The impact of wood identification extends beyond illegal trading and ecological issues. Wood identification is paramount for the timber industry, civil and structural engineering, criminology, archaeology, art history, ethnography, and conservation and restoration, and many other disciplines.
- computer vision
- machine learning
- deep learning
- convolutional neural networks
- artificial neural networks
- generative adversarial networks
1. Introduction
2. Machine Learning
3. Image Acquisition
4. Image Datasets
| Dataset | Description | Image Type | Number of Species | Number of Images | Accessibility | Reference |
|---|---|---|---|---|---|---|
| CAIRO | Commercial hardwood species of Malaysia | Stereo | 37 | 3700 | Inaccessible | [32] |
| FRIM | 52 | 5200 | [33] | |||
| LignoIndo | Commercial hardwood species of Indonesia | 809 | 4854 | [34] | ||
| ZAFU WS 24 | Wood species at Zhejiang A&F University | 24 | 480 | [35] | ||
| RMCA | Commercial wood species of Central Africa | Micro | 77 | 1221 | Open | [36] |
| XDD | Major Fagaceae species of Japan | 18 | 2449 | [37] | ||
| Lauraceae species of East Asia | 39 | 1658 | [38] | |||
| WOOD-AUTH | Wood species of Greece | Macro | 12 | 4272 | [39] | |
| UFPR | Wood species of Brazil | 41 | 2942 | [40] | ||
| UFPR | Micro | 112 | 2240 | [29] |
2.4.1. Image Processing
54. Deep Learning
Deep learning is among the most notable and promising of the many branches of machine learning research.
As a neural network that attempts to simulate the function, structure and behaviour of the human brain (Figure 1), it has the capacity to process and “learn” large amounts of data [48] [49].
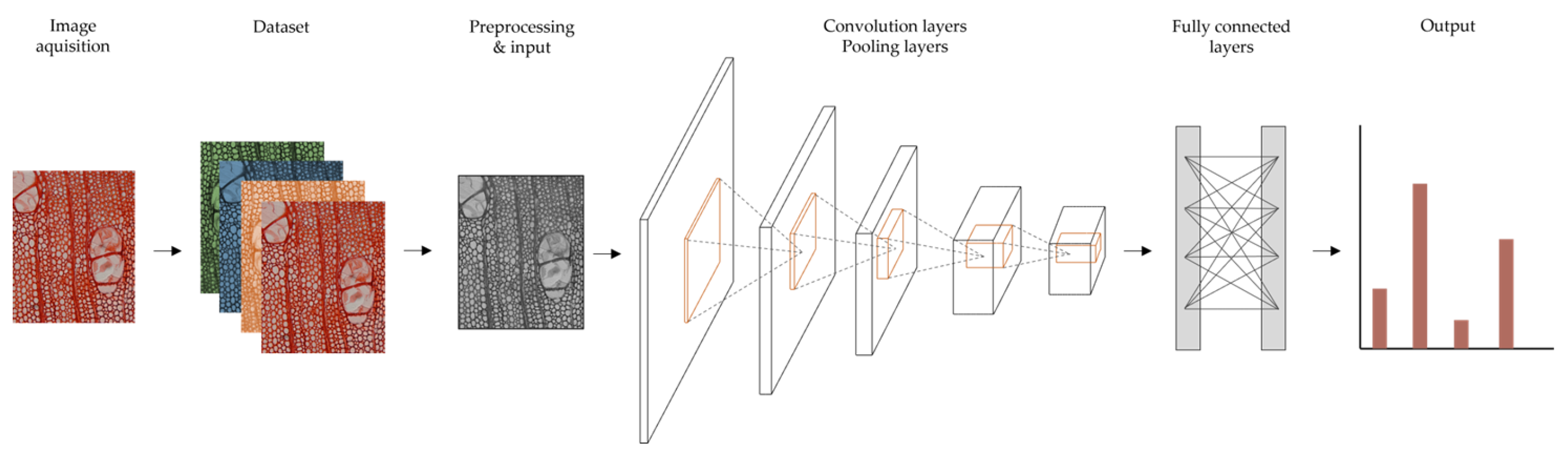
Figure 1. General pipeline of deep learning models for image classification (based on [50] [51]).
