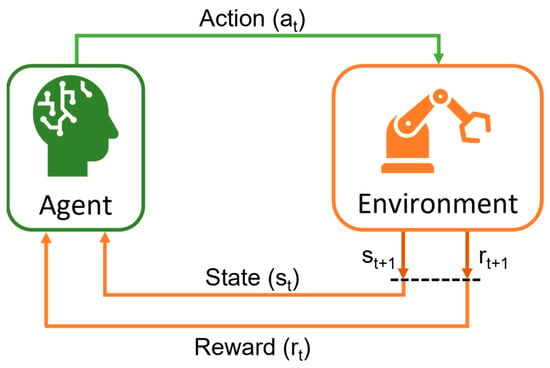
2. Deep Reinforcement Learning
To address higher dimensional and more complex problems, deep neuronal networks (DNNs) were incorporated into RL, leading to deep RL (DRL)
[38][54]. DNNs are used as function approximators to estimate the policy and value function. Moreover, leveraging their capacity to compact input data dimensionality, hence more complex observations, such as images and non-linear problems, can be processed
[39][40][41][55,56,57]. This DRL field started with the Deep Q-Networks (DQN) algorithm
[27][29] which has exponentially increased over the last few years.
ReThis se
archerction describes the catalogue of DRL algorithms, including their primary properties and classification schemes, illustrated in
Figure 2.
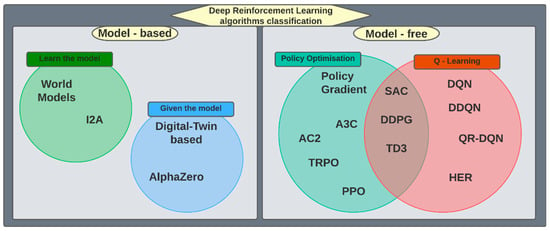
Figure 2. Classification of deep reinforcement learning algorithms.
Figure 2 depicts the most extended classification of DRL algorithms
[42][58]. The main grouping is based on the available information about the dynamics of the environment, which determines the learning process of the agent.
On the one hand, model-based algorithms can be distinguished. These algorithms have access to information on the environment dynamics, including the reward function, which allows the agent to estimate how the environment will react to an action
[43][59]. Typically, these algorithms are integrated with metaheuristics and optimisation techniques
[44][60]. Moreover, they are particularly good at solving high-dimensional problems, as reflected in Aske P. et al. (2020)
[45][61] survey. Furthermore, those methods reflect a higher sample efficiency, as reflected through empirical
[46][47][62,63] and theoretical
[48][64] studies. A complete overview concerning model-based DRL is presented by Luo, F. et al. (2022)
[49][65] in their survey. Inside model-based DRL algorithms
[43][59], there are two different situations depending on if the model is known or not.
Concerning the first group, if the model is known, this knowledge is used to improve the learning process, and the algorithm is integrated with metaheuristics, planning and optimisation techniques. However, since the environments usually have large action spaces, the application of these techniques is highly resource demanding. Thus, a complete optimisation of the learning process cannot be carried out. Moreover, although there are no algorithms defined as such, except for well-known algorithms such as Alpha Zero
[50][66] and Single Agent
[51][67], most of them are adapted to the application and the characteristics of the model environment. In recent years, DRL model-based algorithms that make use of digital twin models may be highlighted, such as the algorithms presented by Matulis and Harvey (2021)
[52][68] and Xia et al. (2021)
[53][69]. Therefore, in the implementation of the model-based algorithms, the following aspects must be addressed:
-
In which state the planning starts;
-
How many computational resources are assigned to it;
-
Which optimisation or planning algorithm is used;
-
What is the relation between the planning and the DRL algorithm.
