Your browser does not fully support modern features. Please upgrade for a smoother experience.
Please note this is a comparison between Version 1 by Majid Hameed Ahmed and Version 2 by Peter Tang.
Short text clustering (STC) has become a critical task for automatically grouping various unlabelled texts into meaningful clusters. STC is a necessary step in many applications, including Twitter personalization, sentiment analysis, spam filtering, customer reviews and many other social network-related applications.
- short text
- text representation
- dimensionality reduction
- clustering techniques
- short text clustering
1. Introduction
Recently, the number of text documents on the Internet has increased significantly and rapidly. The rapid development of mobile devices and Internet technologies has encouraged users to search for information, communicate with friends and share their opinions and ideas on social media such as Twitter, Instagram, and Facebook and search engines such as Google. The texts generated every day in social media are vast and unstructured data [1].
Most of these generated texts come in the form of short texts and need special analysis compared with formally written ones [2][3][2,3]. Short texts can be found on the Internet, including on social media, in product descriptions, in advertisement text, on questions and answers (Q&A) websites [4] and in many other applications. Short texts are distinguished by a lack of context, so finding knowledge in them is difficult. This issue motivates researchers to develop novel, effective methods. Examples of short texts can be found in various contexts, like tweets, search inquiries, chat messages, online reviews and product descriptions. Short text also presents a challenge in clustering owing to its chaotic nature, which typically contains noise, slang, emojis, misspellings, abbreviations and grammatical errors. Tweets are a good example of these challenges. In addition, short text represents various facets of people’s daily lives. As an illustration, Twitter generates 500 million tweets per day. These short texts can be used in several applications, such as trend detection [5], user profiling [6], event exploration [7], system recommendation [8], online user clustering [9] and cluster-based retrieval [2][10][2,10].
With the vast amount of short texts being added to the web every day, extracting valuable information from short text corpora by using data-mining techniques is essential [11][12][11,12]. Among the many different data-mining techniques, clustering stands out as a unique technique for short text that provides the exciting potential to automatically recognize valuable patterns from a massive, messy collection of short texts [13]. Clustering techniques focus on detecting similarity patterns in corpus data, automatically detecting groups of similar short texts, and organising documents into semantic and logical structures.
Clustering techniques help governments, organisations and companies monitor social events, interests and trends by identifying various subjects from user-generated content [14][15][14,15]. Many users can post short text messages, image captions, search queries and product reviews on social media platforms. Twitter sets a restriction of 280 characters on the length of each tweet [16], and Instagram sets a limit of 2200 characters for each post [17].
Clustering short texts (forum titles, result snippets, frequently asked questions, tweets, microblogs, image or video titles and tags) within groups assigned to topics is an important research subject. Short text clustering (STC) has undergone extensive research in recent years to solve the most critical challenges to the current clustering techniques for short text, which are data sparsity, limited length and high-dimensional representation [18][19][20][21][22][23][18,19,20,21,22,23].
Applying standard clustering techniques directly to a short text corpus creates issues. The accuracy is worse when using traditional clustering techniques such as the K-means [24] technique to group short text data than when using the same method to group regular-length documents [25]. One of the reasons is that standard clustering techniques such as K-means [24] and DBSCAN [26] depend on methods that measure the similarity/distance between data objects and accurate text representations [25]. However, the use of standard text representation methods for STC, such as a term frequency inverse-document-frequency (TF-IDF) vectors or bag of words (BOW) [27], leads to sparse and high-dimensional feature vectors that are less distinctive for measuring distance [18][28][29][18,28,29].
2. Applications of Short Text Clustering
Many clustering methods have been used in several real-world applications. The following disciplines and fields use clustering:-
Information retrieval (IR): Clustering methods have been used in various applications in information retrieval, including clustering big datasets. In search engines, text clustering plays a critical role in improving document retrieval performance by grouping and indexing related documents [30].
-
Internet of Things (IoT): With the rapid advancement of technology, several domains have focused on IoT. Data collection in the IoT involves using a global positioning system, radio frequency identification technology, sensors and various other IoT devices. Clustering techniques are used for distributed clustering, which is essential for wireless sensor networks [31][32][31,32].
-
Biology: When clustering genes and samples in gene expression, the gene expression data characteristics become meaningful. They can be classified into clusters based on their expression patterns [33].
-
Industry: Businesses collect large volumes of information about current and prospective customers. For further analysis, customers can be divided into small groups [34].
-
Climate: Recognising global climate patterns necessitates detecting patterns in the oceans and atmosphere. Data clustering seeks to identify atmospheric pressure patterns that significantly impact the climate [35].
-
Medicine: Cluster analysis is used to differentiate among disease subcategories. It can also detect disease patterns in the temporal or spatial distribution [36].
