Extant biology uses RNA to record genetic information and proteins to execute biochemical functions. Nucleotides are translated into amino acids via transfer RNA in the central dogma. tRNA is essential in translation as it connects the codon and the cognate amino acid. Among the three steps in the central dogma, translation is the most important as it bridges the world of nucleic acids and the world of amino acids. In the “RNA world” hypothesis, RNA came first from the primordial environment, recorded the genetic information, and catalyzed fundamental biochemical reactions. Later, RNA alienated the catalytic function of peptides and proteins and released the information storage function to DNA. DNA self-copy, i.e., replication, and DNA-templated RNA polymerization, i.e., transcription, are more intuitive and practicable in prebiotic settings compared to RNA-coded peptide formation. Translation takes place in the endoplasmic reticulum membrane in the cytoplasm with messenger RNA as the template, transfer RNA as the adaptor, and ribosome RNA as the catalytic core.
1. The Evolution of tRNA
Transfer RNA, the core of genetic coding, is an invaluable molecular fossil that can help in discovering the origin of translation. After revealing the double helix structure of DNA in 1953, Crick
[1][2] proposed that an adaptor-like RNA molecule connected the DNA and proteins. This adaptor-like RNA was then proved by Hoagland et al.
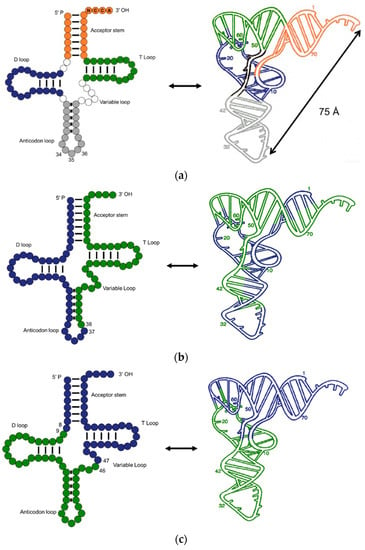
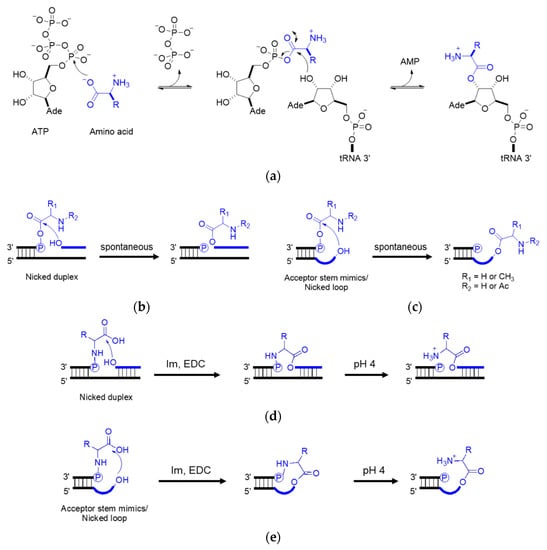
[2][3] and named transfer RNA. Nowadays, the knowledge of tRNA has increased dramatically. A typical tRNA is made up of 76 nucleotides, but the numbers can be 72–96. The classical secondary structure, usually called a “cloverleaf” structure, consists of a CCA end (position 74–76), acceptor stem (1–7 and 67–73), anticodon loop (30–46), T-loop (52–68), D-loop (8–24), and variable loop (
Figure 1a). Although most tRNAs show the classic structure, tRNAs without T-loop, D-loop, or a double helix acceptor stem were identified in the mitochondria of several metazoans
[3][4][5][4,5,6]. When folded up, tRNA adopts a near vertical angle geometry; where the CCA end is 75 angstroms away from the anticodon loop. Magnesium ions play a role in stabilizing the tRNA geometry
[6][7].
Figure 1. Structure and dissections of a type I tRNA from E. coli. (a) Typical cloverleaf 2D and ribbon diagram 3D structure, different loops and stem are colored accordingly; (b) dissection at anticodon loop; (c) dissection at the acceptor domain and anticodon domain.
