Your browser does not fully support modern features. Please upgrade for a smoother experience.
Please note this is a comparison between Version 2 by Vivi Li and Version 1 by Meng Wu.
The detection of crack information is very important in mural conservation. In practice, the number of ancient murals is scarce, and the difficulty of collecting digital information about murals leads to minimal data being collected. Crack information appears in pictures of paintings, which resembles painting traces and is easy to misidentify. However, the current mainstream semantic segmentation networks directly use the features of the backbone network for prediction, which do not fully use the features at different scales and ignore the differences between the decoder and encoder features. A new U-shaped convolutional neural network with feature pyramids and a transformer called TMCrack-net is proposed.
- murals
- crack segmentation
- U-Net
- BiFPN
- FCA
1. Introduction
Ancient murals are regarded as valuable cultural heritage, reflecting the social landscape of the times they are from. They provide a valuable basis for studying ancient cultures because of their scientific, historical, and humanistic value. However, under the influence of natural and artificial factors, many murals [1] have suffered from problems such as cracks, puckering, and scratches, which weaken the information expression of frescoes and are not conducive to preserving history and culture, or the transmission of the art.
Screen cleaning, reinforcement, paper, cloth stickers, disease analysis, expert evaluation, and disease labeling [2] are all involved in the manual disease labeling of ancient murals. A manual method will not only cause secondary damage to the murals but will also be very inefficient. Therefore, image processing technology must be introduced to help heritage conservationists protect murals.
Accurate segmentation of cracks in mural images is challenging, and mural paintings have complex background structures. The painting of the polo picture in the tomb of Prince Zhang Huai in Tang Dynasty is rich in content; the painting has different backgrounds of people, horses, trees among mountains and rocks; and the complex image content increases the difficulty of crack recognition. Cracked images are shown in Figure 1.

Figure 1.
Feature network design: (
a
) person and horse; (
b
) stone; (
c
) trees.
Among the crack detection algorithms of traditional image processing, Hou proposed a K-means Sobel algorithm to extract the disease edges of murals. Two evaluation [3] criteria were given for the specificity of murals: disease recognition rate and edge continuity. Subsequently, his team [4] used geographic information system technology (GIS) to produce high-precision digital orthophoto maps (DOM) of murals, establish a spatial database of diseases, obtain disease maps and trend maps, obtain the locations and severity of diseases through spatial analysis and spatial statistics, and use decision trees to classify disease classes. Gancarczyk [5] applied data mining techniques to image segmentation techniques to extract crack information with unsatisfactory results. Cornelis [6] proposed a multi-scale high-hat transform and K-SVD method and a post-processing method based on semi-supervised clustering to eliminate mislabeling, and weighted fusion of the three methods was performed to calibrate crack information of different sizes and brightnesses. Two types of methods are described below: (1) manual depiction using GIS software; (2) image processing using edge detection and multivariate filtering. Though both methods involve non-contact extraction, they are mostly human–computer interactions and semi-automatic methods requiring improved accuracy.
With the development of computational vision and deep learning, different neural networks are used for mural painting disease detection. Lin [7] used hyperspectral images for disease region identification, using minimum noise fraction (MNF) to focus on different bands and reduce the effect of noise on the data. The mural images were classified into several types of damaged areas and normal areas by back propagation (BP) neural network. Yu [8] used a U-Net network with multi-scale details to detect paint peeling disease in mural paintings of Fengguo Temple of Liao Dynasty in Yi County, Jinzhou City, China. The shallow features of the wall paintings were injected into different stages of the encoder to obtain detailed information about the paint peeling disease, and attention mechanisms were added to suppress invalid features in the encoding stage. Wu [9] proposed the Ghost-C3SE YOLOv5 network to detect the damage to cave murals. The YOLOv5 network structure was adjusted to reduce the dimensionality of the convolutional layers. An attention mechanism was added to the backbone network to adjust the importance of different feature channels.
2. Related Work
Different CNN models are used in crack segmentation methods. The effectiveness of CNNs in crack segmentation has been demonstrated in a large number of experiments.2.1. Feature Pyramid
2. Feature Pyramid
Multi-scale images are one of the most challenging aspects of computer vision, and most networks directly use the features extracted from the backbone network to predict the target. This pioneering work [10] proposed a top-down approach to multi-scale features using the feature pyramid network (FPN). Following this idea, PANet [11] adds a bottom-up path aggregation network on top of FPN to further exploit the different information between the bottom and top-level features. NAS-FPN [12] uses neural architecture searching to design feature network topologies automatically but requires thousands of hours of GPU time and makes it difficult to interpret the network structure. BiFPN [13] adds a bi-directional scale join based on removing nodes with only one input edge and adding a residual structure to join the original junction and the output node. Each of the four network structures is shown in Figure 2.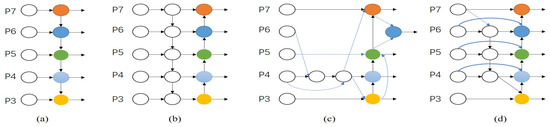
Figure 2. Feature network design. (a) FPN builds top-down networks with lateral connections to fuse detailed and semantic information (P3-P7); (b) PANET adds bottom-up paths to FPN to build a bidirectional fusion backbone network; (c) NAS-FPN uses neural architecture searching to find the most suitable feature network structure for the backbone network; (d) BiFPN, based on bidirectional scale linking, removes nodes with only one input edge and adds a residual structure to link the original junction and the output node.
