is
conc
ribe inteerned with the validation of the taxonomy proposed. Finally, possible extensions of this work are suggested in the Section 6 by looking towar
d the future of hybrid systems from a
ctions a socio-technical view of human-centered systems design.
2. Background and Scope
The poin
t of d
dynamicseparture for building the taxonomy presented in this article was the existing work found on the intersectional space between
AI applications, human-human-computer interaction (HCI) and AI from a crowdsourcing perspective. Although the coining of the term ‘crowdsourcing’ took place in the mid-2000s, some may argue that its origin is rooted in the seminal work of the physicist and astronomer Denison Olmsted, who used news media as a crowdsourcing strategy for obtaining accurate observations on the Leonid meteor shower that was witnessed across the United States in 1833 [20]. Wha
t is interesting
ent teams, and society, P to note is that the sequential steps and general techniques used by Olmsted about nineteen decades ago constitute the basis for most of the current crowdsourcing applications. Aligned with this goal, a variety of taxonomies and conceptual frameworks have been developed to better characterize the way as information technology (IT)-enabled crowdsourcing operates. Among the known classifications of crowdsourcing activities, Corney and co-authors [21] we
re
ters and associates some of the first to frame this phenomenon from a taxonomic point of view by incorporating the nature of the crowd, the payment mechanisms or lack thereof, and the type of task into an integrated framework. In line with this, Rouse [22] proposed a taxonomy that comprises the [3]different forms of i
ntrinsic and
entified a set of core design principles extrinsic motivation that can lead to a successful crowdsourcing experience (e.g., social status, altruistic behavior, and personal achievement). This taxonomic proposal also addresses a set of aspects that are specific to the nature of the crowdsourcing task being undertaken by encompassing the expertise and complexity that are directly or indirectly involved in such initiatives. On the basis of insights from the history of group support systems, one would notice similar points to McGrath’s [8] task circumplex taxons taking into consideration the dif
ferent task types that can be executed by individuals in a gro
r impleup structure, which may include decision-making, idea generation and information gathering to name just a few examples.
To an extent, this research strand led to the proliferation of several taxonom
ie
nting s incorporating task-related elements (e.g., [23,24,25,26,27,28,29,30]). Consistent with
the task properties discussed in most of these studies, a cursory
brid collective intelligenc look at the literature reveals certain commonalities related to crowd attributes (e.g., reputation), requester features (e.g., incentivization), and platform facilities such as aggregation and payment mechanisms [29]. Othe
r effecresearch works have focused specifically on internal forms of crowdsourcing [31] or even on t
he use of crowdsourci
velyng as a taxonomy development strategy by itself [32].
NOn a more generic level, Modaresnezhad and colleagues [10] made a clear distinction between the IT-enabled crowdsourcing requirements in business and non-business con
te
thelessxts by basing their proposal on the four collective intelligence “genes” proposed by Malone et al. [23]. However,
these taxonom
ost of conceptualizaies fail to fully account for the hybrid nature of crowd-AI interaction and thus are unable to capture the variety of interactions and
taxonrelations that occur when using a hybrid intelligence system.
During the last few years, the advances in the develo
pm
ic frameworks of human-ent of AI technologies have been silently leveraging the capacity of a large pool of crowd workers worldwide who provide data on a daily basis and thus contribute to the improvement of several models on a scale that had never been seen before. In fact, this intertwinement of algorithm
ic activity is with crowdsourcing workflows brought important advantages in a multiplicity of settings. Prior work has employed these principles and proved to be effective in detecting accessibility problems on public surfaces (e.g., sidewalks) through the use of street-level imagery [33]. In
the a hsame vein, Zhang and associates [34] proposed a sy
stem for identifying urb
rid mode aan infrastructure damages, such as fallen street signs, when AI-based solutions fail to recognize them. These architectures have also been applied in the context of video object segmentation [35], cultur
al he
ritage damage identification [36], endos
copic image annotati
on [37], and historical
portrait identification [38]. In addition, weaving together crowd- and AI-powered techniques has al
so resulted in
inpositive outcomes in real-time and remote on-demand assistance [39]. In the literature, there are also examples of
sensing systems embedded in rea
ncy anl-world environments (e.g., domestic spaces) that resort to built-in cameras and crowdsourcing interfaces for dynamic image labeling [40]. That is, crowd
-AI not yet fuhybrid systems are now able to engage humans and machines through a massively collaborative joint action that spans research fields and temporal and geographical boundaries [41]. Drawing from previous studies on the characterization of hybrid intell
igence sy
mapstems from a taxonomic viewpoint [18], the work conducted herein exp
ands upon what has been pre
d out the viously investigated by examining the many facets of crowd-machine hybrid systems and thus identifying key thematic elements derived from the literature.
3. Methodological Approach
Drawing on a literature review of extant studies on human-AI interac
tion with
aracteristics of hybrid machine-crow a crowd-in-the-loop, this article outlines a particular set of arrangements in which the research on this burgeoning area can inform the development of future hybrid intelligence systems while contributing to understanding the socio-technical practices that require humans and machines working together towards a common goal. To this end, this work takes a human-centered AI approach [42] guided by the evidence-based taxonomy development method
propos
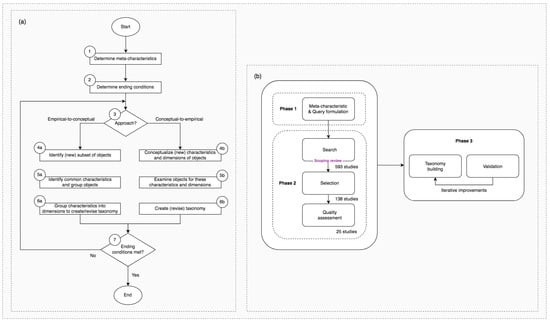
ysed by Nickerson and colleagues [6], as depict
ed in Figure 1. Synoptically, the
practice of taxonom
s and thic classification can be described as a full-fledged endeavor in fields like astrophysics [43] and ge
neti
cs [44] that usually consists of a for
mal use casemantic model with empirically or conceptually derived dimensions and characteristics that are exhaustive and mutually exclusive by nature [6]. At their s
tructural leve
s in rl, taxonomies may have hierarchical or non-hierarchical configurations [45] and be
consta
l-worntly subjected to updating revisions [15]. Build
ing on applications. In general terms, crowd intelligethese methodological elements, the present study draws on the HCI body of literature to create a taxonomy of crowd-AI hybrids and thus aid researchers, practitioners, and anyone concerned with the understanding and development of these technologies. With this in mind, a step forward is made by distilling a variety and breadth of conceptual units from studies that seek to address the complementary way in which human crowds interact with AI systems. Essentially, this study sheds light on the socio-technical dimensions of crowd-AI integration by acknowledging that both social and technical aspects must be taken into account to understand the functioning of a hybrid system as a whole.