In extant life, the DNA sequence that codes the tRNA is either separated with introns, fragmented, or rearranged
[7][8]. This is probably the result of the co-evolution of tRNA and RNA splicing endonuclease
[8][9]. Split and fragmentation in tRNA genes are deemed late acquisitions
[9][10] or a vestige of early tRNA
[10][11].
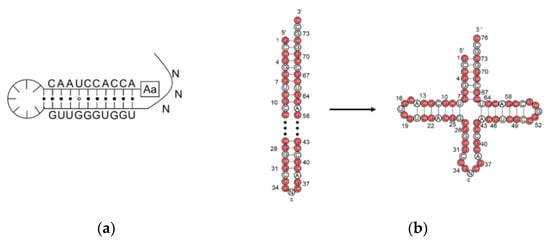
Past decades have witnessed significant progress focusing on the stepwise assembly of tRNA. In the beginning, Woese
[11][19] posited that a subunit of tRNA emerged first and executed a partial role of the extant tRNA. Then, Hopfield
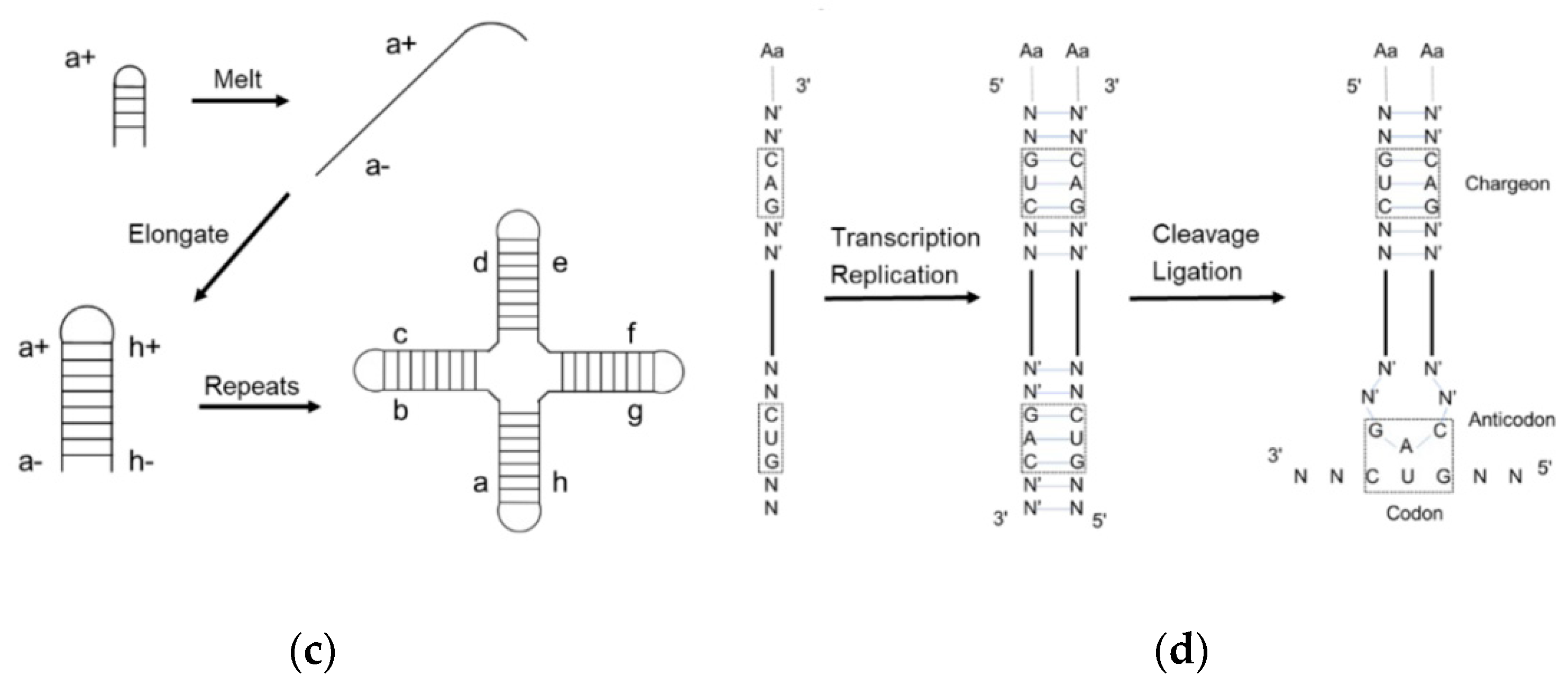
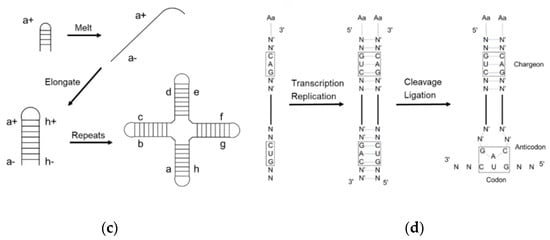
[12][20] suggested that the first primitive tRNA was an RNA hairpin with an amino acid at the 5′-terminus and a foldback overhang on the 3′-terminus (
Figure 2a). The overhang was supposed to interact with and recognize the amino acids. It is a reasonable idea that the hairpin was the most abundant RNA secondary structure in the prebiotic era due to the replication of a single-stranded RNA using itself as the template. However, in the extant tRNA, the anticodon loop is far away from the acceptor stem and any physical interaction is impossible. Although tri-loops are common secondary structure motifs found in naturally occurring RNA
[13][21], the direct interaction of loop would not be limited to a trinucleotide in Hopfield’s model. More nucleobases can be included. Later, Winkler-Oswatitsch and Eigen
[14][22] proposed that the tRNA was made up of a 76-mer hairpin which further assembled the cloverleaf shape tRNA (
Figure 2b). A 39-mer strand, i.e., thirteen RNY-type (purine-N-pyrimidine) triplet nucleotides, acted as the template for the counter strand to form a 78-mer hairpin. Both the Hopfield and Winkler-Oswatitsch models recognized the hairpin as the precursor of tRNA, but the latter model suggested that a long hairpin directly evolved to the extant geometry. Bloch and coworkers
