The 16S rRNA gene is highly conserved in all bacteria (and also archaea). Nonetheless, it contains nine hypervariable regions (V1 - V9), where sequences of these regions can be used to identify and discriminate bacterial genus, sometimes until the species level. This makes the gene a useful tool for phylogenetic studies. With the introduction of next-generation sequencing technologies, 16S rRNA next-generation sequencing (16SNGS) has allowed profiling of bacterial communities found in organisms and the environment, and lead to the discovery of many previously unculturable members of the bacteria kingdom.
- 16S rRNA
- bacterial identification
- 16S rRNA next-generation sequencing workflow
The 16S rRNA gene is approximately 1550 bp in length with 9 hypervariable regions. For 16SNGS, sequencing is usually carried out on one (can be more, but the associated cost will increase) of the variable regions of the gene [48].
1. Introduction
With the advent of Sanger DNA sequencing, bacteria can now be identified via nucleotide sequence of the 16S rRNA gene—a short, conserved gene specific to bacterial genus (96%) and for some, species (87.5%)[1] [10]. This method of bacterial identification is culture-independent and only requires DNA of the tested bacteria[2] [14]. The development of NGS techniques, including 16S rRNA next-generation sequencing (16SNGS), allows further upscaling of sequencing quantity (fragments versus time) even in mixed cultures.
2.16SNGS: Platforms, Workflow and Bioinformatics Analysis
2.1. NGS Technology
The era of NGS began with the introduction of pyrosequencing technology by 454 Life Sciences in 2005, followed by the Solexa/Illumina platform, Life Technologies’ SOLiD, Ion Torrent and Ion Proton sequencers, and later, the MiSeq and HiSeq platforms from Illumina[3][4][5] [17,23,24]. Even though pyrosequencing is considered the “pioneer” of NGS, it is now no longer available after the platform was discontinued by Roche in 2015. The Illumina and Ion fleet of sequencers operate using a “sequencing by synthesis” chemistry[6] [25], compared to the “sequencing by ligation” technology of the now (also) discontinued SOLiD platform[7] [26]. Due to its ability to read palindromic sequences, “sequencing by synthesis” appears to be the more popular chemistry[8] [27], resulting in the dominance of both Illumina and Ion sequencers (currently: Ion Torrent Genexus System and Ion Gene Studio S5 System) in NGS laboratories. Illumina sequencers are now available in either benchtop or production scale categories, allowing users more options to select the best NGS platform according to their laboratory needs and budget allocations (https://www.illumina.com/systems/sequencing-platforms.html). Of note, the most recent player in the NGS industry will be Complete Genomics (acquired by Beijing Genome Institute (BGI))’s “DNA nanoballs” sequencing platforms (https://en.mgitech.cn/products/)[9] [28]; these platforms were reported to be comparable in performance to Illumina sequencers[10][11][12] [29–31]. In the recent decade, third-generation or long-read sequencing technologies by Pacific Biosciences and Oxford Nanopore Technology have also been launched[13][14][15] [32–34], although, due to cost concerns, these platforms are mostly used in research institutes compared to diagnostic laboratories. For a comprehensive overview of NGS platforms and their associated chemistries, readers may refer to reviews by Ambardar et al.[16] [35], Besser et al.[17] [36] and Slatko et al. [18][37]. Regardless of their sequencing chemistry, all NGS platforms can generate millions of DNA molecules with different yields and sequence lengths via parallel sequencing, and allow simultaneous multiplexing of several hundred samples in a single run[19] [38].
2.2. 16SNGS Workflow and Bioinformatics Analysis
Introduction of NGS technologies significantly promoted the development of “metagenomics”. The term “metagenomics” was first used by Handelsman et al. over 20 years ago, where it refers to the study of genetic material from a sample without the need for isolation and culturing of the microorganisms contained in the sample itself[20][21] [39,40]. Originally used to study microbial community diversity within samples from the environment and also organisms, laboratories built on the metagenome concept to sequence only the 16S rRNA gene of bacterial populations within specimens to identify bacteria[4][22] [23,41]. Nevertheless, the workflow for bacteria identification via 16SNGS is vastly different from that of the conventional protocol of culture and biochemical testing (CBtest) (Figure 1).
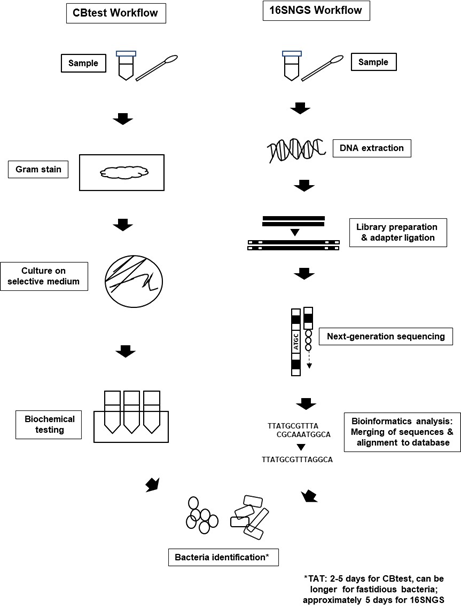
Figure 1. Bacterial identification workflow via CBtest is different from that of 16SNGS. For CBtest, samples are subjected to gram staining and culture on selective medium. Subsequent biochemical testing will reveal the identity of the bacteria. On the other hand, DNA extraction from samples is carried out in the first step of 16SNGS workflow. After library preparation, NGS of the 16S rRNA fragments will then be done, followed by bioinformatics analysis to identify the bacterial sample. Turn-around-time (TAT) of the identification process is workflow-dependent.