In the other group of model-based algorithms, the model of the environment is not fully known, and the algorithms train with a learned model
[54][70]. Normally, a representation of the environment is extracted by using supervised/unsupervised algorithms, which is carried out in a previous step as a model learning process
[55][56][57][71,72,73]. Algorithms such as World Models
[58][74] and Imagination-Augmented Agents (I2A)
[59][75] belong to this group. Nonetheless, the accuracy of the model depends on the observable information and the capacity to adapt to changes in the model dynamics. For this reason, these algorithms are more suitable for dealing with deterministic environments. Based on the experience acquired through the interaction with the environment, three model approaches can be obtained
[60][61][76,77]:
-
Forward model: based on the current state and the selected action by the agent, it estimates the next state;
-
Backward model: a retrospective model that predicts which state and action led to the current state;
-
Inverse model: it assesses which action makes moving from one state to another.
On the other hand, model-free algorithms cannot anticipate the evolution of the environment after an action because the dynamics of the environment is unknown
[62][78]. Thus, the algorithm estimates the most suitable action at the current state based on the acquired experience through interaction. This latter is the most frequent scenario in practice; hence, more algorithms exist
[63][79]. The model-free DRL algorithms focus on the management of acquired experience by algorithms and how they use this information to learn a policy. This distinguishes on-policy algorithms from off-policy algorithms
[64][80]. In the former case, the agent applies its policy generating short-term experience, which frequently consists of a fixed number of transitions (trajectory)
[65][66][81,82]. Based on this information, the policy is updated, and then the experience is discarded. On the other hand, off-policy algorithms have a memory that stores the transitions created by several past policies
[67][83]. This memory is finite and has a memory management method, for instance, FIFO (first-in, first-out)
[68][84]. In this case, the policy is updated with a sampled batch of the stored transitions, considering the experience generated with old policies
[69][85].
Although this latter classification is not exclusive to model-free algorithms, there is a certain parallelism with the two families of model-free algorithms represented in
Figure 2, policy optimisation (PO) and Q-learning families. The first family began with the Policy Gradient algorithm and was later expanded to include the Advantage Actor Critic (A2C)
[70][86], Asynchronous Advantage Actor Critic (A3C)
[71][87], and proximal policy optimization (PPO)
[72][88] algorithms. This class of algorithms is capable of handling continuous and discrete action spaces, and the action at each state is determined by a probability distribution. The second family was derived from Deep Q-Networks (DQN)
[73][89], and algorithms such as Quantile Regression DQN (QR-DQN)
[74][90] and hindsight experience replay (HER)
[75][91] belong to it. In contrast to the other family, they can only deal with discrete action space environments, and the policy calculates the Q-value of each state-action pair to take a decision.
Lastly, it should be highlighted that these classifications are not exclusive, and there are algorithms that integrate features and techniques of different groups, such as the hybrid algorithms that are halfway between policy optimisation and Q-learning families (see
Figure 2). Some algorithms of this group are Soft Actor-Critic (SAC)
[76][92], Deep Deterministic Policy Gradient (DDPG)
[77][93] and Twin Delayed Deep Deterministic Policy Gradient (TD3)
[78][94]. These algorithms address some of the weaknesses of the other algorithms that allow the implementation of approaches to more complex problems. In addition, combinations of algorithms from different groups can be found in the literature, such as DDPG + HER
[79][95] and model-free and model-based algorithms
[45][61].
Integration in the Industry
Manufacturing involves a set of tasks that generally entail decision making by plant operators. These tasks are related to scheduling
[80][96] (e.g., predicting the production based on future demand, guaranteeing the supply chain, planning processes to optimise production and energy consumption); process control
[81][97] (i.e., automated processes such as assembly lines, pick-and-place and path planning); and monitoring
[10] (e.g., decision support systems, calibration and quality control)
[12]. As can be observed, most of these tasks are complex, and their efficient performance needs expert knowledge and time to be programmed. In the manufacturing sector, the former exists for many tasks, but the availability of time is limited even more if flexible production wants to be achieved under the framework of I4.0. Moreover, for smart factories of I5.0, other factors, such as benefits for the well-being of workers and the environment, must be considered. All in all, the automation of manufacturing tasks is a complex optimisation problem that requires novel technologies to be addressed, such as ML. Based on a few investigations
[11][82][83][11,98,99], below the main requirements of an ML application in the industry are listed:
-
Dealing with high-dimensional problems and datasets with moderate effort;
-
Capability to simplify potentially difficult outputs and establish an intuitive interaction with operators;
-
Adapting to changes in the environment in a cost-effective manner, ideally with some degree of automation;
-
Expanding the previous knowledge with the acquired experience;
-
Ability to deal with available manufacturing data without particular needs for the initial capture of very detailed information;
-
Capability to discover relevant intra- and inter-process relationships and, preferably, correlation and/or causation.