[15][23] postulated a self-priming and self-templating model explaining the formation of tRNA and rRNA (
Figure 2c). A cruciform RNA was generated after three cycles of self-replication and denaturation. The final product is perfectly symmetrical, while the extant tRNA is not. Therefore, it was assumed that the final structure could not be achieved via perfect direct duplication. Moller and Janssen
[16][24] suggested a progressive tRNA evolution model, interpreting the anticodon triplets transited from the acceptor stem to the extant anticodon loop (
Figure 2d).
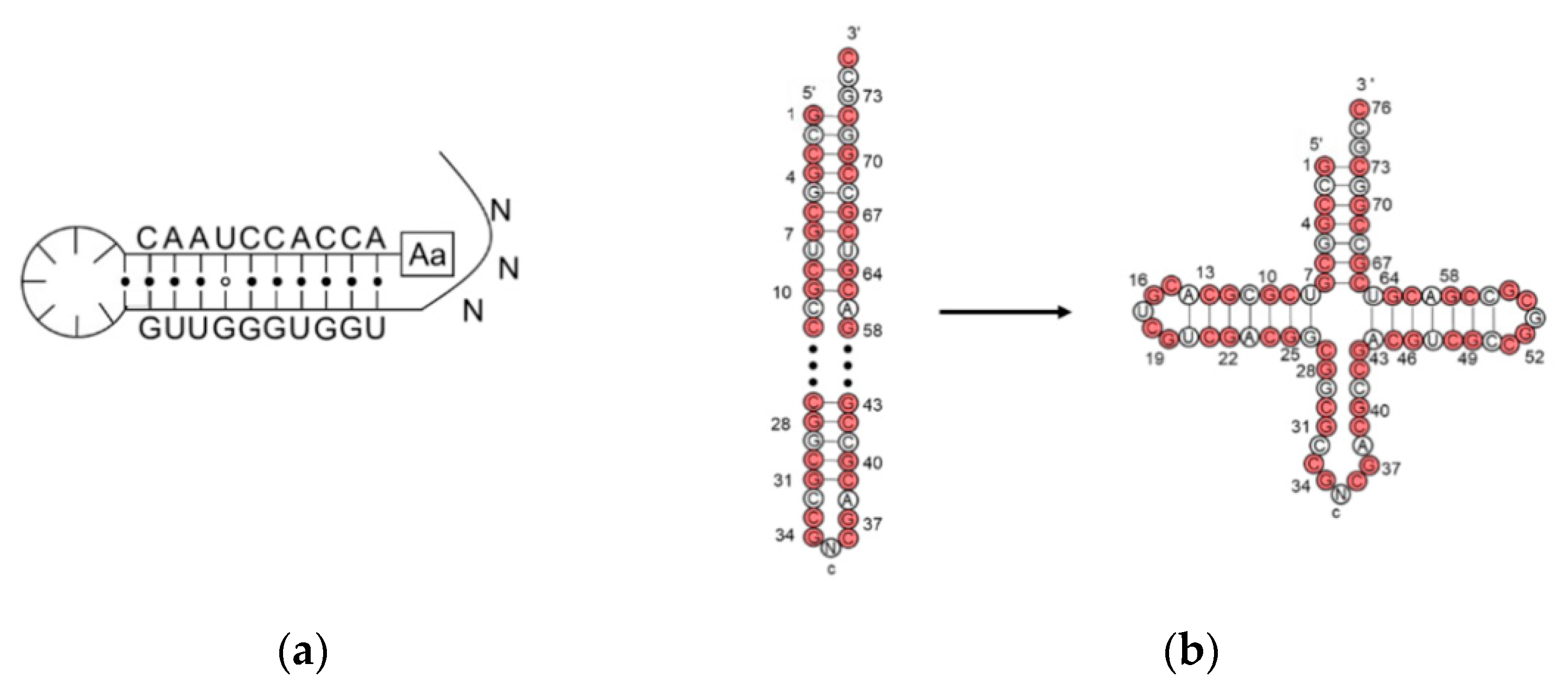
Figure 2. Early models of tRNA evolution. (a) Hopfield model showing trinucleotide interaction with the amino acid at 5′-terminus; (b) Winkler-Oswatitsch and Eigen model showing how tRNA came from RNY-type triplets; (c) Bloch model showing how tRNA came from RNA self-priming and self-templating; (d) Moller model showing how tRNA came from strand replication and ligation.
Contrary to the above models, Maizels and Weiner
[17][31] disassembled the tRNA into two domains, i.e., a conserved top half domain and a non-conserved bottom half domain, connected at the positions 8/9 and 46/47 (
Figure 1c). The top half of the extant tRNA is recognized by aminoacyl tRNA synthetases (aaRS), rRNA, RNase P, and EF-Tu, while the bottom part is an independent hairpin which was incorporated later. Crystallographic studies support the model showing that the energy consumed for rotation of the two halves is associated with the swing angles
[18][32]. The two halves are highly flexible as the energy cost for the swing is low. Such flexibility facilitates interactions between tRNA and other macromolecules. The acceptor stem domain is older than the anticodon loop domain