Briefly, the 16SNGS workflow starts with genomic DNA extraction of bacteria from collected samples. Genomic DNA is extracted using either conventional protocols or commercialized kits, and subsequently quantified to determine quantity and quality of the extracted DNA[23][24] [42,43]. Following this, 16S rRNA gene libraries are prepared, from which variable regions of the 16S rRNA gene will be amplified[5][25] [24,44]. Depending on the sequencing platform, the variable region selected for amplification and sequence for bacterial identification may differ, though it has been reported that the V4-V6 regions are most representative of the full-length 16S rRNA gene[26][27][28][29] [45–48]. Subsequently, DNA pre-processing to obtain specific sizes of DNA fragments is carried out. Adapters will then be added onto the amplified 16S rRNA region. Following this, quantification and normalization of the amplicons will be carried out prior to sequencing[5][30][31][32] [24,49–51].
Increasingly, the processes of DNA extraction and library preparation have been identified as potential bottlenecks of the NGS workflow, especially in a diagnostic laboratory dealing with a large number of samples, daily. To counter this, automated nucleic acid extraction machines, such as the QIAcube (Qiagen Inc.), Maxwell® RSC (Promega Corporation) and KingFisher automated extraction and purification platforms (Thermo Fisher Scientific) allow walk-away DNA extraction[33] [52], and are now an essential component in many large NGS centers. In addition, automation in liquid handling for library preparation is achievable via pipetting workstations such as the Biomek i-Series (Beckman Coulter and Bravo Automated Liquid Handling Platform (Agilent)[34] [53]. In future, microfluidics solutions for NGS library preparation will enable miniaturization and enclosed environment for the process, minimizing contamination and optimizing laboratory space utilization[35][36][37] [54–56].
After sequencing is completed, raw data pre-processing is important prior to bioinformatics analysis. This includes the screening and removal of sequencing adapters, assessing overall sequencing read quality (quality checking), trimming or filtering low quality reads and filtering of reads based on sequence length. This step is important for removing low quality and erroneous reads. To detect putative chimeric sequences in filtered data, the sequences are normally subjected to chimera check[38] [57]. At this stage, all chimeric sequences are removed before the next step of analysis. For data pre-processing, multiple tools are freely available, including PEAT[39] [58], Trimmomatic [40][59] and FastQC (Babraham Bioinformatics, Cambridge). For paired-end data, the merging of forward and reverse reads is done as the first step of quality control and could be performed with BBMerge[41] [60]. To analyze the 16S rRNA gene in bacteria, a common approach is via operational taxonomic unit (OTU) clustering, where sequences are clustered into a representative OTU sequence, defined at ≥97% sequence similarity level[42][43] [61,62]. The OTU-based approach is used to distinguish and differentiate biologically real nucleotide differences from artefacts[44] [63]. The primary output of this approach will be OTU tables represented by BIOM file format. Quantitative Insight into Microbial Ecology (QIIME)[45] [64] is one of the most popular tools for the OTU-based approach. Recently, the amplicon sequence variants (ASVs) approach has been introduced; several pipelines are now available with the aim to correct sequencing errors and improve taxonomic resolution, including DADA2[46] [65], Qiime2-Deblur[47] [66] and USEARCH-UNOISE3[48] [67]. Sensitivity and specificity differ between different pipelines, among which DADA2 was reported to have the best sensitivity and resolution. Even though it produces a higher number of spurious ASV compared to others, DADA2 would still be the best choice to obtain the highest possible resolution[49] [68].
Subsequent alignment of the consensus sequences to a reference database will identify the bacteria being investigated. Public repositories of bacterial 16S rRNA gene database are available for this purpose. The NCBI Bacterial 16S Ribosomal RNA RefSeq Targeted Loci Project (https://www.ncbi.nlm.nih.gov/bioproject/33175) curates comprehensive and non-redundant 16S rRNA sequences submitted by the public to the International Nucleotide Sequence Database Collaboration (INSDC)[50] [69]. On the other hand, the Ribosomal Database project hosted by Michigan State University[51] [57] also contains 16S rRNA sequences from INSDC, though it has a smaller source of taxonomy classification compared to NCBI[52] [70]. Pathogen identification can also be done using SILVA (https://www.arb-silva.de), which provides aligned rDNA sequences from Bacteria, Archaea and Eukaryota domains [53][71].
The Greengenes database (http://greengenes.secondgenome.com) is the default database in the QIIME pipeline. Nonetheless, this database is one of the more popular database used in 16SNGS[54] [73]. However, the database has not been updated since 2014, and may not contain nomenclature of novel or renamed bacteria after 2014. In recent years, new 16S rRNA gene databases such as the GRD—Genomic-based 16S ribosomal RNA Database (https://metasystems.riken.jp/grd/) and the EzBioCloud 16S database (https://www.ezbiocloud.net/resources/16s_download) have been established. GRD curators correct misannotations or missing anti-SD sites and other short segments of the 16S rRNA gene sequences extracted from complete genomes for more reliable taxonomic assignments. EzBioCloud 16S database is a commercial product; nevertheless, at the time of writing, it is freely available for users from academic and non-profit institutions. The database has been shown to allow bacterial identification to species level and provided taxonomic accuracy comparable to SILVA and Greengenes [55][74].