Among ML paradigms, reinforcement learning is suitable for this type of task. The trial-and-error learning through the interaction with the environment and not requiring pre-collected data and prior expert knowledge allow RL algorithms to adapt to uncertain conditions
[12]. Moreover, thanks to the capacity of ANNs to create simple representations of complex inputs and functions, DRL algorithms can address complex tasks, maintaining adaptability and robustness
[84][100]. Indeed, some applications can be found in manufacturing, for instance, in scheduling tasks
[85][86][101,102] and robot manipulation
[87][88][103,104].
However, the application of DRL in industrial processes presents some challenges that must be considered during the implementation. A complete list of challenges is gathered in studies such as
[11][89][11,105]; however, the most common ones perceived by the
resea
rcheuthors in real-world implementations are described below.
-
Stability. In industrial RL applications, the sample efficiency of off-policy algorithms is desirable. However, these show an unstable performance in high-dimensional problems, which worsens if the state and action spaces are continuous. To mitigate this deficiency, two approaches predominate: (i) reducing the brittleness to hyperparameter tuning and (ii) avoiding local optima and delayed rewards. The former can be solved by using tools that optimise the selection of hyperparameters values, such as Optuna
[90][106], or employing algorithms that internally optimise some hyperparameters, such as SAC
[91][107]. The other approach can be addressed by stochastic policies, for example, introducing entropy maximisation such as SAC and improved exploration strategies
[92][108].
-
Sample efficiency. Learning better policies with less experience is key for efficient RL applications in industrial processes. This is because, in many cases, the data availability is limited, and it is preferable to train an algorithm in the shortest possible time. As stated before, among model-free DRL algorithms, off-policy algorithms are more sample efficient than on-policy ones. In addition, model-based algorithms have better performance, but obtaining an accurate model of the environment is often challenging in the industry. Other alternatives to enhance sample efficiency are input remapping, which is often implemented with high-dimensional observations
[93][109], and offline training, which consists of training the algorithm with a simulated environment
[94][110].
-
Training with real processes. Albeit training directly with the real systems is possible, it is very time consuming and entails the wear and tear of robots and automatons
[89][105]. Moreover, human supervision is needed to guarantee safety conditions. Therefore, simulated environments are used in practice, allowing the generation of much experience at a lower cost and faster training. Nonetheless, a real gap exists between simulated and real-world environments, making applying the policy learned during the training difficult
[95][111].
-
Sparse reward. Manufacturing tasks usually involve a large set of steps until reaching their goal. Generally, this is modelled with a zero-reward most of the time and a high reward at the end if the goal is reached
[96][112]. This can discourage the agent in the exploration phase, thus attaining a poor performance. To this end, some solutions are aggregating demonstration data to the experience of the agent in a model-based RL algorithm to learn better models; including scripted policies to initialise the training, such as in QT-Opt
[97][113] and reward shaping provides additional guidance to exploration, boosting the learning process.
-
Reward function. The reward is the most important signal the agent receives because it guides the learning process
[98][114]. For this reason, clearly specifying the goals and rewards is key to achieving a successful learning process. This becomes more complex as the task and the environment becomes more complicated, e.g., industrial environments and manufacturing tasks. To mitigate this problem, some alternatives are integrating intelligent sensors to provide more information, using heuristics techniques and replacing the reward function with a model that predicts that reward
[99][115].