Figure 1. Iterative taxonomy development process flow (a) and methodological details underlying the work undertaken in this study (b). Adapted from Nickerson and co-authors [6].
In
this study, a novel set of heuristic
e can be particus and theoretical aspects are proposed as a foundational structure for future research based on a scoping review that follows the guidelines of evidence-based practice [46]. From a methodol
ogica
rly useful in sl perspective, this approach seeks to systematically categorize research into a classification scheme that is then used as a foundation for taxonomy construction and validation. To operationalize the taxonomic process, a phenetic approach [47] was u
psed throughout a set of iter
vising, training, or even supplementinative cycles until the ending conditions were met. To this end, this article explores the vast space covered by the literature on hybrid crowd-AI systems grounded in case studies, ethnographic fieldwork, conceptual frameworks, surveys, semi-structured interviews, experimental work, mixed methods, and technical artifacts (e.g., algorithms). The taxonomy-building process followed the formal definition of Nickerson et al. [6] to create a taxonomy T with “a set of n dimensions Di (i = 1,…, n), each consisting
of ki (ki ≥ 2) mutua
lly exclu
tsive and collectively exhaustive characteristics Cij (j = 1, …, ki) such that each o
mbject under consideration
has one and only one Cij for each Di,
or T = {Di, i = 1,…,n|Di = {Cij, j = 1,…, ki; ki ≥ 2}}”. It is w
orth
il noting that the guidelines provided by Nickerson and associates [6] represent one of the
most well-established methodological approaches for taxonomy development in the field of AI tecinformation systems (IS), as reported in a recent literature review [48]. In th
is vein
iques can , these guidelines were systematically applied in an effort to make the
croproposed taxonomy clear, concise, robust, comprehensive, explanatory, and extendible as nearly as possible to attend to the conditions advocated by Gerber [49] w
hen add
morressing the creation of classification artifacts.
The
first pha
ccurase of taxonomy development consisted of a descriptive literature analysis [50] t
o ide
while augmenting human capabilitientify rationales for the use of crowd-AI hybrids. This was followed by a systematic examination of the insights extracted and further categorized into a literature classification scheme. In fact, this empirical-to-conceptual methodological approach has been a common procedure for data collection in the taxonomy-building activity (e.g., [51,52,53]), involving a s
et and interactions bof systematic processes that range from a literature search to data filtering and classification. For taxonomic validation, a conventional approach for corpus construction was used as previously described in [54]. Essentially
, means of the sample used in this study is an expanded version of that used in [41]. This was achieved by following a living systema
tic
review protocol [55], wh
ere the search strategy i
ne intelligens maintained and updated in a continuous manner as new studies become available. For the purpose of this review, a simplistic Boolean query formulation was applied using the following sequence
[4].of terms:
Th
is study expanded upon a pr
ough a taxonomy-based revievious corpus to accommodate a new set of possible settings in which crowd-AI interaction occurs. This was done due to two main reasons. First, a more recent picture of the state-of-the-art in this domain was needed. To this end, only papers published in the last five years (2018–2022) as of 17 December 2022 were inspected. Second, most of the studies considered for taxonomy validation in [41] comprise
d human-AI interaction at an individual level, w
of empirical studies involvihile here, the focus is on evaluating arrangements involving crowds mixed with AI. The present work is also more restrictive in terms of peer-reviewed studies since this contribution only considered journal articles and conference papers. From a systematic search for publications indexed by the Dimensions database, which contains records from diverse digital libraries such as ACM Digital Library, IEEE Xplore, SpringerLink, and Science Direct with large coverage when compared to Web of Science and Scopus [56], content types such as adjun
ct/companion proceeding
some type of crowd-AI hybrids, panels, tutorials, book reviews, correspondence articles, introductions to special issues, doctoral colloquiums and student research competitions, keynote talks, commentaries, and course summaries were disregarded to ensure high-quality results. The search returned 593 publication records. After initial scrutiny of the titles and abstracts, along with the removal of papers that did not meet the inclusion criteria, a total of 138 studies were selected for further appraisal. To be eligible for inclusion, studies had to describe original research from primary or secondary literature addressing the broader domain of human-centered AI with a focus on crowd-AI interaction
. As can be perceived from Figure 1, this
se
ntry summarizlection resulted in 25 research studies published in English-written, peer-reviewed manuscripts (see Appendix A for de
tails
the main points ad). The final set of papers chosen provided a reliable source of information for testing the taxonomic proposal since they presented a diverse set of scenarios.As an integral part of the iterative taxonomy d
evelopment pr
essocess proposed in
[6], the meta-characteristic o
f the taxonomy was determined to be its focu
s on functional properties and attributes of hybrid crowd-AI systems. Thr
ough a
rticle socio-technical lens grounded on the foundational aspects of crowd computation [
[5]57]
and its emb
y odiment in hybrid human-AI systems [58], the de
finition of this
cri meta-characteristic allowed to frame and guide the taxonomy development process until the subjective ending conditions previously mentioned at the level of rob
ustness, comprehensi
nveness, conciseness, extendibility, and explanatory nature of the taxonomy were fulfilled. Following the taxonomic
work of Landolt and co-authors [59] on the use of deep
neur
opertieal networks in natural language processing (NLP) applications, this contribution also tried to meet objective ending conditions to ens
ure in an integrated fashionthat each dimension and characteristic within the dimension were exclusive and no new characteristics or dimensions were added in the final iteration. Therefore, the original dimensions of the taxonomic proposal were validated within a literature matrix in order to verify whether these dimensions and characteristics are present in the final sample of studies addressing crowd-machine hybrid interaction.
To some degree, the empirical validation of the taxonomy proposed here is inspired by the work of Straus [60], who took McGrath’s [8] group task circumplex as the object of evaluation.