54.1 Artificial Neural Networks (ANN)
Artificial neural networks are not only one of the main investigation methods, but also constitute the foundation of deep learning [31]. These mathematical structures inspired by biological neural networks are a form of supervised or unsupervised learning that show high ability to learn from examples given to them and extrapolate the information when applied to future non-identified samples. This ability to reproduce, model and “learn” nonlinear processes has given ANNs widespread applications in multiple disciplines [43] [52].
54.2. Convolutional Neural Networks (CNN)
Convolutional neural networks are one of the most significant applications of ANNs. In the AI context, a CNN is a class of feedforward ANN that has been successfully applied to digital image processing analysis.
A CNN processes images more effectively by applying filtering techniques to ANNs [53]. This is a powerful and accurate way of solving classification problems, and CNNs are mainly credited for their role in image analysis, recognition, and classification. The architecture of a CNN typically has multiple layers between input and output: three convolutional layers, a pooling layer and a fully connected layer. These layers process different tasks during the image’s course. As the images progress through the distinct layers, features such as edges, colours and shapes are extracted and interpreted. These features are then learned and classified by the deep neural network, resulting ultimately in the network’s ability to identify a specific object [54] [55]. Other advantages are the capacity of automatically recognise important features without human supervision.
54.3. Generative Adversarial Networks (GANs)
Within deep learning, GANs [56] are described as neural networks that can learn to generate realistic samples from the data on which they were trained.
They use a neural network as a generator that takes a random distribution of data as input and learns to map that information to output the desired distribution of data. A second neural network, known as a discriminator (a binary classifier), will use the input and output images to determine the probability of the image originating as a training image (real) or on the generator (fake), thus assessing the most likely class to which the output image belongs [57].
Generative adversarial networks can produce highly realistic images using CNNs in an unsupervised manner [58].
References
- Voulodimos, A.; Doulamis, N.; Doulamis, A.; Protopapadakis, E.; Deep Learning for Computer Vision: A Brief Review.. Comput. Intell. Neurosci. 2018, 2018, 1-13, 10.1155/2018/7068349.
- Li, N.; Shepperd, M.; Guo, Y.; A Systematic Review of Unsupervised Learning Techniques for Software Defect Prediction. . Inf. Softw. Technol. 2020, 122, 106-287, 10.1016/j.infsof.2020.106287.
- Jordan, M.I.; Mitchell, T.M.; Machine Learning: Trends, Perspectives, and Prospects.. Science 2015, 349, 255–260, 10.1126/science.aaa8415.
- Khan, A.I.; Al-Habsi, S.; Machine Learning in Computer Vision.. Procedia Comput. Sci. 2020, 167, 1444–1451, 10.1016/j.procs.2020.03.355.
- Hwang, S.-W.; Sugiyama, J.; Computer Vision-Based Wood Identification and Its Expansion and Contribution Potentials in Wood Science: A Review.. Plant Methods 2021, 17, 47, 10.1186/s13007-021-00746-1.
- Ravindran, P.; Ebanyenle, E.; Ebeheakey, A.A.; Abban, K.B.; Lambog, O.; Soares, R.; Costa, A.; Wiedenhoeft, A.C. Image Based Identification of Ghanaian Timbers Using the XyloTron: Opportunities, Risks and Challenges. In Proceedings of the 33rd Conference on Neural Information Processing Systems (NeurIPS 2019), Dec. 9-14, Vancouver, Canada; Vancouver, Canada, 2019.
- Ravindran, P.; Thompson, B.J.; Soares, R.K.; Wiedenhoeft, A.C.; The XyloTron: Flexible, Open-Source, Image-Based Macroscopic Field Identification of Wood Products. . Front. Plant Sci. 2020, 11, 1–8, 10.3389/fpls.2020.01015.
- Dormontt, E.E.; Boner, M.; Braun, B.; Breulmann, G.; Degen, B.; Espinoza, E.; Gardner, S.; Guillery, P.; Hermanson, J.C.; Koch, G.; et al.et al. Forensic Timber Identification: It’s Time to Integrate Disciplines to Combat Illegal Logging. . Biol. Conserv. 2015, 191, 790–798, 10.1016/j.biocon.2015.06.038.
- Tou, J.Y.; Tou, P.; Lau, P.Y.; Tay, Y.H. Computer Vision-Based Wood Recognition System. Proc. Int’l Work. Adv. Image Technol. Bangkok, Thail. 2007.
