Your browser does not fully support modern features. Please upgrade for a smoother experience.
Please note this is a comparison between Version 1 by Yintian Zhu and Version 2 by Camila Xu.
3D object detection based on point clouds has many applications in natural scenes, especially in autonomous driving. Point cloud data provide reliable geometric and depth information.
- hybrid attention
- autonomous driving
- point cloud
1. Introduction
3D object detection based on point clouds has many applications in natural scenes, especially in autonomous driving. Point cloud data provide reliable geometric and depth information. However, point clouds are disordered, sparse, and unevenly distributed, increasing the difficulty of object detection [1].
Currently, existing object detection methods mainly include image-based, point cloud-based, and multi-sensor methods [2]. In comparing them, image-based methods lack depth and 3D structure information, making it challenging to identify and locate 3D objects accurately in 3D space. Therefore, plans based on image information tend to be less effective than point clouds [3][4][5][3,4,5]. GS has proposed fusing point cloud and image data for object detection [6]. Subsequently, the classic methods MV3D, PC-CNN [7], AVOD [8], PointPainting [9], etc., have been proposed. However, although these fusion methods can integrate the characteristics of point clouds and images to a certain extent for recognition, the vast amount of calculation involved and the complex network has brought considerable challenges to this field. Thus, point cloud-based methods are the main methods for autonomous driving. The method based on the point cloud has developed rapidly in the last few years, and many classic methods have been proposed, including Pointnet [10], Pointnet++ [11], VoxelNet [12], SE-SSD [13], etc.
Early works usually convert raw point clouds into regular intermediate representations, including projecting 3D point cloud data from bird’s eye or frontal views into 2D images or dense 3D voxels. However, using voxel conversion to improve efficiency can lead to a lack of critical information, resulting in false and missed detection. PointPillars [14] encode point clouds with Pillar coding, which achieves extremely fast detection speed. However, it loses many important foreground points simultaneously, making the effect of detail processing not ideal. There have been a lot of missed and false detections in PointPillars. To solve this critical problem, TANet [15] enhances the local characteristics of the voxel by introducing an attention mechanism. However, due to the information loss during voxel conversion, it is impossible to avoid the occurrence of false and missed detection. In DA-PointRCNN [16], the density sampling method can pay better attention to where the clouds are sparse and improve missed detection. However, false detection exists due to ignoring the importance of feature information.
2. Voxel-Based Methods
In point cloud-based methods, converting the raw point cloud into a regular voxel grid and extracting local features for object detection has attracted much attention. the The voxel concept was first proposed with VoxelNet, in which the point cloud is divided into voxels by block and detected by extracting local features from each voxel. However, even this requires considerable computation. SECOND [17] adds a sparse convolution operation based on VoxelNet to speed up calculation. PointPillars directly converts point clouds into fake images, avoiding the time-consuming convolution calculation. According to their different detection stages, the existing voxel detectors can be roughly divided into single-stage detectors and two-stage detectors. While these methods are efficient and straightforward, due to the reduction of spatial resolution and insufficient structural information their detection performance is significantly affected when the point cloud is relatively sparse. Thus, SA-SSD [18] supplements the utilization of structural information by adding auxiliary networks. HVNet [19] offers a hybrid voxel network that refines the projected and aggregated feature maps from multiple scales to improve detection performance. CIA-SSD [20] introduces a network incorporating IOU-aware confidence correction to extract spatially informative features of detected objects. In comparison, two-stage detectors can achieve higher performance at the cost of higher computation and storage. Part-A2 [21] proposes a two-stage detector consisting of part perception and aggregation modules, which is better able to utilize the location information of detected objects. In general, detection methods based on voxel detection can achieve better detection effects and higher efficiency to a large extent. However, voxelizing the point cloud inevitably causes information loss. Later research work has made up for the loss and distortion caused by the point cloud data processing stage by continuously introducing complex module designs, which has made up for this defect to a certain extent; however, this has a great impact on detection efficiency. Therefore, using voxelization to process point cloud data has certain limitations.3. Point-Based Methods
Unlike voxel-based detection methods, point-based methods directly process the disordered and cluttered point cloud. Thus approach obtains features point-by-point in order to predict each point. The point cloud itself contains very rich physical structure information. Therefore, a point-wise processing network was first proposed in the form of PointNet. This network directly takes the original point cloud as input, guaranteeing no loss of physical information from the original point cloud. Subsequently, PointNet++ improved PointNet to improve the detection efficiency of the network and further optimize the network structure. Most of the subsequent point-based methods have used this network and its variants to point cloud for processing. PointRCNN [22] utilizes PointNet++ to extract features from raw point clouds and a Region Prediction Network (RPN) to generate prediction boxes. 3DSSD [23] introduces a 3D single-stage detection network which uses Euclidean space to achieve feature sampling for far points. PointGNN [24] adds a graph neural network to the framework of 3D object detection, effectively improving recognition accuracy. Proposal Contrast [25] proposed a new unsupervised point cloud pre-training framework to achieve better detection results. Proficient Teachers [26] introduces a new 3D SSL framework that provides better results and removes the necessity of using confidence-based thresholds to filter pseudo-labels. Point-based detection methods directly process the raw point cloud and effectively utilize the physical information of the point cloud itself. However, the huge amount of data inevitably takes up a lot of time and computing resources. Therefore, improving the efficiency of point-based detection is a bottleneck for this method.4. Hybrid Attention Regions with CNN Features (HA-RCNN)
Unlike voxel-based methods, point-based methods need to perform point-wise detection, and as such need to pay more attention to foreground points (i.e., cars, pedestrians, etc.). However, most current point-based object detection frameworks usually adopt downsampling methods, such as random sampling [27] or farthest point sampling. Although these sampling methods can improve computational efficiency, the essential foreground points are ignored. Therefore, in this woresearch, researchersk we aim to train a point-based model to better retain the information of foreground points and efficiently detect multiple types of objects at one time. Based on this, researcherswe propose an efficient point cloud-based object detection algorithm. As shown in Figure 12a, the proposed model framework mainly consists of three parts: Hybrid Sampling (HS), a Hybrid Attention Mechanism (HA), and Foreground Point Segmentation. First, the input original point cloud is processed through hybrid sampling, with as many foreground points retained as possible. Then, the point-wise features are generated by the HA module and focused. Subsequently, the foreground segmentation network is used to segment the foreground points and generate prediction boxes. Finally, 3DNMS is used to filter the prediction box and the refinement module retains the final boxes. In Figure 12b, each sampled point cloud input is extracted pointwise and then focused in the attention layer. Finally, the generated original pointwise features and the pointwise features developed by the attention layer are spliced together.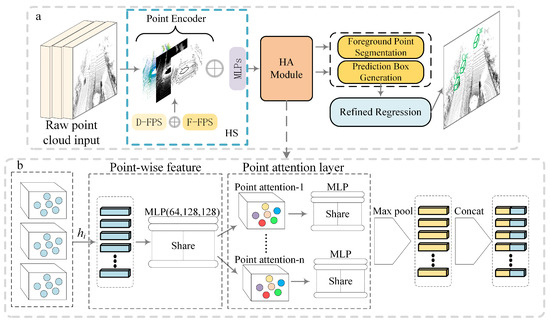
Figure 12.
HA-RCNN model frame diagram (
a
: Overall frame,
b
: HA module refinement).