3. Components of Short Text Clustering
Clustering is a type of data analysis that has been widely studied; it aims to group a collection of data objects or items into subsets or clusters [37]. Specifically, the main goal of clustering is to generate cohesive and identical groups of similar data elements by grouping related data points into unified clusters. All the documents or objects in the same cluster must be as similar as possible [38]. In other words, similar documents in a cluster have similar topics so that the cluster is coherent internally. Distinctions between each cluster are notable. Documents or objects in the same cluster must be as different from those in the other clusters as possible. Text clustering is essential to many real-world applications, such as text mining, online text organisation and automatic information retrieval systems. Fast and high-quality document clustering greatly aids users in successfully navigating, summarizing and organizing large amounts of disorganized data. Furthermore, it may determine the structure and content of previously unknown text collections. Clustering attempts to automatically group documents or objects with similar clusters by using various similarity/distance measures [39]. Differentiating between clustering and classification of documents is crucial [40]. Still, the difference between the two may be unclear because a set of documents must be split into groups in both cases. In general, labelled training data are supplied during classification; however, the challenge arises when attempting to categorize test sets, which consist of unlabelled data, into a predetermined set of classes. In most cases, the classification problem may be handled using a supervised learning method [41][42][41,42]. As mentioned above, one of the significant challenges in clustering is grouping a set of unlabelled and non-predefined data into similar groups. Unsupervised learning methods are commonly used to solve the clustering problem. Furthermore, clustering is used in many data fields that do not rely on predefined knowledge of the data, unlike classification, which requires prior knowledge of the data [43]. Short texts are becoming increasingly common as online social media platforms such as Instagram, Twitter and Facebook increase in size. They have very minimal vocabulary; many words even appear only once. Therefore, STC significantly affects semantic analysis, demonstrating its importance in various applications, such as IR and summarisation [2]. However, the sparsity of short text representation makes the traditional clustering methods unsatisfying. This is due to the sparsity problems caused by each short text document only containing a few words. Short text data contain unstructured sentences that lead to massive variance from regular texts’ vocabulary when using clustering techniques. Therefore, self-corpus-based expansion is presented as a semantically aligned substitutional approach by defining and augmenting concepts in the corpus using clustering techniques [44] or topics based on the probability of frequency of the term [45]. However, dealing with the microblogging data is challenging for any of these methods because of their lack of structure and the small number of co-occurrences among words [46]. Several strategies have been proposed to alleviate the sparsity difficulties caused by lack of context, such as corpus-based metrics [47] and knowledge-based metrics [25][48][25,48]. One of these simple strategies concentrates on data-level enhancements. The main idea is to combine short text documents to create longer ones [49]. For aggregation, related models utilize metadata or external data [48]. Although these models can alleviate some of the sparsity issues, a drawback remains. That is, these models rely on external data to a large extent. STC is more challenging than traditional text clustering. Representations of the text in the original lexical space are typically sparse, and this problem is exacerbated for short texts [50]. Therefore, learning an efficient short text representation scheme suitable for clustering is critical to the success of STC. In essence, the major drawback of the standard STC techniques is that they cannot adequately handle the sparseness of words in the documents. Compared with long texts containing rich contexts, distinguishing the clusters of short documents with few words occurring in the training set is more challenging. Generally, most models primarily focus on learning representation from local co-occurrences of words [21]. Understanding how a model works is critical for using and developing text clustering methods. STC generally contains different steps that can be applied, as shown in Figure 1.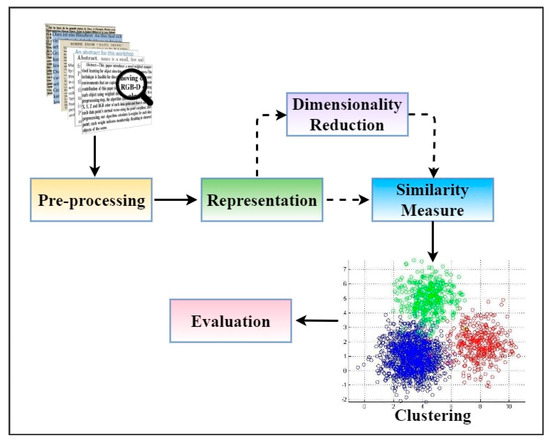
Figure 1.
Components for text-data clustering.
- (I)
-
Pre-processing: It is the first step to take in STC. The data must be cleaned by removing unnecessary characters, words, symbols, and digits. Then, text representation methods can be applied. Pre-processing plays an essential role in building an efficient clustering system because short text data (original text) are unsuitable to be used directly for clustering.
