Your browser does not fully support modern features. Please upgrade for a smoother experience.
Please note this is a comparison between Version 1 by Ania Cravero and Version 2 by Dean Liu.
Sustainable agriculture is currently being challenged under climate change scenarios since extreme environmental processes disrupt and diminish global food production. For example, drought-induced increases in plant diseases and rainfall caused a decrease in food production. Machine Learning and Agricultural Big Data are high-performance computing technologies that allow analyzing a large amount of data to understand agricultural production.
- agriculture
- big data
- machine learning
- data type
1. Agricultural Big Data
Big Data is a type of technology used when the solution is not trivial due to the complexity of the data. It is usually defined through the four dimensions (or 4 V’s). The first V represents the volume of data generated from a data source, stored, and processed for further analysis. The second V refers to the variety of data due to multiple structures, structures, and sizes. Data can be extracted as raw or unstructured, semi-structured, or structured data. The third V refers to the speed of data transmission needed for data to be processed and analyzed. The fourth V refers to veracity, which refers to the capability to validate the grade of the data [1][25].
Big Data allows scientists and engineers to find patterns and trends by examining large amounts of data from multiple origins. A few years ago, Big Data science became an essential modern discipline for data analysis [2][26]. Big Data includes a mix of classical domains of artificial intelligence, including ML, such as statistics, mathematics, and computer science. In general, it has database systems, ML, and distributed systems [3][27].
The Big Data process begins with specifying the sources to extract the data required [4][28]. The next step is storing the data in one of the created representatives, which depends on its processing level, whether unstructured data, semi-structured, or structured. The data are then transformed through filtering and sorting to improve the data quality for various analyses [5][29]. The next step is to analyze the classified data using analytical tools and algorithms (e.g., Deep Learning (DL), ML, OLAP) [6][30], as well as general data science [5][7][29,31]. This allows decision makers to analyze the data to visualize trends [8][32].
For example, Semlali et al. [9][33] use Big Data tools to monitor atmospheric composition. The system architecture contains the data source layer, ingestion, storage via Hadoop, the data management layer, infrastructure, and the monitoring and security layer. They used data on pollutant gas emissions from other sources, such as agriculture, enterprise, and transport. The authors were able to continuously monitor the atmospheric composition through remote sensing. Figure 1 depicts the complete process.
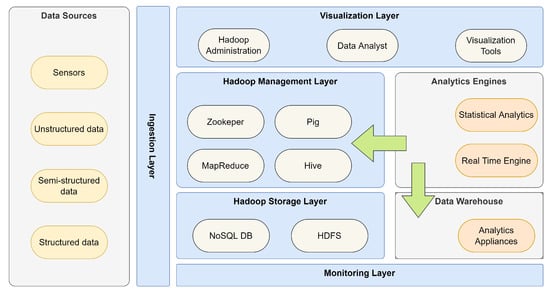
Figure 1. Architecture of Big Data for atmospheric composition monitoring.
MySQL is a database that stores data that have been extracted, processed, and transformed. Then, Python, Java, and BASH are used scripts to read the raw data in Hadoop. Figure 2 shows an example of the process.
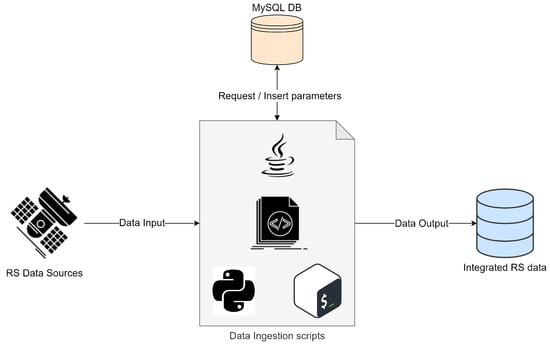
Figure 2.
Representation of the ingestion process.