[19][33].
2. Assignment of the Amino Acids to Genetic Codes
Before discussing the onset of RNA-coded peptides, the emergence of RNA and amino acid precursors in the prebiotic settings needs to be clarified. In the Miller experiment, various products were synthesized and identified under a possible primitive condition. Gly, Ala, and β-Ala were identified at the 100 µM scale. Asp, Glu, Ser, and Val were observed as well, albeit in a lower concentration
[20][21][22][41,42,43]. Later, prebiotic chemistry demonstrated a unified network of nucleic acids, amino acids, and lipids
[23][44]. Precursors of RNA and amino acids were generated by the reductive homologation of hydrogen cyanide. Apart from the amino acids mentioned above, Pro, Leu, Ile, Thr, and Arg might also arise from the primordial soup.
Due to the sequential emergence of amino acids, the assignment of genetic codes must be stepwise. The genetic codes are universal in the three kingdoms; therefore, the assignment of amino acids to the 64 triplets must be established before the division of the kingdoms. In parallel with the evolution of tRNA, several hypotheses for codon assignment have been proposed in the past decades, among which the frozen accident theory and stereochemical theory were first. Frozen accident theory claimed that codons were randomly assigned and are impossible to change significantly afterwards
[1][24][2,51]. The introduction of a new correlation between an amino acid and a codon triplet occurs only if such mutation benefits fitness. However, the frozen accident theory did not solve the puzzle satisfactorily. The degeneracy of the genetic code and the stability of the second base pair of anticodons revealed that the evolution of assignment was accompanied by a single base changing
[25][52].