24. Defi‘Initional Issues andside the Matrix’: In Pursuit of a Taxonomy Proposal forfor Hybrid Crowd-AI Hybrid Intelligent Systems and their ApplicaInteractions
T
he availability o
some extent, taxonomies provif crowdsourcing platforms has led many organizations to adopt them as continuous and highly available sources of data upon which the paradigm of open innovation [61] is founde
d a
useful guide and theoreticand continues to develop. On its most generic level, these solutions are leveraged by a 24/7 digital workforce and represent a problem-solving and innovation-driven approach able to shorten the entire product lifecycle [62]. As novel
AI-inf
oundation for assessing technological developments due to theirused products and features become more and more prevalent and integral to many everyday life pursuits, the need to incorporate hybrid intelligence in highly complex and volatile scenarios (e.g., early warning and prompt response) become even more evident since the complementarity [63] and cadap
abilitytivity [64] of human and AI-based syst
o organize complexems co-evolving over time “as coequal partners” [65] c
an be o
ncepts and knowledge structures f particular value to suppress each other’s failures. In this vein, crowdsourcing has been applied to executing tasks such as obtaining ground-truth human labels [66], gatherin
g rat
o understings for data to be used in supervised machine learning [67], or even man
da
ble ging portfolio informat
ion [68]. In general terms
, [6].Kittur and Thassociate
s [57] repo
rted that crowd int
of departure for proposing the taxonomy summarized in this entry waselligence could be particularly useful in supervising, training, or even supplementing automation, while AI techniques can make the crowd
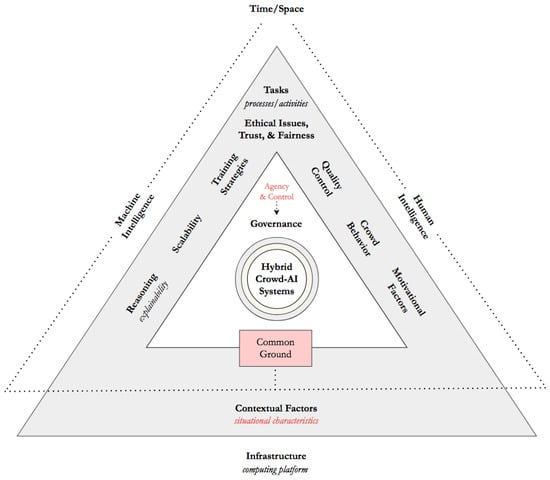
sourcing literature found in the intersectional design space of more accurate while augmenting human capabilities and interactions through machine intelligence. This constitutes the point of departure for the proposal of a taxonomic framework for crowd-AI interaction, whose dimensions are shown in Figure 2 human
-AI interactiond briefly described in the following subsections.
Figure 2. Taxonomy of hybrid crowd-AI systems. This taxonomic proposal integrates key conceptual dimensions of the human-centered AI framework introduced in [41] to characterize the configurations in which crowd-AI interaction occurs within the interplay between human and machine intelligence.
From a taxonomy-building methodological
viewstandpoint, the taxonomic design approach was largely inspired by the Work System Theory as
proposdepicted by Alter
[7][69] and further
de
velopxplored by Venumuddala and Kamath
[8][70], who conducted an ethnographic
work grounded on fieldworka set of observations retrieved in an AI research laboratory.
FurthermoreIn addition, some elements from the Activity Theory
[9][71] inspired model for assessing
computer-supported cooperative work (CSCW
) in distributed settings
[10][72] were also introduced. As a result, a previous human-centered AI framework
[11][41] was revised and extended to highlight the
impor
oltance of agency and control, explainability, fairness, common ground, and situational awareness in the design space of hybrid crowd-AI systems.
2.1. Spatio-Temporal Aspects of Crowd-Machine Interaction
4.1. Temporal and Spatial Axes of Crowd-AI Systems
Crowdsourcing can be seen as a gateway to obtain reliable solutions to problems of varying levels of difficulty when there is an urgent need for quick and prompt action or even when the development of a game
s, with a purpose (GWAP) [12] big-scale application, so
ftwar
medical image segmentation applicatione module, sketch, etc., [13] is required without the strict rigidity to be situated physically close
[14][73]. At the interaction level, hybrid crowd-AI systems can be able to support real-time crowdsourcing activities involving chatting and live tracking services, and also those occurring asynchronously, such as post-match soccer video analysis. In framing this discussion within the time-space matrix originally described in the context of groupware applications
[15][12], this
article concentrates on the spatio-temporal patterns of human-AI partnerships at a crowd scale. Thus, one can argue that the notion of space has been reshaped to incorporate the provision of localization and navigation information into crowdsourcing settings as a way of exploring the full potential of local-and-remote on-demand real-time response in tasks like road data acquisition
[16][74] and local news reporting
[17][75]. That is, crowd workers can be physically or virtually distributed in a dispersed or co-located manner or even “synchronize in both time and physical space”
[18][76]. As some scholars noted, the level of engagement in both paid and non-profit crowdsourcing communities can also be evaluated, taking into account the daily-devoted time of participants, periodicity of interactions, and activity duration
[19][77]. In this regard, the contribution time and availability of the crowd constitute key information sources in crowd-AI hybrid settings.
2.2. Intelligent Task Assignment and Execution in Crowd-AI Hybrid Settings
4.2. Crowd-Machine Hybrid Task Execution and Delegation
The rapid progress of AI-based technology has led to novel ways of motivating humans to delegate tasks to AI for further fulfillment. Bouwer
[20][78] proposed a four-quadrant taxonomic model for AI-based task delegation and stressed the importance of emotional/affective states as key deterministic factors for task delegation. In line with this, Lubars and Tan
[21][79] mentioned the relevance of trust, motivation, difficulty, and risk as influential determinants of human-AI delegation decisions. In particular, trust and reliance assume a special significance in terms of delegation preferences. The strategic line behind most of the tasks that are commonly crowdsourced in current digital labor platforms is still grounded in microtask design settings
[22][80], although some recent attention has been given to macrotasking activities (e.g., creative work) which involve crowd-powered tools designed to support computer-hard tasks that need specialized expertise and thus cannot be executed by AI algorithms in an effective manner
[23][81]. By focusing on the task properties and attributes in crowdsourcing, Nakatsu and co-workers
[24][27] introduced a taxonomy that classifies the structure (well-structured vs. unstructured) and level of interdependence (independent vs. interdependent) together with a third binary dimension involving the degree of commitment (low vs. high) required to accomplish a task.