- Ravindran, P.; Wiedenhoeft, A.C.; Comparison of Two Forensic Wood Identification Technologies for Ten Meliaceae Woods: Computer Vision versus Mass Spectrometry.. Wood Sci. Technol 2020, 54, 1139–1150, 10.1007/s00226-020-01178-1.
- Martins, A.L.R.; Marcal, A.R.S.; Pissarra, J. Modified DBSCAN Algorithm for Microscopic Image Analysis of Wood. In; 2019; pp. 257–269.
- Olschofsky, K.; Köhl, M.; Rapid Field Identification of Cites Timber Species by Deep Learning.. Trees, For. People 2020, 2 , 100-116, 10.1016/j.tfp.2020.100016.
- Barmpoutis, P.; Dimitropoulos, K.; Barboutis, I.; Grammalidis, N.; Lefakis, P.; Wood Species Recognition through Multidimensional Texture Analysis. Comput. Electron. Agric. 2018, 144 , 241–248, 10.1016/j.compag.2017.12.011.
- de Andrade, B.G.; Basso, V.M.; Latorraca, J.V. de F.; Machine Vision for Field-Level Wood Identification.. IAWA J 2020, 41 , 681–698, 10.1163/22941932-bja10001.
- Wang, H.; Zhang, G.; Qi, H.; Wood Recognition Using Image Texture Features. PLoS One 2013, 8, 76-101, 10.1371/journal.pone.0076101.
- Lens, F.; Liang, C.; Guo, Y.; Tang, X.; Jahanbanifard, M.; da Silva, F.S.C.; Ceccantini, G.; Verbeek, F.J.; Computer-Assisted Timber Identification Based on Features Extracted from Microscopic Wood Sections.. IAWA J. 2020, 41 , 660–680, 10.1163/22941932-bja10029.
- Martins, J.; Oliveira, L.S.; Nisgoski, S.; Sabourin, R.; A Database for Automatic Classification of Forest Species. . Mach. Vis. Appl. 2013, 24, 567–578, 10.1007/s00138-012-0417-5.
- Mallik, A.; Tarrío-Saavedra, J.; Francisco-Fernández, M.; Naya, S.; Classification of Wood Micrographs by Image Segmentation.. Chemom. Intell. Lab. Syst. 2011, 107, 351–362, 10.1016/j.chemolab.2011.05.005.
- Kobayashi, K.; Hwang, S.-W.; Okochi, T.; Lee, W.-H.; Sugiyama, J.; Non-Destructive Method for Wood Identification Using Conventional X-Ray Computed Tomography Data.. J. Cult. Herit. 2019, 38, 88–93, 10.1016/j.culher.2019.02.001.
- Kobayashi, K.; Akada, M.; Torigoe, T.; Imazu, S.; Sugiyama, J.; Automated Recognition of Wood Used in Traditional Japanese Sculptures by Texture Analysis of Their Low-Resolution Computed Tomography Data.. J. Wood Sci. 2015, 61, 630–640, 10.1007/s10086-015-1507-6.
- Lopes, D.J.V.; Burgreen, G.W.; Entsminger, E.D.; North American Hardwoods Identification Using Machine-Learning. . Forests 2020, 11, 298, 10.3390/f11030298.
- Yu, H.; Cao, J.; Luo, W.; Liu, Y. Image Retrieval of Wood Species by Color, Texture, and Spatial Information. In Proceedings of the 2009 International Conference on Information and Automation; IEEE, June 2009; pp. 1116–1119.
- Yusof, R.; Khalid, M.; Khairuddin, A.S.M.; Application of Kernel-Genetic Algorithm as Nonlinear Feature Selection in Tropical Wood Species Recognition System.. Comput. Electron. Agric. 2013, 93, 68–77, 10.1016/j.compag.2013.01.007.
- Martins, J.; Oliveira, L.S.; Nisgoski, S.; Sabourin, R. The Forest Species Database – Microscopy Available online: https://web.inf.ufpr.br/vri/databases/forest-species-database-microscopic/ (accessed on 3 May 2022).
- Khalid, M.; Lew, E.; Lee, Y.; Yusof, R.; Nadaraj, M. Design of an Intelligent Wood Species Recognition System. Int. J. Simul. Syst., Sci. Technol. 2008, 9.