Another example is Alex et al. [10][34], who develop a Big Data system that predicts whether fertilizers will cause disease in crops. They use data such as soil moisture, average rainfall, and soil nutrients. The authors also used data such as phosphorus (P), nitrogen (N), magnesium (Mg), calcium (Ca), and sulfur (S). The Big Data process starts with data enrichment, followed by data clustering, so the data can be classified and analyzed to deliver recommendations. Finally, the Hadoop ecosystem was used to store and process the data analyzed with ML. Figure 3 depicts the complete process.
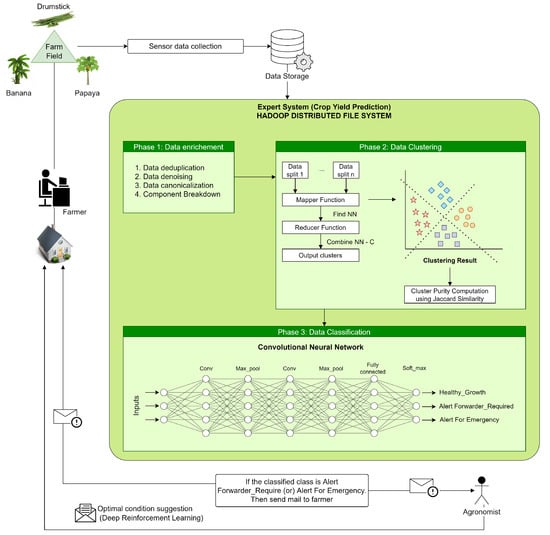
Figure 3.
Big Data architecture for fertilizer management and yield prediction.
Big Data enables data scientists and farmers to understand farming behavior, such as weather, land, soil, crops, animal production, weeds, food safety, biodiversity, remote sensing, farmer decision making, insurance, financing, and climate change [11][12]. It also enables the development of supply chain platforms, allowing agents to access high-quality products, processes, and tools that are capable of improving performance, predicting demand, and addressing farmers according to crop needs, such as the appropriate use of fertilizers.
2. Machine Learning
ML is considered an area of research focusing on mathematical theory, system characteristics, and the product of learning algorithms. The investigation process is interdisciplinary, encompassing disciplines such as artificial intelligence, knowledge theory, optimization, statistics, cognitive science, control, mathematics, and engineering [12][35]. ML is attractive because it can be used in various science domains, significantly impacting society. For example, ML can be used to solve problems such as pattern recognition, recommendation controllers, fact prediction, data mining, and automatic control systems [13][14][36,37].
ML can be classified into three algorithms depending on the available data: supervised, unsupervised, and reinforcement learning. Table 1 summarizes these techniques, differentiating them from various points of view, particularly in data processing. The “Learning Algorithms” row explains the methods used, and the “Data Processing Tasks” row contains the problems to be solved. In ML, the data must be structured, so it must be processed in most cases. This task consists of cleaning the data to remove noise and inconsistencies, integrating it if it is drawn from multiple sources, and transforming the data to normalize it [15][38].
Table 1. Machine Learning techniques.
| Classification | Supervised Learning | Unsupervised Learning | Reinforcement Learning |
|---|---|---|---|
| Data processing tasks |
Classification Estimation Regression |
Prediction Clustering |
Decision-making |
| Learning algorithms | Support vector machine Hidden Markov model Naive Bayes Neural networks Bayesian networks |
Gaussian mixture model K-means X-means |
Q-learning Sarsa learning TD-learning R-learning |
Supervised and unsupervised learning is primarily focused on data analysis. On the other hand, reinforced learning is used for decision-making situations. The ML algorithms presented in Table 1 can optimize the implementation of a task by analyzing samples of data or backgrounds. An important aspect is that ML will function better with more extensive volumes of data to be explored [15][38].
ML algorithms have been used to improve livestock welfare; increase livestock production; improve yield prediction, crop management, disease detection, weed detection, crop quality improvement, and species distinction; and improve water and soil management [11][15][16][17][4,12,38,39].
There are numerous challenges when executing ML in Agricultural Big Data since some techniques must be adapted when there is a large volume of data or the data are variable. There are also challenges in validating the data and obtaining a quality set. Solving these challenges is not a trivial task, but proposals have been carried out, allowing progress in this area of research [11][12].