Stereochemical theory proposed a different viewpoint: that the assignment was rational because of the stereochemical interactions, or the physical affinity, between the amino acids and nucleotides. The initial attempt to interpret the interaction, which dated back to 1954, was the diamond code theory, which proposed that a ‘key-and-lock’ relationship existed between a specific amino acid and the rhomb-shaped ‘holes’ in the DNA strand
[26][54]. The diamond code theory was further developed as the stereochemical theory and numerous models relating to this have since been proposed
[27][28][29][30][31][55,56,57,58,59].
As neither the frozen accident theory nor the stereochemical theory provide a comprehensive solution to the assignment of the genetic codes, further theories have been put forward. The co-evolution theory addressed the issue by asserting that the extant codon assignments were defined according to the sequential emergence of amino acids
[32][68]. The codon assignment is the vestige of the prebiotic amino acid synthesis, which remains in the extant amino acids biosynthesis pathways. Development of the genetic code could be deduced from the precursor–product connections among the amino acids. As the precursors evolved into extant amino acids, co-evolution among amino acid precursors, amino acids, and aaRS took place
[33][34][69,70].
Translation error theory claims that evolution is aimed at reducing errors in translation. Coding started from random assignment and codons for chemically related amino acids were adjacent in the codon table, resulting in high robustness against RNA mutations and translation errors
[35][73]. Ambiguous codon assignments with high entropy binding were progressively replaced with lower binding entropy, suggesting that the extant genetic code emerged from the codes with a lower level of certainty. The certainty increased along with tRNA species expanding during their evolution
[36][74]. The codon assignment reduced base-pairing errors and phenotypic impacts from mutations to the minimum level. Single base alterations, particularly transitions, generally result in no or conservative amino acid replacement. The GC content of amino acid codons is related to the degree of codon degeneration. Third-position degeneration and high GC content provided an additional layer of protection for the primary amino acids that constructed preliminary peptides. Such codon assignment provides increased systematic perseverance for protein synthesis
[37][75].
The above theories for codon assignment are not mutually exclusive
[38][39][76,77]. A hybridized theory would be an option for codon assignment. First, physical interactions between the prebiotic amino acids subset and short RNA strands, similar to the extant acceptor stem, affected the esterification at the 3′-terminus of the RNA (which will be discussed in the next section). The interaction could have been positive, i.e., ribose aminoacyl ester formed where there was a strong interaction between the amino acid side chains and nucleotides, or it could have been negative, i.e., aminoacyl esters formed where the interaction was weak. Even though the selectivity of the amino acid to a trinucleotide is low, the preference would manifest and magnify over time.
3. Coded Peptide Formation
Dipeptides can be produced through the amidation of two amino acids without coupling reagents, but the yield is low
[40][78]. Typical inorganic catalysts include layered double hydroxides
[41][80] and titanium dioxide
[42][81]. Cyanamide, diaminomaleonitrile, ferricyanide, trimetaphosphate, etc. are organic activators that likely catalyze the amide bond formation under prebiotic conditions. Prebiotically plausible N-carbamoyl amino acids (NCA)
[43][82], 5(
4H)-oxazolone
[44][45][83,84], and cyclic acylphosphoramidate (CAPA)
[46][85], activated from the respective amino acids, further yield mixed anhydrides and aminoacyl esters. Although prebiotic peptide formation is prevalent and short random peptides can be functional, the function cannot self-propagate until the amino acid sequence is recorded in RNA or prebiotic nucleotide analogues
[47][86].
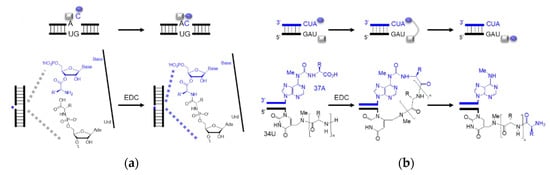
In the extant biology, peptide synthesis starts with the acylation of the 3′-terminus of the tRNA using aaRS (
Figure 34a). In the prebiotic context, acylating RNA strands without the presence of pre-synthesized enzymes initiates RNA-coded peptide synthesis
[48][87]. Tamura et al.
