Your browser does not fully support modern features. Please upgrade for a smoother experience.
Please note this is a comparison between Version 1 by Jibril Abdullahi Bala and Version 2 by Peter Tang.
The advancements in Information and Communication Technology (ICT) as well as increasing demand for vehicular safety has led to significant progressions in Autonomous Vehicle (AV) technology. Perception and Localisation are major operations that determine the success of AV development and usage. Therefore, significant research has been carried out to provide AVs with the capabilities to not only sense and understand their surroundings efficiently, but also provide detailed information of the environment in the form of 3D maps. Visual Simultaneous Localisation and Mapping (V-SLAM) has been utilised to enable a vehicle understand its surroundings, map the environment, and identify its position within the area.
- autonomous vehicles
- computer vision
- localisation
- mapping
- visual SLAM
1. Introduction
Autonomous Vehicles (AVs) have received widespread attention globally due to their low deployment costs, low on-board sensor sizes, and improved technology [1][2][3][4][1,2,3,4]. AVs have the ability to carry out various driving tasks with minimal or no human supervision. This unique ability of AVs significantly reduces driver workload while increasing driver comfort and efficiency. Additionally, these systems improve vehicle safety by reducing human errors, such as drowsiness, intoxication, fatigue, and loss of concentration, which in turn lead to vehicle accidents [2][5][6][7][2,5,6,7]. The end-goal of AV development is to create a driverless system that can perform diverse driving tasks [8]. The successful operation of AVs depends on five operational modules which are perception, localisation, decision making, planning, and control [8][9][8,9]. While decision making, planning, and control majorly involve problem solving, the vehicle can only perform these tasks based on the input from the perception and localisation modules. Perception, planning, and control are significant challenges in AV security and safety [10]. Understanding the surroundings is critical in a vehicle’s operation [11], and sensing the environment is achieved using a variety of perception technologies such as cameras, lidar, radar, Global Position System (GPS) devices, and ultrasonic sensors [12]. Localisation involves a vehicle estimating its position and orientation within a perceived environment. Robust localisation is another key challenge in AV deployment [13]. Several studies have implemented GPS and Global Navigation Satellite System (GNSS)-based localisation schemes. However, these techniques have proven insufficient in terms of precision, and as such, recent research efforts have focused on the use of lidar and cameras for localisation [13]. A popular technique which utilises cameras and lidar sensors for perception and localisation is Simultaneous Localisation and Mapping (SLAM).
SLAM is method in which an autonomous navigation system obtains 2D or 3D geometric information about its surroundings, which is usually unknown, estimates its pose within that environment, and generates a map of the area [14][15][14,15]. SLAM-based systems have been used in a wide range of applications such drones, mobile robots, virtual reality, and augmented reality [14][16][14,16]. A variety of sensors have been used in implementing SLAM such as lidar, GPS, and Inertial Measurement Unit (IMU) sensors [14][17][14,17]. However, SLAM based on cameras has been widely studied due to the low cost, simpler configuration, low energy consumption, and versatility of cameras [14][16][14,16]. This technique, known as Visual SLAM (V-SLAM), uses cameras to estimate an autonomous agent’s position and orientation within an environment, as well as map that environment.
V-SLAM is technique under Visual Odometry (VO) which uses cameras to calculate a body’s change in position over time [18]. V-SLAM has been implemented with different camera types and configurations. Monocular, stereo, and RGB-D cameras have also been successfully used in developing SLAM-based systems [19]. Additionally, these techniques utilises a variety of feature extraction techniques [20] and some researchers have combined traditional V-SLAM schemes with machine and deep learning [21]. Furthermore, the maps generated by SLAM algorithms provide a visual representation of the environment in 2D forms, as in the case of binary occupancy grid maps [22] or 3D forms such as point cloud maps [23].
