Your browser does not fully support modern features. Please upgrade for a smoother experience.
Please note this is a comparison between Version 2 by Sirius Huang and Version 1 by Keith Man.
Many computer vision applications cannot rely on general image data provided in the available public datasets to train models, instead requiring labelled image data that is not readily available in the public domain on a large scale. At the same time, acquiring such data from the real world can be difficult, costly to obtain, and manual labour intensive to label in large quantities. Because of this, synthetic image data has been pushed to the forefront as a potentially faster and cheaper alternative to collecting and annotating real data.
- computer vision
- image synthesis
- synthetic image data
1. Introduction
Modern approaches to computer vision primarily center around the use convolutional neural networks (CNN) and deep learning networks to train image processing models, methods which necessitate large amounts of labelled data and significant computational resources for training, while it is possible to use unlabelled data via unsupervised learning to train some computer vision models, the resulting performance is typically inferior to training via supervised learning and, in some applications, can fail to produce a model with meaningful performance [1]. The need for large quantities of labelled data makes it difficult for computer vision to be utilised in applications where the collection of large amounts of data is impractical, labelling data is costly, or a combination of both. Medical applications struggle with large scale data collection, crowd counting annotation remains a labour intensive task when done manually, and niche applications such as vital sign detection from drones suffers from both. Harder still is ensuring that the collected data is of sufficient quality and diversity to train a robust computer vision model to the performance level required by the application. These difficulties in image data acquisition has seen an increase in interest in synthetic image data as a potentially cheaper and more accessible alternative to acquiring real data for training. While multiple data types are used in the field of computer vision, this discussion is primarily focused on evaluating the use of camera-like image data and methods of generating such data synthetically. As such, the synthetic generation of data types that have seen use in computer vision, such as radar scans, sonar scans, and lidar point clouds are not considered.
Synthetic image data is defined herein as any image data that is either artificially created by modifying real image data or captured from synthetic environments. This can take many forms, including the digital manipulation of real data [2] and the capture of images from synthetic virtual environments [3]. The visual look of synthetic image data also varies between fields of application, from composite imagery [4,5,6][4][5][6] to photo-realistic computer generated images [7,8,9,10,11,12][7][8][9][10][11][12].
2. Computer Vision and Synthetic Image Data
The rise of CNN and deep learning networks in computer vision has necessitated ever larger amounts of image data for training and testing. Such image data is commonly stored in the form of photos and videos. The traditional method of obtaining image data for training, testing, and validation of neural networks has been to capture data from the real world, followed by manual annotation and labelling of the collected data. This methodology is relatively simple and cost effective for smaller image data sets, where there are a minimal number of key objects per image, the exact position of objects is not important, and only the general classification is needed. However, this methodology becomes increasingly more costly when scaled up to large data sets or datasets that require more detailed annotation. The first problem is the collection of large amounts of data. It is possible to automate the collection of real world image data to a certain extent in applications that utilise fixed cameras or vehicle mounted cameras, but this is not the case