3. Deep Reinforcement Learning in the Production Industry
Nowadays, manufacturing industries face major challenges, such as mass customisation and shorter development cycles. Moreover, there is a need to meet the ever-rising bar for product quality and sustainability in the shortest amount of time through an ambiguous and fluctuant market demand
[83][99]. However, those challenges also open up new opportunities for innovative technologies brought by the I4.0 and I5.0
[13][100][13,116]. Among those, AI plays a special role, and furthermore, DRL, after the outstanding results presented by OpenAI
[101][117] and DeepMind
[102][118], among others, is progressively shifted to the production industry
[103][119]. In this sense, some of the main DRL features, such as the adaptability and ability to generalise and extract information from past experiences, have already been demonstrated in a few sectors, as reflected in other reviews. Among them are robotics
[87][104][103,120], scheduling
[105][106][121,122], cyber-physical systems
[107][123] and energy systems
[108][124].
3.1. Path Planning
In manufacturing, path planning is crucial for machines such as computer numerical control (CNC) machines
[109][125] and robot manipulation
[110][126] to perform tasks such as painting, moving in space and welding, and additive manufacturing
[94][111][110,127]. Moreover, path planning is part of the mobile robot navigation system that has an increasing presence in factories
[112][128]. The main objective of this task is to find the optimal trajectory to move the robot or part of it from one point in space to another while maybe performing an operation. In industrial environments, other factors must be considered due to the features of the task or the environment or the potentially severe consequences of a failure. These make path planning more complex, and some of the most popular ones are the avoidance of obstacles, dynamic environments and constraints of the movements of the robots and systems.
For this application, model-free DRL algorithms are predominant, probably due to the complexity of modelling a dynamic environment
[113][129]. DQN, together with its variants, is the most used one
[114][115][116][130,131,132]. Despite some issues, such as overestimating q-values and instability, DQN applications are widely used in path planning. An important task of this field is active object detection (AOD), whose purpose is to determine the optimal trajectory so that a robot has the viewpoints that allow it to gather the necessary visual information to recognise an object. DQN is still used for this purpose, outperforming other AOD methods. Fang et al. (2022)
[117][133] recently presented a self-supervised DQN-based algorithm that improves the success rate and reduces the average trajectory length. Moreover, the developed algorithm was successfully tested with a real robot arm. However, the applications of DQN variants need to become popular in order to overcome the aforementioned drawbacks.
Prioritised DQN (P-DQN) is used to upgrade the convergence speed of DQN, assigning more priority to those samples that contain more information in comparison with the experience
[118][134]. These samples are more likely to be selected to update the parameters of the ANNs. Liu et al. (2022)
[119][135] present a P-DQN-based path-planning algorithm to address path planning in very complex environments with many obstacles. This priority assignment can be detached, constituting a technique called priority experience replay (PER). This technique is combined with Double DQN (DDQN) in
[120][136], increasing the stability of the learning process. Moreover, DDQN also offers satisfactory performance without PER. An example is the path planning application presented in
[40][56], where the DDQN agent is pre-trained in a virtual environment with a 2D-LiDAR and then tested in a real environment using a monocular camera.
In line with I5.0, path planning has a challenge in robotic applications to achieve the estimation of time-efficient and free-collision paths. In this context, crowd navigation of mobile robots can be highlighted due to the need to predict the movement of other objects in the environment, such as humans. For this purpose, the DQN variant of Dueling DQN in combination with an online planner proposed in
[121][137] results in equivalent or even better performance of the state-of-the-art methods (95% of success in complex environments) with less than half the computational cost. Furthermore, based on Social Spatial–Temporal Graph Convolution Network (SSTGCN), a model-based DRL algorithm is developed in
[122][138], highlighting its robustness to changes in the environment.
Lastly, the use of hybrid DRL algorithms should be remarked on because they can work with continuous action space and are not like DQN, which is limited to discrete spaces. For example, Gao et al. (2020)
[123][139] present a novel path planner for mobile robots that combines TD3 and the traditional path planning algorithm Probabilistic Roadmap (PRM). PRM + TD3 is trained in an incremental way, achieving an outstanding generalisation for planning long-distance paths. In addition, a variant of DDPG called mixed experience multi-agent DDPG (ME-MADDPG) is applied to coordinate the displacement of several mobile robots. This algorithm enhances the convergence properties of other DRL algorithms in this field
[124][140].