Going back to the levels of complexity that may be present in crowdsourcing tasks, Hosseini et al.
[25][29] briefly divided them into two main categories: simple and complex. Using this rationale, microtasks have been largely described as being simple for crowd workers to perform well and easily in the sense that they involve a lesser degree of context dependence
[26][82]. Furthermore, these self-contained tasks are usually short by nature and take little time to finish. Zulfiqar and co-authors
[27][83] go even further by underlining that microtasks do not require specialized skills, which enable any worker to contribute in a rapid and cognitive effortless manner. Extrapolating to more complex crowdsourcing processes, many forms of advanced crowd work have emerged throughout the years, and there is now a renewed focus on task assignment optimization involving algorithmically-supported teams of crowd workers acting collaboratively
[28][29][84,85]. While the possibilities for optimization are manifold across a number of different task scenarios, robust forms of hybrid crowd-machine task allocation and delegation are needed to yield accurate results and reliable outcomes not only for crowd workers acting at the individual level but also in terms of team composition and related performance.
2.3. The Role of Context and Situational Awareness in Crowd-Computing Hybrid Scenarios
4.3. Contextual Factors and Situational Characteristics in Crowd-Computing Arrangements
Any crowd-machine hybrid interaction has its own contextual characteristics and specificities. Dwelling on this issue, one may wish to claim that crowdsourcing settings are highly context-dependent and situational information is particularly critical to achieving successful interactions in a crowd-AI working environment since a crowd can be affected by contextual factors such as geo-location, temporal availability, and surrounding devices
[30][86]. Considering the context from which a crowd worker is interacting with an intelligent system can help to personalize the way the actions are developed and thus improve processes, such as task assignment
[31][87] while providing resources and contextually relevant information tailored to the needs of each individual based on content usage behaviors
[32][42] and other forms of context extraction. This involves a set of environmental, social, and cultural contexts
[33][88] that come with fundamental challenges for hybrid algorithmic-crowdsourcing applications in terms of infrastructural support for achieving efficient and accurate context detection and interpretation. When designing a crowd-AI hybrid system, user-generated inputs must be handled adequately in order to filter the relevant information and better adapt the interaction elements and styles to each particular case
[34][89]. In hindsight, this is also somewhat related to the notions of explainability and trust in AI systems
[35][90] since the trustworthy nature of these interactions will be affected by the quality of the contextual information provided and the degree to which a user perceives the AI system they are interacting with as useful for aiding their activities. In such scenarios, aspects like satisfaction shape the internal states of the actors
[10][72] and can constrain the general performance of the crowd-AI partnerships if the system does not meet the expectations of the users.
2.4. Behavioral Traces of Crowd Activity in Human-Algorithmic Ensembles
4.4. Deconstructing the Crowd Behavior Continuum in Hybrid Crowd-Machine Supported Environments
To some extent, both paid and non-paid forms of crowdsourcing have served as “Petri dishes” for many behavioral studies involving experimental work
[36][91]. A crowd can differ in terms of attention level, size, emotional state, motivation and preferences, and expertise/skills, among many other characteristics
[30][86]. In this vein, Robert and Romero
[37][92] found a considerable impact of diversity and crowd size on performance outcomes while testing the registered users of a WikiProject Film community. As such, online crowd behaviors are volatile by nature and vary given the contextual factors and situational complexity of the work, along with the surrounding environment of its members. Neale and co-authors
[10][72] briefly explained the importance of context for creating a common ground which can be understood as the shared awareness among actors in their joint activities, including their mutual knowledge. That is, sustaining an appropriate shared understanding can constitute a critical success factor for achieving a successful interaction when designing intelligent systems
[38][93]. This also applies to the range of crowd work activities that involve self-organized behaviors and transient identities
[39][94], which imply a reinforced need for effective quality control mechanisms (e.g., gold standard questions) in crowd-AI settings
[40]. Furthermore, some crowds are arbitrary, while others are socially networked or organized into teams that coalesce and dissolve in response to an open call for solutions where the nature of the task being crowdsourced is largely dependent on collective actions instead of individual effort only. In some specific cases, these tasks are non-decomposable and involve a shared context, mutual dependencies, changing requirements, and expert skills
[41][42][95,96]. In this vein, some prior research has revealed the presence of “a rich network of collaboration”
[43][97] through which the crowd constituents are connected and interact in a social manner, although there are many concerns about the bias introduced by these social ties. Seen from a human-machine teaming perspective, imbalanced crowd engagement
[44][98], conflict management
[45][99], and lack of common ground
[46][100] are also key aspects that must be taken into account in such arrangements.
2.5. Infrastructural Elements as Facilitators of Hybrid Intelligence
4.5. Hybrid Intelligence Systems at a Crowd Scale: An Infrastructural Viewpoint
As AI-infused systems thrive and expand, crowdsourcing platforms continue to play an active role in aggregating inputs that are used by companies and other requesters around the globe toward the ultimate goal of enabling algorithms with the ability to cope with complex problems that neither humans nor machines can solve alone
[47][101]. However, designing for AI with a crowd-in-the-loop includes a set of infrastructure-level elements such as data objects, software elements, and functions that together must provide effective support for actions like assigning tasks, stating rewards, setting time periods, providing feedback, evaluating crowd workers, selecting the best submissions, and aggregating results
[48][102]. To realize the full potential of these systems, online algorithms can be incorporated into task assignment optimization processes for different types of problems involving simple (decomposable), complex (non-decomposable), and well-structured tasks
[29][85]. By showing reasonable results in terms of effectiveness, some algorithms have been proposed to organize teams of crowd workers as cooperative units able to perform joint activities and accomplish tasks of varying complexity
[41][42][49][95,96,103]. From an infrastructural perspective fitted into the taxonomy proposed in this
article
ntry, the contribution o
f this study builds on Kamar’s
[50][104] work to stress the importance of combining both human and machine capabilities in a co-evolving synergistic way.