2.2. Vision Transformer
3. Vision Transformer
The transformer [15] program has achieved great success in the natural language processing domain, and many researchers have applied the program to tasks related to computer vision. A pure transformer vision model (Vision Transformer, ViT) was proposed by Dosovitskiy [16], which divides, convolves, and spreads images into two-dimensional vectors to solve the transformer’s input problem in the image domain. Liu [17] proposed the Swin-Transformer, which uses a hierarchical construction method similar to that used in convolutional neural networks: chunking the feature maps to reduce computational effort and using spatially shifted bit windows to facilitate information exchange between different windows, thus improving the model’s ability to extract local information. The state-of-the-art level of ImageNet classification is achieved. Inspired by Swin-Transformer, Cao [18] proposed Swin-Unet, the first purely transformer-based U-shaped structure, which uses Swin-Transformer to replace the convolution module in U-Net. Wang [19] proposed UCTransNet, using a CTrans (channel transformer) module instead of skip connections in U-Net. The CTrans module consists of multi-scale channel cross-fusion (called CCT) and channel cross-attention (called CCA). The CCT module performs cross-fusion of multi-scale features through the transformer. The CCA module directs the fusion of the fused multi-scale features with the decoded features through attention. The Swin-Unet algorithm requires a large amount of data to obtain better performance. It lags behind the convolutional network when small amounts of data are available. UCTransNet directly uses the features of the backbone network as input to the transformer. It does not take full advantage of the underlying detailed information. This paperntry uses the pure convolutional network ConvNext as the backbone to extract features that better fit small datasets. The information at different scales is better utilized using a feature fusion network.3. Model Architecture
4. Model Architecture
