Your browser does not fully support modern features. Please upgrade for a smoother experience.
Please note this is a comparison between Version 1 by Christos Ioakimidis and Version 2 by Conner Chen.
Machine Learning (ML) as an intersection of informatics and statistics is a promising challenge for more evidence-based decisions to fill in the gap of existing technological tools and instruments for spatiotemporal requirements. As ML transcended the conventional techniques of modeling, a huge potential of big data management to address complex city problems is presented at the crossroads of modern urban planning challenges to make up their dynamics. Generally speaking, the ML methods are categorized based on the type of ‘learning’.
- case-study analysis
- machine learning
- urban planning
- spatiotemporal
- smart planning
- smart city
1. Introduction
Digitalization is gaining rising interest in all fields of daily life, being favored by the increasing computational capacities and the emergence of efficient algorithmic processes which facilitate data mining. In line with this, Machine Learning (ML) as an intersection of informatics and statistics is a promising challenge for more evidence-based decisions [1] to fill in the gap of existing technological tools and instruments for spatiotemporal requirements. Bhavsar et al. [2] define ML as a collection of data-driven models to automate data through significant patterns, while the first attempts to develop machines to imitate living behavior dates to the 30s by Ross [3]. In 1959, Samuel approaches the concept as the ‘field of study that provides computes with the ability to learn without being further programmed’ [4].
As living laboratories in a multidimensional context with tremendous environmental and social challenges, cities are being more and more implicated in these applications, especially those oriented towards meeting the complex ambitions of sustainability, resilience and climate adaptation, to cite some of them, and dealing with a noticeable mass of data ([2][3][2,3]). At the same time, rapid urbanization challenges and quality of life (QoL) degradation puts pressure on planners to channel the growth and provide monitoring strategies, while the traditional methods (e.g., surveys, etc.) are time-consuming with insufficient outcomes. Advancements in urban geography and relevant sciences, commonly geographical information systems (GIS) tools, use simulations to evaluate and analyze the complex interactions in a city with limited efficiency to simulate scenarios for future growths [4][5][4,5] and visualize spatial, demographic and other relevant data to benefit from digital innovations and patterns. These are the key transformations needed for the abovementioned roadmaps.
Combined with the technology and software advancements, ML and the field of Artificial Intelligence (AI) are being prioritized and becoming more and more essential for cities’ operations towards smart solutions, e.g., optimization of energy performance or waste management, etc. ([6][7][6,7]). They are adopted widely for diverse tasks of the digital society while reducing the human effort [8], a recognition of the achievements in data acquisition and the practical use of algorithmic approaches [9]. Many scholars have already stressed the importance of ML for accurate predictions and correlations between spatial indicators (e.g., [10][11][10,11]).
As ML transcended the conventional techniques of modeling, a huge potential of big data management to address complex city problems is presented at the crossroads of modern urban planning challenges to make up their dynamics [12][13][12,13]. Broadly speaking, ML consist of a group of different models and patterns with the ability to minimize error using repeated processes from data collection, analysis and monitoring [14]. Based on the existing definitions, Machine Learning consists of a set of techniques to automatically detect and predict data or perform decision-making processes under an important level of uncertainty [15]. Hence, ML consists of methods leading to evidence-based processes to meet the standards and quality of a complex problem. Its rapid evolution and growth, with the parallel emergence of its potential, will equal the challenges of modern cities in several fields (mobility, energy, etc.). More and more cities are being included in this dynamic, which concerns the drivers of the urban functionalities or decision-making processes optimizing performance and leading to automation. Overall, the existing ML demonstrations on urban and spatial problems consist of spatiotemporal subjects [16]; however, their implication has not yet been fully explored, despite their large repertoire [17].
Despite the technological achievements and the progress in ML uses, data availability remains a sophisticated task and not equally distributed in every corner of the world. Lack of standards, the topics of private life and confidentiality, spatial granularities or even the lack of synergies and the nature of the heterogeneous data hinder the ML operation. On the other hand, the applications of ML algorithms on specific fields, such as geography, demonstrate the complexity of benchmarking the relevant studies due to the type of data used for the ML analyses or the missing parameters [18].
2. Taxonomy of ML Methods for Urban Applications
Artificial Intelligence, globally, is divided into different parts, namely knowledge representation, genetic algorithms, Artificial Neural Networks (ANN), data mining, etc. The fields of urban planning and engineering are set to expand globally due to their strong, fast-growing relationship to data mining, especially in the smart cities’ fields [19][21]. Despite the ML type and use, the quantity and type of data affect their accuracy and efficiency and enable (or not) the path towards the solution and alternative developments. In this process, Bhavsar et al. [2] underline the importance of problem definition for the appropriate application of ML methods (Figure 14). In reality, problem identification is a complex process depending on different factors, such as data mining, user skills and perceptions, etc.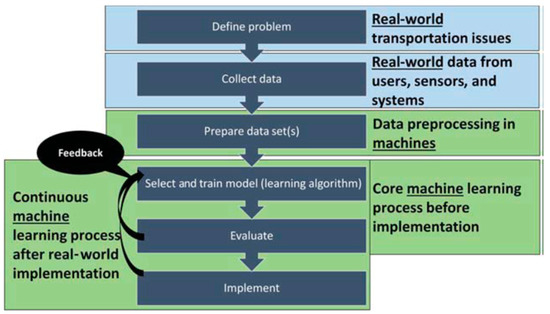
Figure 14.