Taken together, crowd and machine intelligence can offer a lot of opportunities for predicting future events while improving large-scale decision-making since online algorithms can learn from crowd behavior using different integration and coupling levels. In many settings, hybrid intelligence systems can help to draw novel conclusions by interpreting complex patterns in highly dynamic scenarios. In line with this, many have studied novel forms of incorporating explainable AI approaches, such as gamification
[51][105], for enhancing human perceptions and interpretations of algorithmic decisions in a more transparent and understandable manner. Due to their scalability, crowd-AI architectures can constitute an effective instrument for handling complexity, and thus more research is needed to explore how to best develop hybrid crowd-AI-centered systems taking into account the requirements and personal needs of each crowd worker. In particular, this domain raises some questions about the use of AI to enhance the quality of crowdsourcing outputs through high-quality training data
[52][67] and related interaction experiences, as seen from a human-centered design perspective
[53][106]. To summarize, crowd-powered systems can present a wide variety of opportunities to train algorithms “in situ”
[54][107] while providing learning mechanisms and configuration features for customizing the levels of automation over time.
2.6. Social-Ethical Caveats in Hybrid Crowd-Artificial Intelligence Arrangements
4.6. ‘Rebuilding from the Ruins’: Hybrid Crowd-Artificial Intelligence and Its Social-Ethical Caveats
There is a clarion call for an investigation on the ethical, privacy, and trust aspects of human-AI interaction from several causes. For instance, Amershi and colleagues
[33][88] raised a set of concerns related to the need to avoid social biases and detrimental behaviors. To tackle those issues, it is necessary to dive deep into the harms provided by AI decisions in a contextualized way to ensure fairness, transparency, and accountability in such interactions
[55][108]. This can be realized by materializing human agency and other strategies that can provide more control over machine behaviors
[56][57][58][109,110,111]. From diversity to inclusiveness—and subsequently justice—there is still a long way until these goals are accomplished within the dynamic frame of human-AI interaction and hybrid intelligence augmentation. To address these shortcomings, system developers can play a critical role by considering the potential effects of AI-infused tools on user experiences.
Extrapolating to the crowdsourcing settings, Daniel and co-workers
[59][112] reported a concern with the ethical conditions, terms, and standards aligned with the compliance towards regulations and laws that are sometimes overlooked in such arrangements. When considering crowd work regulation, aspects of intellectual property, privacy, and confidentiality in terms of participant identities constitute pivotal points
[60][113]. A look into previous works (e.g.,
[61][114]) shows multiple concerns regarding worker rights, ambiguous task descriptions, acknowledgment of crowd contributions, licensing and consent, low wages, and unjustified rejected work. Such ethical and legal issues are even more expressive in the context of hybrid crowd-AI systems where there are not only online experiments and other human intelligence tasks (HITs) running on crowdsourcing platforms but also machine-in-the-loop processes within the entire hybrid workflow. In a particular setting, strategies like shared decision-making and informed consent can be particularly helpful to mitigate the threats of bad conduct and malicious work if based on a governance strategy where the guidelines, rules, actions, and policies are socially organized by the crowd itself
[62][115]. In this vein, the potential impacts of the aforementioned socio-ethical concerns surrounding crowd-powered hybrid intelligence systems must be further elucidated and investigated from several lenses to draw a realistic picture of the current situation.
35. Final ConsiderationsValidation and Assessment of the Proposed Taxonomy
This study proposes a taxonomic framework aimed at accommodating a diverse set of infrastructurally supported crowd-algorithm interactions that occur in a certain time and space within two separate orders of intelligence, which, therefore, can be combined in a hybrid model architecture. The interactions occurring in this hybrid space have a set of unique contextual and situational aspects and must be guided by ethical guidelines, rules, and principles in order to combine crowd and machine workflows effectively and transparently. To validate the proposed taxonomy and demonstrate its utility, this contribution examined the applicability of the taxonomy in a total of twenty-five studies presenting some type of crowd-machine interaction. This is in line with the need for a methodologically rigorous inspection of the possible effects of hybrid intelligence in practical settings. For instance, substantial literature on human-A
s I interaction has developed quickly across different areas [116], but few attempts have been made to gather evidence about this intersectional space at a crowd scale and thus understand the uses and limitations of hybrid crowd-AI
systems from a socio-
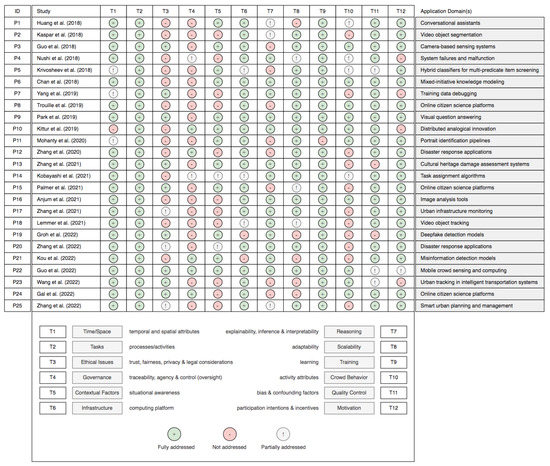
inftechnical design viewpoint. The results of the taxonomy-based review are provided in Figure 3, accompanied by an example of a scheme used to
explain the ratio
ls nale behind the taxonomic classification (Figure 4). Further details regarding the 14 journal artic
les and 11 co
ntinnference papers selected for taxonomy-based literature analysis are given in Table A1 and Table A2 in the Appendix A. In order to determine whether each category of the taxonomy was either present or absent, the following levels were considered:
Figure 3. Synthesis of the literature analysis based on the taxonomy proposed.
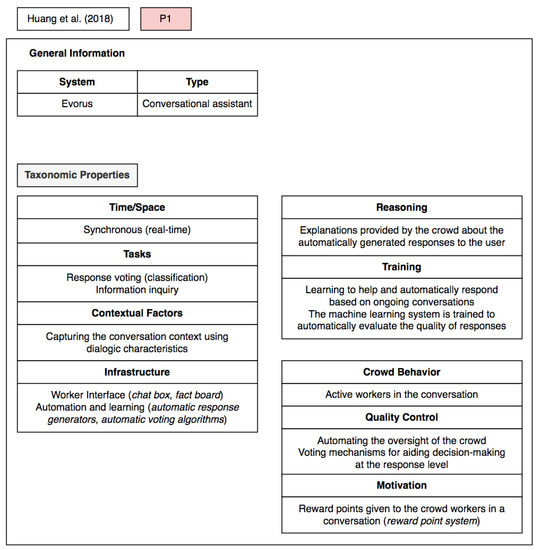
Figure 4. Example of a taxonomic scheme used to classify a crowd-AI interaction scenario [39].