- Stanford, V.L.; University, S.; University, P. ImageNet Available online: https://www.image-net.org/ (accessed on 21 April 2021).
- Seregin, A.P.; Moscow Digital Herbarium: A Consortium since 2019. . Taxon 2020, 69, 417–419, 10.1002/tax.12228.
- New Your Botanical Garden, N. INDEX HERBARIORUM Available online: http://sweetgum.nybg.org/science/ih/ (accessed on 21 April 2022).
- UFPR Forest Species Database – Microscopic Available online: https://web.inf.ufpr.br/vri/databases/forest-species-database-microscopic/ (accessed on 21 April 2022).
- Hwang, S.-W.; Sugiyama, J.; Computer Vision-Based Wood Identification and Its Expansion and Contribution Potentials in Wood Science: A Review. . Plant Methods 2021, 17, 47, 10.1186/s13007-021-00746-1.
- Hwang, S.-W.; Sugiyama, J.; Computer Vision-Based Wood Identification and Its Expansion and Contribution Potentials in Wood Science: A Review.. Plant Methods 2021, 17, 47, 10.1186/s13007-021-00746-1.
- Nasirzadeh, M.; Khazael, A.A.; Khalid, M. bin Woods Recognition System Based on Local Binary Pattern. In Proceedings of the Second International Conference on Computational Intelligence, Communication Systems and Networks, CICSyN 2010; IEEE: Liverpool, UK, July 2010; pp. 308–313.
- Khalid, M.; Yusof, R.; Khairuddin, A.S.M. Improved Tropical Wood Species Recognition System Based on Multi-Feature Extractor and Classifier. Int. J. Electr. Comput. Eng. 2011, 5, 495–501.
- Damayanti, R.; Prakasa, E.; Krisdianto; Dewi, L.M.; Wardoyo, R.; Sugiarto, B.; Pardede, H.F.; Riyanto, Y.; Astutiputri, V.; Panjaitan, G.R.; et al. LignoIndo: Image Database of Indonesian Commercial Timber. IOP Conf. Ser. Earth Environ. Sci. 2019, 374, 12057, doi:10.1088/1755-1315/374/1/012057.
- Wang, H.; Zhang, G.; Qi, H.; Wood Recognition Using Image Texture Features.. PLoS One 2013, 8, 76-101, 10.1371/journal.pone.0076101.
- Silva, N.R. da; De Ridder, M.; Baetens, J.M.; Van den Bulcke, J.; Rousseau, M.; Bruno, O.M.; Beeckman, H.; Van Acker, J.; De Baets, B.; Automated Classification of Wood Transverse Cross-Section Micro-Imagery from 77 Commercial Central-African Timber Species. . Ann. For. Sci. 2017, 74, 30, 10.1007/s13595-017-0619-0.
- Kobayashi, K.; Kegasa, T.; Hwang, S.S.-W.; Sugiyama, J. Anatomical Features of Fagaceae Wood Statistically Extracted by Computer Vision Approaches: Some Relationships with Evolution. PLoS One 2019, 14, doi:10.1371/journal.pone.0220762.
- Sugiyama, J.; Hwang, S.W.; Kobayashi, K.; Zhai, S.; Kanai, I.; Kanai, K. Database of Cross Sectional Optical Micrograph from KYOw Lauraceae Wood. Available online: https://repository.kulib.kyoto-u.ac.jp/dspace/handle/2433/245888 (accessed on 21 April 2022).
- Wood-auth. Barmpoutis P. WOOD-AUTH Dataset A (Version 0.1). Available online: https://doi.org/10.2018/wood.auth (accessed on 21 April 2022).
- UFPR Forest Species Database – Macroscopic Available online: https://web.inf.ufpr.br/vri/databases/forest-species-database-macroscopic/ (accessed on 23 April 2021).
- Kour, A.; Yv, V.; Maheshwari, V.; Prashar, D. A Review on Image Processing. Int. J. Electron. Commun. Comput. Eng. 2012, 4, 2278–4209.
- Filho, P.L.P.; Oliveira, L.S.; Nisgoski, S.; Britto, A.S.; Forest Species Recognition Using Macroscopic Images. . Mach. Vis. Appl. 2014, 25, 1019–1031, 10.1007/s00138-014-0592-7.