- (II)
-
Representation: Documents and texts are collections of unstructured data. These unstructured data need to be transformed into a structured feature space to use mathematical modelling during clustering. The standard techniques of text representation can be divided into the representation-based corpus and representation-based external knowledge methods.
- (III)
-
Dimensionality reduction: Texts or documents, often after being represented by traditional techniques, become high-dimensional. Data-clustering procedures may be slowed down by extensive processing time and storage complexity. Dimensionality reduction is a standard method for dealing with this kind of issue. Many academics employ dimensionality reduction to lessen their application time and memory complexity rather than risk a performance drop. Dimensionality reduction may be more effective than developing inexpensive representation.
- (IV)
-
Similarity measure: It is the fundamental entity in the clustering algorithm. It makes it easier to measure similar entities, group the entities and elements that are most similar and determine the shortest distance between related entities. In other words, distance and similarity have an inverse relationship, so they are used interchangeably. The vector representation of the data items is typically used to compute similarity/distance measures.
- (V)
-
Clustering techniques: The crucial part of any text clustering system is selecting the best algorithm. We cannot choose the best model for a text clustering system without a deep conceptual understanding of each approach. The goal of clustering algorithms is to generate internally coherent clusters that are obviously distinct from one another.
- (VI)
-
Evaluation: It is the final step of STC. Understanding how the model works is necessary before applying or creating text clustering techniques. Several models are available to evaluate STC.
3.1. Document Pre-Processing in Short Text Clustering
Document pre-processing plays an essential part in STC because the short text data (original text) are unsuitable to be used directly for clustering. The textual document likely contains every type of string, such as digits, symbols, words, and phrases. Noisy strings may negatively impact clustering performance, affecting information retrieval [51][52][51,52]. The pre-processing phase for STC enhances the overall processing [47]. In this context, the pre-processing step must be used on documents to cluster if one wants to use machine learning approaches [53]. Pre-processing consists of four steps: tokenization, normalization, stop word removal and stemming. The main pre-processing steps are shown in Figure 2.According to [54], short texts have many unwanted words which may harm the representation rather than assist it. This fact validates the benefits of pre-processing the document in STC. Utilizing the documents with all their words, including unnecessary ones is a complicated task. Generally, words classified under particles, conjunctions and other grammar-based categories, which are commonly used, may be unsuitable for supporting studies on short text clustering. Furthermore, as suggested by Bruce et al. [55], even standard terms such as ‘go’, ‘gone’ and ‘going’ in the English language are created by the derivational and inflectional processes. They fare better if their inflectional and derivational morphemes are taken to remain in their original stems. This reduces the number of words in a document whilst preserving the semantic functions of these words. Therefore, a document free of unwanted words is an appropriate pre-processing goal [56][57][56,57].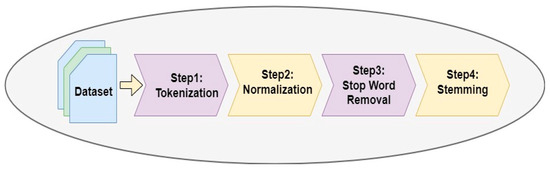 Figure 2.Main pre-processing steps.
Figure 2.Main pre-processing steps.3.2. Document Representation
Even after the noise in the text has been removed during pre-processing, the text still does not fit together well enough to produce the best results when clustering. Therefore, focusing on the text representation step is essential, which involves converting the word or the full text from its initial form into another. Directly applying learning algorithms to text information without representing it is impossible [58][62] because text information has complex nature [59][63]. Textual document content must be converted into a concise representation before applying a machine learning approach to the text. Language-independent approaches are particularly successful because they are not dependent on the meaning of the language and perform well in the event of noisy text. As these methods do not depend on language, they are efficient [60][64]. Short text similarity has attracted more attention in recent years, and understanding semantics correctly between documents is challenging to understanding lexical diversity and ambiguity [61][65]. Representing short text is critical in NLP yet challenging owing to its sparsity; high dimensionality; complexity; large volume and much irrelevant, redundant and noisy information [1][62][1,66]. As a result, the traditional methods of computing semantic similarity are a significant roadblock because they are ineffective in various circumstances. Many existing traditional systems fail to deal with terms not covered by synonyms and cannot handle abbreviations, acronyms, brand names and other terms [63][67]. Examples of these traditional systems are BOW and TF-IDF, which represent text as real value vectors to help with semantic similarity computation. However, these strategies cannot account for the fact that words have diverse meanings and that different words may be used to represent the same concept. For example, consider two sentences: ‘Majid is taking insulin’ and ‘Majid has diabetes’. Although these two sentences have the same meaning, they do not use the same words. These methods capture the lexical features of the text and are simple to implement; however, they ignore the semantic and syntactic features of the text. To address this issue, several studies have expanded and enriched the context of data from an ontology [64][65][68,69] or Wikipedia [66][67][70,71]. However, these techniques require a great deal of understanding of NLP. They still use high-dimensional representation for short text, which may lead to wasting memory and computing time. Generally, these methods use external knowledge to improve contextual information for short texts. Many short text similarity measurement approaches exist, such as representation-based measurement [68][69][72,73], which learn new representations for short text and then measure similarity based on this model [70][74]. A large number of similarity metrics have previously been proposed in the literature. ThWe researchers chchoose corpus-based and knowledge-based metrics because of their observed performance in NLP applications. This research explains several representation-based measurement methods, as shown in Figure 3.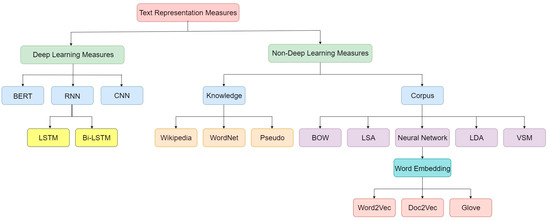 Figure 3.Main taxonomies for short text representation.