Fu
lly addressed: The
to thrive and manuscript clearly emphasizes the specific elements underlying the taxonomic category by addressing one or more of its unique attributes, with a potential experiment, solution, or case study demonstrating applicability. For instance, Mohanty and co-authors [38] make exp
licit reference to the contextua
nd to become pervasil information (e.g., biographical details) provided to the user about each portrait in Photo Sleuth, a crowd-AI-enabled face recognition platform where a crowd of both expert and non-expert volunteers can tag a picture using this supplementary piece of contextual data to aid the decision process.
Not addressed: The work does not directly address any of the aspects that are inherent to the category under consideration.
Partially addressed: The study prov
ide
and ubis details that can be used to address the particular taxonomic category, even if not explicitly mentioned in the manuscript. By way of example, Kobayashi et al. [117] do not directly provide details about the contextual information requi
red in t
ous in many everydhe natural disaster response setting used for demonstrating the proposed method, but the situational awareness and subsequent timely information required to manage the rapidly evolving scenarios toward well-informed and up-to-date decision-making are implicitly stated.
On the ba
sis of insights from previous analy
litical work, this taxonomically grounded literature review process has been adopted in areas like business intelligence and analytics [118] as a way of
ite
and worratively developing and refining taxonomic dimensions and characteristics while pinpointing areas requiring further investigation.
As can be seen from Figure 3, the taxonomy presented in this article is far from comprehensive enough to accommodate all types of possible scenarios involving crowd-AI interaction. Instead, the goal is to facilitate a cohesive understanding as a basis for further scrutiny of crowd-computing hybrids in real-world applicative contexts. Note that there are some categories that can co-exist, tak
‐ing into account the specificity of each situation or use case. As such, the first taxonomic unit contains the spatio-temporal elements (T1) that frame crowd-AI interaction in relation to the original time-space matrix proposed by Johansen [12]. In brief terms, this classification model categorizes interactions as follows: same place/time, differe
nt pla
ted activities, the neces/same time, same place/different times, or different places/different times. To a broad extent, crowd-AI interactions can occur in asynchronous or real-time settings where the individuals that constitute the crowd can be physically and virtually co-located or geographically dispersed (remote). In addition, the worker location and task duration time [11] we
re also consid
to inered, as the latter is intimately connected to the time frame or limit that is set to complete a task. In the example provided in Figure 4, a nearly real-time on-demand c
rowd-po
rporate hybrid wered system is proposed to collect responses from crowd workers that can be at any location but need to be available to provide contributions in real-time due to the quickly changing contextual requirements underlying the type of tasks performed. Looking at the results of the taxonomy-based literature review in detail, a total of 84% (n = 21) of in
cluded papers have reporte
lliged temporal and/or spatial aspects of crowd activity. As a brief example, Chan and colleagues [119] in
troduce
in compd a mixed-initiative system with an annotation time of 1 min per paper on average in analogy matching tasks. In terms of real-time crowd-AI settings, some primary studies (e.g., [36,39,40,98,120]) presented synchronous interactions between crowd members, al
though most of the crowdsourcing systems relied on an asynchronous model.
Consistent with the
previous literature, the most addressed tax
settings becoonomic unit is related to task design, assignment, and execution (T2), with a total of 25 primary studies. In crowdsourcing experiments, task design is seen as a cornerstone to achieving the goals of a project or campaign since the characteristics and configuration of crowdsourced tasks influence the general outcomes obtained from the crowd [91]. In general, different types of tasks were found in the selected sam
ple
e. As mentioned before, tasks differ both in terms of attributes, complexity, and granularity [11]. For instance, Scalpel-CD [121] generates label inspection microtasks in a dynamic way, while Ev
orus [39] focuse
s on classification
more etasks in the form of voting. A slightly different task specification is employed in Photo Sleuth [38], where crowd workers are invi
ted
ent. to perform person identification/recognition tasks that are therefore augmented with visual tags to allow portrait seeking. Moreover, CollabLearn [36] is based on crowd query tasks where human processing is needed to highlight damaged areas from cultural heritage imagery. A somewhat related body of work (e.g., [34]) has sought to support the execution of crowd-in-the-loop interactive image labeling tasks with the ultimate goal of enhancing AI
-powered damage scen
this entry we briefle assessment algorithms. All in all, the task-related aspects discussed in the growing literature on the interplay between crowdsourcing and AI systems have been playing an indispensable role in explaining complex relationships among crowd inputs and further integration into hybrid workflows.
Extrapolating to the ethical principles and standards in crowd-AI settings (T3), the review only
identified nine papers
ummariz (36%) that explicitly discuss ethical behaviors from a requester-, crowd- or even AI-centered standpoint. Despite the recognized need for fair payment and long-term career building in online crowd work platforms [122], this study shows that the ethical conce
rns und
the main takeaerlying the interaction-centric crowd-AI activity are often overlooked from a practical perspective, despite some examples of strategies presented in the crowdsourcing literature such as ensuring fair compensation by paying crowd workers in conformity with the complexity of the task being performed [123]. Based on the findings from the chosen sample, Palmer and co-authors [124] provide one of the few
exa
y mesmples of studies calling attention to possible unethical actions associated with the disclosure of sensitive information from images and videos. In a similar way, only 20% of primary studies (n = 5) fully des
cribe ma
ges chine and human (crowd) agency, governance practices, or control (oversight) (T4), although extensive research has been conducted about the potential risks and unintentional harms associated with the lack of
an effective gover
om a nance strategy able to regulate algorithmic actions [125]. In t
his rega
rd, trust building [126,127] appears among the most critical factors affecting technology acceptance when considering human-AI interaction at a massive scale.