2. Simultaneous Localisation and Mapping (SLAM)
Simultaneous Localisation and Mapping (SLAM) is a major problem in the field of robotics and autonomous navigation systems. The solution to the SLAM problem enables a mobile robot or AV to create a map of its environment while simultaneously keeping track of its pose within the same environment [24][25][24,25]. In the last three decades, significant achievements have been recorded in the field of SLAM [16]. SLAM has been implemented in ground [26], aerial [27], and underwater [28] systems. The SLAM problem has been solved using a variety of approaches. Filter-based algorithms such as Extended Kalman Filter (EKF) and Particle Filter (PF) have been used in SLAM systems. Estimation theoretic approaches such as Bayesian estimation have also been implemented to solve the SLAM problem [24]. For instance, in [29], an optimized self-localization technique for SLAM was presented. This method was developed for dynamic scenes using hypothesis density filters. The novel approach, called GEM-SLAM, achieved major improvements over three benchmark algorithms namely, the Rao Blackwellized Probability Hypothesis Density (RB-PHD) filter, the Single Cluster Probability Hypothesis Density (SC-PHD) filter, and the Factored Solution to SLAM (FastSLAM) algorithm.2.1. SLAM Techniques
SLAM techniques can be categorised into two groups: the Filter-based SLAM and the Graph-based SLAM [29]. The graph-based techniques depend on non-linear optimization techniques and thus, the method used must ensure convergence to global minima. Additionally, pose graph optimisation is susceptible to accumulated errors. Loop closure is used to detect a previously visited location and recalibrates the system’s trajectory [29]. Other graph-based techniques include Occupancy Grid-based SLAM [30], Graph SLAM [30], and Incremental Smoothing and Mapping (iSAM) [31][32][31,32]. Because of the limitations of graph-based approaches, such as convergence to local minima and cumulative errors, filter-based techniques have been investigated as possible alternatives to graph-based techniques. The EKF is one of the earliest methods for solving SLAM and was proposed by [33]. A clutter resistant SLAM algorithm for autonomous guided vehicles in dynamic industrial environments was presented in [24]. This clutter-resistant technique uses point features generated from reflectors and line features to improve SLAM robustness. The technique proved to be accurate and efficient by keeping the localisation error within 19 mm and 31 mm for the X-axis and Y-axis, respectively. The Unscented Kalman Filter (UKF) is related to the class of Linear Regression Kalman Filters. This technique is widely used in SLAM systems to linearize random variable non-linear functions using linear regression [34]. A localisation technique for Wireless Sensor Networks (WSNs) based on UKF and PF algorithms was presented in [34]. The authors modified a Kalman Filter based on UKF and PF localisation. This proposed technique showed a variety of applications such as target tracking and robot localisation based on the simulation results. The PF is also another filter-based method used in SLAM. The PF samples multiple possibilities (particles) of the observer and filters them based on the likelihood of them having the correct pose [35][36][35,36]. A fast algorithm of SLAM for mobile robots based on ball PF was presented in [26]. This technique was a modification of the box PF and the firefly algorithm is used to maintain the diversity of ball particles. This process increased the consistency of the pose estimation and the results demonstrated the superiority in performance of the technique. In addition, ref. [37] presented an embedded PF SLAM implementation using a cost effective platform. In this study, a Genetic Algorithm (GA)-based approach is implemented for calibration and to prevent overfitting. This process provided more generalizable results, robustness, and improved performance. Furthermore, a PF SLAM using differential drive mobile robot was presented in [38]. The study implemented a PF-based SLAM technique on a mobile robot called e-puck. This study observed that the number of particles used had an effect of the performance of the algorithm. Also, ref. [39] developed a stratified PF SLAM based on monocular cameras. This study used a sample weighting algorithm to stratify the particles and was implemented for an Unmanned Aerial Vehicle (UAV). The results were compared to different sample weighting approaches and exhibited improved robustness and accuracy. In addition, the Rao-Blackwellized Particle Filter (RBPF) is used for robust estimation in SLAM [29]. For instance, ref. [40] presented a study which improved grid-based SLAM with RBPF by adaptive proposals and selective resampling. This technique computed an accurate proposal distribution which considers both the movement of the robot and its most recent observation. The results exhibited the advantage of this technique over other previous approaches. Another popular filter-based technique used in SLAM is the Factored Solution to Simultaneous Localization and Mapping (FastSLAM) which is based on the RBPF [41][42][41,42]. The FastSLAM algorithm was later improved by Montemerlo [43][44][43,44]. A hierarchy of the types of SLAM techniques is presented in Figure 1.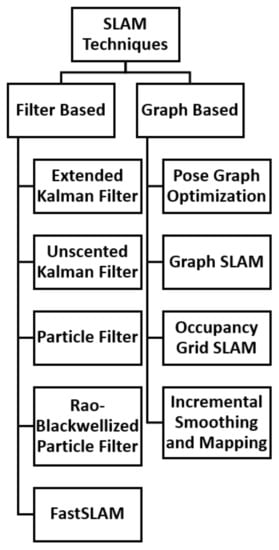
Figure 1.
Hierarchy of SLAM Techniques.