in all computer vision applications. Collection of large datasets for applications such as facial recognition and medical scans can be very difficult for a range of reasons including privacy, cost, and other legal restrictions. It can also be difficult to reliably collect data of specific environmental conditions such as foggy roads, where the presence of fog is not something that can be typically created in a public space just for the sake of data collection. The difficulty only increases when detailed data annotation is needed. Manual data annotation can be a slow and laborious task depending on what needs to be annotated and to what degree of accuracy and precision. Some data sets, such as ImageNet [20][13], are relatively simple to annotate manually as the images primarily need to be placed into categories based on what the primary object in focus is. However, the annotation of over a million images is a massively time consuming task, even using a large group of people. When considering the annotation of more complex details such as the number of people in a crowd, object poses, or the depth of objects, the cost effectiveness decreases significantly. Time and money are not the only concerns either, manual annotation quality tends to decrease when dealing with large data sets due to human error. In some applications, such as the previously mentioned crowd counting, it may not even be possible for a human to reliably count the number of people depending on image quality and crowd density. For such applications, synthetic data provides two key benefits. The first benefit is that data generation can be automated. Generation of synthetic human faces with varying levels of realism has been possible for many years and has enabled the creation of data sets for facial recognition without the privacy concerns that come with taking photos of people or the time and cost required for many people to have their photo taken. The second benefit is that as long as the data synthesis model is able to keep track of various objects and features during the synthesis process, detailed automatic annotation is possible. Of course, it is important to note that although automatic annotation is possible, it is still dependant on how the data synthesis is set up. Detailed information on all objects within a virtual 3D environment is usually available in 3D modelling software or game engines, but if that information is not extracted as part of the data synthesis process then there is fundamentally no difference to collecting data from the real world. These are the primary difficulties behind data collection and annotation for computer vision applications and the major benefits synthetic data can provide.3. Types of Synthetic Imagery for Computer Vision
Synthetic image data can be broadly categorised into two types, synthetic composites and virtual synthetic data.3.1. Synthetic Composite Imagery
Synthetic composite imagery refers to real image data that has been digitally manipulated or augmented to introduce elements that were not originally in the image data. This includes the digital manipulation of the image environment, introduction of synthetic objects into the image or the splicing of different real images into a new image. Synthetic composite datasets such as SURREAL [21][14] are created by projecting 3D synthetic objects or people into real background environments, Figure 1. This data type is often used in situations where the background environment contains enough useful or significant features that it is not worth the loss in domain shift or the effort to recreate the environment synthetically. The SURREAL dataset was primarily created to train networks on human depth estimation and part segmentation. As a result, the synthetic humans do not take into account the background environments they are placed in. The resulting scenes can be easily identified as synthesised by the human eye, but features the network needs to learn are attached to the human object, so the background simply serves as a way to reduce the domain gap to real data by increasing environmental diversity.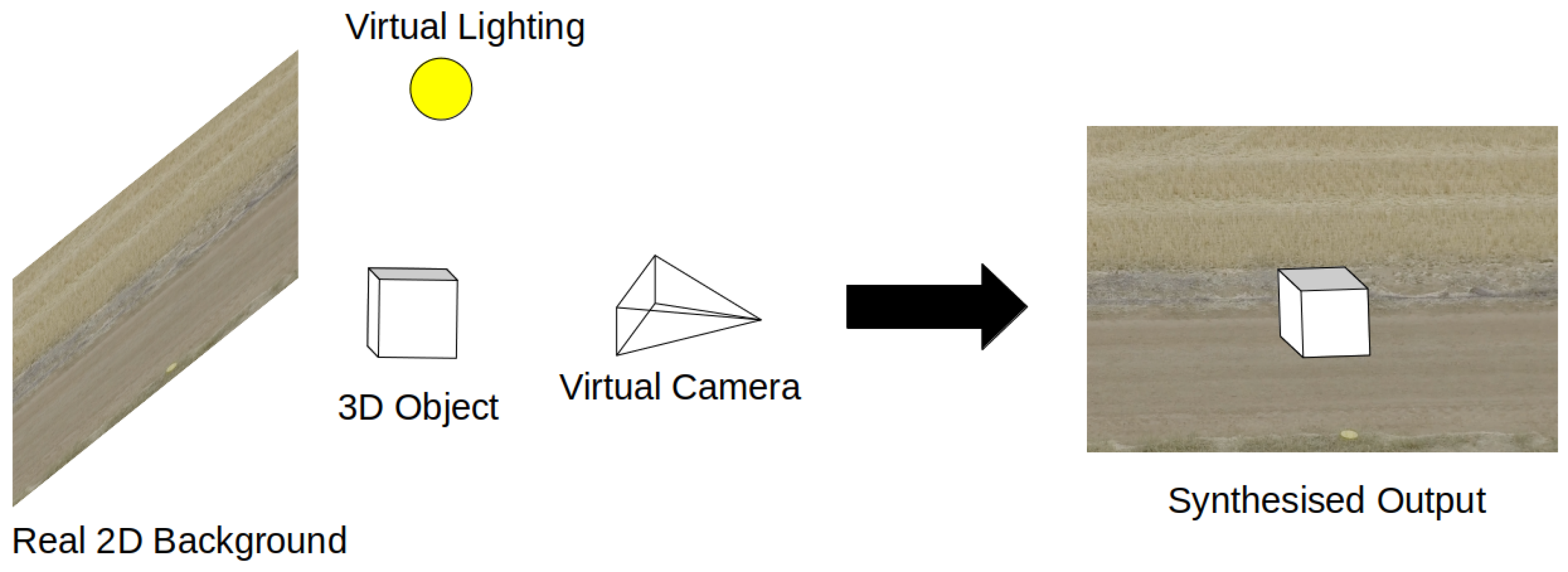
Figure 1.