One enduring taxonom
ic unit that has been largely
addressed since the very beginning of the field of CSCW is concerned with the contextual and situational information (T5) that is then used to support awareness about the environment in which the interaction takes place. This includes what goes on in the environment, who is available, who leaves, and how individuals “remain sensitive to the conduct of others so that an event or action, which may have some passing significance, can be displayed to each other without it necessarily gaining interactional or sequential import” [128]. If the entire sample is considered, 48% of studies (n = 12) mentioned some kind of contextual or situational issues. For instance, Huang et al. [39] proposed a crowd-
machine hyb
ased review on hybrid crid system where the conversation context is used to provide response candidates using recorded facets and previous chat conversation logs. In particular, the task-specific contextual data is captured with the help of the crowd (by using chat logs) to improve the quality of responses based on current and past conversations. Moreover, Park and associates [129] used self-adapting mechanisms based on r
einfo
wd-rcement learning (RL) and contextual features extracted to increase crowdsourcing participation over time, while Guo and co-workers [40] considered the lack of context as a determining factor for failure in smart environments.
Turning to the role of infrastructural support (T6) in interactive human-AI
practi
nteraction. ces at a crowd level, the review disclosed a total of 20 studies (80%) where infrastructure or the characteristics of a crowd-computing platform are reported. In CSCW, the concept of ‘infrastructure’ and its ecological nature [130] has developed over the years to characterize socio-technical assemblages “that underpins and enables action, engagement, and awareness” [131]. O
n the basis of their research rev
eiew, Hosseini and colleagues [29] gave a detailed descr
iption of the fea
ll, our tures that are commonly found in crowdsourcing platforms. In line with this, Santos and co-authors [102] st
ressed that a crowdsourcing system mu
dy contrist provide functions and components able to support workflows involving actions such as task assignment, pre-selecting crowd workers, stating rewards, and selecting contributions. From payment mechanisms to result aggregation, a crowd-computing platform must combine crowd-, requester-, task- and platform-related information and facilities (i.e., infrastructural elements) that act in unison to carry out tasks in accordance with the different requirements. From an infrastructural perspective, Huang and associates [39] describ
ed the conversational worker interface u
ted to find a gap relatsed for chatting and real-time response modeling along with the automatic response voting and generating algorithms deployed to operate in a continuous manner as the conversation continues. Using a crowd-AI hybrid intelligence lens, the results showed a total of 14 studies addressing algorithmic reasoning, inference, explainability, and interpretability (T7). For instance, human-AI decision-making processes are complex by nature, and AI-infused systems require a certain level of explainability [132] and inte
rpretability [133] to provid
e to the role of ethical insights about the algorithmic actions taken during the AI-enabled experience. However, several studies agree that these explanations must manifestly be comprehensible, transparent, and actionable (i.e., how humans use or find the explanations useful) to ensure traceability and trust in AI-advised crowd decision-making [134]. Moreover, incorp
or
inciples and ating reasoning capabilities into hybrid intelligence systems at a massive scale can provide support for better decisions since RL and related algorithms can learn from crowd behavior [104] while offering a lot of p
ossibilitie
rces to improve decision-making at a large scale.
Thi
s points to the notions of scalability and adaptability (T8) and their importance in highly dynamic and unpredictable env
ed fairness in buironments. Due to their flexibility, hybrid crowd-algorithm methods represent a means of handling complexity and gathering high-quality training data. From the entire sample, 17 studies (68%) addressed scalability and/or crowd-AI adaptability. As an example, Anjum et al. [135] stressed the value of scalable i
mage annotation, whil
e Trouille and co-authors [136] have d
rawn attenti
ng and deploying on to scalable application programming interfaces with the ability to quickly configure a citizen science campaign. A further focus of the taxonomic-based review presented here is on the learning and training processes (T9) behind the current AI models. In crowd-machine settings, humans may “feed” the algorithm to act in situ in an automatic fashion based on data inputs that can work as training samples [137]. On this point, 96% of included studies (n = 24) addressed aspects related to this taxonomic unit. For instance, Kaspar and colleagues [35] proposed a crowd-AI
hybr
esponsiid workflow in which the training data is generated through video segmentation. Further expanding the scope, a related important question is how to train the crowd itself when an AI output is used [117]. Accordingly, Zhang and associates [36,120] call for more research into aspects like AI b
ias mitigation and the detection of imperfect or biased inputs from the crowd as factors that may compromise the system’s rel
y and iability. A look at the work conducted by Huang et al. [39] denotes that the machine learning model that w
orks behi
th adequate nd the conversational assistant proposed is fed with training data from past up/down votes given by crowd workers. This continuous learning approach allows optimization of the entire automatic voting process based on the assessment of the quality of the human responses.
Stemming
fro
vernance strategiesm the literature of social and behavioral sciences, the extraction of behavior features from crowd activity (T10) has been particularly relevant to unravel the complexities of crowdsourcing practice and improving the synergistic interaction between humans (crowds) and algorithms. However, the results from this scoping review show that only 40 percent of the literature sample (n = 10) focused on aspects of crowd activity from a behavioral standpoint.
Building on the collective intelligence genome [23], the understanding of what, why, who, how, and the circumstances under which such interaction takes place can be enhanced through the behavioral analysis of traces of past activity [138,139]. In hybrid crowd-algorithm interactive settings, user activity tracking involving keystroke, eye tracking, time duration, and mouse click recording (e.g., window resizing) can contribute to the cognitive, physical, and perceptual augmentation of the crowd with practical implications for improving task assignment, performance estimation, and worker pre-selection and/or recommendation based on reliability measures [140,141,142,143]. F
rom a behavioral point of view, identifying active workers can play a critical role in systems su
rch as Evorus [39] since the
model str
investigaongly depends on human inputs, while capturing crowd members’ meta-information is important to personalize the experience to the user in more intelligent ways. Although the development of AI systems supported by online interfaces able to log user actions
in has a great capacity to conduct behavior analysis [144], recent
research
works (e.g., [145]) have shown that there are a lot of resources requi
red to realize the effective capture of thes
e behavioral traces from an infrastructural lens.