3.2. Process Control
With the automation of factories, process control became a key element in manufacturing. This control is scalable from large SCADA panels that monitor the whole production chain of a factory to specific processes
[125][141]. Moreover, this manufacturing task addresses simple control operations, such as opening valves, and complex control operations, such as coordinating several robot arms for assembling. For this purpose, control strategies have typically been applied; however, the application of artificial intelligence methods, such as neural networks, is growing thanks to the development of smart factories
[10]. Given the plethora of process control tasks, this section focuses on the most recent DRL applications in this field. In addition, a subsection is dedicated to robotic control, especially robot manipulation, due to its significant role in manufacturing
[126][142].
The literature search reflects that DRL algorithms are generally applied to control specific processes and that model-free algorithms predominate. Since control tasks usually involve continuous variables, the algorithms from the policy optimisation family and hybrid algorithms are the most used ones. Regarding the former, PPO is widely applied because it is the most cutting-edge and established algorithm within the PO family. Szarski et al. (2021) apply PPO to control the temperature in a composite curing process to reduce the cycle time
[127][143]. The developed controller is tested with the simulation of a complex curing process in two realistic different aerospace parts, reducing up to 40% of the ramp time. Moreover, this test demonstrates the controller’s applicability because it was only trained for one of the parts. Other PPO applications can be found in other manufacturing processes, such as controlling the power and velocity of a laser in charge of melting via powder bed fusion
[48][64] and controlling the rolls of a strip rolling process to achieve the desired flatness
[128][144]. It should be noted that this last application is also compared with DRL hybrid algorithms, outperforming them regarding results and stability.
Although PPO has been applied to some control tasks, its on-policy nature generally entails larger training. Off-policy DRL algorithms improve it thanks to being more sample efficient
[129][145], and DDPG is the most popular off-policy hybrid algorithm for control applications. This algorithm is an extension of DQN for continuous action spaces, and it is the first off-policy algorithm for this type of space, showing positive performance in the control of complex systems. Fusayasu et al. (2022)
[130][146] present a novel application of DDPG in the control of multi-degree-of-freedom spherical actuators, characterised by their difficult control due to their strong non-linearities of torque. DDPG achieves a highly accurate and robust control, outperforming PID and neural network controllers. In the chemical process control, Ma et al. (2019)
[131][147] demonstrate how a DDPG controller can control a polymerisation system, which is a complex, multi-input, non-linear chemical reaction system with a large time delay and noise tolerance. In this case, the main adaptation of the original algorithm is the inclusion of historical experience to deal with time delay. Another application of DDPG in the optimisation of chemical reactions is
[132][148], where the maximisation of hydrogen production through the partial oxidation reaction of methane is reached. Moreover, TD3, as an improved version of DDPG, is also applied in this type of process, for instance, the multivariable control of a continuous stirred tank reactor (CSTR)
[133][149]. The importance of DDPG and TD3 in process control in the chemical industry is shown in
[134][150], where hybrid and PO algorithms are compared for five use cases, and DDPG and TD3 outperform all of them in all use cases.
3.3. Robotics
Robot manipulation encompasses a wide range of tasks, from assembly operations, such as screwing and peg-in-hole, to robot grasping and pick-and-place operations
[135][136][151,152]. The characteristics of DRL make it very suitable for robotic tasks, which has produced a close relationship between both fields for many years, leading to promising results in the future
[104][137][50,120]. This section includes a mini-review of the most recent DRL applications in this vast field.
Firstly, this re
svie
archw starts with the peg-in-hole assembly, the robotic manipulation task with the most DRL applications according to the literature search, and its high precision characterises it. For this task, PPO is the most commonly applied algorithm with applications such as
[87][138][139][103,153,154]. Among them, the PPO controller developed by Leyendecker et al. (2021)
[87][103] should be noted, where the algorithm is trained through curriculum learning. This technique consists of dividing the learning problem into several subtasks and learning them in ascending order of complexity, which allows the learning of the simpler tasks to be used to learn the more complex ones and improves generalisation skills
[140][155].