TMCrack-Net consists of three main modules: (1) Top-down extraction of crack features using the ConvNext network as the backbone of the U-net network. (2) The AG-BiFPN module includes BiFPN and CCT, a feature fusion network, to exploit the multi-scale features of the image better. (3) An attention fusion module to better enhance useful features and suppress invalid ones. Figure 3 shows the TMCrack-Net with BiFPNet, Transforme, and FCA.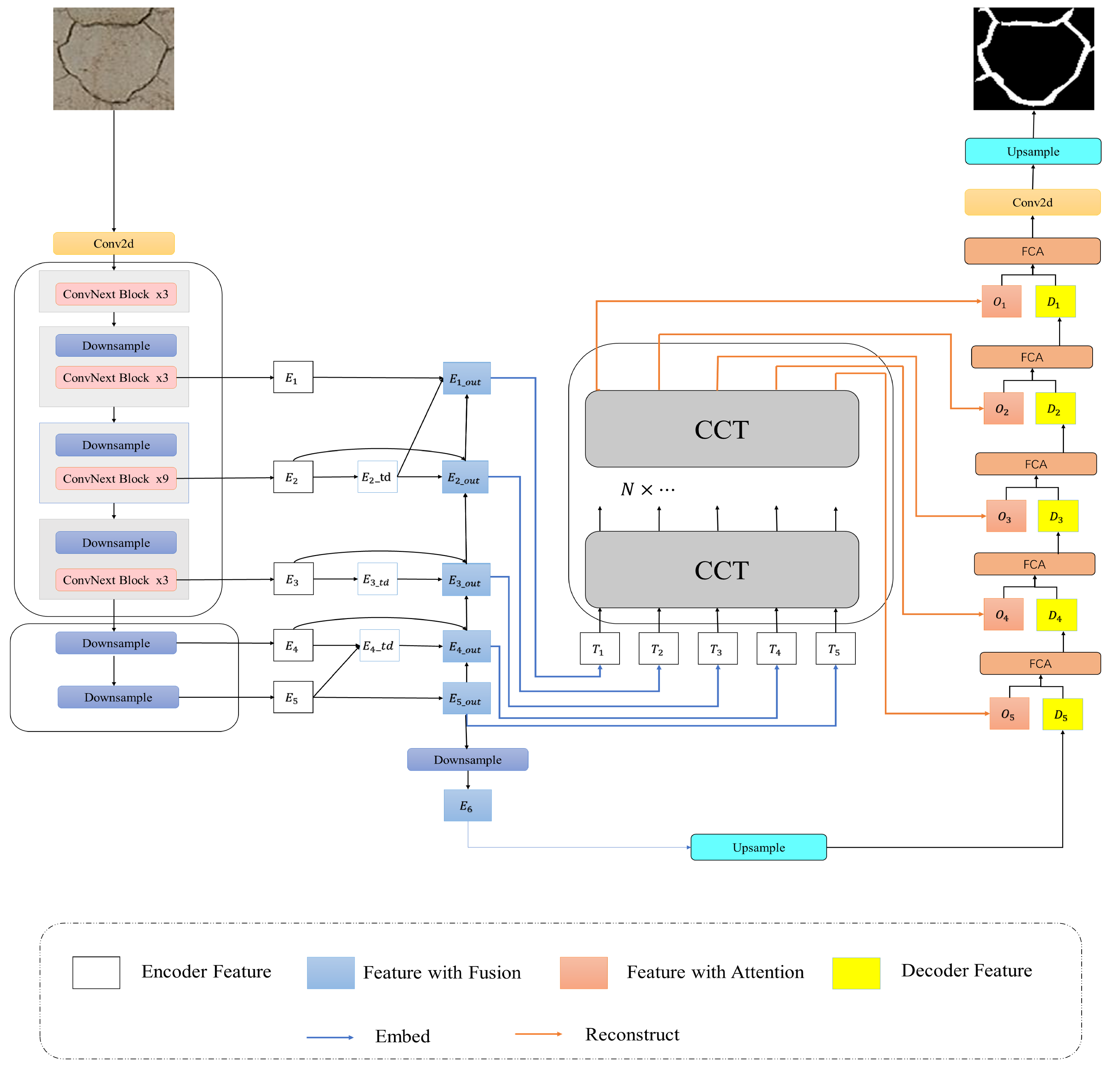
Figure 3.
Overall model framework of TMCrack-Net.
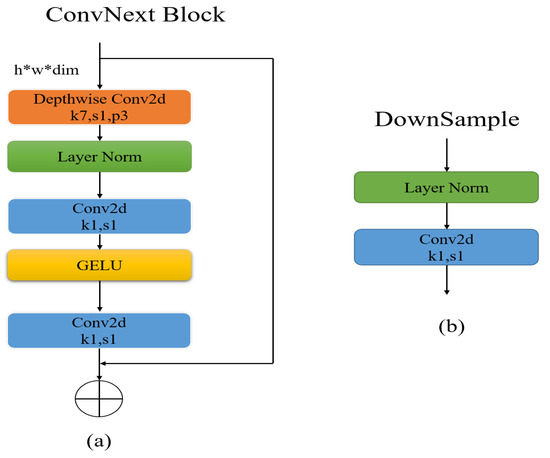
Figure 4. Feature network design. The * stands for multiplication (a) ConvNeXt block’s structure; (b) downsample structure, where k represents the convolution kernel size, s represents the step size, and p represents the padding.
4. AG-BiFPN Module
UCTransNet demonstrates that not all jump-joins are beneficial for segmentation, and simple replication of features at the encoder stage can be detrimental to feature fusion, so more suitable feature fusion methods are needed to join the encoder and decoder. In order to better utilize the features extracted from the backbone network, wresearchers invoke a combination of BiFPN and CCT modules instead of the original hop-join in the U-net. By fusing feature information at different scales through the BiFPN network, the input image retains a richer level of detail contained in the shallow features, better utilizes local information, and focuses on extracting crack details. BiFPN was proposed by Google Research, based on the bi-directional scale join. It removes the nodes with only one input edge, which do not perform feature fusion and contribute little to the network, and add the residual structure to join the original junction with the output node, which can fuse more features. The BiFPN infrastructure is shown in Figure 2d. The single-use feature fusion network with only a convolutional structure is biased toward local interaction and brings some confounding effect, which interferes with recognizing cracks. By adding an attention mechanism after BiFPN, as shown in Figure 5, the CCT module can better emphasize the global information and alleviate the confounding effect at each layer of the pyramid.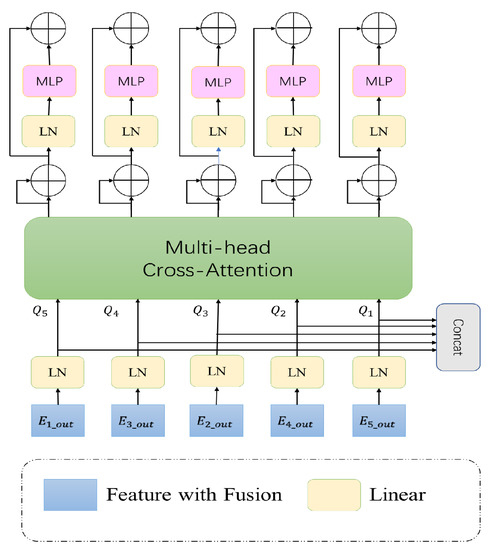
Figure 5.
Structure of the CCT module.