Synthesis via projection of synthetic 3D object onto real 2D background.
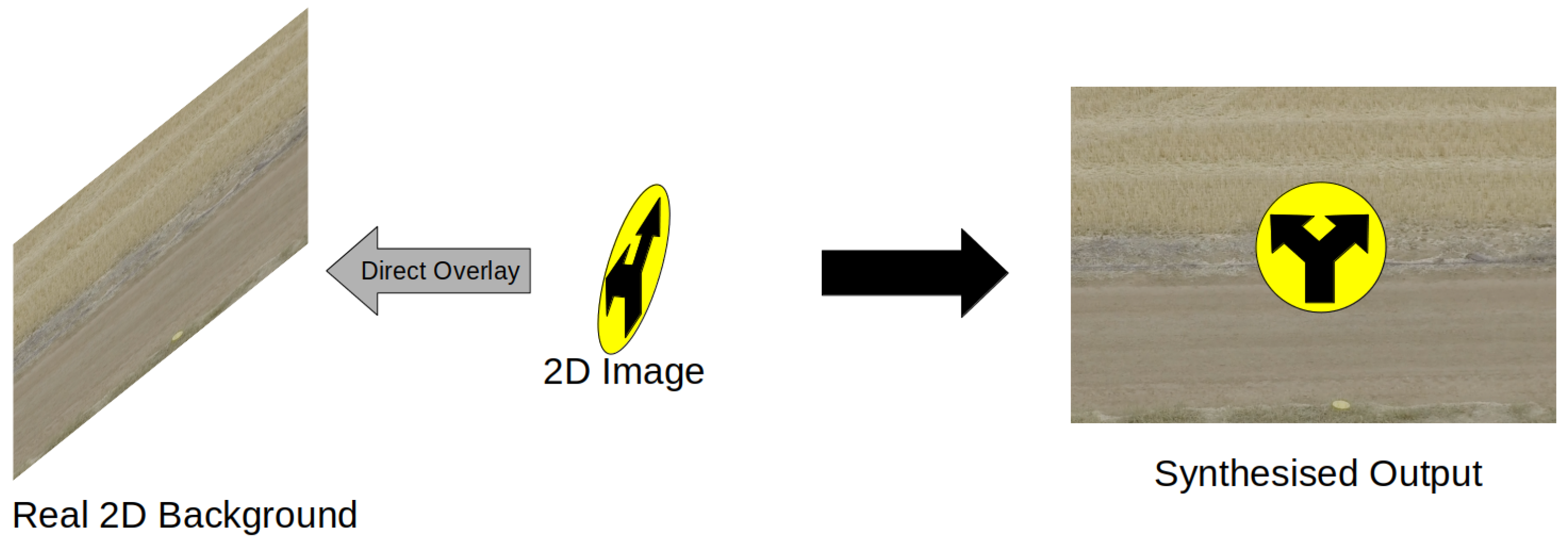
Figure 2.
Synthesis via overlaying 2D image onto real 2D background.
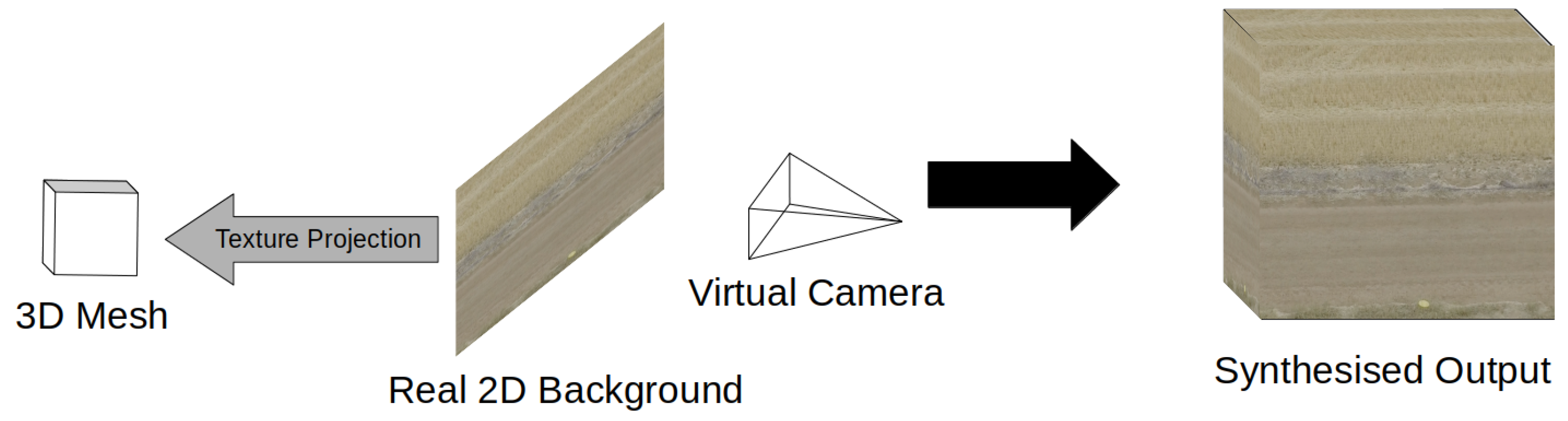
Figure 3.