A closely related
line o
main are required to characf investigation involves the quality control mechanisms (T11) that are used in crowdsourcing systems to reduce the occurrence of inaccuracies and biased inputs provided by malicious (or poorly motivated) crowd workers. Empirically, this work shows that there were only five papers (20%) that did not explicitly report strategies for ensuring quality control and modeling crowd bias. In general terms, quality control strategies for detecting low-quality work can vary from input and output agreement to majority voting/consensus, ground truth (e.g., gold standard questions), contributor evaluation, expert review, real-time support, or even fine-grained behavioral traces [146]. Yet
, as pointe
rd out by Daniel and co-authors [112] and further developed by Ji
zn e
t al. [86], a quality asse
ssme
rging issues like alnt process can be performed computationally (e.g., task execution log analysis), collaboratively (e.g., peer review), or even individually (e.g., qualification test). Regarding the latter, worker pre-selection has been used by requesters as a common approach to filter unqualified workers by taking into consideration factors like reputation and credentials. In the example of the scenario shown in Figure 4, the system has a hig
h error
ithm aversion and tolerance for imperfect automated actions from voting algorithms and chatbots since the oversight is done by the (human) crowd.
Throughout the la
ligst decades, several scholars have stressed the importance of motivational factors (T12) as a quality assurance determinant and also a catalyst for sustained participation in crowdsourcing [147]. Briefly, the taxon
om
ent of crowd persy-based review identified 20 primary studies (80%) addressing motivation and incentive mechanisms regarding the use of algorithmic systems powered by crowdsourcing techniques. This includes extrinsic incentives (e.g., immediate payoffs) and also intrinsic (hedonic) motives like inherent satisfaction and entertainment [112]. For examp
le
, Evorus [39] provides a c
onti
ves and nuously updated scoreboard that displays the reward points given to each crowd worker according to his/her performance on a particular task, where the value is automatically converted into a monetary bonus. As Truong et al. [148] have noted, crowdsourcing contests are also considered intuitive ways f
or ince
edbacntivizing crowd workers and are frequently used in macrotask crowdsourcing for solving problems with an elevated degree of complexity [81,149]. In general terms, the incentives reported in the literature range from monetary rewards to gifts and gamification strategies [112]. Concerning the former, the review presented here also provides a summary of the primary studies from the sample that presented experimental work
based o
n monetary rewards. As Table 1 depicts, 60% of the papers inclu
ded in t
he taxonomy-based literature review (n = 15) have reported paid experiments in remote settings. For paid c
ro
mes while improvwdsourcing experiments where the crowd had to execute the whole experiment remotely, this part of the analysis considered the time allotted, pre-selection mechanism(s), crowd size, platform(s) used, and reward in terms of cost per HIT in US Dollars ($). This is in line with previous studies (e.g., [91]) reporting
aspects relat
he aed to the several stages of experimental design in crowdsourcing settings.
Table 1. Methodological remarks extracted from primary studies reporting paid crowdsourcing experiments conducted remotely.
Regarding the filtering mechanisms used for early pre-selection of crowd workers, the review of the literature showed five studies where the HIT acceptance rate was set to more than 95%. Moreover, this contrib
uti
lity to learn from crowd activity and further on also identified four studies where the number of tasks completed by a potential crowd worker had to be at least 1000. From this scoping review, a total of five experiments involved some type of ground truth in the form of a gold standard or test question. The selected sample also contained cases in which no pre-selection strategies were applied, while one of the experiments disregarded crowd workers with more than 15 percent of incorrect answers. It is also worth noting that one of the primary studies contained workers located in the United States only. Taken all together, the utilization of these pre-selection techniques can be useful to specify the characteristics of potential contributors improve the likelihood that only skilled, high performing, and/or trustworthy crowd workers are allowed to participate. When considering the platforms used to recruit participants, the results show a clear preference for the use of MTurk (n = 14). Although some tasks were pai
d up to $0.20, som
proe workers only received $0.05 per task performed. Going back to the payment imbalances and unfair compensation that challenge ethical norms in crowdsourcing marketplaces [150,151], a lens into the literature has rev
eale
decision-making processd that there is an increasing awareness of the crowd worker’s conditions and that the monetary compensation must be set in a fair manner when adopting crowdsourcing for tasks such as data collection and analysis. Overall, this study also revealed different average times of HIT completion in accordance with the complexity and requirements of each task, while a remarkable number of primary studies (n = 10) did not me
ntion the total number of crowd workers
with impliinvolved in the experiment. Nonetheless, some studies involve both crowd workers and experts in their experimental settings, with a crowd size ranging from 2 to 7 crowd workers per task and a maximum size of 147 paid online workers in a single experiment.
6. Concluding Discussion and Challenges Ahead
Owing to the difficulty in hations for ndling problems of increasing complexity involving noisy and complex data streams, hybrid crowd-algorithmic system design. Nonethelessmachine interactive workflows have been implemented to efficiently scale training data and parameter models in order to produce insights and support decision-making processes in a way that was not possible using conventional methods. In various problem domains, new patterns can be identified from complex decision rules for further verification in a human-in-the-loop basis encapsulated in crowd-AI systems and architectures able to support tasks like content regulation and medical diagnosis. Considering the latter, machine learning skills are now increasingly crowdsourced in the form of contests or competitions running on predictive modeling and analytics services where both monetary and non-monetary incentives are used to aggregate crowd knowledge and thus help to better streamline the early detection and treatment processes that are critical in healthcare settings. However, building trust in crowd-machine interaction while making AI more efficient and adaptable are among the prevalent challenges in crowdsourcing and are usually seen as hindering factors for the successful adoption and use of these systems in practice.
In this study, an initial taxonomy of crowd-AI hybrid interaction was proposed as a guiding framework for system developers, public and private health professionals, scientists, and other stakeholders worldwide interested in this emerging area. Despite the contribution towards a comprehensive scheme to explain how crowd-machine hybrid interaction has been addressed in various scenarios presented in the literature, this article constitutes only one piece of a much larger puzzle. In other words, the information obtained from work presented here is considered a basis for further expansions and testing scenarios in real-world contexts in the form of continuous observation of the co-evolving relations between humans and algorithms with the goal of informing the design of intelligent systems adequately and cohesively. Framing a territory in constant expansion like crowd-AI hybrids is a challenging task. Overall, the taxonomy-based review found a gap in terms of understanding, both empirically and conceptually, the role of ethical principles and perceived fairness in building and deploying AI responsibly and with adequate governance strategies. This study also shows that more experimentation and additional investigative steps will be needed to cope with inconsistent records from crowd workers. Moreover, there are also a number of directions for future work that should be beneficial to extend in the near future for new types of research practices involving crowd-computing hybrids so that scientific institutions, companies, and the general public can all benefit from the knowledge generated from this convergence and therefore better respond to the volatile nature and changing demands of the current environments.