- Silva, N.R. da; De Ridder, M.; Baetens, J.M.; Van den Bulcke, J.; Rousseau, M.; Bruno, O.M.; Beeckman, H.; Van Acker, J.; De Baets, B.; Automated Classification of Wood Transverse Cross-Section Micro-Imagery from 77 Commercial Central-African Timber Species.. Ann. For. Sci. 2017, 74, 30, 10.1007/s13595-017-0619-0.
- Zamri, M.I.P.; Cordova, F.; Khairuddin, A.S.M.; Mokhtar, N.; Yusof, R.; Tree Species Classification Based on Image Analysis Using Improved-Basic Gray Level Aura Matrix. . Comput. Electron. Agric. 2016, 124, 227–233, 10.1016/j.compag.2016.04.004.
- Yusof, R.; Rosli, N.R.; Khalid, M. Tropical Wood Species Recognition Based on Gabor Filter. In Proceedings of the 2009 2nd International Congress on Image and Signal Processing; IEEE, October 2009; pp. 1–5.
- Brunel, G.; Borianne, P.; Subsol, G.; Jaeger, M.; Caraglio, Y.; Automatic Identification and Characterization of Radial Files in Light Microscopy Images of Wood. . Ann. Bot. 2014, 114, 829–840, 10.1093/aob/mcu119.
- Kobayashi, K.; Hwang, S.-W.; Lee, W.-H.; Sugiyama, J.; Texture Analysis of Stereograms of Diffuse-Porous Hardwood: Identification of Wood Species Used in Tripitaka Koreana.. J. Wood Sci. 2017, 63, 322–330, 10.1007/s10086-017-1625-4.
- LeCun, Y.; Bengio, Y.; Hinton, G.; Deep Learning.. Nature 2015, 521, 436–444, 10.1038/nature14539.
- Goodfellow, I.; Bengio, Y.; Courville, A.. Deep Learning; MIT press, Eds.; MIT press: Cambridge, 2016; pp. 800.
- Hwang, S.-W.; Sugiyama, J.; Computer Vision-Based Wood Identification and Its Expansion and Contribution Potentials in Wood Science: A Review.. Plant Methods 2021, 17, 47, 10.1186/s13007-021-00746-1.
- Du, M.; Liu, N.; Hu, X.; Techniques for Interpretable Machine Learning.. Commun. ACM 2019, 63, 68–77, 10.1145/3359786.
- Abiodun, O.I.; Kiru, M.U.; Jantan, A.; Omolara, A.E.; Dada, K.V.; Umar, A.M.; Linus, O.U.; Arshad, H.; Kazaure, A.A.; Gana, U. Comprehensive Review of Artificial Neural Network Applications to Pattern Recognition. IEEE Access 2019, 7, 158820–158846, doi:10.1109/ACCESS.2019.2945545.
- Goodfellow, I.; Bengio, Y.; Courville, A. . Deep Learning; MIT press, Eds.; MIT press: Cambridge, 2016; pp. 800.
- Hwang, S.-W.; Sugiyama, J.; Computer Vision-Based Wood Identification and Its Expansion and Contribution Potentials in Wood Science: A Review. . Plant Methods 2021, 17, 47, 10.1186/s13007-021-00746-1.
- Chai, J.; Zeng, H.; Li, A.; Ngai, E.W.T.; Deep Learning in Computer Vision: A Critical Review of Emerging Techniques and Application Scenarios.. Mach. Learn. with Appl. 2021, 6, 100-134, 10.1016/j.mlwa.2021.100134.
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative Adversarial Nets. In Proceedings of the Advances in Neural Information Processing Systems; Montreal, QC, 2014.
- Yi, X.; Walia, E.; Babyn, P.; Generative Adversarial Network in Medical Imaging: A Review. . Med. Image Anal. 2019, 58, 101-552, 10.1016/j.media.2019.101552.
- Lopes, D.J.V.; Monti, G.F.; Burgreen, G.W.; Moulin, J.C.; Bobadilha, G. dos S.; Entsminger, E.D.; Oliveira, R.F.; Creating High-Resolution Microscopic Cross-Section Images of Hardwood Species Using Generative Adversarial Networks. . Front. Plant Sci. 2021, 12, 10, 10.3389/fpls.2021.760139.