[49][88] and Wu et al.
[50][89] discovered that aminoacyl spontaneously transferred from aminoacyl phosphate mixed anhydride at the 5′-terminus of a donor strand to the 3′-terminus of an acceptor strand in a nicked duplex (
Figure 34b) or nicked loop (
Figure 34c). The transfer showed good stereoselectivity of
L- over
D-amino acids and chemical selectivity among amino acids, which indicates that the conformation of the D-ribose and β-nucleoside resulted in the single-chirality of amino acids. In the case of the nicked duplex transfer, tri-phenylalanine-RNA ester was detected
[51][90]. Similar esterification was achieved via phosphoramidate (
Figure 34d,e)
[52][53][91,92]. While the prebiotic synthesis of mixed anhydride is not yet solved, amino acid phosphoramidate is prebiotic accessible
[54][61]. To achieve the RNA-coded peptide synthesis, either the formation of amino acid donors or the aminoacyl transfer should be processed in an RNA sequence-dependent manner; however, no sequence-dependent acylation has been reported to date.
Figure 34. Aminoacyl esterification on the RNA 3′ terminus. (
a) Amino acid activation using aaRS in the extant biology; (
b) aminoacyl transfer in a nicked duplex; (
c) aminoacyl transfer in a nicked loop; (
d) phosphoramidate-mediated esterification in a nicked duplex; (
e) phosphoramidate-mediated esterification in a nicked loop. Im, imidazole. EDC, 1-ethyl-3-(3-dimethylaminopropyl) carbodiimide. R, amino acid residue.
Enzyme-free RNA-templated peptide synthesis has been reported using 5′-phosphoramidate amino acids (
Figure 45a)
[55][96] and amino acids conjugated to modified RNA bases (
Figure 45b)
[56][97]. Amidation selectivity has been observed between the nucleoside monophosphate and the nicked duplex, validating the idea of ‘mononucleotide translation’. The mononucleotide translation is believed to evolve to the extant triplet code system when adapted to a higher diversity of amino acids. Parallel to the nicked duplex, RNA hairpins, analogues to the tRNA anticodon loop, have also been seen as the platform of peptide synthesis. Non-canonical RNA bases, as well as peptide–RNA chimaera, are assumed as the vestiges of the RNA world that played a role in coded peptide synthesis
[57][98]. In both scenarios, activators such as EDC, which is not considered prebiotic accessible, were used as coupling reagents while the extant biology utilizes aminoacyl ester transfer to form the amide bond. A more possible prebiotic scenario should be comparable to the extant mechanism. Additionally, if the nicked duplex or anticodon loop templated amidation were authentic, a transition of peptide formation from the nicked anticodon loop to the extant acceptor stem should be envisaged.
Figure 45. Sequence-dependent amino acid coupling. Schematic representation of (
a) ‘mononucleotide translation’ in a nicked duplex using one ssRNA as a template and two complementary RNAs with aminoacyl ester and phosphoramidate; (
b) peptide formation in a tRNA anticodon loop mimic using m
6aa
6A and mnm
5U. Rectangle and oval shapes represent amino acids. Bold lines represent RNA strands.
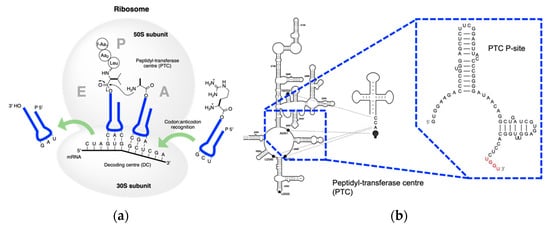
LSU is divided into six domains based on structure and function, among which domain V accounts for peptidyl transferase activity
[58][101]. Interaction between PTC and tRNA on the A-site is responsible for amino deprotonation, water proton transfer, and tetrahedral intermediate formation
[59][102], while r-proteins frame the ribosome structure
[60][61][103,104]. Therefore, Cech
[62][105] had his wise saying ‘The ribosome is a ribozyme’. It is worth mentioning that apart from amidation, the ribosome and ribozymes could catalyze esterification when puromycin was replaced with hydroxypuromycin
[63][64][65][106,107,108]. These examples indicate that the proto-ribosome may have evolved from hydroxylacyl transfer to the extant aminoacyl transfer. Thus, the RNA-coded depsipeptides and polyesters world is a plausible alternative to the RNA–peptide world
[66] (Figure 5)[109].