Although PPO applications abound, other DRL algorithms can be found. For example, Deng et al. (2021) propose an actor-critic-based algorithm that improves the stability and sample efficiency of other state-of-the-art algorithms such as DDPG and TD3
[87][88][103,104]. In addition, training this algorithm with hierarchical reinforcement learning (HRL) notably increases the generalisation capability to other assembly tasks. HRL consists of decomposing tasks into simpler and simpler sub-tasks, establishing levels of hierarchy in which more complex parent tasks are formed by simpler child tasks. With this technique, the most basic tasks are learned, which allow for the development of more complex tasks
[141][156]. Furthermore, among the applications of hybrid algorithms, the work of Beltran-Hernández et al. (2020)
[88][104], which uses SAC to learn contact-rich manipulation tasks and tests the algorithm with a real robot arm, and the proposed uses of DDPG to control the force in contact-rich manipulation in
[142][157] and to enhance the flexibility of assembly lines in
[143][158] are noteworthy. The latter is particular in that it uses a digital twin model of the assembly line to train the DDPG algorithm, and once trained, this model is used to monitor the assembly lines and predict failures during the production stage.
Digital twins are a technology that is increasingly important in I.40 and I.5.0, which seems to be crucial to the development of smart manufacturing. Indeed, some DRL control applications, such as
[143][158], leverages this technology to increase their data efficiency and robustness. Liu et al. (2022) train a DQN algorithm with the digital twin model of a robot arm that has to perform a grasping task
[144][159]. In this line, Xia et al. (2021) do the same with DQN and DDQN + PER for a pick-and-place task
[53][69]. Both cases highlighted the smoother transfer of knowledge from the simulation to the real environment thanks to digital twin models.
Finally, another robot manipulation task to which DRL is currently applied is pick-and-place, which in turn includes other tasks such as motion planning, grasping and reaching a point in space
[137][50]. As in other robotic tasks, the use of DDPG is predominant
[145][160]. Some recent examples are
[146][161], whose objective is reaching a point and measuring the influence of different reward functions, and
[147][162], where the application of DDPG results in robust grasping in pick-and-place operations. In addition, the joint use of DDPG and HER is common, highlighting the work of Marzari et al. (2021), that DDPG + HER is used together with HRL to learn complex pick-and-place tasks
[148][163]. Nonetheless, other state-of-the-art algorithms are used in this field, such as TD3 + HER for the motion planning of robot manipulators
[149][164] and PPO and SAC for a grasping task with an outstanding success rate
[150][165]. In this latter work, it should be noted that SAC training requires fewer episodes, but they last longer.
3.4. Scheduling
The aim of scheduling is to optimise the use of time to reduce the consumption of resources in all senses, hence improving the overall efficiency of the industrial processes. In this, several sub-objectives must be considered. It plays an essential role within any kind of industry and has always been a significant research topic approached from different fields. However, due to its interdisciplinary nature, the size of the problem can easily scale up. Consequently, the optimisation problem has multiple objectives and is usually complex given the uncertainties that must be faced and the high interconnectivity of the elements involved
[151][166]. In this sense, DRL arises as an enabling technology, as reflected in literature reviews concerning smart scheduling in the industry 4.0 framework
[152][167].
On the one hand, in order to solve the multi-objective optimisation problem, a common approach is the implementation of multi-agent DRL algorithms. Several successful studies can be found about this in different production sectors
[12]. Lin et al. (2019)
[85][101] implemented a multi-agent DQN algorithm for a semiconductor manufacturing industry in order to cover the human-based decisions and reduce the complexity of the problem, resulting in enhanced performance. Through a similar approach, Ruiz R. et al. (2022)
[86][102] focus on the maintenance scheduling of several machines presenting up to ≈ 75% improvement in overall performance. Other studies combine those algorithms with IoT devices for smart resource allocation
[153][168] or with other algorithms, such as Lamarckian local search for emergency scheduling activities
[154][169]. For the latter, Baer et al. (2019)
[155][170] propose an interesting approach by implementing a multi-stage learning strategy, training different agents individually but optimising them together towards the global goal, presenting great results. On the other hand, in order to face the increasing fluctuation in production demand and product customisation, actor-critic DRL approaches are usually implemented
[156][171].