Synthesis via projection of real 2D image onto 3D mesh.

Figure 4.
Synthesis via processing of noise maps.
3.2. Virtual Synthetic Data
Virtual synthetic data refers to image data that is completely synthesised, containing no real data directly. This can apply to a wide range of synthetic image data from synthetic objects with patterned textures placed in front of artificial backgrounds to photorealistc 3D environments designed to emulate the real world. Based on the types of virtual synthetic data generation methodologies, virtual synthetic data can be categorised into three groups, virtual scenes, virtual environments, and virtual worlds. This categorisation is independent of the photo-realism of the data that is produced. Virtual scenes are the simplest form of virtual synthetic data. Virtual scenes typically use the minimum amount of 2D and 3D objects to create a scene to capture synthetic image data. The generation of synthetic faces for facial recognition tasks using 3D morphable models or parametric models are an example of virtual scenes. Synthetic faces often do not generate anything below the neck, some models only generate a mask of the face. When viewed from the front, the faces can be captured and used as synthetic image data. If a background is required, it only needs to look correct from the viewing angle, in some situations a realistic background might not even be required. Observing the face from different angles or positions makes it clearly visible that the head is not a complete object. It is not a complete virtual environment, and for the purposes of such applications, a complete virtual environment is not required. Virtual environments are a step above virtual scenes and comprise a complete 3D virtual construction of a specific environment. The environment could be the inside of a house or a pedestrian crossing. Either way, its goal is to enable the capture of image data from multiple perspectives without risking the degradation of data quality due to problems such as object artefacts. When viewed from outside, the virtual environment may still look incomplete, but within the environment, it is self consistent. Virtual worlds are effectively virtual environments on a larger scale. Scenes outside a virtual environment that may have been flat 2D background are fully constructed with events occurring beyond the view of the virtual camera. This is most commonly found in virtual data captured from games that have pre-built large scale environments, such as from the game Grand Theft Auto V. Creating virtual worlds to collect such data is labour intensive, which is why collecting data from games with pre-built worlds is a common alternative. Virtual KITTI [29][22] is an example of a virtual world where the environment from parts of the KITTI dataset [27][20] was recreated digitally to produce a virtual copy of the KITTI dataset. In the field of object detection, some research has moved towards highly photorealistic object renders to reduce the domain gap to the target domain. Other research has found that photorealism might not be the only method of reducing domain gap, instead by using domain randomization, where the objects of interest are placed into random non-realistic environments, it is possible to force a model to learn object features [30][23]. Compared to photorealistic objects, this type of synthetic data may not fit the target domain as well, but its generalisation means that it stands to have better average performance across multiple domains. Virtual synthetic data offers a way to create both photorealistic and photo-unrealistic environments that can be manipulated as required to produce the necessary image data. Facial recognition has made significant progress over the past few years thanks to developments in deep learning networks and large scale data sets. However, it has started to become increasingly difficult to obtain larger data sets from the internet by trawling for faces due to labelling noise and privacy concerns. As a result, synthetic data has become the alternative to obtaining large data sets. The performance of networks trained on synthetic data for facial recognition has historically not been good, the domain gap has often been very large, resulting in poor real world performance. However, synthetic synthesised faces still offer the great benefit of avoiding issues with privacy and developments over the years have shown increased performance in face generation technology [31][24]. Moving past the generation of virtual synthetic data for standalone objects and faces, there are some applications that necessitate the construction of a larger virtual scene. In the scenario where a task such as pedestrian detection is required, but