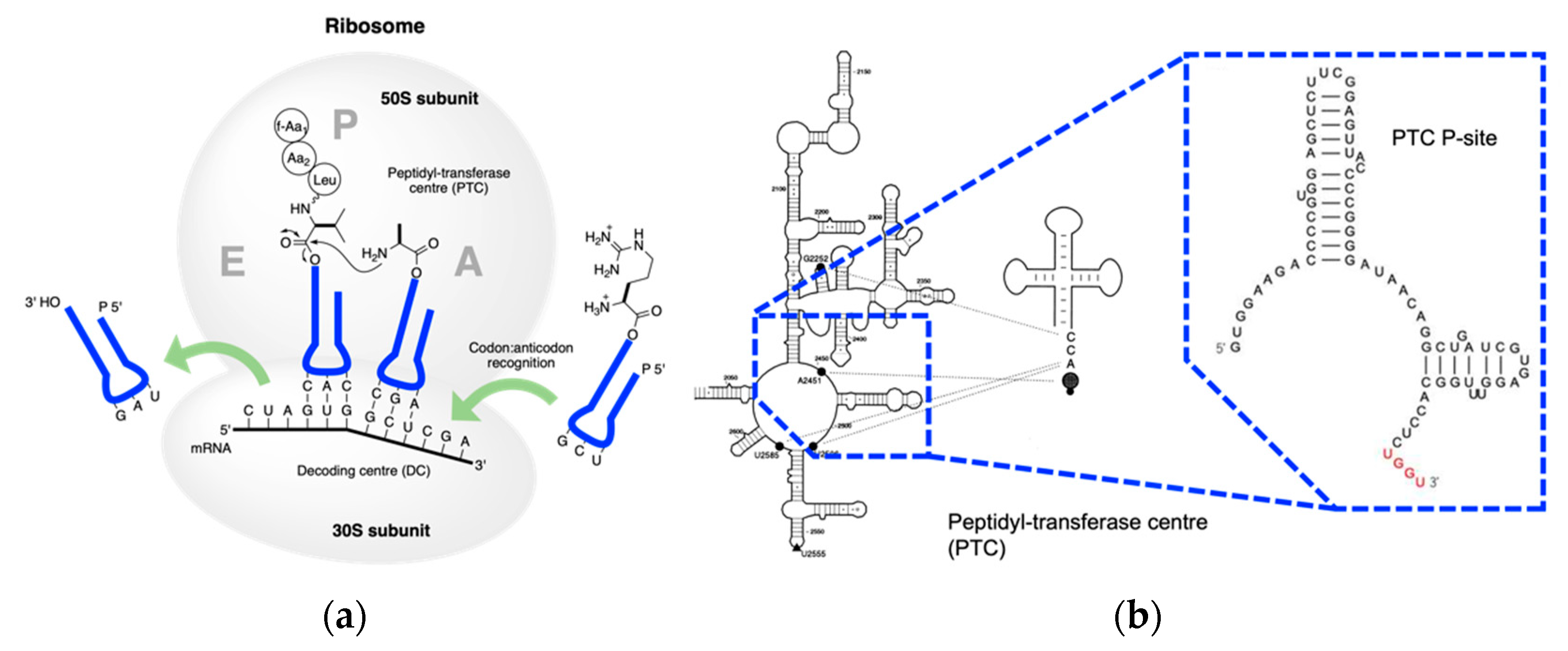
Figure 56. Extant peptidyl transfer. (
a) Mechanism of peptidyl transfer and peptide elongation in the extant biology; (
b) detailed structure of PTC in the LSU interacts with tRNA (adapted from
[67][110]). G2252, U2506, and U2585 interact with the CCA end of the tRNA. The enlargement shows the P binding site. UGGU in red indicates an engineered handle for the CCA end in the tRNA.