The actor-critic approach is characterised by its robustness
[157][172] and acts as an upgrade of the traditional Q-learning, which could act as a decision-support system easing operators scheduling tasks
[158][159][173,174]. Through the actor-critic approach, the policy is periodically checked and recalibrated to the situation, which highly increases the adaptability and eases the implementation in real-time scheduling
[80][160][96,175]. In addition, several studies reflect that it can be implemented with cloud-fog computing services
[161][162][176,177]. Furthermore, the performance can be increased by implementing a processing approach divided into batches, as reflected in Palombarini et al. (2018, 2019) studies
[163][164][178,179]. There are also some novel approaches integrating different neuronal networks that aim to cope with complexity and expand the applications. For example, Park et al. (2020) implemented a proximal policy optimisation (PPO) neuronal network trained with relevant information from scheduled processes, such as the setup status
[165][180].
For latter, despite the great results presented by the research, unfortunately, most of those approaches are not adopted in a practical context. Due to the scheduling policies already established in the production industries, it is quite complex to introduce novel approaches even if the research shows good results. Consequently, increasing research efforts are required in this direction.
3.5. Maintenance
The maintenance objective is to reduce breakdowns and promote overall reliability and efficiency
[166][181]. The term mainly refers to tasks required to restore full operability, such as repairing or replacing damaged components. It significantly impacts the operational reliability and service life of the machinery in any industry. There are four types of maintenance: reactive, preventive, predictive and reliability-centred
[167][168][182,183]. Historically, reactive maintenance has predominated, which was performed after the failure of the machine, mainly due to limited knowledge about their operation and failures. Nowadays, this strategy is still in use for unpredictable failures and failures of cheap objects. Over time, the understanding of the process has increased, and preventive maintenance has come up. Further on, I4.0 technologies and advances in AI have enabled predictive and reliability-centred maintenance
[169][184].
As part of AI advances for maintenance activities in the industry, RL algorithms play an important role due to their self-learning capability
[170][185]. Moreover, the integration of neuronal networks, resulting in DRL, expands the applications and performances even further
[171][186]. Their application can help anticipate failures by predicting key parameters and also prevent failures through in-line maintenance, enlarging the lifetime of components.
The anticipation of failures is usually combined with scheduling optimisation to maximise the results
[172][173][187,188]. In order to speed up the learning phase, Ong, K.S.H, et al. (2022) boards the predictive maintenance problem with a model-free DRL conjoined with the transfer learning method to assist the learning by incorporating expert demonstrations, reducing the training phase time by 58% compared with baseline methods
[174][189]. On the other hand, Acernese, A. et al. board fault detection for a steel plant through a double deep-Q network (DDQN) with prioritised experience replay to enhance and speed up the training
[175][190].
There are also hybrid approaches, such as the one proposed by Chen Li et al. (2022)
[176][191], where feedback control is implemented based on an advantage actor-critic (A2C) RL algorithm to predict the machine status and control the cycle time accordingly. In addition, Yousefi, N. et al. (2022), in their study, propose a dynamic maintenance model based on a Deep Q-learning algorithm to find the optimal maintenance policy at each degradation level of the machine’s components
[177][192].
3.6. Energy Management
Nowadays, and especially with the I5.0 and worldwide policies (e.g., Paris agreement
[178][193]), energy consumption and environmental impact are in the spotlight. In this sense, AI algorithms such as DRL can boost energy efficiency and reduce the environmental impact of the manufacturing industry
[179][194]. The algorithms are usually implemented into the energy market to reduce costs and energy flow control in storage and machines operation to increase their energy consumption effectiveness
[180][195]. In resource- and energy-intensive industries such as printed circuit boards (PCB) fabrication, Leng et al. demonstrated that the DRL algorithm was able to improve lead time and cost while increasing revenues and reducing carbon use when compared to traditional methods (FIFO, random forest)
[181][196]. Lu R. et al. (2020) faced a multi-agent DRL algorithm against a conventional mathematical modelling method simulating the manufacturing of a lithium–ion battery. The benchmark presents a 10% reduction in energy consumption
[182][197].