2.2. Sensors Used in SLAM
Autonomous navigation systems use a variety of sensors to perceive the environment and localise themselves. These sensors include lidar, sonar, a Radio Frequency Identification (RFID), Global Positioning System (GPS), Inertial Measurement Units (IMU), and vision sensors [17]. For instance, ref. [45] evaluated the exact flow of particles used for state estimations in unmanned aerial system navigation. The technique utilised sensor information obtained from IMU and GPS sensors and implemented a novel Bayesian filtering SLAM technique for aerial environments. The results proved the effectiveness of this technique over existing methods in terms of speed of convergence and accuracy. Furthermore, ref. [46] presented a PF-based landmark mapping for SLAM of mobile robots. This technique was based on a Radio Frequency Identification (RFID) system and used two separate filters to estimate position and orientation of the robot and integrated circuit tags. The experimental results validated the technique and showed its computational efficiency. SLAM based on lidar sensors is a popular research area since the sensor data is not affected by illumination changes unlike cameras [47]. This technique is considered to be an accurate and effective method for autonomous agents to create a map and localise themselves [25]. A conic feature-based SLAM technique was developed for open environments in [25]. The technique utilised 2D lidar and a defined conic feature-based parametric approach. The experimental results proved the accuracy of the algorithm in open environments. In addition, ref. [48] benchmarked PF algorithms for efficient Velodyne-based vehicle localisation. Due to the large amount of information obtained by the 3D Velodyne lidar sensor, an analysis was performed to ascertain the how many points were required to achieve optimal efficiency and positioning accuracy. The study conclude that an initial density of two particles per square metre were required to achieve total convergence. Additionally, Global Navigation Satellite System (GNSS) has been successfully used to implement localisation techniques in SLAM. GNSS provides multiple positioning solutions such as precise point positioning, single point position, and Real-time Kinematic (RTK). GNSS is low cost and works well in an open sky environment [47]. A continuous positioning algorithm based on RTK and Visual Inertial SLAM (VI-SLAM) was presented in [49]. In this study, VI-SLAM was used to complement the limitations of RTK such as blockage of satellite signals by trees and buildings. The results showed the effectiveness of the technique to provide continuous positioning solutions. Furthermore, sonar sensors have been successfully implemented in SLAM systems. Laser scanners have also been implemented to solve SLAM problems due to their ability to provide bearing and range information [50][51]. A PF-based outdoor robot localization technique using natural features extracted from a laser scanner was presented in [50][51]. This method applies batch processing which extracts features from full laser scans. The PF is applied to reduce the estimation error associated with EKFs and the technique was verified in real world experiments. Additionally, ref. [51][52] presented a distributed SLAM technique using improved PF for mobile robot localisation. This method used data obtained from laser sensors and dead reckoning. The system exhibited better tolerance and robustness over Distributed PF SLAM.3. Visual Simultaneous Localisation and Mapping (V-SLAM)
3.1. Background of V-SLAM
V-SLAM is a technique in which an autonomous navigation system uses a vision sensor to construct and update a map of an unknown environment while at the same time keeping track of its position and orientation within that environment [52][53][58,59]. In comparison to other sensor data such as lidar, camera data can provide rich and abundant information, which enhances high level operations [54][60]. The camera route is represented as a set of relative poses in a world reference frame. The environment is represented by landmarks which are objects or keypoint features in each frame. The landmarks remain still in static environments, while the landmarks change their position in the case of dynamic environments [54][60]. The V-SLAM process can be broken down into the following steps [52][58]:-
Acquire, read, and pre-process the data from the camera and other devices;
-
Estimate motion and local map of the scene from adjacent camera frames;
-
Optimise and adjust camera poses;
-
Detect loops to eliminate errors and complete the map.
3.2. V-SLAM Categories
V-SLAM can be categorised into three major classifications, namely: Feature-based methods (Indirect method), Direct methods, and Multi-Sensor methods [14]. These methods are presented in Figure 2.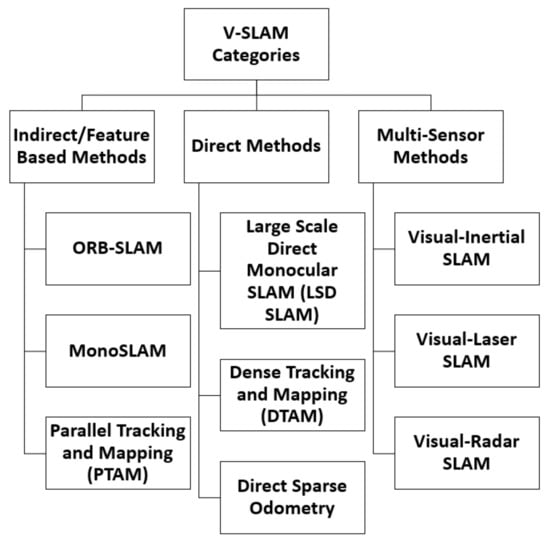
Figure 2.
V-SLAM Categories.