there is no existing real data to conduct network training or even domain adaptation, synthetic data is the only available method of sourcing any data to train a pedestrian detection model [3]. The problem is that synthetic data suffers from domain gaps with real data and without any real data, traditional methods of reducing the domain gap, such as mixing data or fine tuning after pre-training on synthetic data are not possible. In cases like this, the best option is to provide as much ground truth as possible from the virtual scene that has been constructed. Vehicle re-identification is another field that can utilise virtual synthetic data in the scope of a virtual scene, while vehicle detection and identification is closely related to tasks such as urban driving, unlike urban driving, vehicle re-identification is primarily concerned with stationary vehicles and so synthetic vehicles can be placed into small virtual scenes for data collection. Similarities between vehicle types when viewed from different angles as well as the lack of differences between some vehicles types can cause many difficulties with real data. To address this issue, highly diverse data sets are required to learn specific features. However, even if such data is available, manually annotating such data is prohibitively expensive. Synthetic data provides an alternative source of large automatically labelled data that can also be generated from many different perspectives, allowing for much more diverse data sets than what might be normally available from the real world [32][25]. In cases where synthetic scenes are not sufficient to produce the data required for the application, synthetic worlds offer a much larger environment from which to capture data at a computational cost. Most virtual worlds are not fully utilised all the time. Instead, virtual worlds allow for the capture of data in different environments, which can be useful in applications such as autonomous vehicles, while photo-realistic environments are not possible without the use of dedicated designers and significant rendering time, it is possible to generate more basic environments using city layout generation algorithms combined with pre-textured buildings, allowing for the creation of grid-like city environments. The effect of photorealism on performance is substantial, but the biggest advantage of virtual synthesised environments lies in the automatic labeling of objects as well as complete control over environment variables [33][26]. While virtual synthetic data does not directly contain any real data, this does not mean that it cannot reference or replicate real data. The Virtual KITTI data set [29][22] is a fully synthetic recreation of a subset of the KITTI data set. The goal of creating a virtual copy of the KITTI data set was to provide evidence that models trained on real data would perform similarly in virtual environments and that pre-training on synthetic data should provide improvements in performance after fine-tuning.References
- Atapour-Abarghouei, A.; Breckon, T.P. Real-time monocular depth estimation using synthetic data with domain adaptation via image style transfer. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 2800–2810.
- Sakaridis, C.; Dai, D.; Van Gool, L. Semantic foggy scene understanding with synthetic data. Int. J. Comput. Vis. 2018, 126, 973–992.
- Hattori, H.; Lee, N.; Boddeti, V.N.; Beainy, F.; Kitani, K.M.; Kanade, T. Synthesizing a scene-specific pedestrian detector and pose estimator for static video surveillance. Int. J. Comput. Vis. 2018, 126, 1027–1044.
- Tripathi, S.; Chandra, S.; Agrawal, A.; Tyagi, A.; Rehg, J.M.; Chari, V. Learning to generate synthetic data via compositing. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–17 June 2019; pp. 461–470.
- Ekbatani, H.K.; Pujol, O.; Segui, S. Synthetic Data Generation for Deep Learning in Counting Pedestrians. In Proceedings of the ICPRAM, Porto, Portugal, 24–26 February 2017; pp. 318–323.
- Rogez, G.; Schmid, C. Image-based synthesis for deep 3D human pose estimation. Int. J. Comput. Vis. 2018, 126, 993–1008.
- Behl, H.S.; Baydin, A.G.; Gal, R.; Torr, P.H.; Vineet, V. Autosimulate:(quickly) learning synthetic data generation. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; pp. 255–271.
- Martinez-Gonzalez, P.; Oprea, S.; Garcia-Garcia, A.; Jover-Alvarez, A.; Orts-Escolano, S.; Garcia-Rodriguez, J. Unrealrox: An extremely photorealistic virtual reality environment for robotics simulations and synthetic data generation. Virtual Real. 2020, 24, 271–288.
- Müller, M.; Casser, V.; Lahoud, J.; Smith, N.; Ghanem, B. Sim4cv: A photo-realistic simulator for computer vision applications. Int. J. Comput. Vis. 2018, 126, 902–919.