Figure 3.Main taxonomies for short text representation.3.3. Dimensionality Reduction
It is commonly used in machine learning and big data analytics because it aids in analysing large, high-dimensional datasets. It can benefit tasks like data clustering and classification [71][126]. Recently, dimensional-reduction methods have emerged as a promising avenue for improving clustering accuracy [72][127]. Text sequences in term-based vector models have many features. As a result, memory and time complexity consumption are prohibitively expensive for these methods. To address this issue, many researchers use dimensionality reduction to reduce the feature-space size [73][101].3.4. Similarity and Distance Measure
The similarity measure determines the similarity between diverse terms, such as words, sentences, documents or concepts. The goal of determining similarity measures between two terms is to determine the degree of relevance by matching the conceptually similar terms but not necessarily lexicographically similar terms [74][138]. Generally, the similarity measure is a significant and essential component of any clustering technique. This is because it makes it easier to measure two things, group the most similar elements and entities together and determine the shortest distance between them [75][76][139,140]. In other words, distance and similarity have an inverse relationship, so they are used interchangeably. In general, similarity/distance measures are computed using the vector representations of data items. Document similarity is vital in text processing [77][141]. It calculates the degree to which two text objects may be identical. Nonetheless, the similarity and distance measures are used as a retrieval module in information retrieval. Similarity measurements include cosine, Jaccard and inner products; distance measures include Euclidean distance and KL divergence [78][142]. An analysis of the literature studies shows that several similarity metrics have been developed. However, none of the similarity metrics appears to be the most effective for any research [79][143].3.5. Clustering Algorithms
Clustering methods divide a collection of documents into groups or subsets. Cluster algorithms seek to generate internally coherent clusters yet distinct from one another. In other words, documents inside one cluster must be similar as feasible, whereas documents in different clusters should be as diverse as possible. The clustering method splits many text messages into many significant clusters. Clustering has become a standard strategy in information retrieval and text mining [80][145]. Concurrently, text clustering faces various challenges. On the one hand, a text vector is a high-dimensional vector, typically ranging in the thousands or even the ten thousand dimensions. On the other hand, the text vector generally is sparse, making it challenging to identify the cluster centre. Clustering has become an essential means of unsupervised machine learning, attracting many researchers [81][82][146,147]. In general, there are three types of clustering algorithms: hierarchical-based clustering, partition-based clustering and density-based clustering. ThWe researchers quickly discuss a few traditional techniques for each category; clustering algorithms have been extensively studied in the literature [83][84][148,149].3.6. Performance Evaluation Measure
This step provides an overview of the performance measures used to evaluate the proposed model. These performance measures involve comparing the clusters created by the proposed model with the proper clusters. The assessment of clustering results is often called cluster validation. Cluster validity can be employed to identify the number of clusters and determines the corresponding best partition. Many suggestions have been made for measuring the similarity between the two clusters [85][86][160,161]. These measures may be used to evaluate the effectiveness of various data clustering techniques applied to a given dataset. When assessing the quality of a clustering approach, these measurements are typically related to the different kinds of criteria being considered. The term ‘internal assessment’ refers to assessing the clustering outcome using only the data clustered by itself [87][162]. These methods often give the algorithm the perfect score, producing values with a higher degree of similarity inside a cluster and a low degree between clusters. The outcomes of external assessment clustering are evaluated based on data not utilized for clustering, such as known-class labels and external benchmarks. It is noteworthy these external benchmarks are composed of a group of things that have already been categorized, and typically, these sets are created by human specialists. These assessment techniques gauge how well the clustering complies with the established benchmark classes [88][89][163,164].