Machine learning algorithm steps.
2.1. Supervised Learning
Supervised learning methods deal with a function (or an algorithm) to compute outputs based on given information and present data (e.g., the number of dwellings per ha). This information will be used for an automated process to minimize the possible risks of a prediction error, expressed as the difference between the real (data) and the computed values. Examples of this ML are the binary classifications (True or False), etc., or regression problems.2.2. Unsupervised Learning
On the other side, unsupervised learning methods depend only on the unlabeled data and aim to identify hidden patterns of data. An example of this category is clustering, which focuses on the data grouping based on similarities or the method of association for the trends’ identification concerning a specific problem.2.3. Machine Learning Algorithms: An Overview
However, the classification and taxonomy of ML require a thorough analysis of a set of attributes when discussing urban developments. Although there are many areas of focus, ML use has a major driver on land use and cover as great support for sustainable development. Nonetheless, despite the rise of smart cities and related concepts and the advancement of big data, etc., there is little evidence regarding classification, simulation or predictions [20][22]; this section is an step towards the development of this ground. Murphy [21][23] proposes three main types of ML methods, namely supervised (predictive) learning to identify a mapping from outputs to inputs considering a specific set of input-outputs, unsupervised learning, where only the inputs are given, and reinforcement learning, which is less commonly used and explain how to perform with the occurrence of given occasional rewards (Figure 25). Emerging methods, such as convolutional neural networks (CNN), proved their efficiency in extracting features from spatial data [22][24], and recurrent neural networks (RNN) are promising approaches to accurate urban simulations. Examples of successful applications are found in various studies applied to road extraction from the wider perspective of both 2D optical remote sensing images and 3D point clouds commonly used for road data acquisition developed by Chen et al. [23][24][25,26]. In the same study, a comprehensive approach to the definition of morphological feature-based tools for road shape features is designed including support vector machines (SVM) ([25][27]). In the same study, Chen et al. provided three classifications for road area extraction based on traditional methods for identifying of road features (e.g., Lu et al. [26][28], Perciano et al. [27][29], etc.) or deep learning [28][30]). Ensemble-based methods, such as random forests (RF) and similar methods, are boosted for the problem–solution studies of smart urban forms (e.g., [29][30][31][32][31,32,33,34]). On the other hand, ML methods are commonly used as a promising area to achieve smarter and more inclusive urban configurations in the tissues of modern cities [33][35].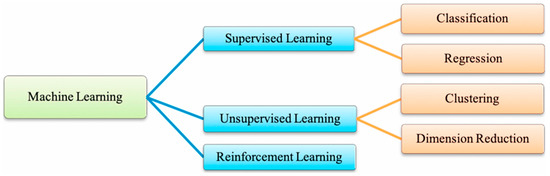
2.4. Decision-Making Urban Planning Processes
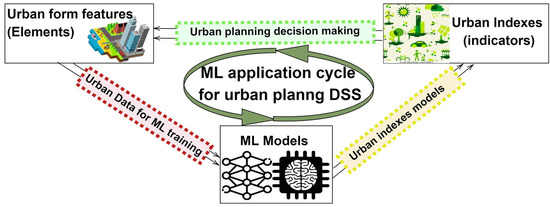
Decision-making processes are fundamental in urban planning strategies, consisting, as they do, of simplified approaches to reality to enable decisions and interactions and allow planners to adjust or modify them in vitro using parametric proposals. Decision-support systems (DSS) facilitate the integration of models and enable the interactions between the diverse parameters to adjust or test solutions and evaluate the consequences leading to desirable and viable solutions. For the special case of predictive modeling, ML has been used for the identification of urban patterns and related indicators. Taking a quick look at the existing literature and the Scopus database correlations, one identifies of 585 documents for ML and the decision-making processes published in the United States and China, as presented in Figure 36.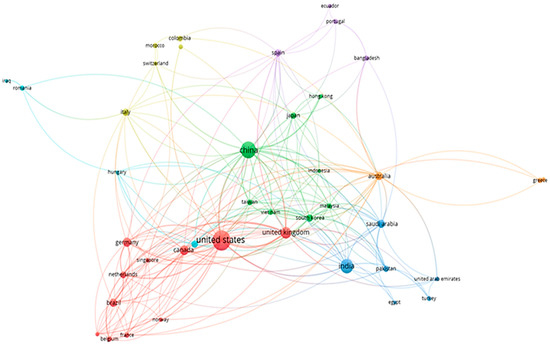
Figure 36.
Correlations of ML and secision-making processes, Scopus database.