- Poucin, F.; Kraus, A.; Simon, M. Boosting Instance Segmentation With Synthetic Data: A Study To Overcome the Limits of Real World Data Sets. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 11–17 October 2021; pp. 945–953.
- Jaipuria, N.; Zhang, X.; Bhasin, R.; Arafa, M.; Chakravarty, P.; Shrivastava, S.; Manglani, S.; Murali, V.N. Deflating dataset bias using synthetic data augmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 14–19 June 2020; pp. 772–773.
- Jiang, C.; Qi, S.; Zhu, Y.; Huang, S.; Lin, J.; Yu, L.F.; Terzopoulos, D.; Zhu, S.C. Configurable 3d scene synthesis and 2d image rendering with per-pixel ground truth using stochastic grammars. Int. J. Comput. Vis. 2018, 126, 920–941.
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. Imagenet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255.
- Varol, G.; Romero, J.; Martin, X.; Mahmood, N.; Black, M.J.; Laptev, I.; Schmid, C. Learning from Synthetic Humans. In Proceedings of the CVPR, Honolulu, HI, USA, 21–26 June 2017.
- Shermeyer, J.; Hossler, T.; Van Etten, A.; Hogan, D.; Lewis, R.; Kim, D. Rareplanes: Synthetic data takes flight. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 4–8 January 2021; pp. 207–217.
- Khadka, A.R.; Oghaz, M.; Matta, W.; Cosentino, M.; Remagnino, P.; Argyriou, V. Learning how to analyse crowd behaviour using synthetic data. In Proceedings of the 32nd International Conference on Computer Animation and Social Agents, Paris, France, 1–3 July 2019; pp. 11–14.
- Allken, V.; Handegard, N.O.; Rosen, S.; Schreyeck, T.; Mahiout, T.; Malde, K. Fish species identification using a convolutional neural network trained on synthetic data. ICES J. Mar. Sci. 2019, 76, 342–349.
- Rosen, S.; Holst, J.C. DeepVision in-trawl imaging: Sampling the water column in four dimensions. Fish. Res. 2013, 148, 64–73.
- Alhaija, H.A.; Mustikovela, S.K.; Mescheder, L.; Geiger, A.; Rother, C. Augmented reality meets computer vision: Efficient data generation for urban driving scenes. Int. J. Comput. Vis. 2018, 126, 961–972.
- Geiger, A.; Lenz, P.; Stiller, C.; Urtasun, R. Vision meets robotics: The kitti dataset. Int. J. Robot. Res. 2013, 32, 1231–1237.
- Marcu, A.; Costea, D.; Licaret, V.; Pîrvu, M.; Slusanschi, E.; Leordeanu, M. SafeUAV: Learning to estimate depth and safe landing areas for UAVs from synthetic data. In Proceedings of the European Conference on Computer Vision (ECCV) Workshops, Munich, Germany, 8–14 September 2018.
- Gaidon, A.; Wang, Q.; Cabon, Y.; Vig, E. Virtual worlds as proxy for multi-object tracking analysis. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 4340–4349.
- Tremblay, J.; Prakash, A.; Acuna, D.; Brophy, M.; Jampani, V.; Anil, C.; To, T.; Cameracci, E.; Boochoon, S.; Birchfield, S. Training deep networks with synthetic data: Bridging the reality gap by domain randomization. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Salt Lake City, UT, USA, 18–22 June 2018; pp. 969–977.
- Qiu, H.; Yu, B.; Gong, D.; Li, Z.; Liu, W.; Tao, D. SynFace: Face Recognition with Synthetic Data. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 11–17 October 2021; pp. 10880–10890.
- Tang, Z.; Naphade, M.; Birchfield, S.; Tremblay, J.; Hodge, W.; Kumar, R.; Wang, S.; Yang, X. Pamtri: Pose-aware multi-task learning for vehicle re-identification using highly randomized synthetic data. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27–28 October 2019; pp. 211–220.
- Shen, B.; Li, B.; Scheirer, W.J. Automatic Virtual 3D City Generation for Synthetic Data Collection. In Proceedings of the 2021 IEEE Winter Conference on Applications of Computer Vision Workshops (WACVW), Seoul, Korea, 11–17 October 2021; pp. 161–170.
More